Fine-tuning a multimodal large language model for clinician-grade autism behavioral scoring from short home videos
Pith reviewed 2026-06-29 02:10 UTC · model grok-4.3
The pith
Fine-tuned multimodal LLMs can extract validated autism behavioral features from home videos with higher clinician agreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
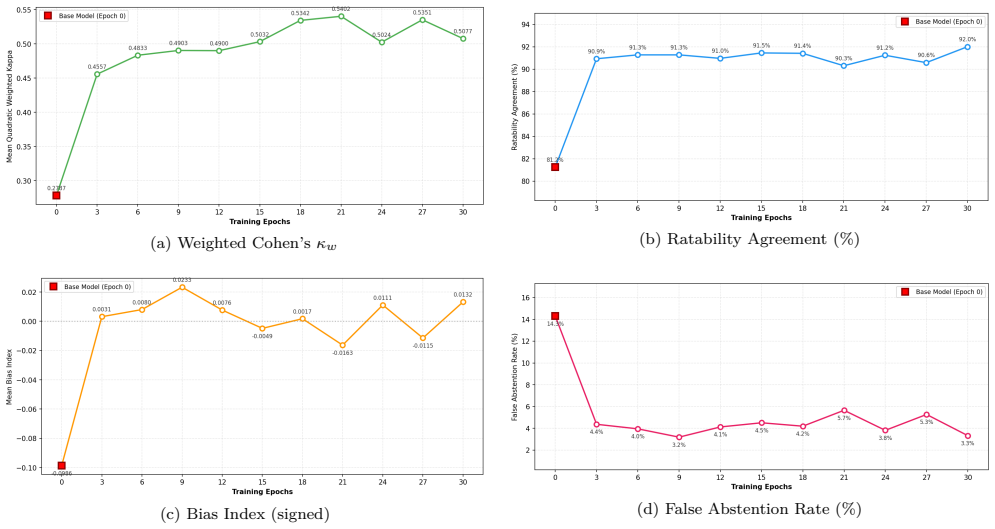
Fine-tuning a multimodal large language model on clinician-rated short home videos enables it to extract 30 validated behavioral features with improved agreement to clinicians, supporting both feature-based diagnosis and direct zero-shot ASD classification at levels matching or exceeding human clinicians.
What carries the argument
Low-rank adaptation (LoRA) fine-tuning of the Gemini 2.5 Pro multimodal LLM to predict scores on 30 validated behavioral features from video input.
Load-bearing premise
The 30 validated behavioral features contain sufficient diagnostic information when extracted reliably from short home videos without introducing systematic errors due to video quality or other factors.
What would settle it
Evaluating the fine-tuned model on an independent set of home videos with multiple clinician ratings to check if the reported improvements in kappa and diagnosis metrics persist.
Figures
read the original abstract
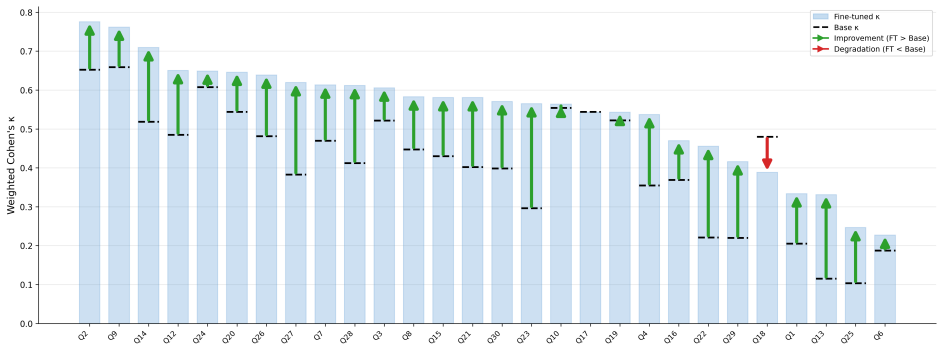
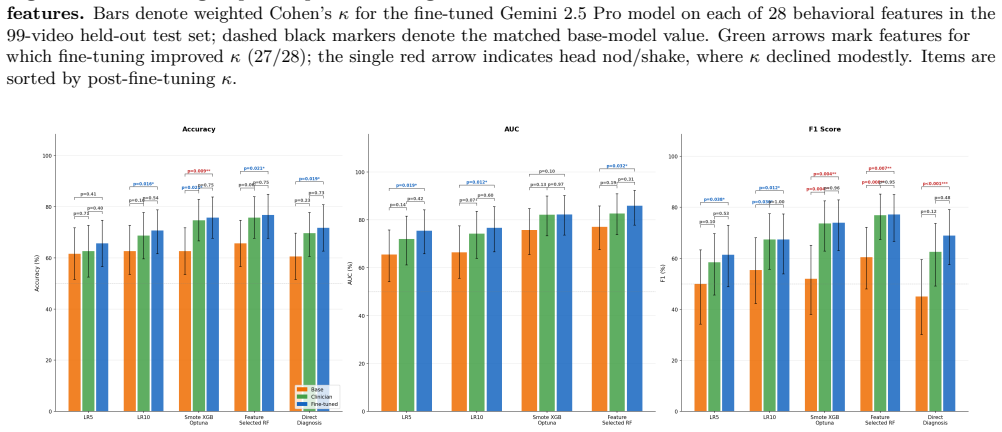
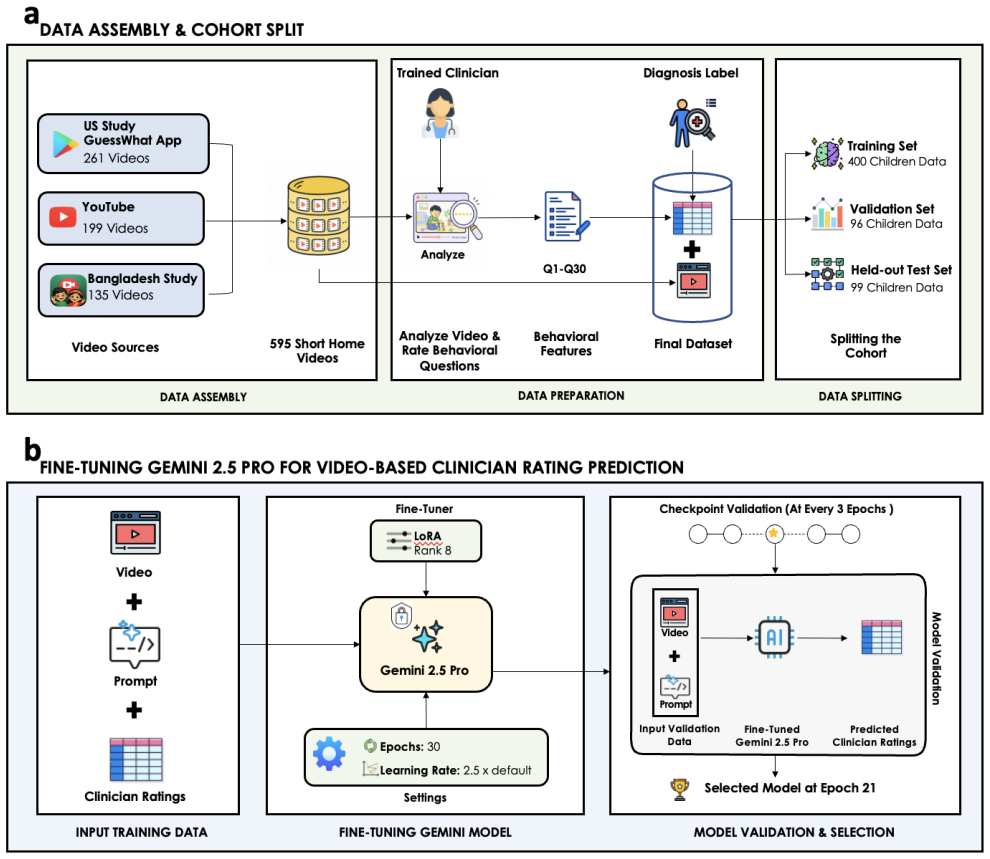
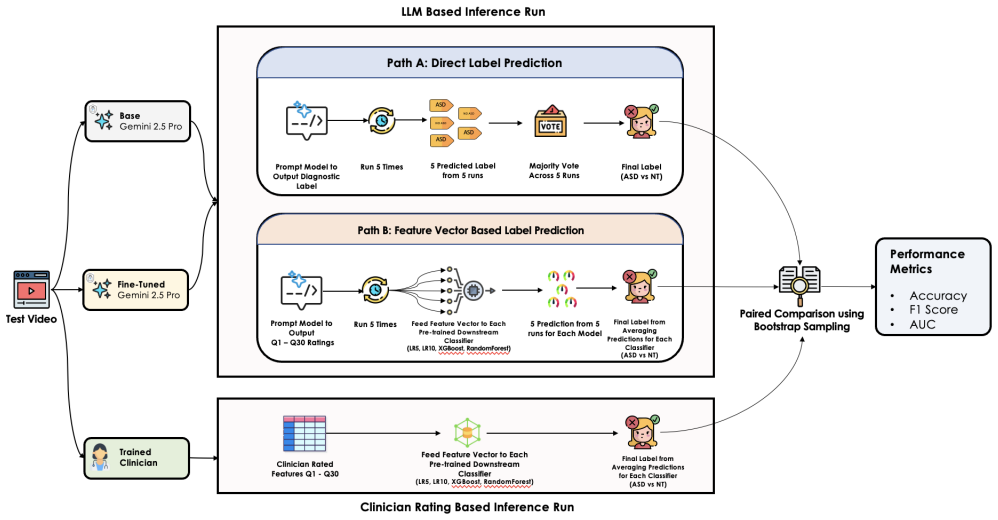
Autism spectrum disorder (ASD) affects 1 in 31 US children, yet median age at diagnosis exceeds four years. Artificial intelligence pipelines that provide quantified diagnosis using easy to access observational data (e.g., home videos) could help with earlier diagnosis, and timely delivery of early treatments. We fine-tuned Gemini 2.5 Pro on 400 clinician-rated home videos with low-rank adaptation, training only on 30 behavioral features previously validated to produce reliable predictions when passed to various ML models. On 99 held-out children (49 ASD, 50 neurotypical), inter-rater reliability with clinicians (per-feature weighted Cohen's kappa) improved by 40% (p<0.001), with 27 of 28 evaluable features improving. As an emergent zero-shot capability, direct ASD diagnosis F1 improved by 53% (p<0.001), matching or exceeding clinician outcomes. Classifier-assisted pipelines using fine-tuned LLM-derived behavioral features matched clinician-scored inputs across all tested pathways and achieved 77% accuracy (95% CI: 68-85%) and an AUC of 86% (95% CI: 78-92%). Fine-tuned multimodal LLMs can serve as scalable behavioral feature extractors for use in autism assessment and diagnosis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuning Gemini 2.5 Pro via LoRA on 400 clinician-rated home videos enables extraction of 30 previously validated behavioral features, yielding a 40% improvement in per-feature weighted Cohen's kappa (p<0.001) and 53% improvement in direct ASD diagnosis F1 (p<0.001) on a held-out set of 99 children (49 ASD, 50 neurotypical). Classifier-assisted pipelines using the LLM-derived features achieve 77% accuracy (95% CI 68-85%) and 86% AUC (95% CI 78-92%), supporting the claim that fine-tuned multimodal LLMs can serve as scalable behavioral feature extractors for autism assessment and diagnosis.
Significance. If the central empirical results hold under broader testing, the work could enable earlier, more accessible ASD diagnosis via short home videos, addressing the current median diagnosis age exceeding four years. Strengths include the use of previously validated features, statistically significant gains on a balanced held-out set, and demonstration of both feature-level reliability improvements and emergent diagnostic capability.
major comments (2)
- [held-out evaluation description] The held-out evaluation (99 children) uses videos drawn from the same single-site clinician-rated home-video distribution as the 400 training videos, with no cross-site, cross-device, or cross-demographic hold-out described. This is load-bearing for the scalability claim, as the reported 40% kappa lift and 77% accuracy could reflect capture of site-specific cues rather than robust extraction invariant to video quality or rater variability.
- [methods description] Full details on video acquisition protocols, exclusion criteria, exact LoRA hyperparameters, and precise definitions of how the 30 behavioral features are extracted by the fine-tuned model are absent. These omissions directly affect assessment of reproducibility and the validity of the p<0.001 significance claims on the 99-child test set.
minor comments (1)
- [abstract] The abstract states '27 of 28 evaluable features improving' without explaining the basis for excluding one feature from evaluation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on generalizability and reproducibility. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [held-out evaluation description] The held-out evaluation (99 children) uses videos drawn from the same single-site clinician-rated home-video distribution as the 400 training videos, with no cross-site, cross-device, or cross-demographic hold-out described. This is load-bearing for the scalability claim, as the reported 40% kappa lift and 77% accuracy could reflect capture of site-specific cues rather than robust extraction invariant to video quality or rater variability.
Authors: We agree that the held-out set is from the same single-site distribution and that this constrains claims of robustness to variations in site, device, or demographics. The reported gains are valid within the studied distribution, but we will revise the Methods to explicitly note the single-site origin and add a limitations section in the Discussion that qualifies the scalability claims and calls for future multi-site validation. revision: yes
-
Referee: [methods description] Full details on video acquisition protocols, exclusion criteria, exact LoRA hyperparameters, and precise definitions of how the 30 behavioral features are extracted by the fine-tuned model are absent. These omissions directly affect assessment of reproducibility and the validity of the p<0.001 significance claims on the 99-child test set.
Authors: We acknowledge these details are required for reproducibility. The revised manuscript will expand the Methods section with video acquisition protocols, exclusion criteria, full LoRA hyperparameters (rank, alpha, dropout), the prompting template and output parsing used for the 30 features, and a complete description of the statistical tests underlying the p-values. revision: yes
- Cross-site, cross-device, or cross-demographic hold-out evaluation, as this would require new data collection outside the current study.
Circularity Check
No significant circularity; results from empirical held-out evaluation
full rationale
The paper describes fine-tuning Gemini 2.5 Pro via LoRA on 400 videos using 30 pre-validated behavioral features, followed by evaluation on a separate 99-video held-out set. Performance metrics (kappa improvement, diagnosis F1, classifier accuracy) are measured directly against clinician ratings on unseen data. No equations, derivations, or self-referential definitions appear; the 30 features serve as fixed training targets rather than outputs redefined by the model. Prior validation of the features is cited but does not bear the load of the current claims, which rest on independent test-set comparison. This matches the default expectation of non-circular empirical ML work.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA adaptation parameters
axioms (1)
- domain assumption Clinician ratings on the 30 behavioral features are reliable and unbiased ground truth for training and evaluation.
Reference graph
Works this paper leans on
-
[1]
Kelly A Shaw. Prevalence and early identification of autism spectrum disorder among children aged 4 and 8 years—autism and developmental disabilities monitoring network, 16 sites, united states, 2022. MMWR. Surveillance Summaries, 74, 2025
2022
-
[2]
Evalua- tion of the diagnostic stability of the early autism spectrum disorder phenotype in the general pop- ulation starting at 12 months.JAMA pediatrics, 173(6):578–588, 2019
Karen Pierce, Vahid H Gazestani, Elizabeth Ba- con, Cynthia Carter Barnes, Debra Cha, Srinivasa Nalabolu, Linda Lopez, Adrienne Moore, Sunny Pence-Stophaeros, and Eric Courchesne. Evalua- tion of the diagnostic stability of the early autism spectrum disorder phenotype in the general pop- ulation starting at 12 months.JAMA pediatrics, 173(6):578–588, 2019
2019
-
[3]
First alarm and time of diagnosis in autism spectrum disorders.Comprehensive child and adolescent nursing, 45(1):75–91, 2022
Sotiria Mitroulaki, Aspasia Serdari, Gregory Trip- sianis, Ronnie Gundelfinger, Aikaterini Arvaniti, Theofanis Vorvolakos, and Maria Samakouri. First alarm and time of diagnosis in autism spectrum disorders.Comprehensive child and adolescent nursing, 45(1):75–91, 2022
2022
-
[4]
Early detection of autism using digital be- havioral phenotyping.Nature Medicine, 29(10): 2489–2497, 2023
Sam Perochon, J Matias Di Martino, Kim- berly LH Carpenter, Scott Compton, Naomi Davis, Brian Eichner, Steven Espinosa, Lauren Franz, Pradeep Raj Krishnappa Babu, Guillermo Sapiro, et al. Early detection of autism using digital be- havioral phenotyping.Nature Medicine, 29(10): 2489–2497, 2023
2023
-
[5]
The earlier the better: An rct of treatment timing ef- fects for toddlers on the autism spectrum.Autism, 27(8):2295–2309, 2023
Whitney Guthrie, Amy M Wetherby, Juliann Woods, Christopher Schatschneider, Renee D Hol- land, Lindee Morgan, and Catherine E Lord. The earlier the better: An rct of treatment timing ef- fects for toddlers on the autism spectrum.Autism, 27(8):2295–2309, 2023
2023
-
[6]
Early diagnosis of autism in the community is associated with marked improvement in social symptoms within 1–2 years.Autism, 26 (6):1353–1363, 2022
Nitzan Gabbay-Dizdar, Michal Ilan, Gal Meiri, Michal Faroy, Analya Michaelovski, Hagit Flusser, Idan Menashe, Judah Koller, Ditza A Zachor, and Ilan Dinstein. Early diagnosis of autism in the community is associated with marked improvement in social symptoms within 1–2 years.Autism, 26 (6):1353–1363, 2022
2022
-
[7]
Sara S Sparrow and Domenic V Cicchetti.The Vineland adaptive behavior scales.Allyn & Bacon, 1989
1989
-
[8]
Catherine Lord, Susan Risi, Linda Lambrecht, Ed- win H Cook Jr, Bennett L Leventhal, Pamela C DiLavore, Andrew Pickles, and Michael Rut- ter. The autism diagnostic observation sched- ule—generic: A standard measure of social and communication deficits associated with the spec- trum of autism.Journal of autism and develop- mental disorders, 30(3):205–223, 2000
2000
-
[9]
Autism screening and diagnosis in low resource settings: Challenges and opportunities to enhance research and services worldwide.Autism Research, 8(5): 473–476, 2015
Maureen S Durkin, Mayada Elsabbagh, Josephine Barbaro, Melissa Gladstone, Francesca Happe, Rosa A Hoekstra, Li-Ching Lee, Alexia Rattazzi, Jennifer Stapel-Wax, Wendy L Stone, et al. Autism screening and diagnosis in low resource settings: Challenges and opportunities to enhance research and services worldwide.Autism Research, 8(5): 473–476, 2015
2015
-
[10]
Responding to autism in low and middle income countries (lmic): what to do and what not to do.Brain sciences, 12(11):1475, 2022
Roy McConkey. Responding to autism in low and middle income countries (lmic): what to do and what not to do.Brain sciences, 12(11):1475, 2022
2022
-
[11]
A review of and roadmap for data science and machine learn- ing for the neuropsychiatric phenotype of autism
Peter Washington and Dennis P Wall. A review of and roadmap for data science and machine learn- ing for the neuropsychiatric phenotype of autism. Annual review of biomedical data science, 6(1):211– 228, 2023
2023
-
[12]
Mobile detection of autism through machine learning on home video: A de- velopment and prospective validation study.PLoS medicine, 15(11):e1002705, 2018
Qandeel Tariq, Jena Daniels, Jessey Nicole Schwartz, Peter Washington, Haik Kalantarian, and Dennis Paul Wall. Mobile detection of autism through machine learning on home video: A de- velopment and prospective validation study.PLoS medicine, 15(11):e1002705, 2018
2018
-
[13]
Qandeel Tariq, Scott Lanyon Fleming, Jessey Nicole Schwartz, Kaitlyn Dunlap, Conor Corbin, Peter Washington, Haik Kalantarian, Naila Z Khan, Gary L Darmstadt, and Den- nis Paul Wall. Detecting developmental delay and autism through machine learning models using home videos of bangladeshi children: development and validation study.Journal of medical Intern...
2019
-
[14]
Use of artifi- cial intelligence to shorten the behavioral diagnosis of autism
Dennis P Wall, Rebecca Dally, Rhiannon Luyster, Jae-Yoon Jung, and Todd F DeLuca. Use of artifi- cial intelligence to shorten the behavioral diagnosis of autism. 2012
2012
-
[15]
Searching for a minimal set of behaviors for autism detection through feature selection-based machine learning.Translational psychiatry, 5(2):e514–e514, 2015
JA Kosmicki, V Sochat, M Duda, and DP Wall. Searching for a minimal set of behaviors for autism detection through feature selection-based machine learning.Translational psychiatry, 5(2):e514–e514, 2015
2015
-
[16]
Sparsifying machine learning mod- els identify stable subsets of predictive features for behavioral detection of autism.Molecular autism, 8(1):65, 2017
Sebastien Levy, Marlena Duda, Nick Haber, and Dennis P Wall. Sparsifying machine learning mod- els identify stable subsets of predictive features for behavioral detection of autism.Molecular autism, 8(1):65, 2017
2017
-
[17]
Feature replacement methods en- able reliable home video analysis for machine learn- ing detection of autism.Scientific reports, 10(1): 21245, 2020
Emilie Leblanc, Peter Washington, Maya Varma, Kaitlyn Dunlap, Yordan Penev, Aaron Kline, and Dennis P Wall. Feature replacement methods en- able reliable home video analysis for machine learn- ing detection of autism.Scientific reports, 10(1): 21245, 2020
2020
-
[18]
Crowdsourced privacy- preserved feature tagging of short home videos for machine learning asd detection.Scientific reports, 11(1):7620, 2021
Peter Washington, Qandeel Tariq, Emilie Leblanc, Brianna Chrisman, Kaitlyn Dunlap, Aaron Kline, Haik Kalantarian, Yordan Penev, Kelley Paskov, Catalin Voss, et al. Crowdsourced privacy- preserved feature tagging of short home videos for machine learning asd detection.Scientific reports, 11(1):7620, 2021
2021
-
[19]
Crowd annotations can approxi- mate clinical autism impressions from short home videos with privacy protections.Intelligence-based medicine, 6:100056, 2022
Peter Washington, Brianna Chrisman, Emilie Leblanc, Kaitlyn Dunlap, Aaron Kline, Cezmi Mutlu, Nate Stockham, Kelley Paskov, and Den- nis Paul Wall. Crowd annotations can approxi- mate clinical autism impressions from short home videos with privacy protections.Intelligence-based medicine, 6:100056, 2022
2022
-
[20]
Us- ing 2d video-based pose estimation for automated prediction of autism spectrum disorders in young children.Scientific Reports, 11(1):15069, 2021
Nada Kojovic, Shreyasvi Natraj, Sharada Prasanna Mohanty, Thomas Maillart, and Marie Schaer. Us- ing 2d video-based pose estimation for automated prediction of autism spectrum disorders in young children.Scientific Reports, 11(1):15069, 2021
2021
-
[21]
Xiangxu Yu, Mindi Ruan, Chuanbo Hu, Wenqi Li, Lynn K Paul, Xin Li, and Shuo Wang. Video- based analysis reveals atypical social gaze in people with autism spectrum disorder.arXiv preprint arXiv:2409.00664, 2024
-
[22]
Marie Amale Huynh, Aaron Kline, Saimourya Surabhi, Kaitlyn Dunlap, Onur Cezmi Mutlu, Mo- hammadmahdi Honarmand, Parnian Azizian, Pe- ter Washington, and Dennis P. Wall. Ensem- ble modeling of multiple physical indicators to dynamically phenotype autism spectrum disor- der.Algorithms, 18(12), 2025. ISSN 1999-4893. doi: 10.3390/a18120764. URLhttps://www.mdp...
-
[23]
Early diagnostic value of home video– based machine learning in autism spectrum disor- der: a meta-analysis.European Journal of Pedi- atrics, 184(1):37, 2024
Longjie Jin, Hualei Cui, Peiyuan Zhang, and Chun- quan Cai. Early diagnostic value of home video– based machine learning in autism spectrum disor- der: a meta-analysis.European Journal of Pedi- atrics, 184(1):37, 2024
2024
-
[24]
An anal- ysis of the real world performance of an artifi- cial intelligence based autism diagnostic.Scien- tific reports, 15(1):29503, 2025
Carmela Salomon, Kelianne Heinz, Judith Aronson-Ramos, and Dennis P Wall. An anal- ysis of the real world performance of an artifi- cial intelligence based autism diagnostic.Scien- tific reports, 15(1):29503, 2025. doi: 10.1038/ s41598-025-15575-8
2025
-
[25]
Automated ai based identification of autism spectrum disorder from home videos.npj Digital Medicine, 8(1):607, 2025
Dong Yeong Kim, Ryemi Do, Youmin Shin, Hewoen Sim, Hanna Kim, Sungchul Cho, Geon- hee Lee, Seyeon Park, Boa Jang, Hyojeong Lim, et al. Automated ai based identification of autism spectrum disorder from home videos.npj Digital Medicine, 8(1):607, 2025
2025
-
[26]
Multimodal ai for risk stratification in autism spec- trum disorder: integrating voice and screening tools.NPJ digital medicine, 8(1):538, 2025
Sookyung Bae, Junho Hong, Sungji Ha, Jiwoo Moon, Jaeeun Yu, Hangnyoung Choi, Junghan Lee, Ryemi Do, Hewoen Sim, Hanna Kim, et al. Multimodal ai for risk stratification in autism spec- trum disorder: integrating voice and screening tools.NPJ digital medicine, 8(1):538, 2025
2025
-
[27]
Aiden Ko, Aaron Kline, Kaitlyn Dunlap, SaiMourya Surabhi, Parnian Azizian, Peter Y. Washington, and Dennis P. Wall.Abstention and Threshold Identification for Uncertainty Manage- ment in Clinical Decision Tools: A Case Study us- ing Human-In-The-Loop Pediatric Autism Classi- fiers, pages 114–129. doi: 10.1142/9789819824755_
-
[28]
URL https://www.worldscientific.com/ doi/abs/10.1142/9789819824755_0009
-
[29]
Classifying autism from crowdsourced semistructured speech recordings: machine learning model comparison study.JMIR pediatrics and parenting, 5(2):e35406, 2022
Nathan A Chi, Peter Washington, Aaron Kline, Arman Husic, Cathy Hou, Chloe He, Kaitlyn Dun- lap, and Dennis P Wall. Classifying autism from crowdsourced semistructured speech recordings: machine learning model comparison study.JMIR pediatrics and parenting, 5(2):e35406, 2022
2022
-
[30]
Advancing hu- man action recognition with foundation models trained on unlabeled public videos, 2024
Yang Qian, Yinan Sun, Ali Kargarandehkordi, Parnian Azizian, Onur Cezmi Mutlu, Saimourya Surabhi, Pingyi Chen, Zain Jabbar, Dennis Paul Wall, and Peter Washington. Advancing hu- man action recognition with foundation models trained on unlabeled public videos, 2024. URL https://arxiv.org/abs/2402.08875
-
[31]
Computer vision estimation of emotion reaction intensity in the wild, 2023
Yang Qian, Ali Kargarandehkordi, Onur Cezmi Mutlu, Saimourya Surabhi, Mohammadmahdi Honarmand, Dennis Paul Wall, and Peter Wash- ington. Computer vision estimation of emotion reaction intensity in the wild, 2023. URLhttps: //arxiv.org/abs/2303.10741
-
[32]
Hashtag2action: Data engi- neering and self-supervised pre-training for action recognition in short-form videos
Yang Qian, Ali Kargarandehkordi, Yinan Sun, Parnian Azizian, Onur Cezmi Mutlu, Saimourya Surabhi, Zain Jabbar, Dennis Wall, Peter Washing- ton, and Huaijin Chen. Hashtag2action: Data engi- neering and self-supervised pre-training for action recognition in short-form videos. InProceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV)...
2025
- [33]
-
[34]
Onur Cezmi Mutlu, Mohammadmahdi Honar- mand, Saimourya Surabhi, and Dennis P. Wall. Tempt: Temporal consistency for test-time adap- tation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 5917–5923, June 2023
2023
-
[35]
Selective test-time domain adap- tation using fisher information for robust facial expression recognition in-the-wild
Mohammadmahdi Honarmand, Onur Cezmi Mutlu, Parnian Azizian, Saimourya Surabhi, and Dennis Wall. Selective test-time domain adap- tation using fisher information for robust facial expression recognition in-the-wild. InProceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) Workshops, pages 5846–5856, June 2025
2025
-
[36]
Topology-guided test-time adapta- tion via persistent homology: From affective behav- ior analysis to autonomous driving
Onur Cezmi Mutlu, Mohammadmahdi Honar- mand, Parnian Azizian, Saimourya Surabhi, and Dennis P Wall. Topology-guided test-time adapta- tion via persistent homology: From affective behav- ior analysis to autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) Workshops, pages 5331–5340, June 2026
2026
-
[37]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: A family of highly capable multimodal models. arxiv 2023.arXiv preprint arXiv:2312.11805, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Gheorghe Comanici, Eric Bieber, Mike Schaek- ermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the fron- tier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Video-mme: The first-ever comprehensive eval- uation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive eval- uation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 24108–24118, 2025
2025
-
[41]
Mvbench: A comprehensive multi- modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi- modal video understanding benchmark. InPro- ceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 22195– 22206, 2024
2024
-
[42]
Video generation models: A survey of post- training and alignment.TechRxiv, 2026(0227),
Chaoyu Li, Xiaoyi Gu, Yogesh Kulkarni, Eun Woo Im, Mohammadmahdi Honarmand, Zeyu Wang, Juntong Song, Fei Du, Xilin Jiang, Kexin Zheng, Tianzhi Li, Fei Tao, and Pooyan Fa- zli. Video generation models: A survey of post- training and alignment.TechRxiv, 2026(0227),
2026
-
[43]
URL https://www.techrxiv.org/doi/abs/ 10.36227/techrxiv.177220111.17351887/v1
doi: 10.36227/techrxiv.177220111.17351887/ v1. URL https://www.techrxiv.org/doi/abs/ 10.36227/techrxiv.177220111.17351887/v1
-
[44]
Capabilities of Gemini Models in Medicine
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, et al. Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Advancing multimodal medical capabilities of gemini
Lin Yang, Shawn Xu, Andrew Sellergren, Timo Kohlberger, Yuchen Zhou, Ira Ktena, Atilla Kiraly, Faruk Ahmed, Farhad Hormozdiari, Tiam Jaroen- sri, et al. Advancing multimodal medical capabil- ities of gemini.arXiv preprint arXiv:2405.03162, 2024
-
[46]
Towards generalist biomedical ai
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al. Towards generalist biomedical ai. Nejm Ai, 1(3):AIoa2300138, 2024
2024
-
[47]
Llava- med: Training a large language-and-vision assis- tantforbiomedicineinoneday.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Nau- mann, Hoifung Poon, and Jianfeng Gao. Llava- med: Training a large language-and-vision assis- tantforbiomedicineinoneday.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
2023
-
[48]
Towards injecting medical visual knowledge into multimodal llms at scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, et al. Towards injecting medical visual knowledge into multimodal llms at scale. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7346–7370, 2024
2024
-
[49]
Jiajie Li, Garrett Skinner, Gene Yang, Brian R Quaranto, Steven D Schwaitzberg, Peter CW Kim, and Jinjun Xiong. Llava-surg: towards multi- modal surgical assistant via structured surgical video learning.arXiv preprint arXiv:2408.07981, 2024
-
[50]
Juseong Jin and Chang Wook Jeong. Surgical- llava: Toward surgical scenario understanding via large language and vision models.arXiv preprint arXiv:2410.09750, 2024
-
[51]
VidLPRO: A 12 video-language pre-training framework for robotic and laparoscopic surgery
Mohammadmahdi Honarmand, Muhammad Ab- dullah Jamal, and Omid Mohareri. VidLPRO: A 12 video-language pre-training framework for robotic and laparoscopic surgery. InAdvancements In Medical Foundation Models: Explainability, Ro- bustness, Security, and Beyond, 2024. URLhttps: //openreview.net/forum?id=xdpOaTjOdR
2024
-
[52]
Chenyu Lian, Hong-Yu Zhou, Yizhou Yu, and Liansheng Wang. Less could be better: Parameter- efficient fine-tuning advances medical vision foun- dation models.arXiv preprint arXiv:2401.12215, 2024
-
[53]
Tianyu Zhou, Junyi Tang, Zehui Li, Dahong Qian, and Suncheng Xiang. Ldp: Parameter-efficient fine-tuning of multimodal llm for medical report generation.arXiv preprint arXiv:2512.10750, 2025
-
[54]
Large language models deconstruct the clinical intuition behind diagnosing autism.Cell, 188(8): 2235–2248, 2025
Jack Stanley, Emmett Rabot, Siva Reddy, Eugene Belilovsky, Laurent Mottron, and Danilo Bzdok. Large language models deconstruct the clinical intuition behind diagnosing autism.Cell, 188(8): 2235–2248, 2025
2025
-
[55]
Aiding large language models using clinical scoresheets for neurobehavioral diag- nostic classification from text: Algorithm develop- ment and validation.JMIR AI, 4:e75030, 2025
Kaiying Lin, Abdur Rasool, Saimourya Surabhi, Cezmi Mutlu, Haopeng Zhang, Dennis P Wall, and Peter Washington. Aiding large language models using clinical scoresheets for neurobehavioral diag- nostic classification from text: Algorithm develop- ment and validation.JMIR AI, 4:e75030, 2025
2025
-
[56]
Exploiting large language models for diag- nosing autism associated language disorders and identifying distinct features.NPJ Digital Medicine, 8(1):763, 2025
Chuanbo Hu, Wenqi Li, Mindi Ruan, Xiangxu Yu, Shalaka Deshpande, Lynn K Paul, Shuo Wang, and Xin Li. Exploiting large language models for diag- nosing autism associated language disorders and identifying distinct features.NPJ Digital Medicine, 8(1):763, 2025
2025
-
[57]
Ex- ploiting chatgpt for diagnosing autism-associated language disorders and identifying distinct features
Chuanbo Hu, Wenqi Li, Mindi Ruan, Xiangxu Yu, Lynn K Paul, Shuo Wang, and Xin Li. Ex- ploiting chatgpt for diagnosing autism-associated language disorders and identifying distinct features. Research Square, pages rs–3, 2024
2024
-
[58]
Multimodal llm vs
Parnian Azizian, Mohammadmahdi Honarmand, Aditi Jaiswal, Aaron Kline, Kaitlyn Dunlap, Peter Washington, and Dennis P Wall. Multimodal llm vs. human-measured features for ai predictions of autism in home videos.Algorithms, 18(11):687, 2025
2025
-
[59]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URL https:// arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[60]
Guess what? towards understanding autism from structured video using facial affect
Haik Kalantarian, Peter Washington, Jessey Schwartz, Jena Daniels, Nick Haber, and Den- nis P Wall. Guess what? towards understanding autism from structured video using facial affect. Journal of healthcare informatics research, 3(1): 43–66, 2019. 13
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.