MemoBench: Benchmarking World Modeling in Dynamically Changing Environments
Pith reviewed 2026-06-29 02:00 UTC · model grok-4.3
The pith
MemoBench introduces a benchmark to evaluate how video generation models maintain memory consistency for objects that disappear and reappear amid dynamic changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemoBench is a benchmark built around the disappear-and-reappear paradigm in dynamically changing environments, where a target object undergoes a physical process, disappears, and must be recovered in its updated state. It consists of 360 ground-truth clips and an evaluation suite with automated metrics and VQA-based assessment across four diagnostic pillars. Evaluation of eight state-of-the-art models shows key insights and open challenges in memory consistency under this paradigm.
What carries the argument
MemoBench, the diagnostic benchmark using the disappear-and-reappear paradigm to test memory consistency in dynamic scenes.
If this is right
- Current video generation models exhibit limitations in maintaining memory consistency when objects disappear and reappear in changing environments.
- The four diagnostic pillars provide structured ways to assess different aspects of world modeling.
- Automated metrics combined with VQA offer a scalable evaluation method for such benchmarks.
- Insights from the evaluation point to specific open challenges that future models need to address.
Where Pith is reading between the lines
- Adopting this benchmark could drive development of models better at simulating physical continuity.
- Similar paradigms might apply to other AI domains like robotics planning or autonomous driving.
- Extensions could include more complex interactions or longer sequences to test deeper memory.
Load-bearing premise
The 360 curated clips and four diagnostic pillars form a representative test of world modeling in dynamically changing environments.
What would settle it
A video generation model that scores highly on all four pillars of MemoBench by correctly recovering updated object states after disappearance would challenge the revealed challenges.
Figures

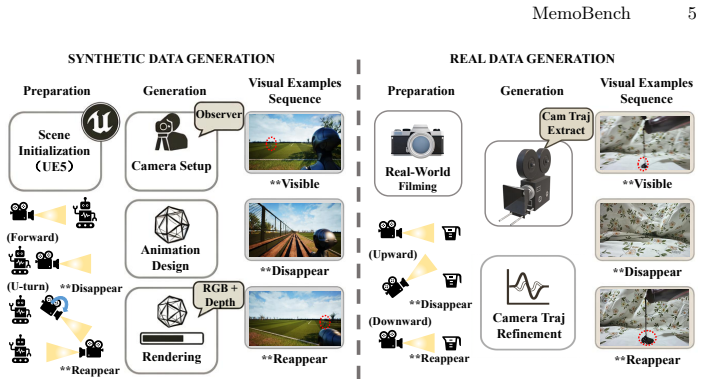
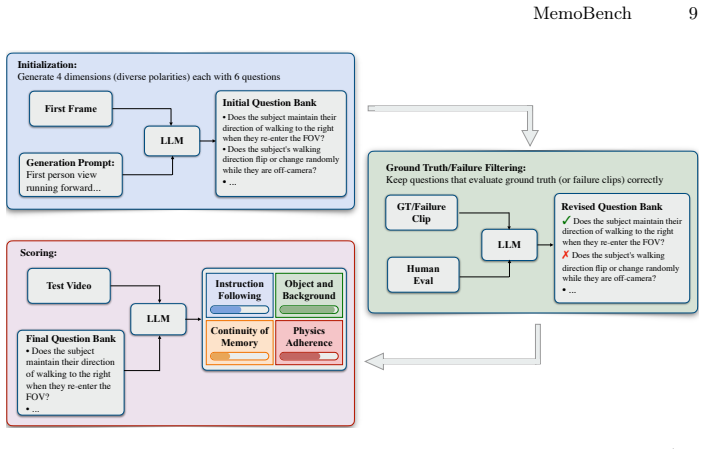
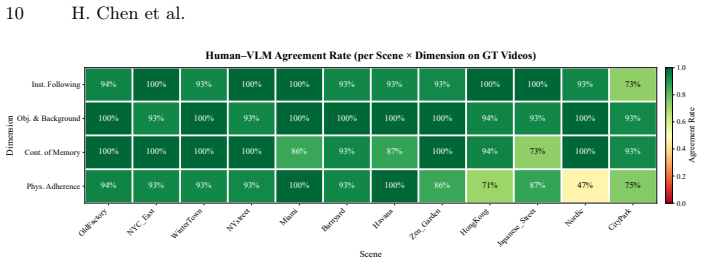



read the original abstract
Video generation models aspire to simulate dynamic environments, and several benchmarks now evaluate memory consistency across frames. However, most assess consistency only while the target remains in view, and the few that force objects out of view evaluate static scenes where nothing changes during occlusion. To bridge this gap, we introduce MemoBench, a diagnostic benchmark built around the disappear-and-reappear paradigm in dynamically changing environments: a target object undergoes a physical process, disappears from view, and must be correctly recovered in its updated state upon reappearance. We curate 360 ground-truth clips spanning synthetic and real-world scenes, and design an evaluation suite combining automated metrics with VQA-based assessment across four diagnostic pillars. Evaluation of eight state-of-the-art models reveals key insights and open challenges regarding memory consistency under the disappear-and-reappear paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemoBench, a diagnostic benchmark for video generation models that evaluates memory consistency under the disappear-and-reappear paradigm in dynamically changing environments. A target object undergoes a physical process, disappears from view, and must be recovered in its updated state upon reappearance. The benchmark comprises 360 ground-truth clips spanning synthetic and real-world scenes, with an evaluation suite that combines automated metrics and VQA-based assessment across four diagnostic pillars. Evaluation of eight state-of-the-art models is used to surface key insights and open challenges regarding memory consistency.
Significance. If the curation and evaluation protocols hold, MemoBench would address a clear gap in existing benchmarks, which either keep targets in view or use static scenes during occlusion. The focus on dynamic physical processes during disappear-and-reappear, combined with mixed automated/VQA metrics and both synthetic/real clips, could provide actionable diagnostics for world-modeling capabilities. The explicit evaluation of eight models already yields concrete observations that could inform model development.
major comments (2)
- [§3] §3 (Benchmark Construction): The claim that the 360 clips form a representative test of dynamically changing environments requires explicit justification of the selection criteria for physical processes, scene complexity, and occlusion durations; without these, it is unclear whether the reported model failures generalize beyond the chosen set.
- [§4] §4 (Evaluation Suite): The four diagnostic pillars and the precise definitions of the automated metrics versus VQA questions are load-bearing for the central claim that the benchmark is diagnostic; the manuscript must specify how each pillar isolates memory consistency from other failure modes such as generation quality or prompt adherence.
minor comments (2)
- [Table 1, Figure 2] Table 1 and Figure 2: axis labels and legend entries should explicitly state the metric ranges and whether higher/lower is better to avoid ambiguity when comparing the eight models.
- [§5] §5 (Results): The discussion of 'key insights' would benefit from quantitative effect sizes or statistical significance tests rather than qualitative descriptions of model behavior.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment point by point below, with commitments to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The claim that the 360 clips form a representative test of dynamically changing environments requires explicit justification of the selection criteria for physical processes, scene complexity, and occlusion durations; without these, it is unclear whether the reported model failures generalize beyond the chosen set.
Authors: We agree that an explicit justification of selection criteria is required to support claims of representativeness. In the revised manuscript we will add a dedicated paragraph in §3 that details the criteria: physical processes were chosen to span common state-changing phenomena (melting, freezing, deformation, color shift, growth/shrinkage) drawn from everyday dynamics; scene complexity was balanced across synthetic (fully controllable) and real-world (varied lighting, backgrounds) clips; and occlusion durations were sampled uniformly from 3–15 seconds to probe both short- and longer-term memory. These choices were made to maximize diagnostic coverage while remaining feasible for accurate ground-truth annotation. The added text will clarify the intended scope and limits of generalization. revision: yes
-
Referee: [§4] §4 (Evaluation Suite): The four diagnostic pillars and the precise definitions of the automated metrics versus VQA questions are load-bearing for the central claim that the benchmark is diagnostic; the manuscript must specify how each pillar isolates memory consistency from other failure modes such as generation quality or prompt adherence.
Authors: We concur that the isolation mechanisms must be stated explicitly. The four pillars are defined as follows: Pillar 1 (State Consistency) uses an automated IoU-based metric on segmented object state before vs. after reappearance, with a separate generation-quality score to factor out low-fidelity synthesis; Pillar 2 (Temporal Coherence) employs VQA questions on frame-to-frame consistency while holding the text prompt fixed across all models; Pillar 3 (Occlusion Handling) measures disappearance/reappearance fidelity via automated tracking metrics independent of prompt following; Pillar 4 (Dynamic Update) uses targeted VQA to check whether the change occurring during occlusion is reflected, again with fixed prompts. We will expand §4 with these explicit isolation statements and precise metric/VQA definitions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs a benchmark (MemoBench) consisting of 360 curated clips and four diagnostic pillars, then evaluates eight external state-of-the-art models using automated metrics and VQA. No derivation chain, equations, fitted parameters, or predictions exist that could reduce to inputs by construction. All claims rest on explicit curation of ground-truth clips and direct comparison to independent models, rendering the work self-contained with no load-bearing self-citations or self-definitional steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.03520 (2024) 2, 3
Bansal, H., Lin, Z., Xie, T., Zong, Z., Yarom, M., Bitton, Y., Jiang, C., Sun, Y., Chang, K.W., Grover, A.: Videophy: Evaluating physical commonsense for video generation. arXiv preprint arXiv:2406.03520 (2024) 2, 3
Pith/arXiv arXiv 2024
-
[2]
arXiv preprint arXiv:2503.06800 (2025) 3, 4
Bansal, H., Peng, C., Bitton, Y., Goldenberg, R., Grover, A., Chang, K.W.: Videophy-2: A challenging action-centric physical commonsense evaluation in video generation. arXiv preprint arXiv:2503.06800 (2025) 3, 4
arXiv 2025
-
[3]
arXiv preprint arXiv:2511.16719 (2025) 7
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025) 7
Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2310.19512 (2023) 3
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512 (2023) 3
Pith/arXiv arXiv 2023
-
[5]
In: CVPR (2024) 3
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion models. In: CVPR (2024) 3
2024
-
[6]
arXiv preprint arXiv:2304.14404 (2023) 3
Chen, T.S., Lin, C.H., Tseng, H.Y., Lin, T.Y., Yang, M.H.: Motion-conditioned diffusion model for controllable video synthesis. arXiv preprint arXiv:2304.14404 (2023) 3
arXiv 2023
-
[7]
In: ICLR (2023) 3
Chen, X., Wang, Y., Zhang, L., Zhuang, S., Ma, X., Yu, J., Wang, Y., Lin, D., Qiao, Y., Liu, Z.: Seine: Short-to-long video diffusion model for generative transition and prediction. In: ICLR (2023) 3
2023
-
[8]
arXiv preprint arXiv:2509.21657 (2025) 3, 10, 11, 14, S2, S3
Dai, Y., Jiang, F., Wang, C., Xu, M., Qi, Y.: Fantasyworld: Geometry- consistent world modeling via unified video and 3d prediction. arXiv preprint arXiv:2509.21657 (2025) 3, 10, 11, 14, S2, S3
arXiv 2025
-
[9]
arXiv preprint arXiv:2504.00983 (2025) 2, 3, 4
Duan, H., Yu, H.X., Chen, S., Fei-Fei, L., Wu, J.: Worldscore: A unified evaluation benchmark for world generation. arXiv preprint arXiv:2504.00983 (2025) 2, 3, 4
arXiv 2025
-
[10]
Feng, Y., Li, Y., Liu, C., Chen, Y., Jiang, F., Huang, Y., Hua, H., Yuan, Z., Zheng, K., Niu, L., et al.: Visual aesthetic benchmark: Can frontier models judge beauty? arXiv preprint arXiv:2605.12684 (2026) 8
Pith/arXiv arXiv 2026
-
[11]
In: CVPR (2026) 3
Ge, X., Pan, Y., Zhang, Y., Li, X., Zhang, W., Zhang, D., Wan, Z., Lin, X., Zhang, X., Liang, J., et al.: Airsim360: A panoramic simulation platform within drone view. In: CVPR (2026) 3
2026
-
[12]
Google: Gemini 3.1 pro (2026),https://blog.google/innovation- and- ai/ models- and- research/gemini- models/gemini- 3- 1- pro/, accessed: 2026-03-02 8
2026
-
[13]
arXiv preprint arXiv:1803.10122 (2018) 1, 3
Ha, D., Schmidhuber, J.: World models. arXiv preprint arXiv:1803.10122 (2018) 1, 3
Pith/arXiv arXiv 2018
-
[14]
arXiv preprint arXiv:2501.00103 (2024) 3, 10, 11, 14, S2, S3
HaCohen, Y., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., et al.: Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103 (2024) 3, 10, 11, 14, S2, S3
Pith/arXiv arXiv 2024
-
[15]
arXiv preprint arXiv:2301.04104 (2023) 1, 3
Hafner, D., Pasukonis, J., Ba, J., Lillicrap, T.: Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104 (2023) 1, 3
Pith/arXiv arXiv 2023
-
[16]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024) 3
Pith/arXiv arXiv 2024
-
[17]
arXiv preprint arXiv:2508.13009 (2025) 10, 11, 14, S2, S3 MemoBench 17
He, X., Peng, C., Liu, Z., Wang, B., Zhang, Y., Cui, Q., Kang, F., Jiang, B., An, M., Ren, Y., et al.: Matrix-game 2.0: An open-source real-time and streaming interactive world model. arXiv preprint arXiv:2508.13009 (2025) 10, 11, 14, S2, S3 MemoBench 17
Pith/arXiv arXiv 2025
-
[18]
arXiv preprint arXiv:2211.13221 (2022) 3
He, Y., Yang, T., Zhang, Y., Shan, Y., Chen, Q.: Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:2211.13221 (2022) 3
Pith/arXiv arXiv 2022
-
[19]
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Adv. Neural Inform. Process. Syst. (2022) 3
2022
-
[20]
Hore, A., Ziou, D.: Image quality metrics: Psnr vs. ssim. In: ICPR (2010) 8
2010
-
[21]
In: CVPR (2023) 8
Hu, Y., Hua, H., Yang, Z., Shi, W., Smith, N.A., Luo, J.: Promptcap: Prompt- guided image captioning for vqa with gpt-3. In: CVPR (2023) 8
2023
-
[22]
In: CVPR (2023) 8
Hu, Y., Liu, B., Kasai, J., Wang, Y., Ostendorf, M., Krishna, R., Smith, N.A.: Tifa: Accurate and interpretable text-to-image faithfulness evaluation with ques- tion answering. In: CVPR (2023) 8
2023
-
[23]
In: ECCV (2024) 8
Hua, H., Shi, J., Kafle, K., Jenni, S., Zhang, D., Collomosse, J., Cohen, S., Luo, J.: Finematch: Aspect-based fine-grained image and text mismatch detection and correction. In: ECCV (2024) 8
2024
-
[24]
arXiv preprint arXiv:2410.09733 (2024) 8
Hua, H., Tang, Y., Zeng, Z., Cao, L., Yang, Z., He, H., Xu, C., Luo, J.: Mmcompo- sition: Revisiting the compositionality of pre-trained vision-language models. arXiv preprint arXiv:2410.09733 (2024) 8
arXiv 2024
-
[25]
arXiv preprint arXiv:2505.19415 (2025) 8
Hua, H., Zeng, Z., Song, Y., Tang, Y., He, L., Aliaga, D., Xiong, W., Luo, J.: Mmig-bench: Towards comprehensive and explainable evaluation of multi-modal image generation models. arXiv preprint arXiv:2505.19415 (2025) 8
arXiv 2025
-
[26]
In: CVPR (2024) 2, 3, 4, 6
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video genera- tive models. In: CVPR (2024) 2, 3, 4, 6
2024
-
[27]
arXiv preprint (2025) 3, 10, 11, 14, S2, S3
HunyuanWorld, T.: Hy-world 1.5: A systematic framework for interactive world modeling with real-time latency and geometric consistency. arXiv preprint (2025) 3, 10, 11, 14, S2, S3
2025
-
[28]
arXiv preprint arXiv:2411.02385 (2024) 3
Kang, B.,Yue,Y.,Lu, R.,Lin, Z.,Zhao,Y., Wang, K.,Huang,G., Feng,J.: Howfar is video generation from world model: A physical law perspective. arXiv preprint arXiv:2411.02385 (2024) 3
Pith/arXiv arXiv 2024
-
[29]
arXiv preprint arXiv:2509.13414 (2025) 5, 8
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., et al.: Mapanything: Univer- sal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414 (2025) 5, 8
Pith/arXiv arXiv 2025
-
[30]
Kuaishou: Kling (2024),https://kling.kuaishou.com/en, accessed: 2026-03-01 3
2024
-
[31]
arXiv preprint arXiv:2502.20694 (2025) 2, 3, 4
Li, D., Fang, Y., Chen, Y., Yang, S., Cao, S., Wong, J., Luo, M., Wang, X., Yin, H., Gonzalez, J.E., et al.: Worldmodelbench: Judging video generation models as world models. arXiv preprint arXiv:2502.20694 (2025) 2, 3, 4
arXiv 2025
-
[32]
arXiv preprint arXiv:2506.17201 (2025) 3, 10, 11, 14, S2, S3
Li, J., Tang, J., Xu, Z., Wu, L., Zhou, Y., Shao, S., Yu, T., Cao, Z., Lu, Q.: Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition. arXiv preprint arXiv:2506.17201 (2025) 3, 10, 11, 14, S2, S3
arXiv 2025
-
[33]
arXiv preprint arXiv:2601.03444 (2026) 8
Li, W., Zhao, M., Dong, W., Cai, J., Wei, Y., Pocress, M., Li, Y., Yuan, W., Wang, X., Hou, R., et al.: Grading scale impact on llm-as-a-judge: Human-llm alignment is highest on 0-5 grading scale. arXiv preprint arXiv:2601.03444 (2026) 8
arXiv 2026
-
[34]
Authorea Preprints (2026) 3
Li, Y., Meng, S., Yang, C., Feng, W., Liu, J., An, Z., Wang, Y., Tian, Y.: A comprehensive survey of interaction techniques in 3d scene generation. Authorea Preprints (2026) 3
2026
-
[35]
arXiv preprint arXiv:2601.01075 (2026) 2 18 H
Lillemark, H.J., Huang, B., Zhan, F., Du, Y., Keller, T.A.: Flow equivariant world models: Memory for partially observed dynamic environments. arXiv preprint arXiv:2601.01075 (2026) 2 18 H. Chen et al
Pith/arXiv arXiv 2026
-
[36]
arXiv preprint arXiv:2412.00131 (2024) 3
Lin, B., Ge, Y., Cheng, X., Li, Z., Zhu, B., Wang, S., He, X., Ye, Y., Yuan, S., Chen, L., et al.: Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131 (2024) 3
Pith/arXiv arXiv 2024
-
[37]
In: CVPR (2026) 3
Lin, X., Song, M., Zhang, D., Lu, W., Li, H., Du, B., Yang, M.H., Nguyen, T., Qi, L.: Depth any panoramas: A foundation model for panoramic depth estimation. In: CVPR (2026) 3
2026
-
[38]
arXiv preprint arXiv:2404.01291 (2024) 8
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., Ramanan, D.: Evaluating text-to-visual generation with image-to-text generation. arXiv preprint arXiv:2404.01291 (2024) 8
arXiv 2024
-
[39]
arXiv preprint arXiv:2603.06022 (2026) 3
Liu, C., Wang, X., Lin, Q., Xiao, A., Chen, H., Wen, S., Zhang, H., Qi, L., Yang, M.H., Jeni, L.A., et al.: Mosiv: Multi-object system identification from videos. arXiv preprint arXiv:2603.06022 (2026) 3
arXiv 2026
-
[40]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026) 3
Liu,M.,Liu,J.,Zhang,Y.,Li,J.,Yang,M.Y.,Nex,F.,Cheng,H.:4dstr:Advancing generative 4d gaussians with spatial-temporal rectification for high-quality and consistent 4d generation. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026) 3
2026
-
[41]
arXiv preprint arXiv:2604.04198 (2026) 3
Liu, M., Zhang, D., Liu, J., Cui, J., Xie, H., Chen, G., Ye, H., Yang, M.Y., Nex, F., Cheng, H.: Driveva: Video action models are zero-shot drivers. arXiv preprint arXiv:2604.04198 (2026) 3
Pith/arXiv arXiv 2026
-
[42]
arXiv preprint arXiv:2402.008271(2024) 3
Liu, P., Song, L., Zhang, D., Hua, H., Tang, Y., Tu, H., Luo, J., Xu, C.: Emo- avatar: Efficient monocular video style avatar through texture rendering. arXiv preprint arXiv:2402.008271(2024) 3
arXiv 2024
-
[43]
Liu, Y., Li, L., Ren, S., Gao, R., Li, S., Chen, S., Sun, X., Hou, L.: Fetv: A benchmark for fine-grained evaluation of open-domain text-to-video generation. Adv. Neural Inform. Process. Syst. (2023) 3
2023
-
[44]
arXiv preprint arXiv:2603.30045 (2026) 3
Liu, Y., Lin, X., Li, X., Yang, B., Wang, C., Sunkavalli, K., Hold-Geoffroy, Y., Tan, H., Zhang, K., Xie, X., et al.: Omniroam: World wandering via long-horizon panoramic video generation. arXiv preprint arXiv:2603.30045 (2026) 3
arXiv 2026
-
[45]
Luma AI: Luma dream machine (2024),https://lumalabs.ai/dream-machine, accessed: 2026-03-01 3
2024
-
[46]
arXiv preprint arXiv:2303.08320 (2023) 3
Luo, Z., Chen, D., Zhang, Y., Huang, Y., Wang, L., Shen, Y., Zhao, D., Zhou, J., Tan, T.: Videofusion: Decomposed diffusion models for high-quality video genera- tion. arXiv preprint arXiv:2303.08320 (2023) 3
arXiv 2023
-
[47]
In: ICCV (2025) 8
Ma, W., Chen, H., Zhang, G., Chou, Y.C., Chen, J., de Melo, C., Yuille, A.: 3dsrbench: A comprehensive 3d spatial reasoning benchmark. In: ICCV (2025) 8
2025
-
[48]
OpenAI: Sora (2024),https://openai.com/index/sora/, accessed: 2026-03-01 3
2024
-
[49]
OpenAI: Sora2 (2025),https://openai.com/index/sora-2/, accessed: 2026-03-01 3
2025
-
[50]
arXiv preprint arXiv:2304.07193 (2023) 6
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 6
Pith/arXiv arXiv 2023
-
[51]
arXiv preprint arXiv:2503.09642 (2025) 1, 3, 10, 11, 14, S2, S3
Peng, X., Zheng, Z., Shen, C., Young, T., Guo, X., Wang, B., Xu, H., Liu, H., Jiang, M., Li, W., et al.: Open-sora 2.0: Training a commercial-level video generation model in 200 k. arXiv preprint arXiv:2503.09642 (2025) 1, 3, 10, 11, 14, S2, S3
Pith/arXiv arXiv 2025
-
[52]
arXiv preprint arXiv:2410.18072 (2024) 3, 4
Qin, Y., Shi, Z., Yu, J., Wang, X., Zhou, E., Li, L., Yin, Z., Liu, X., Sheng, L., Shao, J., et al.: Worldsimbench: Towards video generation models as world simulators. arXiv preprint arXiv:2410.18072 (2024) 3, 4
arXiv 2024
-
[53]
com / research / introducing-gen-3-alpha, accessed: 2026-03-01 3 MemoBench 19
Runway ML: Gen-3 alpha (2024),https : / / runwayml . com / research / introducing-gen-3-alpha, accessed: 2026-03-01 3 MemoBench 19
2024
-
[54]
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Adv. Neural Inform. Process. Syst. (2022) 6
2022
-
[55]
arXiv preprint arXiv:2209.14792 (2022) 3
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make-a-video: Text-to-video generation without text- video data. arXiv preprint arXiv:2209.14792 (2022) 3
Pith/arXiv arXiv 2022
-
[56]
In: CVPR (2025) 3
Sun, K., Huang, K., Liu, X., Wu, Y., Xu, Z., Li, Z., Liu, X.: T2v-compbench: A comprehensive benchmark for compositional text-to-video generation. In: CVPR (2025) 3
2025
-
[57]
arXiv preprint arXiv:2601.20540 (2026) 1, 3, 10, 11, 14, S2
Team, R., Gao, Z., Wang, Q., Zeng, Y., Zhu, J., Cheng, K.L., Li, Y., Wang, H., Xu, Y., Ma, S., Chen, Y., Liu, J., Cheng, Y., Yao, Y., Zhu, J., Meng, Y., Zheng, K., Bai, Q., Chen, J., Shen, Z., Yu, Y., Zhu, X., Shen, Y., Ouyang, H.: Advancing open-source world models. arXiv preprint arXiv:2601.20540 (2026) 1, 3, 10, 11, 14, S2
Pith/arXiv arXiv 2026
-
[58]
In: ECCV (2020) 6
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: ECCV (2020) 6
2020
-
[59]
In: ECCV (2024) 3
Voleti, V., Yao, C.H., Boss, M., Letts, A., Pankratz, D., Tochilkin, D., Laforte, C., Rombach, R., Jampani, V.: Sv3d: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion. In: ECCV (2024) 3
2024
-
[60]
arXiv preprint arXiv:2503.20314 (2025) 3, 10, 11, 14, S2
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 3, 10, 11, 14, S2
Pith/arXiv arXiv 2025
-
[61]
arXiv preprint arXiv:2605.13169 (2026) 8
Wang, C., Lin, X., Liu, J., Liu, Y., Wang, Z., Qi, D., Yan, Y., Chen, X.: PanoWorld: Towards spatial supersensing in 360-degree panorama world. arXiv preprint arXiv:2605.13169 (2026) 8
Pith/arXiv arXiv 2026
-
[62]
In: AAAI (2023) 6
Wang, J., Chan, K.C., Loy, C.C.: Exploring clip for assessing the look and feel of images. In: AAAI (2023) 6
2023
-
[63]
arXiv preprint arXiv:2308.06571 (2023) 3
Wang, J., Yuan, H., Chen, D., Zhang, Y., Wang, X., Zhang, S.: Modelscope text- to-video technical report. arXiv preprint arXiv:2308.06571 (2023) 3
Pith/arXiv arXiv 2023
-
[64]
arXiv preprint arXiv:2506.19291 (2025) 3
Wang, X., Zhao, Y., Ye, B., Shan, X., Lyu, W., Qi, L., Chan, K.C., Li, Y., Yang, M.H.: Holigs: Holistic gaussian splatting for embodied view synthesis. arXiv preprint arXiv:2506.19291 (2025) 3
arXiv 2025
-
[65]
IJCV (2025) 3
Wang, Y., Chen, X., Ma, X., Zhou, S., Huang, Z., Wang, Y., Yang, C., He, Y., Yu, J., Yang, P., et al.: Lavie: High-quality video generation with cascaded latent diffusion models. IJCV (2025) 3
2025
-
[66]
IEEE TIP (2004) 8
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE TIP (2004) 8
2004
-
[67]
In: SIGGRAPH (2024) 3
Wang,Z.,Yuan,Z.,Wang,X.,Li,Y.,Chen,T.,Xia,M.,Luo,P.,Shan,Y.:Motionc- trl: A unified and flexible motion controller for video generation. In: SIGGRAPH (2024) 3
2024
-
[68]
arXiv preprint arXiv:2406.09455 (2024) 3
Xiang, J., Liu, G., Gu, Y., Gao, Q., Ning, Y., Zha, Y., Feng, Z., Tao, T., Hao, S., Shi, Y., et al.: Pandora: Towards general world model with natural language actions and video states. arXiv preprint arXiv:2406.09455 (2024) 3
arXiv 2024
-
[69]
In: ECCV (2024) 3
Xing,J.,Xia,M.,Zhang,Y.,Chen,H.,Yu,W.,Liu,H.,Liu,G.,Wang,X.,Shan,Y., Wong, T.T.: Dynamicrafter: Animating open-domain images with video diffusion priors. In: ECCV (2024) 3
2024
-
[70]
arXiv preprint arXiv:2406.02509 (2024) 3 20 H
Xu, D., Nie, W., Liu, C., Liu, S., Kautz, J., Wang, Z., Vahdat, A.: Camco: Camera-controllable 3d-consistent image-to-video generation. arXiv preprint arXiv:2406.02509 (2024) 3 20 H. Chen et al
Pith/arXiv arXiv 2024
-
[71]
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Adv. Neural Inform. Process. Syst. (2023) 8
2023
-
[72]
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Adv. Neural Inform. Process. Syst. (2024) 7
2024
-
[73]
arXiv preprint arXiv:2408.06072 (2024) 3, 10, 11, 14, S2, S3
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024) 3, 10, 11, 14, S2, S3
Pith/arXiv arXiv 2024
-
[74]
arXiv preprint arXiv:2409.02048 (2024) 3
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024) 3
Pith/arXiv arXiv 2024
-
[75]
Yuan, S., Huang, J., Xu, Y., Liu, Y., Zhang, S., Shi, Y., Zhu, R.J., Cheng, X., Luo, J., Yuan, L.: Chronomagic-bench: A benchmark for metamorphic evaluation of text-to-time-lapse video generation. Adv. Neural Inform. Process. Syst. (2024) 3
2024
-
[76]
IJCV (2025) 3
Zhang, D.J., Wu, J.Z., Liu, J.W., Zhao, R., Ran, L., Gu, Y., Gao, D., Shou, M.Z.: Show-1: Marrying pixel and latent diffusion models for text-to-video generation. IJCV (2025) 3
2025
-
[77]
arXiv preprint arXiv:2510.18135 (2025) 3, 4
Zhang, J., Jiang, M., Dai, N., Lu, T., Uzunoglu, A., Zhang, S., Wei, Y., Wang, J., Patel, V.M., Liang, P.P., et al.: World-in-world: World models in a closed-loop world. arXiv preprint arXiv:2510.18135 (2025) 3, 4
arXiv 2025
-
[78]
In: CVPR (2018) 8
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018) 8
2018
-
[79]
arXiv preprint arXiv:2508.01112 (2025) 3
Zhao, Y., Chen, H., Liu, C., Li, Z., Herrmann, C., Hur, J., Li, Y., Yang, M.H., Raj, B., Xu, M.: Masiv: Toward material-agnostic system identification from videos. arXiv preprint arXiv:2508.01112 (2025) 3
arXiv 2025
-
[80]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025) 3
Zhao, Y., Liu, C., Chen, H., Raj, B., Xu, M., Baltrusaitis, T., Rundle, M., Wu, H., Ghasedi, K.: Total-editing: Head avatar with editable appearance, motion, and lighting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025) 3
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.