SIFT: Self-Imagination Fine-Tuning for Physically Plausible Motion in Video Diffusion Models
Pith reviewed 2026-06-29 04:36 UTC · model grok-4.3
The pith
Video diffusion models learn physically plausible motions by fine-tuning on videos they generate themselves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
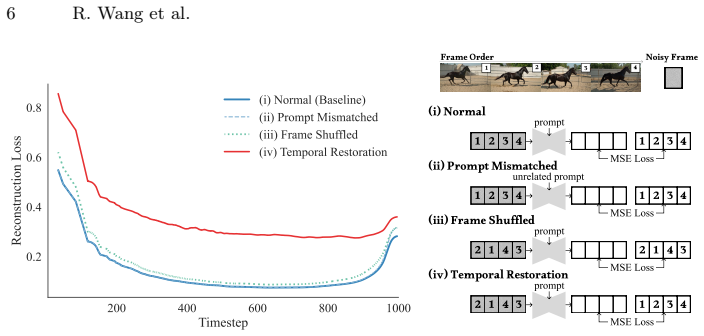
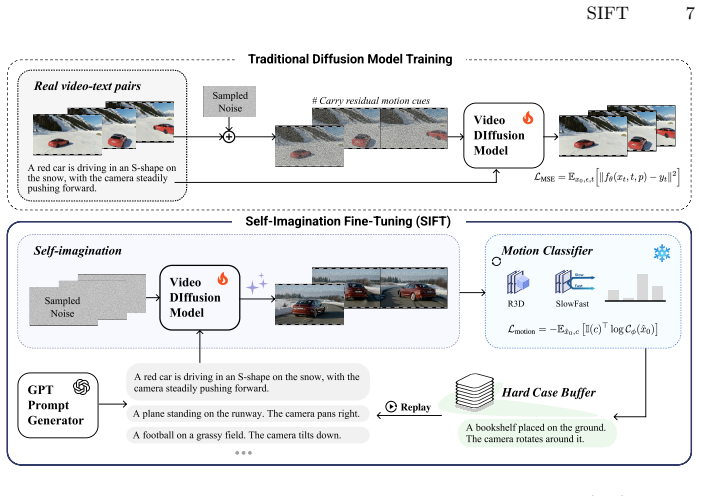
The reconstruction shortcut in diffusion training on noisy real videos encourages replication of existing motion patterns rather than learning grounded kinematics. SIFT breaks this by having the model train on its own generations, using motion-aware discriminative supervision and progressive hard-case replay to learn disentangled, physically plausible motions across a broad space covered by free text prompts.
What carries the argument
The Self-Imagination Fine-Tuning (SIFT) paradigm that replaces direct reconstruction of real videos with learning from the model's own generated videos under motion-aware discriminative supervision.
If this is right
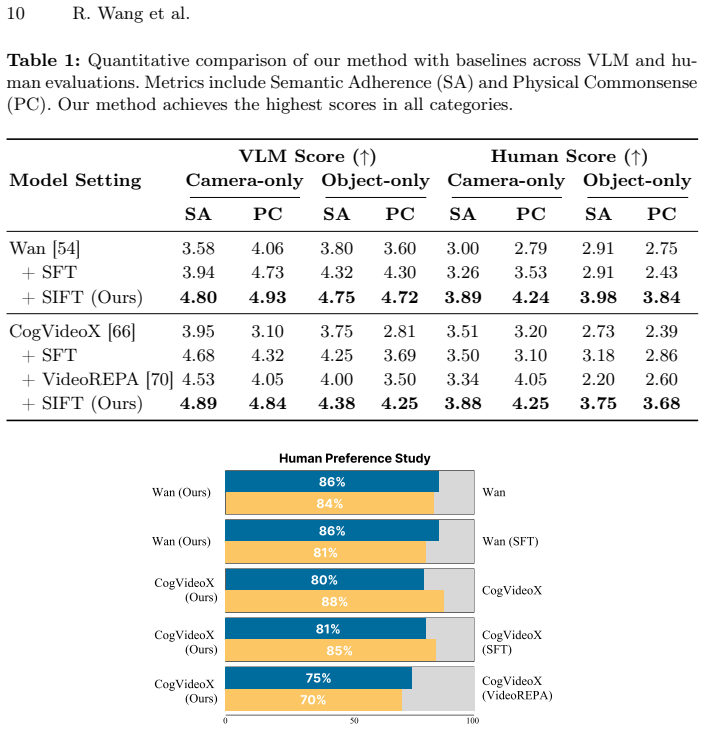
- Generated videos show substantially improved physical realism.
- Motion entanglement between independent sources such as camera and object movement is reduced.
- Controllability of video generation increases.
- Dense coverage of rare and finely-disentangled motion scenarios becomes possible without costly data collection.
Where Pith is reading between the lines
- The same self-imagination loop may help other generative models that suffer from reconstruction biases in geometry or causality.
- Training pipelines could shift away from large curated video datasets toward prompt-driven self-generation.
- Pairing the fine-tuned model with an external physics simulator could provide an automatic check on the learned motions.
Load-bearing premise
That the model's self-generated videos, when used for training with the added supervision, teach real kinematic principles instead of reinforcing whatever artifacts the base model already has.
What would settle it
Running the fine-tuned model on prompts known to produce entangled motions in the base model and finding no reduction in entanglement or physical violations.
Figures



read the original abstract
Recent advances in video diffusion models have greatly improved visual fidelity, yet their generated motions often violate physical plausibility. We observe a common kinematic failure, "motion entanglement", the unintended coupling of independent motion sources, such as camera movement and object motion. We identify that this issue stems from data bias and the reconstruction-based training design of diffusion models. Training on noisy videos that still retain coarse motion cues inadvertently encourages the model to replicate existing motion without an incentive to learn how to model kinematically-grounded motions. To address this, we propose a Self-Imagination Fine-Tuning (SIFT) paradigm, which enables the model to learn from its own generated videos rather than directly reconstructing real ones, breaking the reconstruction shortcut. We further employ motion-aware discriminative supervision and a progressive hard-case replay strategy to stabilize and accelerate learning. By leveraging freely-generated text prompts, our method can densely cover a broad motion space, including rare or finely-disentangled scenarios that would be costly to collect as video data. Extensive experiments demonstrate that our approach substantially improves the physical realism, motion disentanglement, and controllability of generated videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Self-Imagination Fine-Tuning (SIFT) for video diffusion models to mitigate motion entanglement (unintended coupling of independent sources such as camera and object motion). It replaces direct reconstruction on real videos with fine-tuning on the model's own generations, augmented by motion-aware discriminative supervision and progressive hard-case replay, claiming this breaks the reconstruction shortcut and yields improved physical realism, disentanglement, and controllability from text prompts.
Significance. If the central claim holds under rigorous validation, the approach could meaningfully advance controllable video synthesis by enabling denser coverage of motion spaces without new curated data collection. The self-supervised loop and hard-case replay are conceptually appealing for addressing data bias, though their effectiveness depends on whether generated videos supply independent corrective signal.
major comments (3)
- [Abstract] Abstract: the central claim that SIFT 'substantially improves the physical realism, motion disentanglement, and controllability' is unsupported by any quantitative results, baselines, metrics, or experimental details. Without these, the magnitude of improvement and comparison to prior disentanglement methods cannot be assessed; this is load-bearing for the paper's contribution.
- [Abstract] Abstract (method description): the claim that training on self-generated videos 'breaks the reconstruction shortcut' and produces kinematically grounded motions rests on the unverified assumption that the model's free generations contain usable corrective signal about independent motion sources. Because the base model was trained on biased real data, its generations are expected to reproduce the same entanglements; the motion-aware discriminative head has no external oracle (physics simulation, 3D GT, or kinematic loss) and can at best reinforce statistical patterns labeled as 'disentangled.' This assumption is load-bearing for the entire paradigm.
- [Abstract] Abstract: the statement that 'freely-generated text prompts... densely cover a broad motion space, including rare or finely-disentangled scenarios' is not accompanied by any analysis or ablation showing that the generated distribution actually improves coverage or reduces entanglement relative to the training data distribution.
minor comments (1)
- [Abstract] The abstract uses several high-level terms ('motion entanglement', 'kinematically-grounded motions', 'motion-aware discriminative supervision') without concise operational definitions or references to their precise implementation in the method section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below. Revisions have been made to the abstract to incorporate quantitative results and additional supporting analysis from the experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SIFT 'substantially improves the physical realism, motion disentanglement, and controllability' is unsupported by any quantitative results, baselines, metrics, or experimental details. Without these, the magnitude of improvement and comparison to prior disentanglement methods cannot be assessed; this is load-bearing for the paper's contribution.
Authors: We agree that the abstract would be strengthened by explicit quantitative support. The revised abstract now includes specific metrics from our experiments (e.g., improvements in physical plausibility and disentanglement scores relative to baselines) and references the relevant experimental sections for direct comparison to prior methods. revision: yes
-
Referee: [Abstract] Abstract (method description): the claim that training on self-generated videos 'breaks the reconstruction shortcut' and produces kinematically grounded motions rests on the unverified assumption that the model's free generations contain usable corrective signal about independent motion sources. Because the base model was trained on biased real data, its generations are expected to reproduce the same entanglements; the motion-aware discriminative head has no external oracle (physics simulation, 3D GT, or kinematic loss) and can at best reinforce statistical patterns labeled as 'disentangled.' This assumption is load-bearing for the entire paradigm.
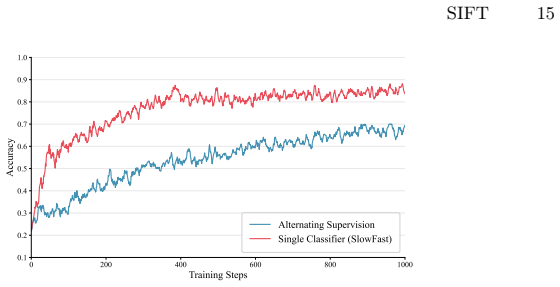
Authors: The motion-aware discriminative head is trained on self-generated pairs to distinguish entangled from disentangled motion patterns, providing an internal corrective signal that guides the diffusion process away from reconstruction shortcuts. Ablation studies in the manuscript demonstrate that removing this component leads to measurable increases in entanglement, supporting that the self-imagination loop supplies usable signal beyond inherited biases. We have expanded the method section with further discussion of this mechanism. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'freely-generated text prompts... densely cover a broad motion space, including rare or finely-disentangled scenarios' is not accompanied by any analysis or ablation showing that the generated distribution actually improves coverage or reduces entanglement relative to the training data distribution.
Authors: We have added a quantitative comparison of motion coverage and entanglement metrics between the original training distribution and the self-generated videos used in fine-tuning. This analysis, now summarized in the revised abstract and detailed in the experiments, shows increased diversity in motion parameters and reduced entanglement scores. revision: yes
Circularity Check
Self-supervised loop present but central claims remain empirically grounded
full rationale
The paper describes a self-imagination fine-tuning loop on model-generated videos plus discriminative supervision to break reconstruction shortcuts, yet the claims of improved physical realism and motion disentanglement rest on extensive experiments rather than reducing by definition or self-citation to the inputs. No equations, fitted predictions renamed as results, or load-bearing self-citations appear in the provided text. The method is self-contained against external benchmarks, yielding only minor circularity from the self-supervised framing itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
5-vl technical report
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv (2025)
2025
-
[2]
In: ICCV
Bain, M., Nagrani, A., Varol, G., Zisserman, A.: Frozen in time: A joint video and image encoder for end-to-end retrieval. In: ICCV. pp. 1728–1738 (2021)
2021
-
[3]
arXiv (2024)
Bansal, H., Lin, Z., Xie, T., Zong, Z., Yarom, M., Bitton, Y., Jiang, C., Sun, Y., Chang, K.W., Grover, A.: Videophy: Evaluating physical commonsense for video generation. arXiv (2024)
2024
-
[4]
arXiv (2023)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv (2023)
2023
-
[5]
In: CVPR
Burgert, R., Xu, Y., Xian, W., Pilarski, O., Clausen, P., He, M., Ma, L., Deng, Y., Li, L., Mousavi, M., et al.: Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise. In: CVPR. pp. 13–23 (2025)
2025
-
[6]
arXiv (2025)
Chefer, H., Singer, U., Zohar, A., Kirstain, Y., Polyak, A., Taigman, Y., Wolf, L., Sheynin, S.: Videojam: Joint appearance-motion representations for enhanced motion generation in video models. arXiv (2025)
2025
-
[7]
arXiv (2023)
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv (2023)
2023
-
[8]
In: CVPR
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion models. In: CVPR. pp. 7310–7320 (2024)
2024
-
[9]
Chen, T.S., Siarohin, A., Menapace, W., Deyneka, E., Chao, H.w., Jeon, B.E., Fang, Y., Lee, H.Y., Ren, J., Yang, M.H., et al.: Panda-70m: Captioning 70m videos with multiple cross-modality teachers
-
[10]
Chu, R., He, Y., Chen, Z., Zhang, S., Xu, X., Xia, B., Wang, D., Yi, H., Liu, X., Zhao, H., et al.: Wan-move: Motion-controllable video generation via latent trajectory guidance. arXiv preprint arXiv:2512.08765 (2025)
-
[11]
In: ICCV
Feichtenhofer, C., Fan, H., Malik, J., He, K.: Slowfast networks for video recogni- tion. In: ICCV. pp. 6202–6211 (2019)
2019
-
[12]
arXiv (2024)
Fu, X., Liu, X., Wang, X., Peng, S., Xia, M., Shi, X., Yuan, Z., Wan, P., Zhang, D., Lin, D.: 3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation. arXiv (2024)
2024
-
[13]
arXiv (2025)
Geng,Z.,Deng,M.,Bai,X.,Kolter,J.Z.,He,K.:Meanflowsforone-stepgenerative modeling. arXiv (2025)
2025
-
[14]
arXiv (2025)
Gillman, N., Herrmann, C., Freeman, M., Aggarwal, D., Luo, E., Sun, D., Sun, C.: Force prompting: Video generation models can learn and generalize physics-based control signals. arXiv (2025)
2025
-
[15]
Google DeepMind: Gemini image — nano banana.https://deepmind.google/ models/gemini-image/(2025), official model page, accessed 2026-03-03
2025
-
[16]
Google DeepMind: Veo 3.https://deepmind.google/models/veo/(2025)
2025
-
[17]
arXiv (2023)
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv (2023)
2023
-
[18]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024) SIFT 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
arXiv (2022)
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv (2022)
2022
-
[20]
NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS (2020)
2020
-
[21]
arXiv (2022)
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers. arXiv (2022)
2022
-
[22]
arXiv (2024)
Hou, C., Chen, Z.: Training-free camera control for video generation. arXiv (2024)
2024
-
[23]
arXiv (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv (2024)
2024
-
[24]
NeurIPS37, 48955–48970 (2024)
Ju, X., Gao, Y., Zhang, Z., Yuan, Z., Wang, X., Zeng, A., Xiong, Y., Xu, Q., Shan, Y.: Miradata: A large-scale video dataset with long durations and structured captions. NeurIPS37, 48955–48970 (2024)
2024
-
[25]
arXiv (2024)
Kang, B., Yue, Y., Lu, R., Lin, Z., Zhao, Y., Wang, K., Huang, G., Feng, J.: How far is video generation from world model: A physical law perspective. arXiv (2024)
2024
-
[26]
In: ICCV
Khachatryan, L., Movsisyan, A., Tadevosyan, V., Henschel, R., Wang, Z., Navasardyan, S., Shi, H.: Text2video-zero: Text-to-image diffusion models are zero- shot video generators. In: ICCV. pp. 15954–15964 (2023)
2023
-
[27]
arXiv (2024)
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv (2024)
2024
-
[28]
Kuaishou: Kling ai.https://app.klingai.com/global/(2025)
2025
-
[29]
arXiv (2023)
Lian, L., Shi, B., Yala, A., Darrell, T., Li, B.: Llm-grounded video diffusion models. arXiv (2023)
2023
-
[30]
arXiv (2025)
Lin, Z., Cen, S., Jiang, D., Karhade, J., Wang, H., Mitra, C., Ling, T., Huang, Y., Liu, S., Chen, M., et al.: Towards understanding camera motions in any video. arXiv (2025)
2025
-
[31]
arXiv (2024)
Ling, P., Bu, J., Zhang, P., Dong, X., Zang, Y., Wu, T., Chen, H., Wang, J., Jin, Y.: Motionclone: Training-free motion cloning for controllable video generation. arXiv (2024)
2024
-
[32]
arXiv (2022)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv (2022)
2022
-
[33]
In: ECCV
Liu, S., Ren, Z., Gupta, S., Wang, S.: Physgen: Rigid-body physics-grounded image-to-video generation. In: ECCV. pp. 360–378. Springer (2024)
2024
-
[34]
arXiv (2022)
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv (2022)
2022
-
[35]
arXiv (2024)
Liu, Y., Zhang, K., Li, Y., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y., Sun, H., Gao, J., et al.: Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv (2024)
2024
-
[36]
In: CVPR
Lv, J., Huang, Y., Yan, M., Huang, J., Liu, J., Liu, Y., Wen, Y., Chen, X., Chen, S.: Gpt4motion: Scripting physical motions in text-to-video generation via blender- oriented gpt planning. In: CVPR. pp. 1430–1440 (2024)
2024
-
[37]
arXiv (2025)
Ma, G., Huang, H., Yan, K., Chen, L., Duan, N., Yin, S., Wan, C., Ming, R., Song, X., Chen, X., et al.: Step-video-t2v technical report: The practice, challenges, and future of video foundation model. arXiv (2025)
2025
-
[38]
arXiv (2024)
Ma, X., Wang, Y., Jia, G., Chen, X., Liu, Z., Li, Y.F., Chen, C., Qiao, Y.: Latte: Latent diffusion transformer for video generation. arXiv (2024)
2024
-
[39]
In: ACM Multimedia
Mao, J., Wang, X., Aizawa, K.: Guided image synthesis via initial image editing in diffusion model. In: ACM Multimedia. pp. 5321–5329 (2023) 18 R. Wang et al
2023
-
[40]
arXiv (2024)
Meng, F., Liao, J., Tan, X., Shao, W., Lu, Q., Zhang, K., Cheng, Y., Li, D., Qiao, Y., Luo, P.: Towards world simulator: Crafting physical commonsense-based benchmark for video generation. arXiv (2024)
2024
-
[41]
arXiv (2024)
Nan, K., Xie, R., Zhou, P., Fan, T., Yang, Z., Chen, Z., Li, X., Yang, J., Tai, Y.: Openvid-1m: A large-scale high-quality dataset for text-to-video generation. arXiv (2024)
2024
-
[42]
arXiv (2021)
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M.: Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv (2021)
2021
-
[43]
In: ICCV
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV. pp. 4195–4205 (2023)
2023
-
[44]
pexels.com/(2025), accessed: 2025-11-13
Pexels: Pexels – free stock photos, royalty free images & videos.https://www. pexels.com/(2025), accessed: 2025-11-13
2025
-
[45]
arXiv (2022)
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv (2022)
2022
-
[46]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[47]
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding (2022)
2022
-
[48]
In: ICLR (2021)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
2021
-
[49]
arXiv (2020)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv (2020)
2020
-
[50]
In: CVPR
Sun, K., Huang, K., Liu, X., Wu, Y., Xu, Z., Li, Z., Liu, X.: T2v-compbench: A comprehensive benchmark for compositional text-to-video generation. In: CVPR. pp. 8406–8416 (2025)
2025
-
[51]
arXiv (2024)
Tan, X., Jiang, Y., Li, X., Zong, Z., Xie, T., Yang, Y., Jiang, C.: Physmotion: Physics-grounded dynamics from a single image. arXiv (2024)
2024
-
[52]
arXiv (2024)
Team, G., Georgiev, P., Lei, V.I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vin- cent,D.,Pan,Z.,Wang,S.,etal.:Gemini1.5:Unlockingmultimodalunderstanding across millions of tokens of context. arXiv (2024)
2024
-
[53]
In: CVPR
Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., Paluri, M.: A closer look at spatiotemporal convolutions for action recognition. In: CVPR. pp. 6450–6459 (2018)
2018
-
[54]
arXiv (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv (2025)
2025
-
[55]
arXiv (2025)
Wang, C., Chen, C., Huang, Y., Dou, Z., Liu, Y., Gu, J., Liu, L.: Physctrl: Gener- ative physics for controllable and physics-grounded video generation. arXiv (2025)
2025
-
[56]
In: CVPR
Wang, Q., Shi, Y., Ou, J., Chen, R., Lin, K., Wang, J., Jiang, B., Yang, H., Zheng, M., Tao, X., et al.: Koala-36m: A large-scale video dataset improving consis- tency between fine-grained conditions and video content. In: CVPR. pp. 8428–8437 (2025)
2025
-
[57]
In: ICCV
Wang, R., Huang, H., Zhu, Y., Russakovsky, O., Wu, Y.: The silent assistant: Noisequery as implicit guidance for goal-driven image generation. In: ICCV. pp. 17618–17628 (2025)
2025
-
[58]
arXiv (2023) SIFT 19
Wang, Y., He, Y., Li, Y., Li, K., Yu, J., Ma, X., Li, X., Chen, G., Chen, X., Wang, Y., et al.: Internvid: A large-scale video-text dataset for multimodal understanding and generation. arXiv (2023) SIFT 19
2023
-
[59]
5: Empowering video mllms with long and rich context modeling
Wang, Y., Li, X., Yan, Z., He, Y., Yu, J., Zeng, X., Wang, C., Ma, C., Huang, H., Gao, J., et al.: Internvideo2. 5: Empowering video mllms with long and rich context modeling. arXiv (2025)
2025
-
[60]
In: AAAI
Wu, T., Zhang, Y., Wang, X., Zhou, X., Zheng, G., Qi, Z., Shan, Y., Li, X.: Customcrafter: Customized video generation with preserving motion and concept composition abilities. In: AAAI. vol. 39, pp. 8469–8477 (2025)
2025
-
[61]
In: ECCV
Wu, T., Si, C., Jiang, Y., Huang, Z., Liu, Z.: Freeinit: Bridging initialization gap in video diffusion models. In: ECCV. pp. 378–394. Springer (2024)
2024
-
[62]
In: CVPR
Xie, T., Zhao, Y., Jiang, Y., Jiang, C.: Physanimator: Physics-guided generative cartoon animation. In: CVPR. pp. 10793–10804 (2025)
2025
-
[63]
In: CVPR
Xue, Q., Yin, X., Yang, B., Gao, W.: Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video generation. In: CVPR. pp. 18826–18836 (2025)
2025
-
[64]
arXiv (2025)
Xue, Z., Zhang, J., Hu, T., He, H., Chen, Y., Cai, Y., Wang, Y., Wang, C., Liu, Y., Li, X., et al.: Ultravideo: High-quality uhd video dataset with comprehensive captions. arXiv (2025)
2025
-
[65]
Yang, X., Li, B., Zhang, Y., Yin, Z., Bai, L., Ma, L., Wang, Z., Cai, J., Wong, T.T., Lu,H.,etal.:Towardsphysicallyplausiblevideogenerationviavlmplanning.arXiv 2(2025)
2025
-
[66]
arXiv (2024)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv (2024)
2024
-
[67]
arXiv (2024)
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv (2024)
2024
-
[68]
arXiv (2025)
Zhang, K., Xiao, C., Mei, Y., Xu, J., Patel, V.M.: Think before you diffuse: Llms- guided physics-aware video generation. arXiv (2025)
2025
-
[69]
In: ECCV
Zhang, T., Yu, H.X., Wu, R., Feng, B.Y., Zheng, C., Snavely, N., Wu, J., Freeman, W.T.: Physdreamer: Physics-based interaction with 3d objects via video genera- tion. In: ECCV. pp. 388–406. Springer (2024)
2024
-
[70]
arXiv (2025)
Zhang, X., Liao, J., Zhang, S., Meng, F., Wan, X., Yan, J., Cheng, Y.: Videorepa: Learning physics for video generation through relational alignment with foundation models. arXiv (2025)
2025
-
[71]
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv (2024) SIFT 1 Overview This supplementary material provides additional implementation details, in- cluding the LLMs used for prompt generation and evaluation, together with a full description of our human ...
2024
-
[72]
–Scene layout, background, and interactions align with the prompt
Semantic Adherence Rate how well the video matches the prompt: –Objects, actions, and events correspond to the prompt (penalize miss- ing or extra elements). –Scene layout, background, and interactions align with the prompt
-
[73]
–Objects move only with plausible causes (no drifting or sudden changes without force)
Physical Plausibility Rate how realistic the motions are: –Motions are continuous, stable, and physically possible in the real world. –Objects move only with plausible causes (no drifting or sudden changes without force). GPT-4o Training prompts Generation.We use GPT-4o [23] to generate 10,000 training prompts covering diverse camera-only/object-only moti...
-
[74]
A description of a scene with completely stationary subjects (no move- ment)
-
[75]
The camera
A description of the camera action, starting with “The camera ...”. Requirements: –Subjects should be diverse: vehicles, animals, people, objects, furniture, sports equipment, artworks, etc. –Camera movements should vary and be selected only from: pan, tilt, zoom, truck, pedestal, dolly, arc, orbit, rotate. –Use simple, natural English. Avoid rare or over...
-
[76]
A description of a scene with moving subjects
-
[77]
Thecamera
Adescriptionofacompletelystaticcamerastartingwith“Thecamera”. Requirements: –Subjects should be highly diverse: animals, people, vehicles, objects, etc. –Subject movements can be active (run, move, fly, drive, rotate, etc.) or passive (fall, flow, swing, being thrown, drift, etc.). –Ensure no two prompts are similar in subject or movement type. Gemini-Pro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.