SHIFT: Gate-Modulated Activation Steering for Knowledge Conflict Mitigation in Retrieval-Augmented Generation
Pith reviewed 2026-06-29 04:35 UTC · model grok-4.3
The pith
A lightweight gate module lets LLMs resolve knowledge conflicts in RAG by modulating activations instead of editing neurons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
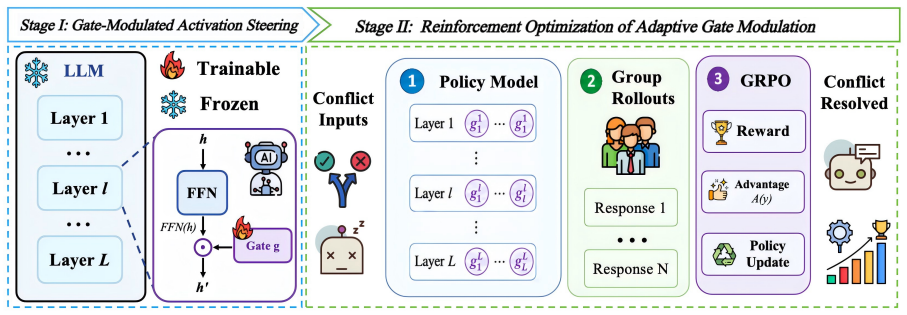
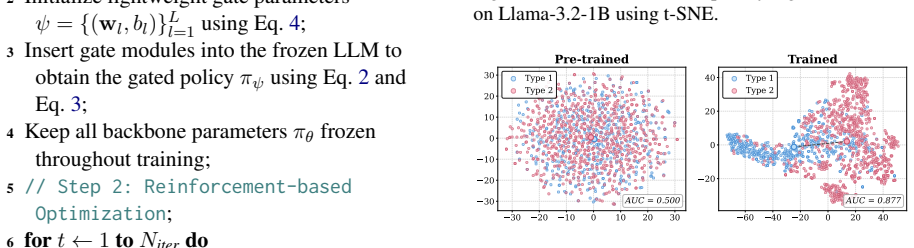
SHIFT reformulates neuron-level modification as learnable gate modulation, equipping LLMs with a lightweight gate module that optimizes fewer than 0.01% trainable parameters while keeping the backbone model frozen. During generation, the gate module adjusts the model's internal representations to adaptively leverage contextual and parametric knowledge.
What carries the argument
The learnable gate module that performs activation steering by modulating internal representations to balance knowledge sources.
If this is right
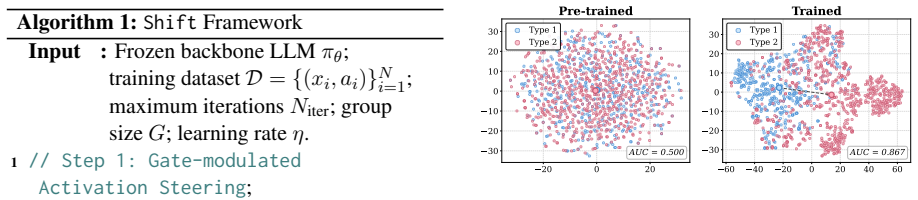
- Knowledge conflicts in RAG can be mitigated without compromising the LLM's general capabilities.
- Only a very small fraction of parameters needs training compared with full model updates or neuron edits.
- The model can adaptively choose when to draw on retrieved context versus its own parameters during generation.
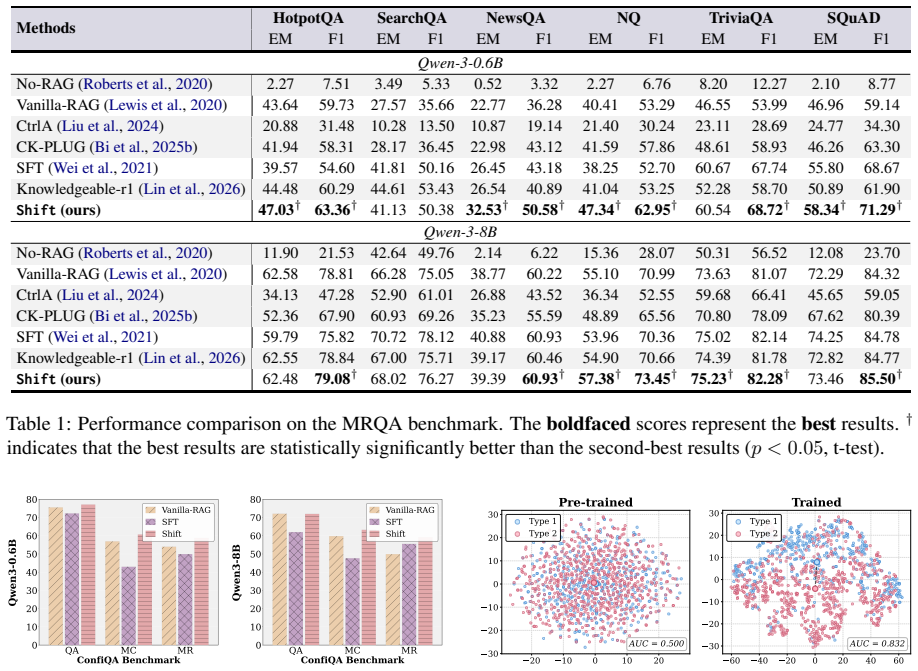
- The method shows effectiveness across six datasets when compared with various baselines.
Where Pith is reading between the lines
- The frozen-backbone design could allow easy addition to already-deployed LLMs without retraining the core model.
- The same gate approach might address other forms of internal inconsistency in language models beyond RAG settings.
- Combining the gate with other lightweight adaptation methods could further reduce the cost of handling knowledge issues.
Load-bearing premise
A gate module trained on a tiny parameter budget can steer activations to resolve conflicts without introducing new unintended side effects on model behavior.
What would settle it
An experiment in which SHIFT fails to improve conflict resolution rates or causes measurable drops on non-conflict tasks relative to the neuron-editing baselines.
Figures

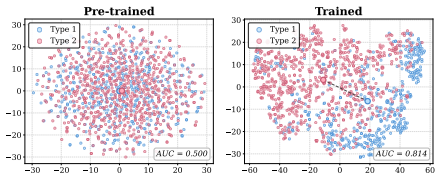
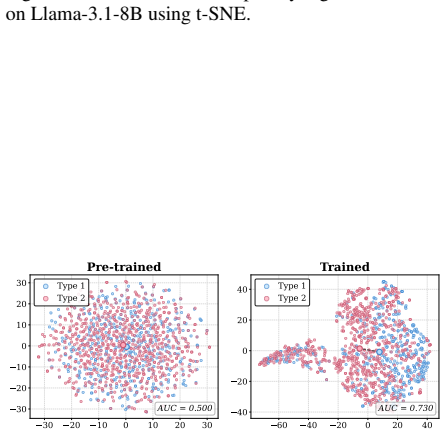
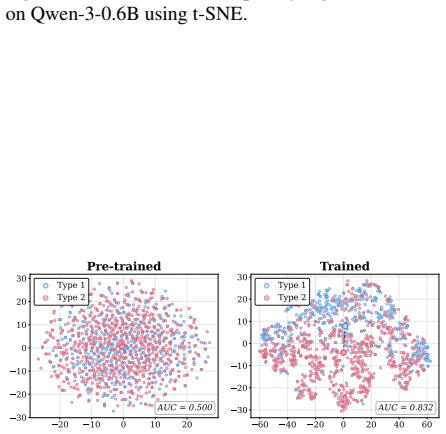




read the original abstract
Retrieval-augmented generation (RAG) enhances LLMs by incorporating external knowledge to support response generation. However, conflicts between retrieved context and parametric knowledge have emerged as a critical challenge in RAG systems. To mitigate such conflicts, numerous studies have attempted to identify and edit knowledge-related internal neurons, aiming to improve the ability of LLMs to rely on contextual evidence during generation. However, these neuron-level approaches may introduce unintended cascading effects that compromise the general capabilities of LLMs, as the modified neurons are often entangled with broader model behaviors and functionalities. In this paper, we introduce SHIFT, a novel framework that reformulates neuron-level modification as learnable gate modulation, allowing LLMs to adaptively regulate internal activations for knowledge conflict resolution. Technically, our SHIFT equips LLMs with a lightweight gate module and optimizes fewer than 0.01% trainable parameters while keeping the backbone model frozen. During generation, the gate module adjusts the model's internal representations to adaptively leverage contextual and parametric knowledge. Extensive experiments on six datasets validate the effectiveness of our SHIFT in comparison with various competing baselines. All datasets and code are available at https://github.com/OpenBMB/SHIFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SHIFT, a framework that reformulates neuron-level editing for knowledge conflict resolution in RAG as learnable gate modulation of internal activations. It equips the LLM with a lightweight gate module, optimizes fewer than 0.01% parameters while freezing the backbone, and uses the gates during generation to adaptively balance contextual and parametric knowledge. Effectiveness is validated via experiments on six datasets against competing baselines, with code and data released.
Significance. If the central claims hold, the work offers a parameter-efficient alternative to direct neuron editing that may reduce unintended side effects on general capabilities. The <0.01% trainable parameter budget and frozen backbone are notable strengths for practical deployment; reproducible code release further strengthens the contribution.
major comments (3)
- [Abstract, §3] Abstract and §3 (method): The central claim that gate modulation avoids the cascading effects of prior neuron edits rests on the assumption that the learned gates will selectively affect conflict-related activations. No inductive bias, regularization term, or locality constraint is described that would prevent the gates from altering entangled non-conflict behaviors when modulating the same representations.
- [§4] §4 (experiments): While six datasets are mentioned, the manuscript provides no quantitative evidence (e.g., ablation on general capability metrics such as MMLU or downstream task performance post-modulation) demonstrating that the gate module preserves capabilities better than direct editing baselines. This evidence is load-bearing for the claim of reduced side effects.
- [§3.2] §3.2 (gate module): The description of the gate architecture and training objective does not specify how context-dependent routing is achieved under the <0.01% parameter budget; without this, it is unclear whether the module has sufficient capacity for the claimed adaptive regulation.
minor comments (2)
- The abstract states that 'all datasets and code are available,' which is a positive; ensure the GitHub repository includes the exact training scripts, hyper-parameters, and evaluation code used for the reported results.
- [§3] Notation for the gate module (e.g., how the modulation is applied to activations) should be formalized with an equation in §3 to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): The central claim that gate modulation avoids the cascading effects of prior neuron edits rests on the assumption that the learned gates will selectively affect conflict-related activations. No inductive bias, regularization term, or locality constraint is described that would prevent the gates from altering entangled non-conflict behaviors when modulating the same representations.
Authors: We acknowledge that the manuscript does not introduce an explicit regularization term or locality constraint on the gates. The training objective optimizes the gates end-to-end on conflict-resolution examples while keeping the backbone frozen; this task-specific supervision provides an implicit bias toward selective modulation, as the gates are only updated to improve contextual reliance on the target tasks. We agree that making this reasoning more explicit would strengthen the central claim and will add a dedicated paragraph in §3 discussing the implicit inductive bias arising from the frozen backbone and conflict-focused objective. revision: partial
-
Referee: [§4] §4 (experiments): While six datasets are mentioned, the manuscript provides no quantitative evidence (e.g., ablation on general capability metrics such as MMLU or downstream task performance post-modulation) demonstrating that the gate module preserves capabilities better than direct editing baselines. This evidence is load-bearing for the claim of reduced side effects.
Authors: The referee correctly notes the absence of MMLU-style ablations. Because the backbone parameters remain completely frozen and only <0.01% parameters are introduced, general capabilities are preserved by construction, unlike neuron-editing methods that permanently alter entangled neurons. Nevertheless, to provide the requested quantitative support we will add post-modulation evaluations on MMLU and a held-out downstream task in the revised §4, comparing SHIFT against the direct-editing baselines. revision: yes
-
Referee: [§3.2] §3.2 (gate module): The description of the gate architecture and training objective does not specify how context-dependent routing is achieved under the <0.01% parameter budget; without this, it is unclear whether the module has sufficient capacity for the claimed adaptive regulation.
Authors: We apologize for the insufficient detail in §3.2. The gate module is a lightweight, shared low-rank adapter per layer that receives both the current activation and a compact context embedding; the modulation is computed via a small MLP whose parameters are tied across layers, keeping the total trainable count under 0.01%. Context dependence arises because the context embedding is recomputed from the retrieved passage at each generation step. We will expand §3.2 with the precise architecture diagram, parameter breakdown, and training objective to clarify capacity and routing. revision: yes
Circularity Check
No circularity: SHIFT introduces independent gate module without reduction to inputs
full rationale
The paper's core contribution is the introduction of a lightweight gate module (optimizing <0.01% parameters on a frozen backbone) that reformulates prior neuron-editing ideas as adaptive modulation. No equations, fitted parameters, or self-citations appear in the abstract or description that would make any claimed prediction or result equivalent to its inputs by construction. The approach is presented as an external technical addition addressing cascading effects of neuron edits, with no self-definitional loops, no renaming of known results, and no load-bearing self-citation chains. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- gate module parameters =
<0.01% of total parameters
axioms (1)
- domain assumption Gate modulation of internal activations can resolve knowledge conflicts without the cascading effects of neuron-level edits.
invented entities (1)
-
lightweight gate module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
A survey on rag meeting llms: Towards retrieval-augmented large language models , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[2]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
How much knowledge can you pack into the parameters of a language model? , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[3]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[4]
International Conference on Learning Representations , volume=
Redeep: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability , author=. International Conference on Learning Representations , volume=
-
[5]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Replug: Retrieval-augmented black-box language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[6]
Transactions of the Association for Computational Linguistics , volume=
In-context retrieval-augmented language models , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[7]
International conference on machine learning , pages=
Improving language models by retrieving from trillions of tokens , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[8]
2020 , eprint=
REALM: Retrieval-Augmented Language Model Pre-Training , author=. 2020 , eprint=
2020
-
[9]
2026 , eprint=
Beyond Precision: Training-Inference Mismatch is an Optimization Problem and Simple LR Scheduling Fixes It , author=. 2026 , eprint=
2026
-
[10]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Cutting off the head ends the conflict: A mechanism for interpreting and mitigating knowledge conflicts in language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[11]
2024 , eprint=
Studying Large Language Model Behaviors Under Context-Memory Conflicts With Real Documents , author=. 2024 , eprint=
2024
-
[12]
2024 , eprint=
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models , author=. 2024 , eprint=
2024
-
[13]
2023 , eprint=
The Internal State of an LLM Knows When It's Lying , author=. 2023 , eprint=
2023
-
[14]
arXiv preprint arXiv:2310.06824 , year=
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
-
[15]
2025 , eprint=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2025 , eprint=
2025
-
[16]
Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL) , pages=
Future lens: Anticipating subsequent tokens from a single hidden state , author=. Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL) , pages=
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Truthfulrag: Resolving factual-level conflicts in retrieval-augmented generation with knowledge graphs , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
the moon is made of marshmallows
Faitheval: Can your language model stay faithful to context, even if" the moon is made of marshmallows" , author=. International Conference on Learning Representations , volume=
-
[19]
International Conference on Learning Representations , volume=
Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts , author=. International Conference on Learning Representations , volume=
-
[20]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
Retrieval augmentation reduces hallucination in conversation , author=. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
2021
-
[21]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[22]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Understanding parametric and contextual knowledge reconciliation within large language models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[23]
2025 , eprint=
The Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation , author=. 2025 , eprint=
2025
-
[24]
The Twelfth International Conference on Learning Representations , year=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. The Twelfth International Conference on Learning Representations , year=
-
[25]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
The power of noise: Redefining retrieval for rag systems , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[26]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[27]
T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[28]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[29]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[30]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[31]
2024 , eprint=
CtrlA: Adaptive Retrieval-Augmented Generation via Inherent Control , author=. 2024 , eprint=
2024
-
[32]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[33]
2024 , eprint=
Context-DPO: Aligning Language Models for Context-Faithfulness , author=. 2024 , eprint=
2024
-
[34]
2022 , eprint=
Finetuned Language Models Are Zero-Shot Learners , author=. 2022 , eprint=
2022
-
[35]
2023 , eprint=
In-Context Retrieval-Augmented Language Models , author=. 2023 , eprint=
2023
-
[36]
2026 , eprint=
Resisting Contextual Interference in RAG via Parametric-Knowledge Reinforcement , author=. 2026 , eprint=
2026
-
[37]
Context: Fine-Grained Control of Knowledge Reliance in Language Models , author=
Parameters vs. Context: Fine-Grained Control of Knowledge Reliance in Language Models , author=. 2025 , eprint=
2025
-
[38]
2025 , eprint=
AdaCAD: Adaptively Decoding to Balance Conflicts between Contextual and Parametric Knowledge , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
FaithfulRAG: Fact-Level Conflict Modeling for Context-Faithful Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[40]
2023 , eprint=
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author=. 2023 , eprint=
2023
-
[41]
2025 , eprint=
Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models , author=. 2025 , eprint=
2025
-
[42]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
Squad: 100,000+ questions for machine comprehension of text , author=. Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
2016
-
[43]
N ews QA : A Machine Comprehension Dataset
Trischler, Adam and Wang, Tong and Yuan, Xingdi and Harris, Justin and Sordoni, Alessandro and Bachman, Philip and Suleman, Kaheer. N ews QA : A Machine Comprehension Dataset. Proceedings of the 2nd Workshop on Representation Learning for NLP. 2017. doi:10.18653/v1/W17-2623
-
[44]
arXiv preprint arXiv:1704.05179 , year=
Searchqa: A new q&a dataset augmented with context from a search engine , author=. arXiv preprint arXiv:1704.05179 , year=
-
[45]
2022 , eprint=
Entity-Based Knowledge Conflicts in Question Answering , author=. 2022 , eprint=
2022
-
[46]
MRQA 2019 Shared Task: Evaluating Generalization in Reading Comprehension
Fisch, Adam and Talmor, Alon and Jia, Robin and Seo, Minjoon and Choi, Eunsol and Chen, Danqi. MRQA 2019 Shared Task: Evaluating Generalization in Reading Comprehension. Proceedings of the 2nd Workshop on Machine Reading for Question Answering. 2019. doi:10.18653/v1/D19-5801
-
[47]
arXiv preprint arXiv:2404.16032 , year=
Studying large language model behaviors under context-memory conflicts with real documents , author=. arXiv preprint arXiv:2404.16032 , year=
-
[48]
2020 , eprint=
How Much Knowledge Can You Pack Into the Parameters of a Language Model? , author=. 2020 , eprint=
2020
-
[49]
Advances in neural information processing systems , volume=
Realtime qa: What's the answer right now? , author=. Advances in neural information processing systems , volume=
-
[50]
Advances in Neural Information Processing Systems , volume=
Toolqa: A dataset for llm question answering with external tools , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[52]
arXiv preprint arXiv:2109.01652 , year=
Finetuned language models are zero-shot learners , author=. arXiv preprint arXiv:2109.01652 , year=
-
[53]
ACM computing surveys , volume=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[54]
2025 , eprint=
ClashEval: Quantifying the tug-of-war between an LLM's internal prior and external evidence , author=. 2025 , eprint=
2025
-
[55]
Knowledge Neurons in Pretrained Transformers
Dai, Damai and Dong, Li and Hao, Yaru and Sui, Zhifang and Chang, Baobao and Wei, Furu. Knowledge Neurons in Pretrained Transformers. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.581
-
[56]
2025 , eprint=
ParamMute: Suppressing Knowledge-Critical FFNs for Faithful Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[57]
Context: Fine-Grained Control of Knowledge Reliance in Language Models , author=
Parameters vs. Context: Fine-Grained Control of Knowledge Reliance in Language Models , author=. arXiv preprint arXiv:2503.15888 , year=
-
[58]
The Fourteenth International Conference on Learning Representations , year=
LUMINA: Detecting Hallucinations in RAG System with Context–Knowledge Signals , author=. The Fourteenth International Conference on Learning Representations , year=
-
[59]
2024 , eprint=
Backward Lens: Projecting Language Model Gradients into the Vocabulary Space , author=. 2024 , eprint=
2024
-
[60]
arXiv preprint arXiv:2310.14053 , year=
Beyond accuracy: Evaluating self-consistency of code large language models with identitychain , author=. arXiv preprint arXiv:2310.14053 , year=
-
[61]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[62]
2025 , eprint=
ToolRL: Reward is All Tool Learning Needs , author=. 2025 , eprint=
2025
-
[63]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[64]
arXiv preprint arXiv:2203.11171 , year=
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[65]
2024 , eprint=
Cutting Off the Head Ends the Conflict: A Mechanism for Interpreting and Mitigating Knowledge Conflicts in Language Models , author=. 2024 , eprint=
2024
-
[66]
2023 , eprint=
Attention Lens: A Tool for Mechanistically Interpreting the Attention Head Information Retrieval Mechanism , author=. 2023 , eprint=
2023
-
[67]
2024 , eprint=
Retrieval Head Mechanistically Explains Long-Context Factuality , author=. 2024 , eprint=
2024
-
[68]
arXiv preprint arXiv:2309.15098 , year=
Attention satisfies: A constraint-satisfaction lens on factual errors of language models , author=. arXiv preprint arXiv:2309.15098 , year=
-
[69]
Self-dc: When to reason and when to act? self divide-and-conquer for compositional unknown questions , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[70]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
The earth is flat because...: Investigating llms’ belief towards misinformation via persuasive conversation , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[71]
Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024) , pages=
Tug-of-war between knowledge: Exploring and resolving knowledge conflicts in retrieval-augmented language models , author=. Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024) , pages=
2024
-
[72]
arXiv preprint arXiv:2405.11613 , year=
Decoding by Contrasting Knowledge: Enhancing LLMs' Confidence on Edited Facts , author=. arXiv preprint arXiv:2405.11613 , year=
-
[73]
arXiv preprint arXiv:2310.00935 , year=
Resolving knowledge conflicts in large language models , author=. arXiv preprint arXiv:2310.00935 , year=
-
[74]
arXiv e-prints , pages=
Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models , author=. arXiv e-prints , pages=
-
[75]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Context-faithful prompting for large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[76]
arXiv preprint arXiv:2601.06842 , year=
Seeing through the Conflict: Transparent Knowledge Conflict Handling in Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2601.06842 , year=
-
[77]
arXiv preprint arXiv:2403.08319 , year=
Knowledge Conflicts for LLMs: A Survey , author=. arXiv preprint arXiv:2403.08319 , year=
-
[78]
arXiv preprint arXiv:2510.12460 , year=
Probing Latent Knowledge Conflict for Faithful Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2510.12460 , year=
-
[79]
Adacad: Adaptively decoding to balance conflicts between contextual and parametric knowledge , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[80]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.