Reflect-R1: Evidence-Driven Reflection for Self-Correction in Long Video Understanding
Pith reviewed 2026-07-01 06:45 UTC · model grok-4.3
The pith
A three-stage evidence-driven pipeline with decoupled reinforcement learning enables reliable self-correction for long video understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
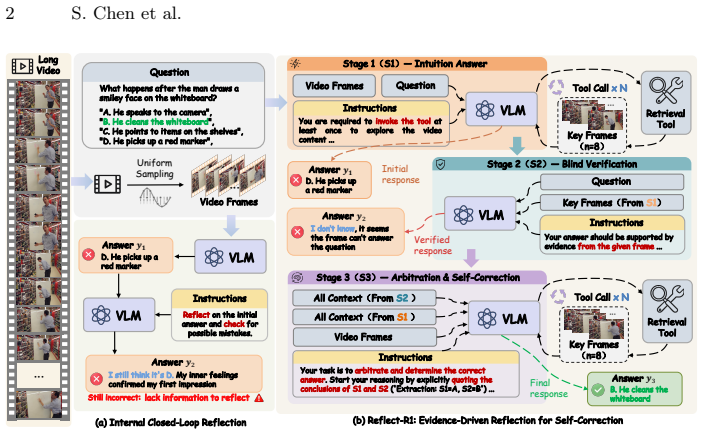
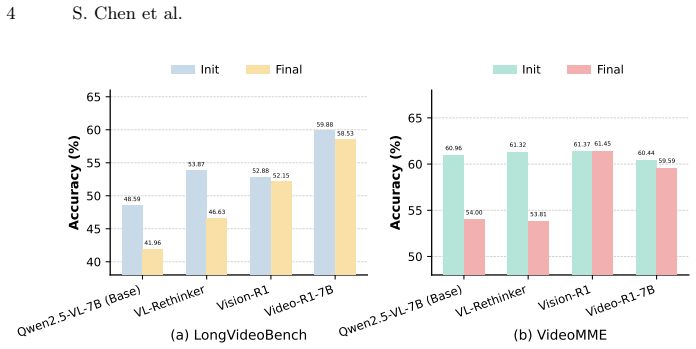
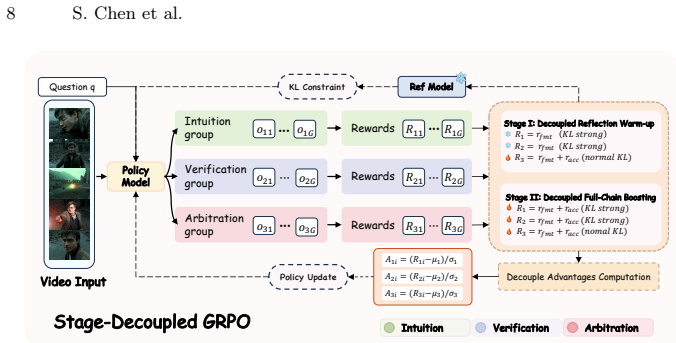
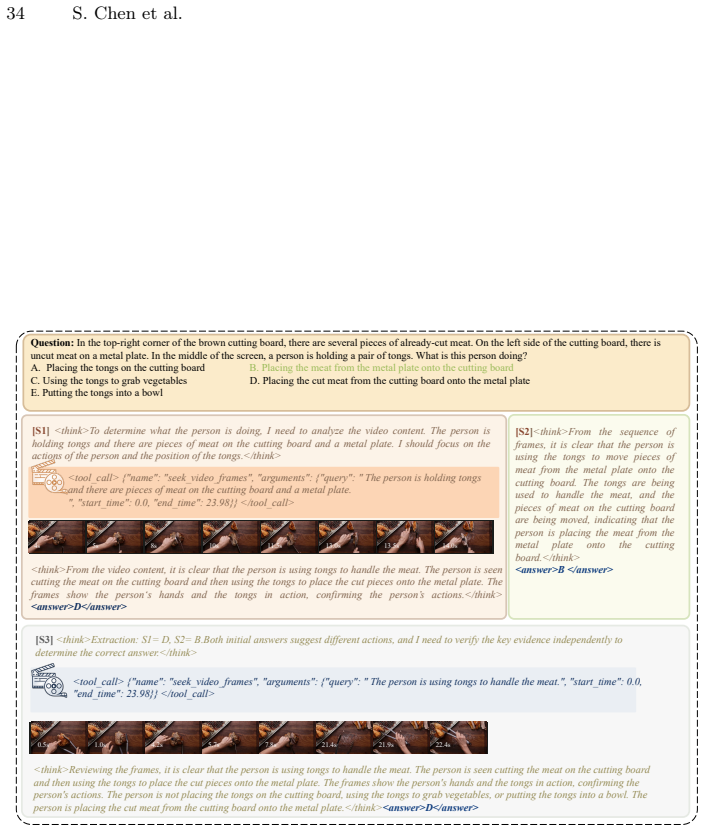
Reflect-R1 constructs a three-stage pipeline consisting of intuition, verification, and arbitration. By dynamically retrieving objective visual evidence to verify initial intuitions and autonomously executing multiple temporal searches to resolve conflicts, it completely breaks the hallucination loop. To overcome policy coupling, a stage-decoupled reinforcement learning algorithm named SD-GRPO independently computes advantage functions across different reasoning stages. A dataset of 120K samples is constructed to bridge the training data gap, and experiments show state-of-the-art performance on VideoMME and LongVideoBench with improved genuine rectification rates.
What carries the argument
The three-stage pipeline of intuition, verification, and arbitration that uses dynamic retrieval of objective visual evidence for verification and multiple temporal searches for conflict resolution, trained via the stage-decoupled SD-GRPO algorithm.
If this is right
- Genuine rectification rates increase because corrections are now strictly grounded in objective visual evidence rather than closed-loop internal reflection.
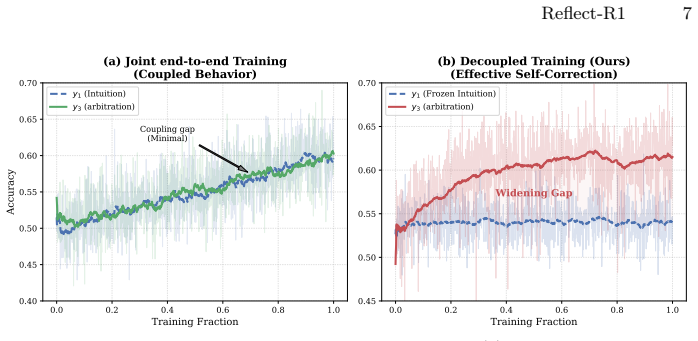
- Policy coupling is avoided in multi-stage reflection pipelines because advantage functions are computed independently per stage.
- Performance reaches state-of-the-art levels on long-video benchmarks such as VideoMME and LongVideoBench.
- Self-correction becomes authentic and no longer relies on models simply confirming their own prior outputs.
Where Pith is reading between the lines
- The same evidence-retrieval approach could be tested on other multimodal tasks such as long-document or audio understanding where internal reflection also risks hallucination loops.
- Selection bias in the temporal search step may still appear in domains where relevant evidence is sparse or ambiguously timed.
- Scaling the 120K dataset or combining SD-GRPO with other reinforcement methods could be explored to further reduce training data requirements.
Load-bearing premise
Dynamically retrieving objective visual evidence can reliably verify initial intuitions and autonomously resolve conflicts via multiple temporal searches without introducing new errors or selection biases.
What would settle it
A controlled test on videos where the initial model output is wrong but the evidence retrieval step either misses key frames or returns frames that support the wrong answer, after which the final arbitration output remains incorrect.
Figures
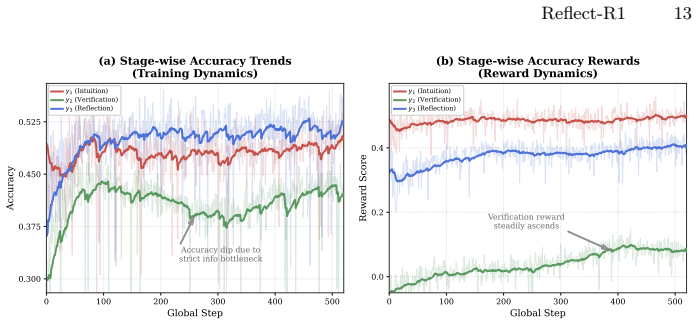
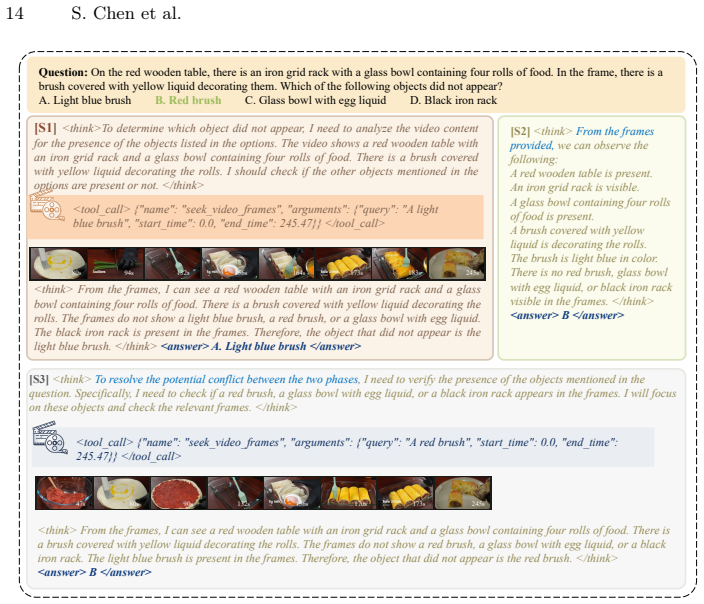

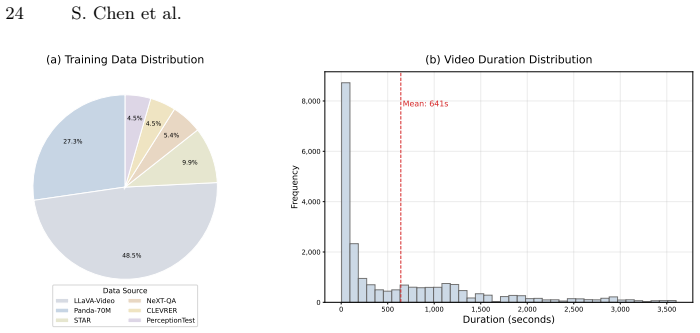







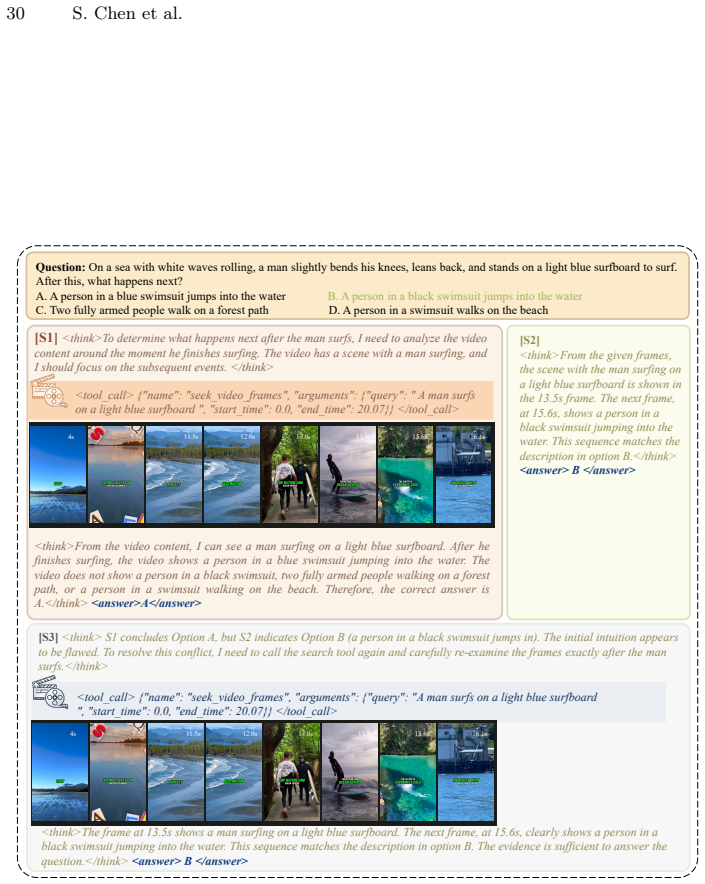



read the original abstract
Current multimodal reflection mechanisms for long video understanding predominantly rely on closed-loop self-reflection within internal parameters. Lacking objective external evidence, models are frequently trapped in blind confidence and often fail to correct errors. Furthermore, applying reinforcement learning to multi-stage reflection pipelines introduces severe policy coupling, which is exacerbated by a critical scarcity of dedicated training data. To address these limitations, this work proposes Reflect-R1, the first Evidence-Driven self-correction framework for long video understanding. The framework constructs a three-stage pipeline consisting of intuition, verification, and arbitration. By dynamically retrieving objective visual evidence to verify initial intuitions and autonomously executing multiple temporal searches to resolve conflicts, it completely breaks the hallucination loop. To overcome policy coupling, we design a stage-decoupled reinforcement learning algorithm named SD-GRPO that independently computes advantage functions across different reasoning stages. Concurrently, we construct a dataset of 120K samples to bridge the training data gap. Extensive experiments on benchmarks such as VideoMME and LongVideoBench demonstrate that Reflect-R1 achieves state-of-the-art performance. Our method significantly improves the genuine rectification rate and enables authentic self-correction strictly grounded in objective evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reflect-R1, a three-stage (intuition, verification, arbitration) evidence-driven self-correction framework for long video understanding. It dynamically retrieves objective visual evidence to verify initial intuitions and resolve conflicts via multiple temporal searches, claims to completely break hallucination loops, introduces the SD-GRPO stage-decoupled RL algorithm to address policy coupling, and releases a 120K-sample training dataset. Experiments report SOTA results on VideoMME and LongVideoBench with improved genuine rectification rates.
Significance. If the core claims hold, the work would be significant for multimodal video reasoning by replacing closed-loop internal reflection with externally grounded verification, addressing a documented failure mode in current MLLMs. The stage-decoupled RL formulation and dedicated dataset construction are practical contributions that could generalize beyond this pipeline.
major comments (3)
- [Abstract and §3] Abstract and §3 (pipeline description): the assertion that the method 'completely breaks the hallucination loop' is load-bearing yet rests on the unverified premise that dynamic evidence retrieval and autonomous temporal searches introduce neither selection bias nor new errors. No mechanism is described for detecting or mitigating retrieval-induced hallucinations in the arbitration stage.
- [§4] §4 (SD-GRPO): while the algorithm decouples advantage estimation across stages during training, it leaves inference-time retrieval behavior unchanged; thus the arbitration stage remains exposed to any biases present in the verification-stage evidence, undermining the claim of autonomous conflict resolution.
- [Experimental section] Experimental section (VideoMME / LongVideoBench results): the reported SOTA gains and 'genuine rectification rate' improvements lack an ablation isolating the contribution of evidence retrieval quality versus the three-stage structure; without this, it is unclear whether the performance stems from the proposed mechanism or from stronger retrieval alone.
minor comments (2)
- [Dataset section] The 120K dataset construction details (filtering criteria, temporal sampling strategy, and human verification protocol) are only sketched; expanding this would strengthen reproducibility claims.
- [§4] Notation for the advantage function in SD-GRPO could be clarified with an explicit equation showing how stage-specific advantages are computed and combined.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of our framework. We address each major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (pipeline description): the assertion that the method 'completely breaks the hallucination loop' is load-bearing yet rests on the unverified premise that dynamic evidence retrieval and autonomous temporal searches introduce neither selection bias nor new errors. No mechanism is described for detecting or mitigating retrieval-induced hallucinations in the arbitration stage.
Authors: We agree the phrasing 'completely breaks' is strong and that the manuscript does not explicitly describe a dedicated mechanism for detecting retrieval-induced errors in arbitration. The arbitration stage relies on multiple independent temporal searches to cross-verify evidence and resolve conflicts, which grounds decisions in objective visual data rather than internal parameters. To address the concern, we will revise the abstract and §3 to replace 'completely breaks' with 'substantially mitigates' and add a limitations paragraph discussing potential retrieval biases. revision: yes
-
Referee: [§4] §4 (SD-GRPO): while the algorithm decouples advantage estimation across stages during training, it leaves inference-time retrieval behavior unchanged; thus the arbitration stage remains exposed to any biases present in the verification-stage evidence, undermining the claim of autonomous conflict resolution.
Authors: SD-GRPO targets policy coupling exclusively during RL training by decoupling advantage estimation per stage. The inference pipeline remains the three-stage structure, where arbitration performs autonomous multiple temporal searches to resolve conflicts between intuition and verification outputs. This design ensures conflict resolution occurs at inference independently of training dynamics, preserving the external grounding claim. revision: no
-
Referee: [Experimental section] Experimental section (VideoMME / LongVideoBench results): the reported SOTA gains and 'genuine rectification rate' improvements lack an ablation isolating the contribution of evidence retrieval quality versus the three-stage structure; without this, it is unclear whether the performance stems from the proposed mechanism or from stronger retrieval alone.
Authors: We will add a new ablation in the experimental section comparing the full Reflect-R1 pipeline against a retrieval-only baseline (without the staged intuition-verification-arbitration structure) on both benchmarks to isolate the contribution of the three-stage mechanism. revision: yes
Circularity Check
No circularity: framework relies on external evidence and empirical validation
full rationale
The paper proposes a three-stage pipeline (intuition, verification, arbitration) that uses dynamic external visual evidence retrieval and a stage-decoupled RL algorithm (SD-GRPO), plus a constructed 120K-sample dataset. Performance is evaluated on external benchmarks (VideoMME, LongVideoBench). No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or derivations that reduce to inputs by construction appear in the provided text. The central claim of breaking the hallucination loop is presented as a design outcome grounded in objective evidence retrieval, not an internal self-referential loop or ansatz smuggled via prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2103.06224 (2021)
Arumugam, D., Henderson, P., Bacon, P.L.: An information-theoretic perspective on credit assignment in reinforcement learning. arXiv preprint arXiv:2103.06224 (2021)
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025)
2025
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, T.S., Siarohin, A., Menapace, W., Deyneka, E., Chao, H.w., Jeon, B.E., Fang, Y., Lee, H.Y., Ren, J., Yang, M.H., et al.: Panda-70m: Captioning 70m videos with multiple cross-modality teachers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13320–13331 (2024)
2024
-
[4]
arXiv preprint arXiv:2504.15275 (2025)
Cheng, J., Xiong, G., Qiao, R., Li, L., Guo, C., Wang, J., Lv, Y., Wang, F.Y.: Stop summation: Min-form credit assignment is all process reward model needs for reasoning. arXiv preprint arXiv:2504.15275 (2025)
-
[5]
In: The Fourteenth International Conference on Learning Repre- sentations (2026)
Chenzhaoyu, Lin, H., Nie, Y., Ma, F., Xu, X., Yu, F., Long, C.: Invert4TVG: A temporal video grounding framework with inversion tasks preserving action under- standing ability. In: The Fourteenth International Conference on Learning Repre- sentations (2026)
2026
-
[6]
Video-R1: Reinforcing Video Reasoning in MLLMs
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y., Peng, T., Wu, J., Zhang, X., Wang, B., Yue, X.: Video-r1: Reinforcing video reasoning in mllms. arXiv preprint arXiv:2503.21776 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24108–24118 (2025)
2025
-
[8]
In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Compu- tational Linguistics: Human Language Technologies, Volume 2 (Industry Papers)
Godin, F., Kumar, A., Mittal, A.: Learning when not to answer: a ternary reward structure for reinforcement learning based question answering. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Compu- tational Linguistics: Human Language Technologies, Volume 2 (Industry Papers). pp. 122–129 (2019)
2019
-
[9]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
Guo, C., He, Y., Nie, Y., Ma, F., Xu, X., Long, C.: T2sgrid: Temporal-to-spatial gridification for video temporal grounding. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 3443–3454 (June 2026)
2026
-
[10]
Nature645(8081), 633–638 (2025)
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature645(8081), 633–638 (2025)
2025
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, B., Li, H., Jang, Y.K., Jia, M., Cao, X., Shah, A., Shrivastava, A., Lim, S.N.: Ma-lmm: Memory-augmented large multimodal model for long-term video under- standing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13504–13514 (2024)
2024
-
[12]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Huang, W., Jia, B., Zhai, Z., Cao, S., Ye, Z., Zhao, F., Xu, Z., Hu, Y., Lin, S.: Vision-r1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) Reflect-R1 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al.: Openai o1 system card. arXiv preprint arXiv:2412.16720 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Advances in neural information processing systems35, 22199–22213 (2022)
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. Advances in neural information processing systems35, 22199–22213 (2022)
2022
-
[16]
arXiv preprint arXiv:2508.03100 (2025)
Kulkarni, Y., Fazli, P.: Avatar: Reinforcement learning to see, hear, and reason over video. arXiv preprint arXiv:2508.03100 (2025)
-
[17]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, S., Li, J., Zhao, G., Zhang, Y., Meng, X., Yu, F.R., Ji, X., Li, M.: Eventgpt: Event stream understanding with multimodal large language models. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 29139–29149 (June 2025)
2025
-
[18]
Sequence Modeling of Temporal Credit Assignment for Episodic Reinforcement Learning
Liu, Y., Luo, Y., Zhong, Y., Chen, X., Liu, Q., Peng, J.: Sequence modeling of temporal credit assignment for episodic reinforcement learning. arXiv preprint arXiv:1905.13420 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[19]
Advances in neural information processing systems36, 46534–46594 (2023)
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., et al.: Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems36, 46534–46594 (2023)
2023
-
[20]
In: Proceedings of the 31st International Conference on Computational Linguistics
Madhusudhan, N., Madhusudhan, S.T., Yadav, V., Hashemi, M.: Do llms know when to not answer? investigating abstention abilities of large language models. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 9329–9345 (2025)
2025
-
[21]
arXiv preprint arXiv:2502.16863 (2025)
Nagpal, K., Dong, D., Bouvier, J.B., Mehr, N.: Leveraging large language mod- els for effective and explainable multi-agent credit assignment. arXiv preprint arXiv:2502.16863 (2025)
-
[22]
arXiv preprint arXiv:2511.05489 (2025)
Pan, J., Zhang, Q., Zhang, R., Lu, M., Wan, X., Zhang, Y., Liu, C., She, Q.: Timesearch-r: Adaptive temporal search for long-form video understanding via self-verification reinforcement learning. arXiv preprint arXiv:2511.05489 (2025)
-
[23]
arXiv preprint arXiv:2601.06224 (2026)
Pan, M., Gan, W., Chen, J., Zhang, W., Sun, B., Yin, J., Zhang, X.: Ground what you see: Hallucination-resistant mllms via caption feedback, diversity-aware sampling, and conflict regularization. arXiv preprint arXiv:2601.06224 (2026)
-
[24]
Advances in Neural Information Processing Systems36, 42748–42761 (2023)
Patraucean, V., Smaira, L., Gupta, A., Recasens, A., Markeeva, L., Banarse, D., Koppula, S., Malinowski, M., Yang, Y., Doersch, C., et al.: Perception test: A di- agnostic benchmark for multimodal video models. Advances in Neural Information Processing Systems36, 42748–42761 (2023)
2023
-
[25]
In: 2025 IEEE International Con- ference on Multimedia and Expo (ICME)
Pereira, J., Lopes, V., Semedo, D., Neves, J.: Self-res: Self-reflection in large vision- language models for long video understanding. In: 2025 IEEE International Con- ference on Multimedia and Expo (ICME). pp. 1–9. IEEE (2025)
2025
-
[26]
Pignatelli, E., Ferret, J., Geist, M., Mesnard, T., van Hasselt, H., Pietquin, O., Toni, L.: A survey of temporal credit assignment in deep reinforcement learning (2024)
2024
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Shi, Y., Yan, W., Xu, G., Li, Y., Chen, Y., Li, Z., Yu, F., Li, M., Yeo, S.Y.: Pvchat: Personalized video chat with one-shot learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 23321–23331 (October 2025) 18 S. Chen et al
2025
-
[29]
Advances in neural information processing systems36, 8634–8652 (2023)
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Lan- guage agents with verbal reinforcement learning. Advances in neural information processing systems36, 8634–8652 (2023)
2023
-
[30]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, X., Qiu, J., Xie, L., Tian, Y., Jiao, J., Ye, Q.: Adaptive keyframe sampling for long video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29118–29128 (2025)
2025
-
[31]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team, G., Georgiev, P., Lei, V.I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vin- cent,D.,Pan,Z.,Wang,S.,etal.:Gemini1.5:Unlockingmultimodalunderstanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
arXiv preprint arXiv:2404.10960 (2024)
Tomani, C., Chaudhuri, K., Evtimov, I., Cremers, D., Ibrahim, M.: Uncertainty- based abstention in llms improves safety and reduces hallucinations. arXiv preprint arXiv:2404.10960 (2024)
-
[33]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Wang, H., Qu, C., Huang, Z., Chu, W., Lin, F., Chen, W.: Vl-rethinker: Incen- tivizing self-reflection of vision-language models with reinforcement learning. arXiv preprint arXiv:2504.08837 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
arXiv preprint arXiv:2510.01132 (2025)
Wang, R., Ammanabrolu, P.: A practitioner’s guide to multi-turn agentic reinforce- ment learning. arXiv preprint arXiv:2510.01132 (2025)
-
[35]
In: European Conference on Computer Vision
Wang, X., Zhang, Y., Zohar, O., Yeung-Levy, S.: Videoagent: Long-form video understanding with large language model as agent. In: European Conference on Computer Vision. pp. 58–76. Springer (2024)
2024
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence
Wang, Z., Yu, S., Stengel-Eskin, E., Yoon, J., Cheng, F., Bertasius, G., Bansal, M.: Videotree: Adaptive tree-based video representation for llm reasoning on long videos. In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence. pp. 3272–3283 (2025)
2025
-
[37]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[38]
TruthRL: Incentivizing Truthful LLMs via Reinforcement Learning
Wei, Z., Yang, X., Sun, K., Wang, J., Shao, R., Chen, S., Kachuee, M., Gollapudi, T., Liao, T., Scheffer, N., et al.: Truthrl: Incentivizing truthful llms via reinforce- ment learning. arXiv preprint arXiv:2509.25760 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
arXiv preprint arXiv:2405.09711 (2024)
Wu,B.,Yu,S.,Chen,Z.,Tenenbaum,J.B.,Gan,C.:Star:Abenchmarkforsituated reasoning in real-world videos. arXiv preprint arXiv:2405.09711 (2024)
-
[40]
Advances in Neural Information Pro- cessing Systems37, 28828–28857 (2024)
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context interleaved video-language understanding. Advances in Neural Information Pro- cessing Systems37, 28828–28857 (2024)
2024
-
[41]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiao,J.,Shang,X.,Yao,A.,Chua,T.S.:Next-qa:Nextphaseofquestion-answering to explaining temporal actions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9777–9786 (2021)
2021
-
[42]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizingreasoningandactinginlanguagemodels.In:Theeleventhinternational conference on learning representations (2022)
2022
-
[43]
In: CVPR
Ye, J., Wang, Z., Sun, H., Chandrasegaran, K., Durante, Z., Eyzaguirre, C., Bisk, Y., Niebles, J.C., Adeli, E., Fei-Fei, L., et al.: Re-thinking temporal search for long-form video understanding. In: CVPR. pp. 8579–8591 (2025)
2025
-
[44]
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Yi, K., Gan, C., Li, Y., Kohli, P., Wu, J., Torralba, A., Tenenbaum, J.B.: Clevrer: Collision events for video representation and reasoning. arXiv preprint arXiv:1910.01442 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[45]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Zhang, Y., Liu, X., Tao, R., Chen, Q., Fei, H., Che, W., Qin, L.: Vitcot: Video-text interleaved chain-of-thought for boosting video understanding in large language models. In: Proceedings of the 33rd ACM International Conference on Multimedia. Reflect-R1 19 p. 5267–5276. MM ’25, Association for Computing Machinery, New York, NY, USA (2025)
2025
-
[46]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Llava-video: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Zhao, F., Tan, S., Qiu, X., Xun, L., Jiang, W., Zheng, J., Fan, H., Gao, J., Yan, D., Li, M.: Favchat: Hierarchical prompt-query guided facial video understanding with data-efficient grpo (2026)
2026
-
[48]
type": "function
Zhou, J., Shu, Y., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y., Zhang, B., et al.: Mlvu: Benchmarking multi-task long video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13691–13701 (2025) 20 S. Chen et al. Reflect-R1: Evidence-Driven Reflection for Self-Correction in Long...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.