From Black-Box to Clinical Insight: A Multi-Stage Explainable Framework for Speech-Based Cognitive Impairment Detection
Pith reviewed 2026-06-29 04:34 UTC · model grok-4.3
The pith
A multi-stage framework turns black-box speech model outputs into narratives aligned with clinical cognitive profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
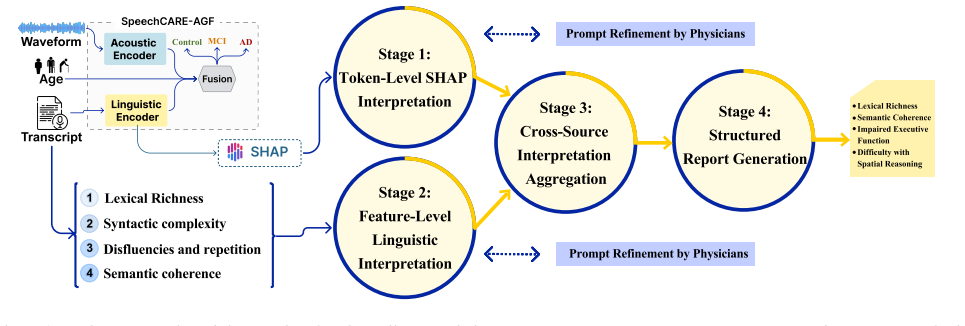
The framework maps the base model's predictions onto four cognitive-linguistic dimensions through SHAP token attribution, theory-informed linguistic features, and a four-stage LLM reasoning pipeline, yielding narratives that physicians judged to align with patient-level cognitive profiles on 70 English samples.
What carries the argument
The four-stage LLM reasoning pipeline that consumes SHAP attributions and linguistic features to generate dimension-specific clinical narratives.
If this is right
- Model outputs become traceable to specific linguistic properties such as lexical richness and syntactic complexity.
- The generated narratives support direct comparison against a patient's overall cognitive profile.
- The pipeline can be inserted into existing screening workflows without requiring new model training.
- High usability scores suggest the output format is readable enough for routine clinical review.
Where Pith is reading between the lines
- The same staged attribution-plus-reasoning structure could be tested on other speech or language tasks where black-box predictions need clinical grounding.
- If hallucinations remain low across languages, the method might reduce the need for separate post-hoc explanation tools in medical AI.
- Longer-term use could reveal whether the four dimensions capture enough variance to guide individualized follow-up testing.
Load-bearing premise
That SHAP attributions plus the staged LLM pipeline produce faithful mappings to cognitive dimensions without hallucination or post-hoc fitting.
What would settle it
Independent physicians rating a fresh set of model-generated narratives for factual alignment with recorded speech samples and for presence of invented clinical details.
Figures

read the original abstract
Speech-based cognitive impairment detection offers a noninvasive, accessible alternative to costly biomarker assays, yet transformer-based models remain clinically uninterpretable. We propose a multi-stage explainability framework that translates black-box transformer predictions into clinically grounded narratives by integrating SHapley Additive exPlanations (SHAP)-based token attribution, theory-informed linguistic features, and a four-stage LLM reasoning pipeline using LLaMA-3.1-70B-Instruct. Built on the SpeechCARE-Adaptive Gating Network multimodal screening model (F1 = 72.11% on the NIA PREPARE benchmark), the framework maps model outputs to four cognitive-linguistic dimensions, including lexical richness, syntactic complexity, and semantic coherence. Physician evaluation on 70 stratified English samples demonstrated strong alignment with patient-level cognitive profiles, and a System Usability Scale score of 82/100 indicated high potential for clinical workflow integration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multi-stage explainable framework for speech-based cognitive impairment detection. It augments the SpeechCARE-Adaptive Gating Network (F1=72.11% on NIA PREPARE) with SHAP token attributions, theory-informed linguistic features (lexical richness, syntactic complexity, semantic coherence), and a four-stage LLaMA-3.1-70B-Instruct reasoning pipeline to generate clinically grounded narratives. Physician evaluation on 70 stratified English samples is reported to show strong alignment with patient-level cognitive profiles, alongside a System Usability Scale score of 82/100 suggesting clinical integration potential.
Significance. If the physician alignment claim is substantiated with quantitative metrics and controls, the framework could meaningfully address the interpretability gap in transformer-based speech models for cognitive screening. The integration of SHAP with LLM reasoning is a plausible direction, but the current evidence base is too thin to establish clinical utility or faithfulness of the generated narratives.
major comments (2)
- [Abstract / Physician evaluation] Physician evaluation (abstract): The central claim of 'strong alignment with patient-level cognitive profiles' on 70 samples provides no quantitative agreement metrics (Cohen's kappa, Pearson correlation with independent cognitive scores, or inter-rater reliability), no blinding protocol, and no pre-specified evaluation criteria or exclusion rules. This directly undermines verification that the SHAP+four-stage LLM pipeline produces faithful rather than post-hoc fitted narratives.
- [Abstract / Framework description] Framework pipeline (abstract): The assumption that the four-stage LLM reasoning produces unbiased mappings to cognitive-linguistic dimensions is load-bearing for the 'clinical insight' claim, yet no ablation, hallucination controls, or comparison against human-generated reference narratives is described. Without these, the added value of the LLaMA stage over the base SpeechCARE outputs cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger quantitative support for our claims. We address each major comment below and will incorporate revisions to address the identified gaps.
read point-by-point responses
-
Referee: [Abstract / Physician evaluation] Physician evaluation (abstract): The central claim of 'strong alignment with patient-level cognitive profiles' on 70 samples provides no quantitative agreement metrics (Cohen's kappa, Pearson correlation with independent cognitive scores, or inter-rater reliability), no blinding protocol, and no pre-specified evaluation criteria or exclusion rules. This directly undermines verification that the SHAP+four-stage LLM pipeline produces faithful rather than post-hoc fitted narratives.
Authors: We agree that the absence of quantitative metrics in the abstract and main text weakens the claim. The current manuscript reports only qualitative alignment on the 70 samples. In revision we will compute and report Cohen's kappa, Pearson correlation with independent cognitive scores, and inter-rater reliability (where multiple raters are available). We will also add a dedicated subsection describing the blinding protocol, pre-specified evaluation criteria, and any exclusion rules applied. These changes will appear in both the abstract and the results section. revision: yes
-
Referee: [Abstract / Framework description] Framework pipeline (abstract): The assumption that the four-stage LLM reasoning produces unbiased mappings to cognitive-linguistic dimensions is load-bearing for the 'clinical insight' claim, yet no ablation, hallucination controls, or comparison against human-generated reference narratives is described. Without these, the added value of the LLaMA stage over the base SpeechCARE outputs cannot be assessed.
Authors: We acknowledge that the manuscript does not contain ablations of the four-stage pipeline, explicit hallucination controls, or direct comparisons to human-generated reference narratives. In the revised version we will add an ablation study that removes individual LLM stages and measures effects on narrative quality and alignment scores. We will also introduce hallucination controls via expert factuality ratings and include a side-by-side comparison against human expert narratives on a held-out subset of samples. These analyses will quantify the incremental contribution of the LLaMA stage. revision: yes
Circularity Check
No circularity: central claim is independent empirical evaluation
full rationale
The paper presents an additive explainability framework (SHAP + linguistic features + four-stage LLaMA pipeline) built on the SpeechCARE base model. The load-bearing claim is a separate physician evaluation on 70 stratified samples showing alignment with cognitive profiles. No equations, derivations, or self-citation chains are shown that reduce this alignment to quantities fitted or defined within the same pipeline by construction. The evaluation is described as external validation rather than a renamed or post-hoc fit of the base model's outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
I don’t remember
Introduction Cognitive impairment, including mild cognitive impairment (MCI) and Alzheimer’s disease (AD), poses an urgent pub- lic health challenge, with projected U.S. prevalence reaching 11–16 million cases by 2050 [1]. Speech offers a uniquely ac- cessible, noninvasive biomarker for early cognitive decline [2]. Acoustic and linguistic cues reflect imp...
2050
-
[2]
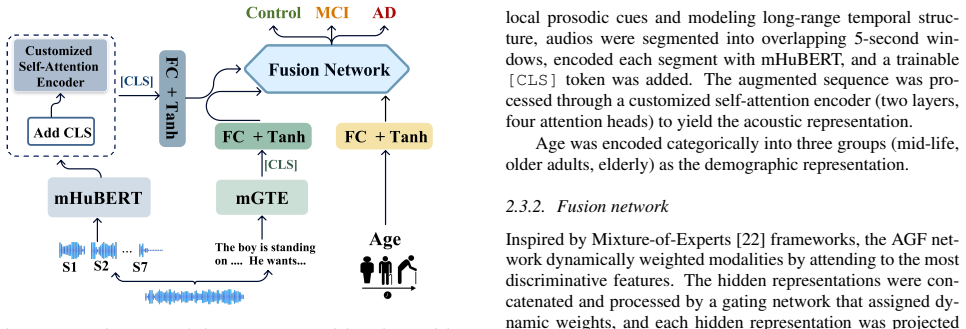
Method 2.1. Data: PREPARE challenge dataset We used the National Institute on Aging (NIA) PREPARE benchmark dataset [17] comprising speech recordings from 2,058 participants (1,646 training, 412 testing) across three lan- arXiv:2606.27973v1 [cs.CL] 26 Jun 2026 A DM C IC o n t r o l Customized Self-Attention Encoder Add CLS mHuBERT mGTE S1 S2 S7 ... The bo...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
curtains
Result 3.1. Model performance evaluation We began our evaluation by analyzing model performance. Fol- lowing training, we selected the model checkpoint that achieved the highest F1-score on the validation set and used this check- point to evaluate performance on the official Test set released by the PREPARE challenge organizers. The model achieved an Area...
-
[4]
Discussion This paper is the first to present a multi-stage explainability framework showing that sequentially combining SHAP attri- butions, theory-informed linguistic features, and LLM-based reasoning can bridge the gap between black-box transformer predictions and clinically meaningful narratives. Speech anal- ysis provides a functional complement to r...
2025
-
[5]
The content generated by this tool was thoroughly reviewed, revised, and approved by the au- thors
AI disclosure We used ChatGPT (OpenAI, GPT-4) to assist proofreading the manuscript for language quality. The content generated by this tool was thoroughly reviewed, revised, and approved by the au- thors. No AI tools were used for drafting the manuscript, data analysis, experiment design, or results interpretation
-
[6]
Mild cognitive impairment,
R. C. Petersen, “Mild cognitive impairment,”CONTINUUM: life- long Learning in Neurology, vol. 22, no. 2, pp. 404–418, 2016
2016
-
[7]
Changes in the rhythm of speech differ- ence between people with nondegenerative mild cognitive impair- ment and with preclinical dementia,
J. J. Meil ´an, F. Mart ´ınez-S´anchez, I. Mart ´ınez-Nicol´as, T. E. Llorente, and J. Carro, “Changes in the rhythm of speech differ- ence between people with nondegenerative mild cognitive impair- ment and with preclinical dementia,”Behavioural neurology, vol. 2020, no. 1, p. 4683573, 2020
2020
-
[8]
R. C. Petersen, O. Lopez, M. J. Armstrong, T. S. Getchius, M. Ganguli, D. Gloss, G. S. Gronseth, D. Marson, T. Pringsheim, G. S. Dayet al., “Practice guideline update summary: Mild cogni- tive impairment: Report of the guideline development, dissemina- tion, and implementation subcommittee of the american academy of neurology,”Neurology, vol. 90, no. 3, p...
2018
-
[9]
Detecting mild cognitive impairment using follow-up call speech and electronic health record data in home health care settings,
M. Zolnoori, A. Zolnour, S. Rashidi, I. Spens, Y . Haghbin, S. Vergez, G. Flaherty, N. Onorato, F. Vasquez, J. M. Nobleet al., “Detecting mild cognitive impairment using follow-up call speech and electronic health record data in home health care settings,” Journal of Gerontological Nursing, vol. 52, no. 1, pp. 8–14, 2026
2026
-
[10]
Speechcura: A novel speech augmentation framework to tackle data scarcity in healthcare,
S. Rashidi, H. Azadmaleki, A. Zolnour, M. J. Momeni Nezhad, and M. Zolnoori, “Speechcura: A novel speech augmentation framework to tackle data scarcity in healthcare,” inMEDINFO 2025—Healthcare Smart×Medicine Deep. IOS Press, 2025, pp. 1858–1859
2025
-
[11]
Leveraging text-to-speech and voice conversion as data augmentation for alzheimer’s disease detection from spontaneous speech,
S. Rashidi, Y . Haghbin, H. Azadmaleki, A. Zolnour, and M. Zol- noori, “Leveraging text-to-speech and voice conversion as data augmentation for alzheimer’s disease detection from spontaneous speech,” inICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026, pp. 6491–6495
2026
-
[12]
Y . Haghbin, S. Rashidi, A. Zolnour, and M. Zolnoori, “The voice of equity: A systematic evaluation of bias mitigation techniques for speech-based cognitive impairment detection across architec- tures and demographics,”arXiv preprint arXiv:2601.16989, 2026
-
[13]
An explain- able ai approach to speech-based alzheimer’s dementia screen- ing,
F. Iqbal, Z. S. Syed, M. S. S. Syed, and A. S. Syed, “An explain- able ai approach to speech-based alzheimer’s dementia screen- ing,” inSMM24, Workshop on Speech, Music and Mind 2024. ISCA, 2024, pp. 11–15
2024
-
[14]
Alzheimer’s dementia recognition through spontaneous speech,
S. Luz, F. Haider, S. de la Fuente Garcia, D. Fromm, and B. MacWhinney, “Alzheimer’s dementia recognition through spontaneous speech,” p. 780169, 2021
2021
-
[15]
A novel ap- proach to explain the black-box nature of machine learning in compressive strength predictions of concrete using shapley addi- tive explanations (shap),
I. Ekanayake, D. Meddage, and U. Rathnayake, “A novel ap- proach to explain the black-box nature of machine learning in compressive strength predictions of concrete using shapley addi- tive explanations (shap),”Case studies in construction materials, vol. 16, p. e01059, 2022
2022
-
[16]
Explainable identification of demen- tia from transcripts using transformer networks,
L. Ilias and D. Askounis, “Explainable identification of demen- tia from transcripts using transformer networks,”IEEE Journal of Biomedical and Health Informatics, vol. 26, no. 8, pp. 4153–4164, 2022
2022
-
[17]
Explaining the explainer: A first theoretical analysis of lime,
D. Garreau and U. Luxburg, “Explaining the explainer: A first theoretical analysis of lime,” inInternational conference on arti- ficial intelligence and statistics. PMLR, 2020, pp. 1287–1296
2020
-
[18]
Useful blunders: Can automated speech recognition errors improve downstream demen- tia classification?
C. Li, W. Xu, T. Cohen, and S. Pakhomov, “Useful blunders: Can automated speech recognition errors improve downstream demen- tia classification?”Journal of biomedical informatics, vol. 150, p. 104598, 2024
2024
-
[19]
Detecting Cognitive Decline Using Speech Only: The ADReSSo Challenge,
S. Luz, F. Haider, S. de la Fuente, D. Fromm, and B. MacWhin- ney, “Detecting Cognitive Decline Using Speech Only: The ADReSSo Challenge,” inInterspeech 2021, 2021, pp. 3780–3784
2021
-
[20]
V oiceprints of cognitive impairment: analyzing digital voice for early detection of alzheimer’s and related dementias,
N. Rezaii, B. Wong, P. Aisen, L. Beckett, J. L. Dage, A. Eloyan, T. Foroud, K. Womack, M. C. Carrillo, J. H. Krameret al., “V oiceprints of cognitive impairment: analyzing digital voice for early detection of alzheimer’s and related dementias,”npj Demen- tia, vol. 1, no. 1, p. 35, 2025
2025
-
[21]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Speechcare: dynamic multimodal modeling for cognitive screening in diverse linguistic and speech task contexts,
H. Azadmaleki, Y . Haghbin, S. Rashidi, M. J. Momeni Nezhad, A. Zolnour, and M. Zolnoori, “Speechcare: dynamic multimodal modeling for cognitive screening in diverse linguistic and speech task contexts,”npj Digital Medicine, vol. 8, no. 1, p. 677, 2025
2025
-
[23]
M. Zolnoori, H. Azadmaleki, Y . Haghbin, A. Zolnour, M. J. M. Nezhad, S. Rashidi, M. Naserian, E. Esmaeili, and S. K. Arpanahi, “National institute on aging prepare challenge: Early detection of cognitive impairment using speech–the speechcare solution,” arXiv preprint arXiv:2511.08132, 2025
-
[24]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[25]
mgte: Generalized long-context text representation and reranking models for multilingual text re- trieval,
X. Zhang, Y . Zhang, D. Long, W. Xie, Z. Dai, J. Tang, H. Lin, B. Yang, P. Xie, F. Huanget al., “mgte: Generalized long-context text representation and reranking models for multilingual text re- trieval,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2024, pp. 1393–1412
2024
-
[26]
mhubert-147: A compact multilingual hubert model,
M. Z. Boito, V . Iyer, N. Lagos, L. Besacier, and I. Calapode- scu, “mhubert-147: A compact multilingual hubert model,”arXiv preprint arXiv:2406.06371, 2024
-
[27]
A closer look into mixture-of-experts in large language models,
K. M. Lo, Z. Huang, Z. Qiu, Z. Wang, and J. Fu, “A closer look into mixture-of-experts in large language models,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 4427–4447
2025
-
[28]
Adscreen: A speech processing-based screening system for automatic identification of patients with alzheimer’s disease and related dementia,
M. Zolnoori, A. Zolnour, and M. Topaz, “Adscreen: A speech processing-based screening system for automatic identification of patients with alzheimer’s disease and related dementia,”Artificial intelligence in medicine, vol. 143, p. 102624, 2023
2023
-
[29]
Llmcare: early detection of cognitive impair- ment via transformer models enhanced by llm-generated synthetic data,
A. Zolnour, H. Azadmaleki, Y . Haghbin, F. Taherinezhad, M. J. M. Nezhad, S. Rashidi, M. Khani, A. Taleban, S. M. Sani, M. Dadkhahet al., “Llmcare: early detection of cognitive impair- ment via transformer models enhanced by llm-generated synthetic data,”Frontiers in Artificial Intelligence, vol. 8, p. 1669896, 2025
2025
-
[30]
(2025) Ai agent orchestration patterns
Microsoft. (2025) Ai agent orchestration patterns. [Online]. Available: Accessed: Feb. 20, 2026. [Online]. Avail- able: https://learn.microsoft.com/en-us/azure/architecture/ai-ml/ guide/ai-agent-design-patterns
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.