Monocular Avatar Reconstruction via Cascaded Diffusion Priors and UV-Space Differentiable Shading
Pith reviewed 2026-06-29 04:27 UTC · model grok-4.3
The pith
Cascaded LoRAs adapt a diffusion backbone in UV space to reconstruct relightable 4K PBR avatars from a single image after training on under 100 scans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
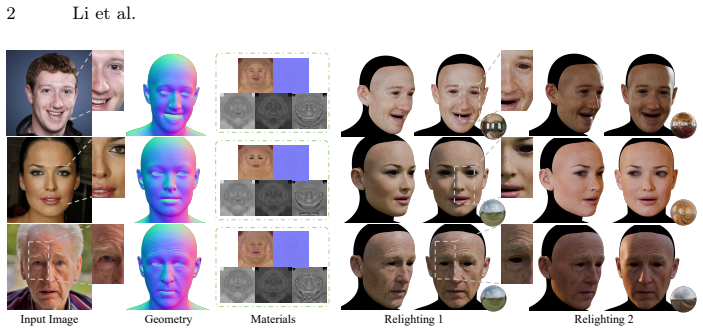
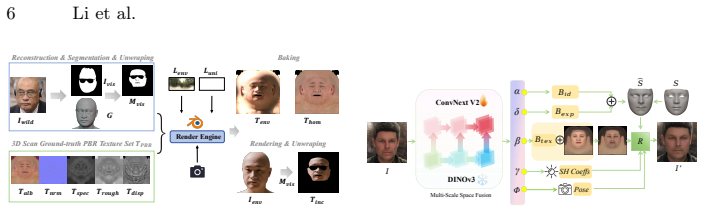
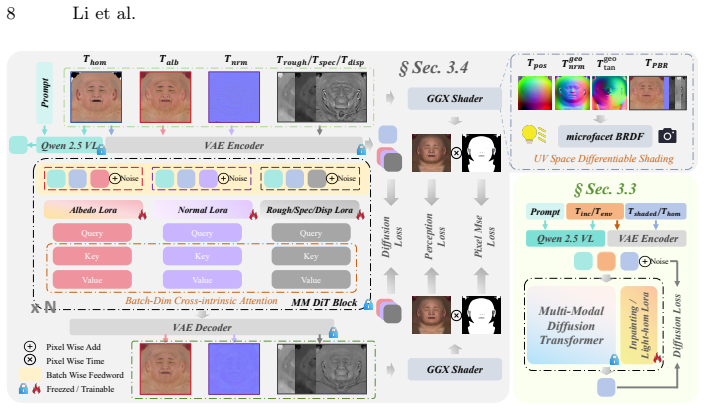
Sequential LoRA adaptations on a unified diffusion backbone first complete occluded UV textures via inpainting, then apply light homogenization and cross-intrinsic attention to synthesize pixel-aligned PBR maps, with a UV-space differentiable BRDF shading loss ensuring the outputs satisfy the rendering equation and produce 4K assets that generalize better than prior methods when trained on fewer than 100 real scans.
What carries the argument
Cascaded Low-Rank Adaptations (LoRAs) for inpainting, light-homogenization, and material decomposition in UV space, augmented by cross-intrinsic attention and supervised by a differentiable BRDF shading loss.
If this is right
- The method produces complete 4K PBR maps for albedo, normal, roughness, specular, and displacement.
- Assets exhibit superior realism and generalization compared with existing state-of-the-art pipelines.
- Reconstruction succeeds from a single in-the-wild image without reliance on large proprietary 3D datasets.
- Physical plausibility follows directly from enforcing the rendering equation during the decomposition stage.
Where Pith is reading between the lines
- The cascaded adaptation pattern could be tested on other inverse rendering tasks that currently lack paired PBR data.
- Public release of the weights may enable rapid integration into consumer 3D content tools.
- Extending the same UV-space loss to video inputs could be a direct next experiment for temporal consistency.
Load-bearing premise
The pre-trained diffusion backbone's semantic priors stay sufficiently intact after the sequential LoRA adaptations for the generated UV textures and PBR maps to remain pixel-aligned and physically consistent under only the shading loss.
What would settle it
Rendered images of the output PBR assets under new lighting conditions that deviate from expected material behavior or fail to match the input photo's appearance would show the decomposition does not hold.
Figures





read the original abstract
Reconstructing high-fidelity, relightable 3D avatars from a single in-the-wild image is a challenging ill-posed problem, primarily hindered by the scarcity of high-quality PBR data and the complexity of disentangling illumination from intrinsic materials. In this paper, we present a data-efficient framework that leverages the robust priors of a unified pre-trained diffusion backbone to sequentially address texture completion, delighting, and material decomposition. Unlike existing methods that rely on fragmented pipelines or extensive proprietary datasets, we utilize cascaded Low-Rank Adaptations (LoRAs) to adapt the strong generative prior of the diffusion model for each sub-task in UV space. Specifically, we first employ an Inpainting LoRA to complete missing UV textures caused by occlusion, leveraging the model's semantic understanding to generate semantically and photometrically coherent details. Subsequently, a Light-Homogenization LoRA and a novel Cross-Intrinsic Attention mechanism are introduced to remove baked-in lighting and collaboratively synthesize pixel-aligned PBR maps (Albedo, Normal, Roughness, Specular, and Displacement). To ensure physical plausibility, we impose a UV-space differentiable BRDF shading loss during the decomposition stage, forcing the generative process to adhere to the rendering equation without the artifacts typical of rasterization-based supervision. Extensive experiments demonstrate that our method, trained on fewer than 100 real 3D scans, generates comprehensive, 4K-resolution PBR assets with superior realism and generalization compared to state-of-the-art methods, and all training code and model weights will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a data-efficient framework for monocular reconstruction of high-fidelity, relightable 3D avatars from a single in-the-wild image. It uses cascaded Low-Rank Adaptations (LoRAs) on a pre-trained diffusion backbone to sequentially perform UV-space texture completion (Inpainting LoRA), light homogenization, and material decomposition into PBR maps (Albedo, Normal, Roughness, Specular, Displacement) via a novel Cross-Intrinsic Attention mechanism, supervised by a UV-space differentiable BRDF shading loss to enforce adherence to the rendering equation. The method claims to generate comprehensive 4K-resolution PBR assets with superior realism and generalization when trained on fewer than 100 real 3D scans.
Significance. If the central claims hold with supporting evidence, the work would offer a notable advance in data-efficient monocular avatar reconstruction by leveraging unified diffusion priors through sequential adaptations rather than fragmented pipelines or large proprietary datasets, potentially enabling more accessible production of relightable PBR assets for graphics and vision applications.
major comments (2)
- [Abstract] Abstract: the claim of 'superior realism and generalization compared to state-of-the-art methods' is asserted without any quantitative metrics, baseline comparisons, ablation studies, or error analysis, directly undermining evaluation of the central claim that the cascaded LoRA pipeline succeeds with <100 scans.
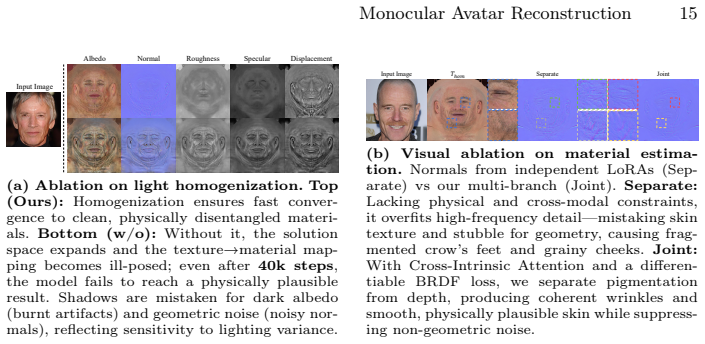
- [Abstract] Abstract (description of decomposition stage): the physical-plausibility claim rests on the UV-space differentiable BRDF shading loss forcing adherence to the rendering equation, yet no implementation details, formulation, or verification are supplied that this loss (which penalizes only rendered appearance) can enforce mutual pixel alignment and intrinsic uniqueness across the generated PBR maps after three sequential LoRA adaptations.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address the major comments point-by-point below and propose revisions where they strengthen the presentation of our work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'superior realism and generalization compared to state-of-the-art methods' is asserted without any quantitative metrics, baseline comparisons, ablation studies, or error analysis, directly undermining evaluation of the central claim that the cascaded LoRA pipeline succeeds with <100 scans.
Authors: The abstract serves as a high-level overview. The full manuscript provides quantitative metrics, baseline comparisons, ablation studies, and error analysis in the dedicated Experiments section, supporting the data-efficiency claim with fewer than 100 scans. We will update the abstract to include specific quantitative highlights from our results. revision: yes
-
Referee: [Abstract] Abstract (description of decomposition stage): the physical-plausibility claim rests on the UV-space differentiable BRDF shading loss forcing adherence to the rendering equation, yet no implementation details, formulation, or verification are supplied that this loss (which penalizes only rendered appearance) can enforce mutual pixel alignment and intrinsic uniqueness across the generated PBR maps after three sequential LoRA adaptations.
Authors: Details on the loss formulation, implementation, and verification are provided in the Methods and Experiments sections of the manuscript. The loss is designed to enforce adherence to the rendering equation through differentiable shading in UV space. We acknowledge the referee's point on potential need for more explicit verification of uniqueness and will add further analysis or clarification in the revised manuscript. revision: partial
Circularity Check
No circularity: pipeline uses external pre-trained diffusion weights and standard rendering equation
full rationale
The method adapts a pre-trained diffusion backbone with cascaded LoRAs for inpainting, light-homogenization, and decomposition, then applies a UV-space differentiable BRDF shading loss derived from the standard rendering equation. No equations or procedures define outputs in terms of the method's own fitted predictions or self-citations; training uses external <100 scans, and supervision enforces physical consistency externally rather than by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained diffusion model semantic priors remain usable after sequential LoRA fine-tuning for texture completion, delighting, and material decomposition.
- standard math The standard rendering equation can be evaluated differentiably in UV space to enforce physical consistency without rasterization artifacts.
Reference graph
Works this paper leans on
-
[1]
In: CGF (2023)
Aliari, M.A., Beauchamp, A., Popa, T., Paquette, E.: Face editing using part-based optimization of the latent space. In: CGF (2023)
2023
-
[2]
In: CVPR (2023)
Bai, H., Kang, D., Zhang, H., Pan, J., Bao, L.: Ffhq-uv: Normalized facial uv- texture dataset for 3d face reconstruction. In: CVPR (2023)
2023
-
[3]
In: CVPR (2021)
Bai, Z., Cui, Z., Liu, X., Tan, P.: Riggable 3d face reconstruction via in-network optimization. In: CVPR (2021)
2021
-
[4]
TOG (2021)
Bao, L., Lin, X., Chen, Y., Zhang, H., Wang, S., Zhe, X., Kang, D., Huang, H., Jiang, X., Wang, J., Yu, D., Zhang, Z.: High-fidelity 3d digital human head creation from rgb-d selfies. TOG (2021)
2021
-
[5]
TOG (2021)
Bao, L., Lin, X., Chen, Y., Zhang, H., Wang, S., Zhe, X., Kang, D., Huang, H., Jiang, X., Wang, J., et al.: High-fidelity 3d digital human head creation from rgb-d selfies. TOG (2021)
2021
-
[6]
In: SIG- GRAPH (1999)
Blanz, V., Vetter, T.: A morphable model for the synthesis of 3d faces. In: SIG- GRAPH (1999)
1999
-
[7]
In: ICCV (2017)
Bulat, A., Tzimiropoulos, G.: How far are we from solving the 2d & 3d face align- ment problem? (and a dataset of 230,000 3d facial landmarks). In: ICCV (2017)
2017
-
[8]
In: ECCV (2022)
Chai, Z., Zhang, H., Ren, J., Kang, D., Xu, Z., Zhe, X., Yuan, C., Bao, L.: Realy: Rethinking the evaluation of 3d face reconstruction. In: ECCV (2022)
2022
-
[9]
In: ICCV (2023)
Chai, Z., Zhang, T., He, T., Tan, X., Baltrusaitis, T., Wu, H., Li, R., Zhao, S., Yuan, C., Bian, J.: Hiface: High-fidelity 3d face reconstruction by learning static and dynamic details. In: ICCV (2023)
2023
-
[10]
TOG (1982)
Cook, R.L., Torrance, K.E.: A reflectance model for computer graphics. TOG (1982)
1982
-
[11]
Dai, J., Wang, A., Ni, B., Cao, T.: High-quality facial albedo generation for 3d face reconstruction from a single image using a coarse-to-fine approach. arXiv:2506.13233 (2025)
arXiv 2025
-
[12]
In: CVPR (2022)
Daněček, R., Black, M.J., Bolkart, T.: Emoca: Emotion driven monocular face capture and animation. In: CVPR (2022)
2022
-
[13]
Danecek, R., Black, M.J., Bolkart, T.: Emoca: Emotion driven monocular face capture and animation. In: CVPR (2022) Monocular Avatar Reconstruction 25 3DDFA-V3HRNDeep3DOursDECASMIRK EMOCA Fig.A5:Qualitativecomparisonofgeometricfidelity.Wecompareourdisplaced geometry against various state-of-the-art methods. While DECA and EMOCA attempt to reconstruct faces...
2022
-
[14]
In: ICLR (2023)
De Luigi, L., Cardace, A., Spezialetti, R., Zama Ramirez, P., Salti, S., Di Stefano, L.: Deep learning on implicit neural representations of shapes. In: ICLR (2023)
2023
-
[15]
In: ACM SIGGRAPH 2012 Courses
Debevec, P.: The light stages and their applications to photoreal digital actors. In: ACM SIGGRAPH 2012 Courses. pp. 1–10 (2012)
2012
-
[16]
In: CVPR (2018)
Deng, J., Cheng, S., Xue, N., Zhou, Y., Zafeiriou, S.: Uv-gan: Adversarial facial uv map completion for pose-invariant face recognition. In: CVPR (2018)
2018
-
[17]
In: CVPRW (2019)
Deng, Y., Yang, J., Xu, S., Chen, D., Jia, Y., Tong, X.: Accurate 3d face reconstruc- tion with weakly-supervised learning: From single image to image set. In: CVPRW (2019)
2019
-
[18]
EG (2021)
Dib, A., Bharaj, G., Ahn, J., Thébault, C., Gosselin, P.H., Romeo, M., Chevallier, L.: Practical face reconstruction via differentiable ray tracing. EG (2021)
2021
-
[19]
Dib, A., Hafemann, L.G., Got, E., Anderson, T., Fadaeinejad, A., Cruz, R.M., Car- bonneau, M.A.: Mosar: Monocular semi-supervised model for avatar reconstruction 26 Li et al. 3DDFA-V3HRNDeep3D OursDECASMIRK EMOCA Fig.A6: Qualitative comparison of geometric fidelity.Compared to alternative geometric estimation methods, our approach leverages normal and dis...
2024
-
[20]
In: SIGGRAPH (2021)
Feng, Y., Feng, H., Black, M.J., Bolkart, T.: Learning an animatable detailed 3D face model from in-the-wild images. In: SIGGRAPH (2021)
2021
-
[21]
In: WACV (2025)
Galanakis, S., Lattas, A., Moschoglou, S., Zafeiriou, S.: Fitdiff: Robust monocular 3d facial shape and reflectance estimation using diffusion models. In: WACV (2025)
2025
-
[22]
In: CVPR (2021)
Gecer, B., Deng, J., Zafeiriou, S.: Ostec: One-shot texture completion. In: CVPR (2021)
2021
-
[23]
In: CVPR (2019)
Gecer, B., Ploumpis, S., Kotsia, I., Zafeiriou, S.: Ganfit: Generative adversarial network fitting for high fidelity 3d face reconstruction. In: CVPR (2019)
2019
-
[24]
In: ECCV (2020)
Guo, J., Zhu, X., Yang, Y., Yang, F., Lei, Z., Li, S.Z.: Towards fast, accurate and stable 3d dense face alignment. In: ECCV (2020)
2020
-
[25]
ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR (2022)
2022
-
[26]
CVPR (2017)
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. CVPR (2017)
2017
-
[27]
Jiang, D., Liu, D., Wang, Z., Wu, Q., Jin, X., Liu, D., Li, Z., Wang, M., Gao, P., Yang, H.: Distribution matching distillation meets reinforcement learning. arXiv:2511.13649 (2025)
arXiv 2025
-
[28]
In: SIGGRAPH (1986)
Kajiya, J.T.: The rendering equation. In: SIGGRAPH (1986)
1986
-
[29]
In: CVPR (2019)
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: CVPR (2019)
2019
-
[30]
In: CVPR (2020) Monocular Avatar Reconstruction 27
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan. In: CVPR (2020) Monocular Avatar Reconstruction 27
2020
-
[31]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv:2506.15742 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
In: CVPR (2023)
Lattas, A., Moschoglou, S., Ploumpis, S., Gecer, B., Deng, J., Zafeiriou, S.: Fitme: Deep photorealistic 3d morphable model avatars. In: CVPR (2023)
2023
-
[33]
in-the- wild
Lattas, A., Moschoglou, S., Gecer, B., Ploumpis, S., Triantafyllou, V., Ghosh, A., Zafeiriou, S.: Avatarme: Realistically renderable 3d facial reconstruction "in-the- wild". In: CVPR (2020)
2020
-
[34]
PAMI (2022)
Lattas, A., Moschoglou, S., Ploumpis, S., Gecer, B., Ghosh, A., Zafeiriou, S.: Avatarme++: Facial shape and brdf inference with photorealistic rendering-aware gans. PAMI (2022)
2022
-
[35]
In: CVPR (2020)
Lee, C.H., Liu, Z., Wu, L., Luo, P.: Maskgan: Towards diverse and interactive facial image manipulation. In: CVPR (2020)
2020
-
[36]
In: CVPR (2023)
Lei, B., Ren, J., Feng, M., Cui, M., Xie, X.: A hierarchical representation network for accurate and detailed face reconstruction from in-the-wild images. In: CVPR (2023)
2023
-
[37]
Li, H., Chen, H., Ye, C., Chen, Z., Li, B., Xu, S., Guo, X., Liu, X., Wang, Y., Zhang, B., Ikehata, S., Shi, B., Rao, A., Zhao, H.: Light of normals: Unified feature representation for universal photometric stereo. arXiv:2506.18882 (2025)
-
[38]
In: CVPR (2024)
Li, H., Feng, Y., Xue, S., Liu, X., Zeng, B., Li, S., Liu, B., Liu, J., Han, S., Zhang, B.: Uv-idm: identity-conditioned latent diffusion model for face uv-texture generation. In: CVPR (2024)
2024
-
[39]
Li, H., Ye, C., Chen, H., Xiao, W., Yan, Z., Xiao, L., Chen, Z., Xiang, J., Xu, S., Liu, X., Wang, Y., Zhang, B., Han, X., Yang, J., Zhao, H.: Near: Coupled neural asset-renderer stack. arXiv:2511.18600 (2025)
arXiv 2025
-
[40]
In: CVPR (2020)
Li, R., Bladin, K., Zhao, Y., Chinara, C., Ingraham, O., Xiang, P., Ren, X., Prasad, P., Kishore, B., Xing, J., Li, H.: Learning formation of physically-based face at- tributes. In: CVPR (2020)
2020
-
[41]
SIGGRAPH Asia (2017)
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4D scans. SIGGRAPH Asia (2017)
2017
-
[42]
In: NeurIPS (2017)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: NeurIPS (2017)
2017
-
[43]
MediaPipe: A Framework for Building Perception Pipelines
Lugaresi, C., Tang, J., Nash, H., McClanahan, C., Uboweja, E., Hays, M., Zhang, F., Chang, C.L., Yong, M.G., Lee, J., et al.: Mediapipe: A framework for building perception pipelines. arXiv:1906.08172 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[44]
In: CVPR (2023)
Papantoniou, F., Lattas, A., Moschoglou, S., Zafeiriou, S.: Relightify: Relightable 3d faces from a single image via diffusion models. In: CVPR (2023)
2023
-
[45]
In: AVSS (2009)
Paysan, P., Knothe, R., Amberg, B., Romdhani, S., Vetter, T.: A 3d face model for pose and illumination invariant face recognition. In: AVSS (2009)
2009
-
[46]
In: WACV (2024)
Rai, A., Gupta, H., Pandey, A., Carrasco, F.V., Takagi, S.J., Aubel, A., Kim, D., Prakash, A., De la Torre, F.: Towards realistic generative 3d face models. In: WACV (2024)
2024
-
[47]
In: ECCV (2018)
Ranjan, A., Bolkart, T., Sanyal, S., Black, M.J.: Generating 3d faces using convo- lutional mesh autoencoders. In: ECCV (2018)
2018
-
[48]
In: CVPR (2024)
Retsinas, G., Filntisis, P.P., Danecek, R., Abrevaya, V.F., Roussos, A., Bolkart, T., Maragos, P.: 3d facial expressions through analysis-by-neural-synthesis. In: CVPR (2024)
2024
-
[49]
In: CVPR (2022) 28 Li et al
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022) 28 Li et al
2022
-
[50]
In: CVPR (2019)
Sanyal, S., Bolkart, T., Feng, H., Black, M.: Learning to regress 3d face shape and expression from an image without 3d supervision. In: CVPR (2019)
2019
-
[51]
In: ECCV (2024)
Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distilla- tion. In: ECCV (2024)
2024
-
[52]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv:2508.10104 (2025)
Pith/arXiv arXiv 2025
-
[53]
In: CVPR (2020)
Smith, W.A.P., Seck, A., Dee, H., Tiddeman, B., Tenenbaum, J., Egger, B.: A morphable face albedo model. In: CVPR (2020)
2020
-
[54]
In: ICML (2023)
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: ICML (2023)
2023
-
[56]
LongCat-Image Technical Report
Team, M.L., Ma, H., Tan, H., Huang, J., Wu, J., He, J.Y., Gao, L., Xiao, S., Wei, X., Ma, X., et al.: Longcat-image technical report. arXiv:2512.07584 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Team, Z.I.: Z-image: An efficient image generation foundation model with single- stream diffusion transformer. arXiv:2511.22699 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
In: CVPR (2019)
Tran, L., Liu, F., Liu, X.: Towards high-fidelity nonlinear 3d face morphable model. In: CVPR (2019)
2019
-
[59]
In: CVPR (2018)
Tran, L., Liu, X.: Nonlinear 3d face morphable model. In: CVPR (2018)
2018
-
[60]
In: CVPR (2025)
Wang, C., Kang, D., Sun, H., Qian, S., Wang, Z., Bao, L., Zhang, S.H.: Mega: Hybrid mesh-gaussian head avatar for high-fidelity rendering and head editing. In: CVPR (2025)
2025
-
[61]
Wang, H.: A review of 3d face reconstruction from a single image. arXiv:2110.09299 (2021)
-
[62]
In: CVPR (2022)
Wang, L., Chen, Z., Yu, T., Ma, C., Li, L., Liu, Y.: Faceverse: a fine-grained and detail-controllable 3d face morphable model from a hybrid dataset. In: CVPR (2022)
2022
-
[63]
In: ICCVW (2021)
Wang, X., Xie, L., Dong, C., Shan, Y.: Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In: ICCVW (2021)
2021
-
[64]
In: CVPR (2024)
Wang, Z., Zhu, X., Zhang, T., Wang, B., Lei, Z.: 3d face reconstruction with the geometric guidance of facial part segmentation. In: CVPR (2024)
2024
-
[65]
In: CVPR (2023)
Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon, I.S., Xie, S.: Convnext v2: Co-designing and scaling convnets with masked autoencoders. In: CVPR (2023)
2023
-
[66]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
arXiv preprint arXiv:2508.19754 (2025)
Wu, Y., Wu, Y., Li, W., Lu, Y., Feng, K., Chen, X.: Fastavatar: Towards uni- fied fast high-fidelity 3d avatar reconstruction with large gaussian reconstruction transformers. arXiv:2508.19754 (2025)
-
[68]
In: CVPR (2025)
Yang, X., Taketomi, T., Endo, Y., Kanamori, Y.: Freeuv: Ground-truth-free re- alistic facial uv texture recovery via cross-assembly inference strategy. In: CVPR (2025)
2025
-
[69]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zheng, M., Yang, H., Huang, D., Chen, L.: Imface: A nonlinear 3d morphable face model with implicit neural representations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20343–20352 (2022) Monocular Avatar Reconstruction 29
2022
-
[70]
PAMI (2025)
Zheng, M., Zhang, H., Yang, H., Chen, L., Huang, D.: Imface++: A sophisticated nonlinear 3d morphable face model with implicit neural representations. PAMI (2025)
2025
-
[71]
In: CVPR (2022)
Zheng, Q., Deng, J., Zhu, Z., Li, Y., Zafeiriou, S.: Decoupled multi-task learning with cyclical self-regulation for face parsing. In: CVPR (2022)
2022
-
[72]
In: CVPR (2024)
Zhou, M., Hyder, R., Xuan, Z., Qi, G.: Ultravatar: A realistic animatable 3d avatar diffusion model with authenticity guided textures. In: CVPR (2024)
2024
-
[73]
in-the-wild
Zielonka, W., Bolkart, T., Thies, J.: Towards metrical reconstruction of human faces. In: ECCV (2022) 30 Li et al. Fig.A7:For "in-the-wild" images, our pipeline robustly infers across different ethnic- ities, ages, and genders. This inference produces complete PBR textures and relighting renderings under a variety of environmental lighting conditions. Mon...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.