HAT-4D: Lifting Monocular Video for 4D Multi-Object Interactions via Human-Agent Collaboration
Pith reviewed 2026-06-29 04:14 UTC · model grok-4.3
The pith
HAT-4D reconstructs 4D multi-object interactions from monocular videos by combining vision models with targeted human feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
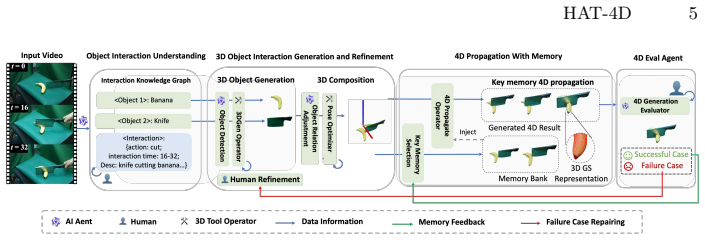
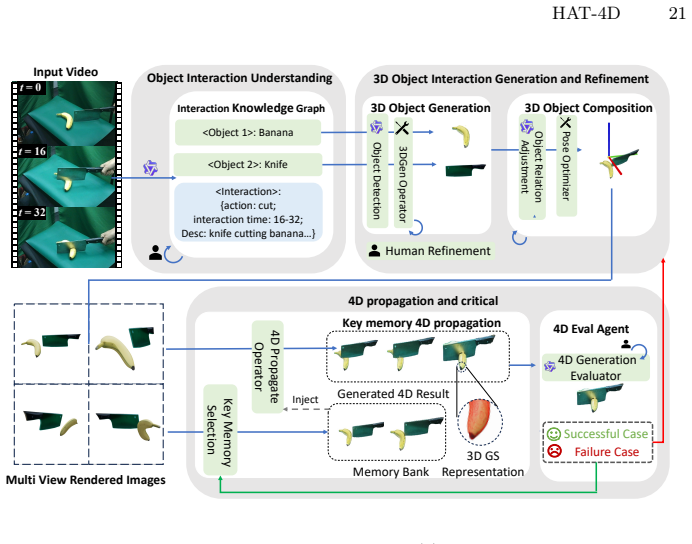
HAT-4D is the first agentic framework that integrates VLMs with a multi-level human-in-the-loop feedback mechanism to reconstruct the 3D geometry, temporal dynamics, and physical interactions of multiple objects from a single monocular video, yielding physically plausible assets without multi-camera rigs and enabling the MVOIK-4D benchmark.
What carries the argument
The multi-level human-in-the-loop feedback mechanism integrated with VLMs that resolves depth ambiguities and interaction-induced occlusions during 3D generation and 4D propagation.
If this is right
- HAT-4D reaches state-of-the-art scores on most evaluation metrics while preserving competitive semantic alignment.
- Datasets generated by HAT-4D raise baseline model performance when used for fine-tuning.
- The framework produces the open-world MVOIK-4D benchmark together with a multi-dimensional protocol that tests physical plausibility and temporal consistency.
- The method supplies scalable 4D interaction data for Embodied AI and VLA training without requiring multi-camera capture setups.
Where Pith is reading between the lines
- The same feedback loop could be tested on single-object or static-scene videos to measure how much human input is still needed once interaction complexity drops.
- If the generated assets prove stable in physics simulators, they could directly seed large-scale robot training environments drawn from everyday video sources.
- The benchmark protocol itself might serve as a template for evaluating other video-to-4D pipelines that claim physical realism.
Load-bearing premise
A small amount of human feedback suffices to resolve depth ambiguities and occlusions consistently across diverse in-the-wild videos.
What would settle it
Compare physical-plausibility and temporal-consistency scores on a held-out set of complex interaction videos when the system runs with zero human feedback versus the reported human-assisted version; a negligible gap would undermine the assumption.
Figures

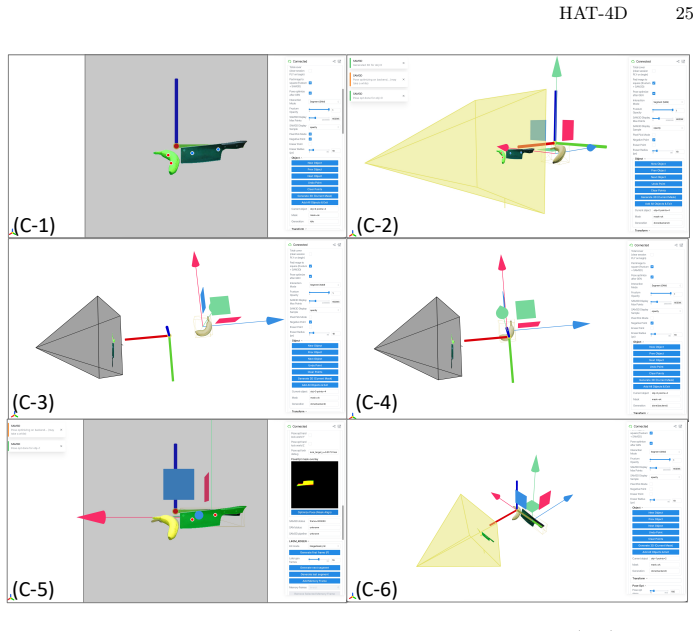
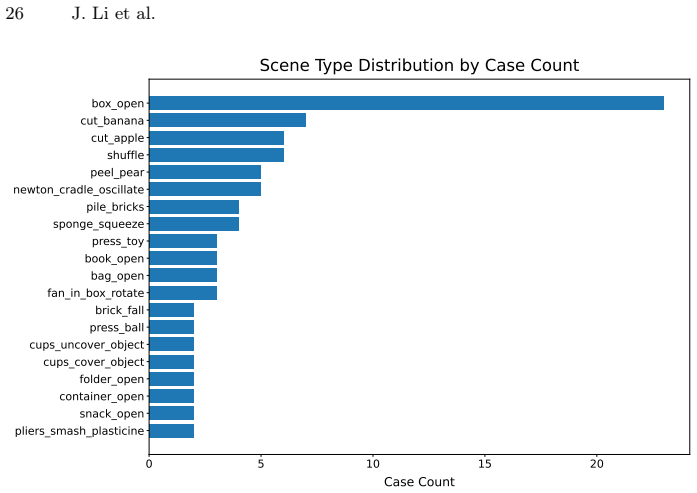
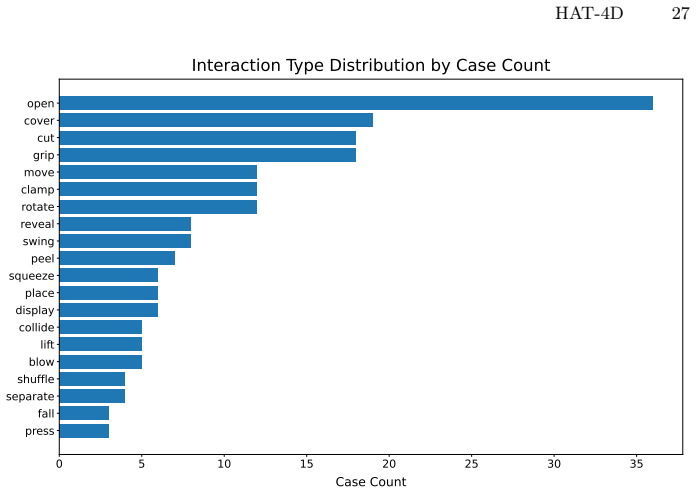
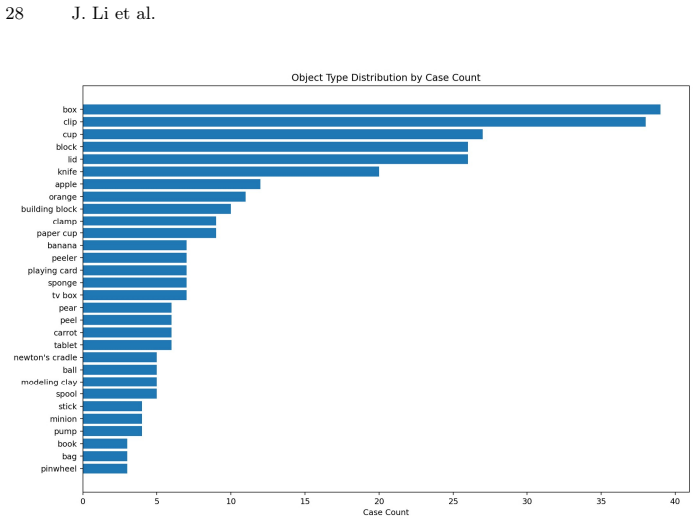

read the original abstract
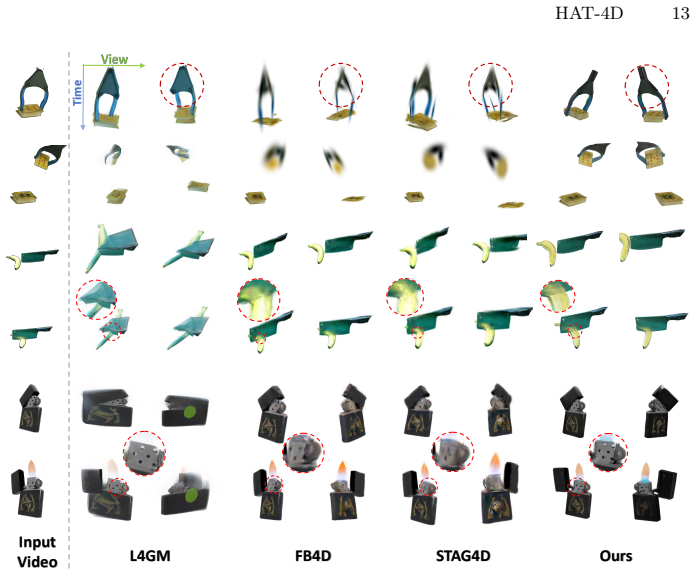
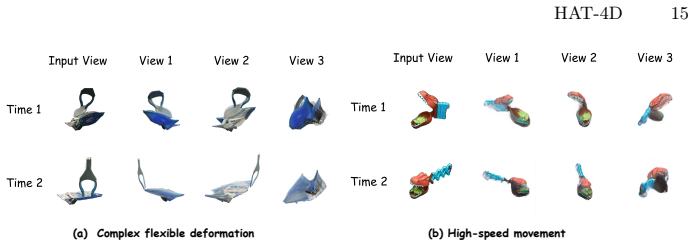
Extracting dynamic 4D object interactions from massive, in-the-wild monocular videos offers a highly efficient data collection pathway for scaling Embodied AI and training VLAs. However, existing monocular 4D reconstruction methods primarily focus on isolated objects, often failing under the severe occlusions and complex dynamics inherent in multi-object interactions. To bridge this gap, we propose HAT-4D, the first agentic framework designed to reconstruct the 3D geometry, temporal dynamics, and physical interactions of multiple objects from a single video. By integrating VLMs with a multi-level human-in-the-loop feedback mechanism, HAT-4D efficiently resolves depth ambiguities and interaction-induced occlusions during 3D generation and 4D propagation, yielding physically plausible assets without relying on expensive multicamera rigs. As a scalable data engine, HAT-4D facilitates the creation of MVOIK-4D, an open-world benchmark for monocular 4D interaction reconstruction, accompanied by a novel multi-dimensional evaluation protocol focused on physical plausibility and temporal consistency. Extensive experiments demonstrate that HAT-4D achieves SOTA performance on most evaluation metrics, while maintaining competitive semantic alignment. Ablation studies show that introducing a small amount of human feedback improves interaction reconstruction. Moreover, the data produced by HAT-4D effectively improves baseline performance when used for fine-tuning. Our data and code are available at https://lijiaxin0111.github.io/HAT4D/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HAT-4D, the first agentic framework that integrates VLMs with a multi-level human-in-the-loop feedback mechanism to reconstruct 3D geometry, temporal dynamics, and physical interactions of multiple objects from monocular in-the-wild videos. It produces the MVOIK-4D benchmark with a new multi-dimensional evaluation protocol focused on physical plausibility and temporal consistency, claims SOTA results on most metrics while maintaining semantic alignment, shows via ablations that small human feedback improves reconstruction, and demonstrates that the generated data improves baseline performance on fine-tuning.
Significance. If the central claims hold with proper quantitative support, HAT-4D would offer a practical, hardware-light pathway for generating large-scale 4D interaction data for Embodied AI and VLAs. The open benchmark, evaluation protocol, and code release would provide a reusable resource for standardizing assessment of monocular 4D multi-object methods.
major comments (2)
- [Abstract] Abstract: the claim that 'a small amount of human feedback improves interaction reconstruction' and enables scalable resolution of depth ambiguities/occlusions is load-bearing for both the SOTA reconstruction results and the downstream data-improvement claim, yet the abstract (and the reviewed portions) supply no quantitative metrics on feedback volume (interventions per video or total time), inter-video consistency, or failure modes when feedback is minimized.
- [Abstract] Abstract: SOTA performance is asserted on 'most evaluation metrics' with 'competitive semantic alignment,' but the abstract provides no details on baselines, error bars, dataset splits, or the precise definition/measurement of physical plausibility, preventing verification of the central empirical claims.
minor comments (1)
- [Abstract] The abstract states that data and code are available at a GitHub link; confirming that the released assets include the exact human-feedback logs and evaluation scripts would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each point below and will revise the abstract accordingly to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'a small amount of human feedback improves interaction reconstruction' and enables scalable resolution of depth ambiguities/occlusions is load-bearing for both the SOTA reconstruction results and the downstream data-improvement claim, yet the abstract (and the reviewed portions) supply no quantitative metrics on feedback volume (interventions per video or total time), inter-video consistency, or failure modes when feedback is minimized.
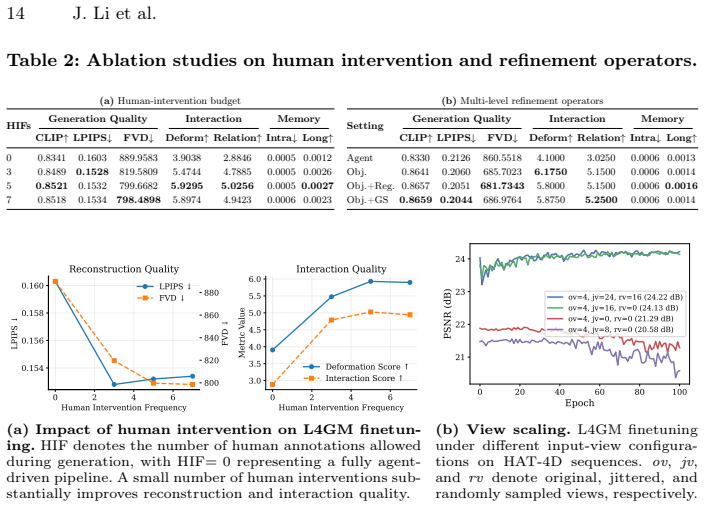
Authors: We agree that the abstract would be strengthened by including quantitative details on human feedback volume and costs. The manuscript's ablation studies (Section 4.3) demonstrate the benefit of limited human input, and we will revise the abstract to report key figures such as average interventions per video and time per sequence drawn from those experiments. revision: yes
-
Referee: [Abstract] Abstract: SOTA performance is asserted on 'most evaluation metrics' with 'competitive semantic alignment,' but the abstract provides no details on baselines, error bars, dataset splits, or the precise definition/measurement of physical plausibility, preventing verification of the central empirical claims.
Authors: We acknowledge that the abstract is high-level and omits these specifics. The experiments section details the baselines, MVOIK-4D splits, metrics (including physical plausibility and temporal consistency), and results with variability measures. We will revise the abstract to name the primary baselines and briefly define the evaluation focus. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents HAT-4D as an agentic framework that integrates external VLMs with a multi-level human-in-the-loop mechanism to resolve depth ambiguities and occlusions in monocular 4D reconstruction. No equations, fitted parameters, or self-referential predictions appear in the abstract or description. Claims of SOTA performance and data utility rest on empirical results from external components rather than any reduction to self-defined inputs, self-citations, or ansatzes. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs combined with limited human feedback can reliably resolve depth ambiguities and occlusions in multi-object interaction videos
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2311.15127 (2023)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
Pith/arXiv arXiv 2023
-
[3]
Budd, S., Robinson, E.C., Kainz, B.: A survey on active learning and human-in- the-loop deep learning for medical image analysis. Medical Image Analysis71, 102062 (Jul 2021).https://doi.org/10.1016/j.media.2021.102062,http:// dx.doi.org/10.1016/j.media.2021.102062
-
[4]
Cen, J., Fang, J., Zhou, Z., Yang, C., Xie, L., Zhang, X., Shen, W., Tian, Q.: Segment anything in 3d with radiance fields (2024),https://arxiv.org/abs/ 2304.12308
arXiv 2024
-
[5]
arXiv preprint arXiv:2601.14253 (2026)
Chen, H., Chen, X., Zhang, Y., Xu, Z., Chen, A.: Motion 3-to-4: 3d motion recon- struction for 4d synthesis. arXiv preprint arXiv:2601.14253 (2026)
arXiv 2026
-
[6]
arXiv preprint arXiv:2503.09631 (2025)
Chen, J., Zhang, B., Tang, X., Wonka, P.: V2m4: 4d mesh animation reconstruction from a single monocular video. arXiv preprint arXiv:2503.09631 (2025)
arXiv 2025
-
[7]
Chen, J., Gao, D., Lin, K.Q., Shou, M.Z.: Affordance grounding from demonstra- tion video to target image (2023),https://arxiv.org/abs/2303.14644
arXiv 2023
-
[8]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Chen, Y., Guo, S., Yang, T., Ding, L., Yu, X., Gu, J., Xue, T.: 4dslomo: 4d recon- struction for high speed scene with asynchronous capture. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–11 (2025)
2025
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, Z., Li, J., Liang, J., Tan, L., Guo, Y., Lu, C., Li, Y.L.: Mˆ 3-vos: Multi-phase, multi-transition, and multi-scenery video object segmentation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29193–29202 (2025)
2025
-
[10]
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., Zhu, Y., Zhang, W., Luo, Z., Zhao, D., Bing, L.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms (2024),https://arxiv.org/abs/2406.07476
Pith/arXiv arXiv 2024
-
[11]
Advances in Neural Information Processing Systems36, 35799–35813 (2023) HAT-4D 17
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., et al.: Objaverse-xl: A universe of 10m+ 3d objects. Advances in Neural Information Processing Systems36, 35799–35813 (2023) HAT-4D 17
2023
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023)
2023
-
[13]
Do, T.T., Nguyen, A., Reid, I.: Affordancenet: An end-to-end deep learning ap- proach for object affordance detection (2018),https://arxiv.org/abs/1709. 07326
2018
-
[14]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Geng, C., Zhang, Y., Wu, S., Wu, J.: Birth and death of a rose. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26102–26113 (2025)
2025
-
[15]
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d (2024), https://arxiv.org/abs/2311.04400
Pith/arXiv arXiv 2024
-
[16]
Hou, C., Ze, Y., Fu, Y., Gao, Z., Hu, S., Yu, Y., Zhang, S., Xu, H.: 4d visual pre-training for robot learning (2025),https://arxiv.org/abs/2508.17230
arXiv 2025
-
[17]
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: Vbench: Comprehensive benchmark suite for video generative models (2023),https:// arxiv.org/abs/2311.17982
arXiv 2023
-
[18]
Hunyuan3D, T., :, Zhang, B., Guo, C., Guo, D., Liu, H., Yan, H., Shi, H., Yu, J., Xu, J., Huang, J., Li, K., Wang, L., Linus, Wang, P., Lin, Q., Tang, R., Yang, X., Li, Y., Guan, Y., Zhao, Y., Yang, Y., Lai, Z., Liang, Z., Zhao, Z.: Hy3d-bench: Generation of 3d assets (2026),https://arxiv.org/abs/2602.03907
arXiv 2026
-
[19]
Ji, K., Shi, Y., Jin, Z., Chen, K., Xu, L., Ma, Y., Yu, J., Wang, J.: Towards immersive human-x interaction: A real-time framework for physically plausible motion synthesis (2025),https://arxiv.org/abs/2508.02106
arXiv 2025
-
[20]
arXiv preprint arXiv:2311.02848 (2023)
Jiang,Y.,Zhang,L.,Gao,J.,Hu,W.,Yao,Y.:Consistent4d:Consistent360{\deg} dynamic object generation from monocular video. arXiv preprint arXiv:2311.02848 (2023)
arXiv 2023
-
[21]
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything (2023),https://arxiv.org/abs/2304.02643
Pith/arXiv arXiv 2023
-
[22]
Krishna,R.,Zhu,Y.,Groth,O.,Johnson,J.,Hata,K.,Kravitz,J.,Chen,S.,Kalan- tidis, Y., Li, L.J., Shamma, D.A., Bernstein, M.S., Li, F.F.: Visual genome: Con- necting language and vision using crowdsourced dense image annotations (2016), https://arxiv.org/abs/1602.07332
Pith/arXiv arXiv 2016
-
[23]
Advances in Neural Information Processing Systems37, 62189–62222 (2024)
Li, B., Zheng, C., Zhu, W., Mai, J., Zhang, B., Wonka, P., Ghanem, B.: Vivid-zoo: Multi-view video generation with diffusion model. Advances in Neural Information Processing Systems37, 62189–62222 (2024)
2024
-
[24]
arXiv preprint arXiv:2503.20784 (2025)
Li, J., Gao, H.a., Li, W., Chi, H., Liu, C., Du, C., Liu, Y., Gao, M., Zhang, G., Zhang, Z., et al.: Fb-4d: Spatial-temporal coherent dynamic 3d content generation with feature banks. arXiv preprint arXiv:2503.20784 (2025)
arXiv 2025
-
[25]
Li, R., Zhang, S., He, X.: Sgtr: End-to-end scene graph generation with transformer (2022),https://arxiv.org/abs/2112.12970
arXiv 2022
-
[26]
Li, S., Zhang, H., Chen, X., Wang, Y., Ban, Y.: Genhoi: Generalizing text-driven 4d human-object interaction synthesis for unseen objects (2025),https://arxiv. org/abs/2506.15483
arXiv 2025
-
[27]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Y.L., Xu, Y., Xu, X., Mao, X., Yao, Y., Liu, S., Lu, C.: Beyond object recog- nition: A new benchmark towards object concept learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20029–20040 (2023) 18 J. Li et al
2023
-
[28]
Liu, R., Wu, R., Hoorick, B.V., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3d object (2023),https://arxiv.org/abs/2303. 11328
2023
-
[29]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Liu, X., Wen, B., Liu, X., Zhou, Z., Fan, H., Lu, C., Ma, L., Chen, Y., Li, Y.L.: Interacted object grounding in spatio-temporal human-object interactions. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 5622–5630 (2025)
2025
-
[30]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Lu, C.Y., Zhou, P., Xing, A., Pokhariya, C., Dey, A., Shah, I.N., Mavidipalli, R., Hu, D., Comport, A.I., Chen, K., et al.: Diva-360: The dynamic visual dataset for immersive neural fields. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 22466–22476 (2024)
2024
-
[31]
arXiv preprint arXiv:2506.18890 (2025)
Ma, Z., Chen, X., Yu, S., Bi, S., Zhang, K., Ziwen, C., Xu, S., Yang, J., Xu, Z., Sunkavalli, K., et al.: 4d-lrm: Large space-time reconstruction model from and to any view at any time. arXiv preprint arXiv:2506.18890 (2025)
arXiv 2025
-
[32]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Mou, L., Lei, J., Wang, C., Liu, L., Daniilidis, K.: Dimo: Diverse 3d motion gener- ation for arbitrary objects. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 14357–14368 (2025)
2025
-
[33]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[34]
Advances in Neural Information Processing Systems37, 56828–56858 (2024)
Ren, J., Xie, C., Mirzaei, A., Kreis, K., Liu, Z., Torralba, A., Fidler, S., Kim, S.W., Ling, H., et al.: L4gm: Large 4d gaussian reconstruction model. Advances in Neural Information Processing Systems37, 56828–56858 (2024)
2024
-
[35]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models (2021)
2021
-
[36]
Settles, B.: Active learning literature survey (2009)
2009
-
[37]
arXiv preprint arXiv:2508.10104 (2025)
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
Pith/arXiv arXiv 2025
-
[38]
Team, S.D., Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., Lin, A., Liu, J., Ma, Z., Sagar, A., Song, B., Wang, X., Yang, J., Zhang, B., Dollár, P., Gkioxari, G., Feiszli, M., Malik, J.: Sam 3d: 3dfy anything in images (2025),https://arxiv.org/abs/2511.16624
Pith/arXiv arXiv 2025
-
[39]
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Fvd: A new metric for video generation (2019)
2019
-
[40]
In: European Conference on Computer Vision
Voleti, V., Yao, C.H., Boss, M., Letts, A., Pankratz, D., Tochilkin, D., Laforte, C., Rombach, R., Jampani, V.: Sv3d: Novel multi-view synthesis and 3d genera- tion from a single image using latent video diffusion. In: European Conference on Computer Vision. pp. 439–457. Springer (2024)
2024
-
[41]
Wang, B., Wu, V., Wu, B., Keutzer, K.: Latte: Accelerating lidar point cloud annotation via sensor fusion, one-click annotation, and tracking (2019),https: //arxiv.org/abs/1904.09085
Pith/arXiv arXiv 2019
-
[42]
IEEE Transac- tions on Pattern Analysis and Machine Intelligence41(7), 1559–1572 (Jul 2019)
Wang, G., Zuluaga, M.A., Li, W., Pratt, R., Patel, P.A., Aertsen, M., Doel, T., David, A.L., Deprest, J., Ourselin, S., Vercauteren, T.: Deepigeos: A deep interactive geodesic framework for medical image segmentation. IEEE Transac- tions on Pattern Analysis and Machine Intelligence41(7), 1559–1572 (Jul 2019). https://doi.org/10.1109/tpami.2018.2840695,htt...
-
[43]
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer (2025),https://arxiv.org/abs/2503. 11651
2025
-
[44]
Wang, Y., Li, K., Li, X., Yu, J., He, Y., Wang, C., Chen, G., Pei, B., Yan, Z., Zheng, R., Xu, J., Wang, Z., Shi, Y., Jiang, T., Li, S., Zhang, H., Huang, Y., Qiao, Y., Wang, Y., Wang, L.: Internvideo2: Scaling foundation models for multimodal video understanding (2024),https://arxiv.org/abs/2403.15377
arXiv 2024
-
[45]
arXiv preprint arXiv:2601.11421 (2026)
Wang, Z., Liu, C., Xiang, Y., Zhang, R., Hao, Q., Lu, H., Chen, H., Feng, Z., Zheng, K., Ye, D., et al.: The great march 100: 100 detail-oriented tasks for evaluating embodied ai agents. arXiv preprint arXiv:2601.11421 (2026)
arXiv 2026
-
[46]
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering (2024),https: //arxiv.org/abs/2310.08528
arXiv 2024
-
[47]
arXiv preprint arXiv:2407.17470 (2024)
Xie, Y., Yao, C.H., Voleti, V., Jiang, H., Jampani, V.: Sv4d: Dynamic 3d con- tent generation with multi-frame and multi-view consistency. arXiv preprint arXiv:2407.17470 (2024)
arXiv 2024
-
[48]
arXiv preprint arXiv:2503.16396 (2025)
Yao, C.H., Xie, Y., Voleti, V., Jiang, H., Jampani, V.: Sv4d 2.0: Enhancing spatio- temporal consistency in multi-view video diffusion for high-quality 4d generation. arXiv preprint arXiv:2503.16396 (2025)
arXiv 2025
-
[49]
Yu, W., Zhu, S., Yang, T., Chen, C.: Consistency-based active learning for object detection (2022),https://arxiv.org/abs/2103.10374
arXiv 2022
-
[50]
Zeng, J., Bu, Q., Wang, B., Xia, W., Chen, L., Dong, H., Song, H., Wang, D., Hu, D., Luo, P., Cui, H., Zhao, B., Li, X., Qiao, Y., Li, H.: Learning manipulation by predicting interaction (2024),https://arxiv.org/abs/2406.00439
arXiv 2024
-
[51]
In: European Confer- ence on Computer Vision
Zeng, Y., Jiang, Y., Zhu, S., Lu, Y., Lin, Y., Zhu, H., Hu, W., Cao, X., Yao, Y.: Stag4d: Spatial-temporal anchored generative 4d gaussians. In: European Confer- ence on Computer Vision. pp. 163–179. Springer (2024)
2024
-
[52]
arXiv preprint arXiv:2507.23785 (2025)
Zhang, B., Xu, S., Wang, C., Yang, J., Zhao, F., Chen, D., Guo, B.: Gaus- sian variation field diffusion for high-fidelity video-to-4d synthesis. arXiv preprint arXiv:2507.23785 (2025)
arXiv 2025
-
[53]
Zhang, C., Moing, G.L., Koppula, S., Rocco, I., Momeni, L., Xie, J., Sun, S., Sukthankar, R., Barral, J.K., Hadsell, R., Ghahramani, Z., Zisserman, A., Zhang, J., Sajjadi, M.S.M.: Efficiently reconstructing dynamic scenes one d4rt at a time (2025),https://arxiv.org/abs/2512.08924
arXiv 2025
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, M., Zhuo, L., Tan, T., Xie, G., Nie, X., Li, Y., Zhao, R., He, Z., Wang, Z., Cai, J., et al.: Ipr-1: Interactive physical reasoner. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 33415– 33425 (2026)
2026
-
[55]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[56]
arXiv preprint arXiv:2508.10868 (2025) 20 J
Zhang, Y., Zhang, L., Ma, R., Cao, N.: Texverse: A universe of 3d objects with high-resolution textures. arXiv preprint arXiv:2508.10868 (2025) 20 J. Li et al. HAT-4D: Lifting Monocular Video for 4D Multi-Object Interactions via Human–Agent Collaboration Supplementary Material We introduce: –More implementation details of the HAT-4D framework in Sec.7, ad...
arXiv 2025
-
[57]
Do NOT output numeric pose or distance
-
[58]
distance_hint must be one of: {near_zero, near, mid, far, unknown}
-
[59]
Focus on events that start, end, or change within this segment
-
[60]
left cup
Keep object naming consistent with previous memory. Object naming rules: 4.1 Prefer distinguishing objects by appearance (color, texture, shape, size, damage, stain, marks). 4.2 Objects should represent real object instances. Avoid pure spatial region names. 36 J. Li et al. 4.3 Only when objects are visually indistinguishable, spatial qualifiers such as "...
-
[61]
Objects should be ordered from +X to -X (more negative means farther)
Output x-axis depth ordering timeline. Objects should be ordered from +X to -X (more negative means farther)
-
[62]
segment_id
Output key pairwise spatial relations: horizontal (left/right/overlap) vertical (above/below/overlap) optional depth (front/behind/same_depth). segment_id: {segment_id} object_text_hint: {object_text} relation_hint: {relation_hint} segment_frame_tokens: {segment_tokens} frame_mapping: {token_lines} previous_segment_memory: {memory_text} Return JSON with k...
-
[63]
Merge duplicated object identities
-
[64]
Resolve temporal conflicts across segments
-
[65]
left cup
Keep only symbolic spatial relations. Do not output numeric pose or distance. Object merging rules: 3.1 Prefer instance names distinguished by 38 J. Li et al. appearance details (color, texture, shape, size, markings). 3.2 If objects are visually indistinguishable, spatial qualifiers such as "left cup" / "right cup" are allowed, but must remain consistent...
-
[66]
Output ordering from +X to -X (more negative means farther)
Merge x-axis depth ordering timelines. Output ordering from +X to -X (more negative means farther)
-
[67]
objects": [string],
Merge relative_position_timeline across the entire video. Inputs: object_text_hint: {object_text} relation_hint: {relation_hint} all_frame_tokens: {frame_tokens} segment_fragments_json: {segment_fragments_json} segment_memories_json: {segment_memories_json} Return JSON with keys: { "objects": [string], "object_meta": [ { "id": string, "name": string, "cat...
-
[68]
Use world coordinate convention: objects ordered from +X to -X (more negative means farther)
-
[69]
Provide time-sliced depth ordering covering the video timeline
-
[70]
x_depth_order_timeline
If information is insufficient, output a single global ordering. Inputs: object_text_hint: {object_text} relation_hint: {relation_hint} frame_tokens: {frame_tokens} current_scene_graph_json: {current_scene_graph_json} segment_memories_json: {segment_memories_json} Return JSON: { "x_depth_order_timeline": [ { "frame_range": string, "start_frame_index": int...
-
[71]
Provide exactly {n_pos} positive points
-
[72]
Provide exactly {n_neg} negative points
-
[73]
Positive points must lie on the target object
-
[74]
Negative points should lie on non-target objects or background regions
-
[75]
First decompose the target object into visible semantic parts. 42 J. Li et al
-
[76]
Distribute positive points across different visible parts whenever possible
-
[77]
part_decomposition
If failure analysis is provided, prioritize correcting the detected issues, such as: - missing_parts - extra_objects - wrong_positive_points - wrong_negative_points Return JSON: { "part_decomposition": [ { "part_name": string, "is_visible": bool, "importance": "high|medium|low" } ], "positive_points": [ { "x": float, "y": float, "part_name": string } ], "...
-
[78]
Original image with mask overlay
-
[79]
Binary mask image (white = mask)
-
[80]
Foreground cutout (mask region only)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.