ConCise: Training-Free Conclusion-Chain State Compression for Cost-Efficient Multi-Step RAG Services
Pith reviewed 2026-06-30 11:28 UTC · model grok-4.3
The pith
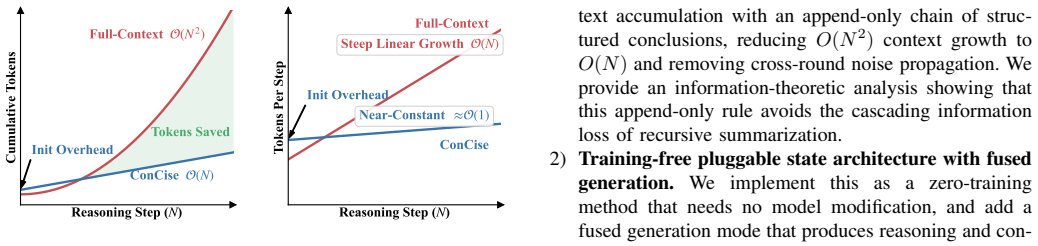
ConCise replaces raw-text accumulation in multi-step RAG with an append-only chain of structured conclusions, cutting token growth from quadratic to linear.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
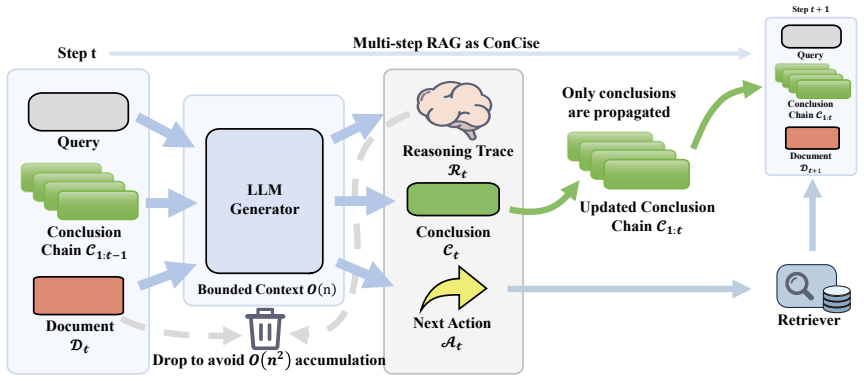
ConCise is a state-layer protocol that restructures cross-round context transmission for multi-step RAG services by replacing raw-text accumulation with an append-only chain of structured conclusions, which compresses cumulative context growth from O(N²) to approximately O(N), and by introducing a fused generation mechanism that jointly emits reasoning and conclusions in a single API call.
What carries the argument
The append-only chain of structured conclusions, which transmits only compressed state across rounds instead of full histories, together with fused generation that combines reasoning and conclusion output to avoid separate calls.
Load-bearing premise
The structured conclusions produced after each round must contain every fact needed for correct later retrieval and final answers without omissions or introduced errors.
What would settle it
A direct comparison on the same multi-hop questions where the conclusion-chain version produces measurably lower final-answer accuracy than the raw-text baseline.
Figures

read the original abstract
Multi-step retrieval-augmented generation (RAG) has been widely deployed as LLM-powered web services for complex question answering, where iterative retrieval-reasoning rounds deliver strong multi-hop accuracy. However, this paradigm causes historical documents and reasoning traces to accumulate across rounds, inflating cumulative input tokens approximately as $O(N^2)$ with progressively increasing noise density. In API-based service architectures, such growth directly amplifies per-request billing cost, network payload, and response latency. Existing compression approaches rely on pretrained modules or GPU-level KV cache access, introducing model hosting overhead incompatible with API-native, Serverless, and edge-side deployments. To address this issue, this paper proposes ConCise, a training-free state-layer protocol that restructures cross-round context transmission for multi-step RAG services. Specifically, ConCise replaces raw-text accumulation with an append-only chain of structured conclusions, compressing cumulative context growth from $O(N^2)$ to approximately $O(N)$. Furthermore, a fused generation mechanism is introduced to jointly emit reasoning and conclusions in a single API call, eliminating repeated input billing from serial dual-invocation overhead. Extensive experiments across twelve paired configurations spanning three models, two datasets, and two representative frameworks demonstrate that ConCise achieves 64.63\% average token savings while maintaining acceptable accuracy, providing a plug-and-play, deployment-friendly solution for cost-efficient multi-step RAG service optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ConCise, a training-free state compression protocol for multi-step RAG services. It replaces accumulating raw historical documents and reasoning traces (which grow as O(N²)) with an append-only chain of LLM-generated structured conclusions (O(N) growth) and adds a fused generation mechanism that emits reasoning and conclusions in one API call. Experiments across twelve paired configurations (three models, two datasets, two frameworks) report 64.63% average token savings while maintaining acceptable accuracy.
Significance. If the empirical results hold under the stated conditions, the work provides a practical, deployment-friendly optimization for API-based, serverless, and edge RAG services that avoids pretrained compressors or KV-cache access. The training-free, prompt-only implementation and explicit O(N) scaling claim are strengths that directly address billing, latency, and payload costs in production multi-step RAG.
major comments (1)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of 'acceptable accuracy' across all twelve configurations is not supported by reported baselines, exact accuracy values, statistical tests, or an explicit definition of acceptability; without these, the paired accuracy measurements cannot be evaluated for whether the conclusion chain preserves required information.
minor comments (3)
- [§3.2] §3.2: the fused-generation prompt template should be provided verbatim so that the single-call billing reduction can be reproduced.
- [Figure 2 and Table 1] Figure 2 and Table 1: axis labels and legend entries for token counts versus round number are unclear; clarify whether the plotted curves include or exclude the conclusion chain itself.
- [§2] §2: the O(N²) growth claim is stated without a short derivation or reference to prior multi-step RAG analyses; a one-sentence justification would strengthen the motivation.
Simulated Author's Rebuttal
We thank the referee for identifying the need for greater transparency in the accuracy evaluation. We address the comment below and commit to a revision that supplies the missing details.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of 'acceptable accuracy' across all twelve configurations is not supported by reported baselines, exact accuracy values, statistical tests, or an explicit definition of acceptability; without these, the paired accuracy measurements cannot be evaluated for whether the conclusion chain preserves required information.
Authors: We agree that the manuscript does not currently provide the supporting data required to substantiate the phrase 'acceptable accuracy.' In the revised manuscript we will (1) report exact accuracy numbers for every one of the twelve configurations, (2) include the corresponding non-compressed baseline accuracies for direct comparison, (3) define 'acceptable' explicitly (accuracy degradation ≤ 3 % relative to baseline), and (4) add paired statistical tests (e.g., McNemar or Wilcoxon signed-rank) with p-values. These additions will appear in a new subsection of §4 and will be referenced from the abstract. revision: yes
Circularity Check
No significant circularity; empirical protocol with external validation
full rationale
The paper presents ConCise as a training-free prompt-engineering protocol that replaces raw-text accumulation with an append-only chain of structured conclusions and adds fused generation. Its central claims rest on direct empirical measurements across twelve paired configurations (three models, two datasets, two frameworks) showing token savings and accuracy preservation. No equations, fitted parameters, or self-citations are invoked as load-bearing derivations; the O(N) scaling and cost reductions are measured outcomes rather than constructed by definition from the method itself. The protocol is self-contained against external benchmarks and does not reduce any prediction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structured conclusions can capture essential information from retrieval and reasoning rounds without loss
invented entities (1)
-
Conclusion chain
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[2]
Interleav- ing retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Interleav- ing retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 10 014–10 037
2023
-
[3]
Active retrieval augmented generation,
Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y . Yang, J. Callan, and G. Neubig, “Active retrieval augmented generation,” in Proceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 7969–7992
2023
-
[4]
Self-rag: Learning to retrieve, generate, and critique through self-reflection,
A. Asai, Z. Wu, Y . Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” inThe Twelfth International Conference on Learning Representations, 2024. TABLE III CASE1 (IRCOT): RAWOUTPUTSNIPPETCOMPARISON Round Baseline +ConCise Step 1 . . . Among these, Robert Menzies was born in Stan- more. So the ...
2024
-
[5]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han, “Search-r1: Training llms to reason and leverage search engines with reinforcement learning,”arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024
2024
-
[7]
Enhancing llm qos through cloud-edge collaboration: A diffusion-based multi-agent reinforcement learning approach,
Z. Yao, Z. Tang, W. Yang, and W. Jia, “Enhancing llm qos through cloud-edge collaboration: A diffusion-based multi-agent reinforcement learning approach,”IEEE Transactions on Services Computing, 2025
2025
-
[8]
Eat: Qos-aware edge-collaborative aigc task scheduling via attention- guided diffusion reinforcement learning,
Z. Xu, Z. Tang, J. Lou, Z. Yao, X. Xie, T. Wang, Y . Wang, and W. Jia, “Eat: Qos-aware edge-collaborative aigc task scheduling via attention- guided diffusion reinforcement learning,”IEEE Transactions on Mobile Computing, 2026
2026
-
[9]
Velo: A vector database- assisted cloud-edge collaborative llm qos optimization framework,
Z. Yao, Z. Tang, J. Lou, P. Shen, and W. Jia, “Velo: A vector database- assisted cloud-edge collaborative llm qos optimization framework,” in 2024 IEEE International Conference on Web Services (ICWS). IEEE, 2024, pp. 865–876
2024
-
[10]
Adaptive request scheduling and load balancing for edge deployed large language models,
F. Mou, Z. Tang, W. Jia, and W. Zhao, “Adaptive request scheduling and load balancing for edge deployed large language models,”IEEE Transactions on Services Computing, vol. 19, no. 2, pp. 934–947, 2026
2026
-
[11]
Cloud- edge system for scheduling unpredictable llm requests with combinato- rial bandit,
Y . Li, J. Guo, Z. Tang, X. Ding, J. Wang, T. Wang, and W. Jia, “Cloud- edge system for scheduling unpredictable llm requests with combinato- rial bandit,”IEEE Transactions on Services Computing, vol. 18, no. 6, 2025
2025
-
[12]
Adapting multi- model inference pipelines with diffusion-based reinforcement learning in edge computing,
J. Sheng, Z. Tang, J. Guo, K. Yue, T. Wang, and W. Jia, “Adapting multi- model inference pipelines with diffusion-based reinforcement learning in edge computing,”IEEE Transactions on Services Computing, vol. 19, no. 2, pp. 920–933, 2026
2026
-
[13]
Llmlingua: Com- pressing prompts for accelerated inference of large language models,
H. Jiang, Q. Wu, C.-Y . Lin, Y . Yang, and L. Qiu, “Llmlingua: Com- pressing prompts for accelerated inference of large language models,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 13 358–13 376
2023
-
[14]
Exit: Context-aware extractive compression for enhancing retrieval- augmented generation,
T. Hwang, S. Cho, S. Jeong, H. Song, S. Han, and J. C. Park, “Exit: Context-aware extractive compression for enhancing retrieval- augmented generation,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 4895–4924
2025
-
[15]
Snapkv: Llm knows what you are looking for before generation,
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen, “Snapkv: Llm knows what you are looking for before generation,”Advances in Neural Information Processing Systems, vol. 37, pp. 22 947–22 970, 2024
2024
-
[16]
In-context autoencoder for context compression in a large language model,
T. Ge, J. Hu, L. Wang, X. Wang, S.-Q. Chen, and F. Wei, “In-context autoencoder for context compression in a large language model,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[17]
Adapting language models to compress contexts,
A. Chevalier, A. Wettig, A. Ajith, and D. Chen, “Adapting language models to compress contexts,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 3829– 3846
2023
-
[18]
xrag: Extreme context compression for retrieval-augmented generation with one token,
X. Cheng, X. Wang, X. Zhang, T. Ge, S.-Q. Chen, F. Wei, H. Zhang, and D. Zhao, “xrag: Extreme context compression for retrieval-augmented generation with one token,”Advances in Neural Information Processing Systems, vol. 37, pp. 109 487–109 516, 2024
2024
-
[19]
Recomp: Improving retrieval-augmented lms with compression and selective augmentation,
F. Xu, W. Shi, and E. Choi, “Recomp: Improving retrieval-augmented lms with compression and selective augmentation,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[20]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[21]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,
X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa, “Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,” inProceedings of the 28th International Conference on Computational Linguistics, 2020, pp. 6609–6625
2020
-
[22]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering,
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning, “Hotpotqa: A dataset for diverse, explainable multi-hop question answering,” inProceedings of the 2018 conference on empirical methods in natural language processing, 2018, pp. 2369–2380
2018
-
[23]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[24]
Large lan- guage models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large lan- guage models are zero-shot reasoners,”Advances in neural information processing systems, vol. 35, pp. 22 199–22 213, 2022
2022
-
[25]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,”Advances in neural information processing systems, vol. 36, pp. 11 809–11 822, 2023
2023
-
[26]
Measuring and narrowing the compositionality gap in language mod- els,
O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis, “Measuring and narrowing the compositionality gap in language mod- els,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 5687–5711
2023
-
[27]
Search-o1: Agentic search-enhanced large reasoning models,
X. Li, G. Dong, J. Jin, Y . Zhang, Y . Zhou, Y . Zhu, P. Zhang, and Z. Dou, “Search-o1: Agentic search-enhanced large reasoning models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 5420–5438
2025
-
[28]
Deepnote: Note-centric deep retrieval- augmented generation,
R. Wang, Q. Zhao, Y . Yan, D. Zha, Y . Chen, S. Yu, Z. Liu, Y . Wang, S. Wang, X. Hanet al., “Deepnote: Note-centric deep retrieval- augmented generation,” inFindings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 19 688–19 715
2025
-
[29]
Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon gen- eration,
Z. Wang, A. Liu, H. Lin, J. Li, X. Ma, and Y . Liang, “Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon gen- eration,”arXiv preprint arXiv:2403.05313, 2024
-
[30]
Markov chain of thought for efficient mathematical reasoning,
W. Yang, M. Liao, and K. Fan, “Markov chain of thought for efficient mathematical reasoning,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 7132–7157
2025
-
[31]
Inftythink: Breaking the length limits of long-context reasoning in large language models,
Y . Yan, Y . Shen, Y . Liu, J. Jiang, M. Zhang, J. Shao, and Y . Zhuang, “Inftythink: Breaking the length limits of long-context reasoning in large language models,”arXiv preprint arXiv:2503.06692, 2025
-
[32]
Efficient serverless function scheduling in edge computing,
J. Lou, Z. Tang, X. Lu, S. Yuan, J. Li, W. Jia, and C. Wu, “Efficient serverless function scheduling in edge computing,” inICC 2024-IEEE International Conference on Communications. IEEE, 2024, pp. 1029– 1034
2024
-
[33]
Ultrarag: A low-code mcp framework for building complex and innovative rag pipelines,
OpenBMB, “Ultrarag: A low-code mcp framework for building complex and innovative rag pipelines,” https://github.com/OpenBMB/UltraRAG, 2025
2025
-
[34]
Api pricing,
OpenAI, “Api pricing,” https://openai.com/api/pricing/, 2026, accessed: 2026-02-28
2026
-
[35]
Empowering edge intelligence: A comprehensive survey on on-device ai models,
X. Wang, Z. Tang, J. Guo, T. Meng, C. Wang, T. Wang, and W. Jia, “Empowering edge intelligence: A comprehensive survey on on-device ai models,”ACM Computing Surveys, vol. 57, no. 9, pp. 1–39, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.