Generative AI Literacy Training Improves Intelligence Analysts' Discrimination of Real and AI-Generated Images
Pith reviewed 2026-06-30 01:05 UTC · model grok-4.3
The pith
A 30-minute training raises intelligence analysts' accuracy distinguishing real from AI-generated images by 9 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
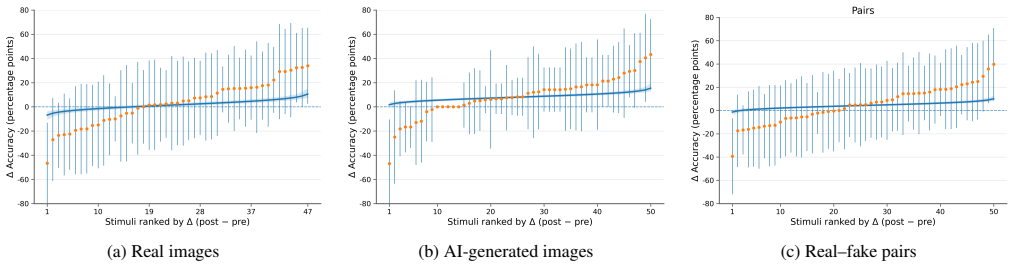
A 30-minute expert-led training that presents visual patterns from seven real and fifty AI-generated images increases intelligence analysts' discrimination accuracy by 9 percentage points from a 72 percent baseline, with the effect driven by a 14.2 percentage point gain in correctly identifying real images.
What carries the argument
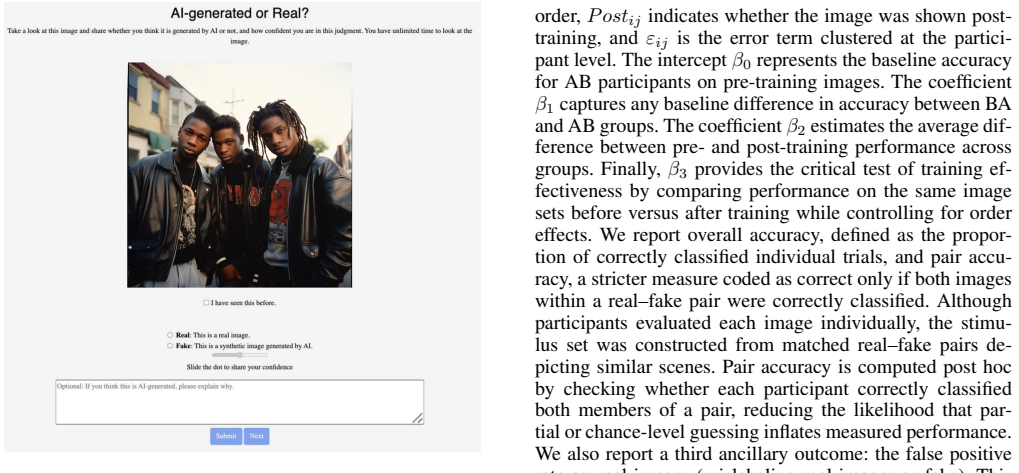
The 30-minute training intervention that highlights patterns in real and AI-generated images, measured through pre-post image judgments in a counterbalanced within-subject design with matched image pairs.
If this is right
- Accuracy gains concentrate on real images rather than AI-generated ones.
- Training effects vary with participants' prior levels of digital forensics and generative AI experience.
- The intervention shows differential effectiveness across image categories defined by pose complexity and scene context.
- Brief trainings supply causal evidence that organizations can use to address visual misinformation.
Where Pith is reading between the lines
- The same training format could be adapted and tested with other groups that routinely evaluate visual evidence.
- Retention of accuracy gains could be measured by re-testing the same analysts after days or weeks.
- Pairing the training with automated detection tools might produce combined performance above either method alone.
Load-bearing premise
The matched image pairs and counterbalanced within-subject design isolate the effect of the training content from practice effects, fatigue, or image-specific features.
What would settle it
A replication study with new matched image pairs that finds no pre-to-post accuracy increase would indicate the observed gains were not caused by the training content.
Figures

read the original abstract
Across social and online platforms, people are increasingly exposed to AI-generated images. As a consequence, the task of distinguishing AI-generated from authentic images is becoming a central challenge for information ecosystems. While humans perform better than chance, accuracy falls short of many operational needs. Initial evidence shows that visually oriented training can improve deepfake detection but does not improve participants' ability to identify real images as real. Here, we investigate the efficacy of a brief training intervention for intelligence analysts employed by the United States government in 2024. We conducted a counterbalanced within-subject randomized experiment in which we showed participants real and AI-generated images varying in pose complexity and scene context and asked them whether each image was real or AI-generated, both before and after an expert delivered a 30-minute training that pointed out patterns in seven real and 50 AI-generated images. We collected 2,544 image-level judgments from 32 intelligence analysts. We find training increased overall accuracy by 9 percentage points (95% CI: [2.7, 15.4]) from a baseline of 72%. We find the improvement is driven by a 14.2 percentage point increase in accuracy for real images (95% CI: [0.7, 27.7]). Through a careful experimental setup that curated matched pairs of real and AI-generated images across pose complexity categories, we reveal how these trainings influence people with different levels of digital forensics and generative AI experience and identify the kind of image-based content where this training intervention appears to be most effective. Ultimately, these results provide causal evidence that a brief, structured training can improve human judgment across a diverse array of real and AI-generated images, informing organizational responses to AI-generated visual misinformation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a counterbalanced within-subject experiment with 32 U.S. intelligence analysts who made 2,544 real/AI image judgments before and after a 30-minute expert training on visual patterns. It claims the training produced a 9 pp overall accuracy gain (95% CI [2.7, 15.4]) from a 72% baseline, driven by a 14.2 pp gain on real images (95% CI [0.7, 27.7]), and presents this as causal evidence that brief structured training improves discrimination across image types.
Significance. If the accuracy gains are attributable to the specific training content rather than repeated exposure, the result has applied value for government and organizational training programs addressing AI-generated visual misinformation. The use of domain-expert participants and matched real/AI image pairs across pose and context categories strengthens ecological relevance. The large number of judgments (2,544) and reporting of confidence intervals are positive features of the empirical design.
major comments (1)
- [Abstract] Abstract and experimental setup: The central causal claim that the 30-minute training produced the observed accuracy increases rests on the assumption that the pre-post within-subject design isolates the intervention from practice effects, task familiarization, or implicit learning across the two sessions. No parallel control arm (e.g., filler activity of comparable duration) is described, so general improvements from repeated testing cannot be separated from training-specific effects. This directly affects interpretation of both the 9 pp overall and 14.2 pp real-image gains.
minor comments (1)
- [Abstract] Abstract: The 95% CI for the real-image accuracy change ([0.7, 27.7]) is wide and includes values near zero; this should be discussed when interpreting the practical magnitude of the effect on real images.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying a key limitation in our experimental design. We address this point directly below and agree that revisions are warranted to ensure accurate interpretation of our findings.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental setup: The central causal claim that the 30-minute training produced the observed accuracy increases rests on the assumption that the pre-post within-subject design isolates the intervention from practice effects, task familiarization, or implicit learning across the two sessions. No parallel control arm (e.g., filler activity of comparable duration) is described, so general improvements from repeated testing cannot be separated from training-specific effects. This directly affects interpretation of both the 9 pp overall and 14.2 pp real-image gains.
Authors: We agree that this is a substantive limitation of the current design. The study used a pre-post within-subjects approach with counterbalancing of image presentation order and categories, but did not include a parallel control condition (such as a filler task of equivalent duration). Consequently, we cannot fully isolate training-specific effects from general practice or familiarization effects. While the differential improvement on real-image identification (rather than uniform gains) is consistent with the training content, this does not rule out alternative explanations. We will revise the abstract, results, and discussion sections to qualify the causal language—replacing 'causal evidence' with phrasing that describes the observed association between the intervention and performance changes while explicitly noting the design limitation. We will also expand the limitations paragraph to recommend control-arm studies in future work. These changes will be incorporated in the revised manuscript. revision: yes
Circularity Check
No circularity: direct empirical measurement of pre-post accuracy changes
full rationale
The paper reports measured accuracy improvements from a controlled within-subject experiment with 32 participants providing 2,544 judgments before and after a 30-minute training intervention. No equations, parameter fits, or derivations are present that reduce the reported 9 pp overall or 14.2 pp real-image gains to inputs by construction. The design description (counterbalanced matched pairs) and causal attribution rest on standard experimental logic rather than self-referential definitions or self-citation chains. This is a straightforward empirical report with no load-bearing steps that collapse to the paper's own fitted quantities or prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying calculation of 95% confidence intervals for paired accuracy differences (approximate normality or bootstrap validity).
Reference graph
Works this paper leans on
-
[1]
The Effect of Education in Prompt Engineering: Evidence from Journalists.Proceedings of the International AAAI Conference on Web and Social Media (ICWSM). ArXiv:2409.12320. Bateman, J
-
[2]
Deepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024
Deepfake-eval-2024: A multi-modal in- the-wild benchmark of deepfakes circulated in 2024.arXiv preprint arXiv:2503.02857. Chen, E.; Seo, H.; Ruffin, M.; Lee, D.; Wang, G.; and Xiong, A
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Intriguing properties of synthetic images: from generative adversarial networks to diffusion models. arXiv:2304.06408. Cozzolino, D.; Poggi, G.; Corvi, R.; Nießner, M.; and Ver- doliva, L
-
[4]
Raising the Bar of AI-generated Image De- tection with CLIP. arXiv:2312.00195. Diel, A.; et al
-
[5]
InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, CHI ’26
De- signing Effective Digital Literacy Interventions for Boost- ing Deepfake Discernment. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, CHI ’26. New York, NY , USA: Association for Computing Ma- chinery. ISBN 9798400722783. Gomila, R
2026
-
[6]
How to Distinguish AI-Generated Images from Authentic Photographs. arXiv:2406.08651. Kamali, N.; Nakamura, K.; Kumar, A.; Chatzimparmpas, A.; Hullman, J.; and Groh, M
-
[7]
In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25
Characterizing Photoreal- ism and Artifacts in Diffusion Model-Generated Images. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25. Kim, S. J.; Lu, Y .; and Peng, Y
2025
-
[8]
InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems
User Experience Design Professionals’ Perceptions of Gen- erative Artificial Intelligence. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. ACM. ArXiv:2309.15237. Lin, L.; Gupta, N.; Zhang, Y .; Ren, H.; Liu, C.-H.; Ding, F.; Wang, X.; Li, X.; Verdoliva, L.; and Hu, S
-
[9]
Detect- ing Multimedia Generated by Large AI Models: A Survey. arXiv:2402.00045. Lintner, T
-
[10]
InProceedings of the 2020 CHI Conference on Human Factors in Computing Sys- tems, 1–16
What is AI Literacy? Com- petencies and Design Considerations. InProceedings of the 2020 CHI Conference on Human Factors in Computing Sys- tems, 1–16. New York, NY , USA: Association for Comput- ing Machinery. Luccioni, S.; Akiki, C.; Mitchell, M.; and Jernite, Y
2020
-
[11]
Towards Universal Fake Image Detectors that Generalize Across Generative Models. arXiv:2302.10174. Pennycook, G.; and Rand, D. G
-
[12]
Towards the Detection of Diffusion Model Deepfakes. arXiv:2210.14571. Roca, T.; Roman, A. C.; Vega, J. T.; Duarte, M.; Wang, P.; White, K.; Misra, A.; and Ferres, J. L
-
[13]
How good are humans at detecting AI-generated images? Learnings from an experiment.arXiv preprint arXiv:2507.18640. Ruffin, M.; Seo, H.; Xiong, A.; and Wang, G
-
[14]
Simonsohn, U.; Montealegre, A.; and Evangelidis, I
ArXiv:2406.08271. Simonsohn, U.; Montealegre, A.; and Evangelidis, I
-
[15]
Can You Tell What’s Real Now? Accessed: 2024-08-27
AI is Getting Better Fast. Can You Tell What’s Real Now? Accessed: 2024-08-27. Thompson, S
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.