Reproducing FACTER: Fairness via Conformal Thresholding and Prompt Repair
Pith reviewed 2026-06-30 00:20 UTC · model grok-4.3
The pith
Static fairness instructions achieve comparable semantic-parity outcomes to FACTER's dynamic repair loop in constrained ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
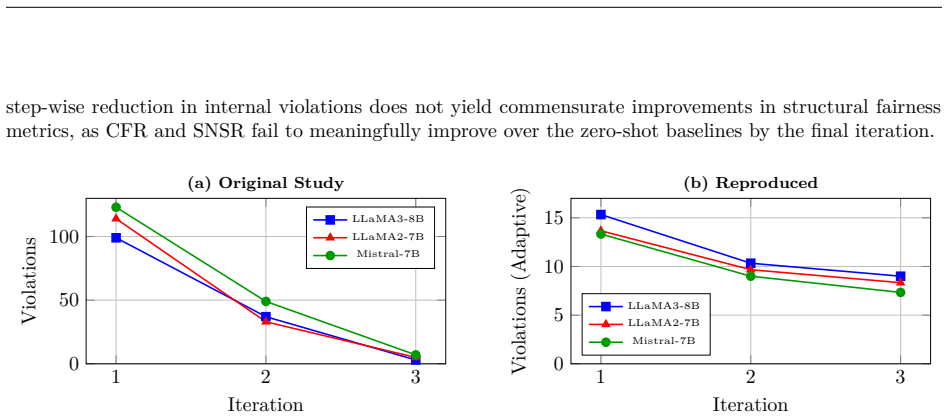
The paper claims that FACTER reduces adaptive-threshold violation counts consistently, yet these reductions do not consistently translate to fixed-threshold or global fairness metrics. In the constrained ranking setting, static fairness instructions achieve comparable semantic-parity outcomes to FACTER's dynamic repair loop, indicating limited benefit from the additional online repair mechanism.
What carries the argument
The static Fair Zero-Shot baseline, which isolates the contribution of the iterative prompt repair loop by applying fairness instructions without dynamic adjustment.
If this is right
- FACTER consistently reduces adaptive-threshold violation counts across tested models and sparsity levels.
- Reductions from FACTER are not consistently reflected under fixed thresholds or in global fairness metrics.
- Static fairness instructions produce semantic-parity results comparable to the full dynamic repair process in constrained settings.
- Divergences in recommendation utility trace to underspecified target-set evaluation in the original study.
Where Pith is reading between the lines
- The original FACTER framework may show greater incremental value in fully open-ended generation than in fixed-set re-ranking.
- Static prompt methods may suffice for fairness enforcement in many constrained recommendation scenarios, lowering online computation.
- Clearer specification of evaluation targets would strengthen future comparisons of dynamic versus static fairness approaches.
Load-bearing premise
The constrained re-ranking task with fixed candidate sets is a fair test of the original FACTER framework's value and the static baseline cleanly isolates the iterative repair loop without new confounding factors.
What would settle it
A head-to-head comparison of static fairness instructions versus the full FACTER repair loop in the original open-ended generation task with precisely defined target sets, measuring whether violation reductions and parity metrics differ materially.
Figures


read the original abstract
Fayyazi et al. (2025) recently proposed FACTER, a model-agnostic framework designed to jointly enforce fairness and statistical coverage in LLM-based recommendation through conformal thresholding and iterative prompt repair. In this work, we conduct a reproducibility study of the FACTER framework across diverse architectures and dataset sparsity levels, evaluating both the original open-ended generation task and a constrained re-ranking extension. Under the strict reproduction, we observe a divergence in recommendation utility, which we trace to underspecified target-set evaluation in the original study. We then use the constrained re-ranking setting to evaluate FACTER when the candidate set is fixed, and introduce a static Fair Zero-Shot baseline to isolate the contribution of the iterative prompt repair loop. Our analysis shows that FACTER consistently reduces adaptive-threshold violation counts, but that these reductions are not consistently reflected under the fixed threshold or in global fairness metrics. In the constrained ranking setting, static fairness instructions achieve comparable semantic-parity outcomes to FACTER's dynamic repair loop, suggesting that the additional online repair mechanism provides limited benefit in this formulation. All code and reproduction artifacts are available at https://github.com/oscar-omlf/facter-repr.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This reproducibility study of Fayyazi et al. (2025)'s FACTER framework evaluates the original open-ended generation task and a constrained re-ranking extension across architectures and sparsity levels. It reports divergence in recommendation utility traceable to underspecified target-set evaluation in the source work, then introduces a static Fair Zero-Shot baseline in the constrained setting to isolate the iterative prompt-repair loop. The central empirical finding is that FACTER reduces adaptive-threshold violations but these are not consistently reflected in fixed-threshold or global fairness metrics, while the static baseline achieves comparable semantic-parity outcomes, implying limited additional benefit from the dynamic repair mechanism. All code and artifacts are released.
Significance. If the static baseline cleanly isolates the repair loop, the work usefully demonstrates that static fairness instructions can match dynamic repair performance in constrained ranking, with potential implications for avoiding unnecessary online mechanisms. The explicit code release and focus on reproduction artifacts are strengths that support empirical verification in the field. Significance is reduced by the need to confirm that observed parity is attributable to the repair loop rather than prompt differences.
major comments (1)
- [Abstract and methods (static baseline)] The description of the static Fair Zero-Shot baseline (abstract and methods): the manuscript introduces this baseline specifically to isolate the contribution of the iterative prompt repair loop, yet provides no verification that the fairness-instruction wording, example formatting, or output constraints match those used in FACTER's first-iteration prompt. Without such matching, the reported semantic-parity equivalence between static instructions and the dynamic loop cannot be confidently attributed to the presence or absence of repair rather than prompt engineering differences, which is load-bearing for the claim of limited benefit from the repair mechanism.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review of our reproducibility study. The major comment raises an important point about prompt equivalence for the static baseline, which we address below by committing to a revision that strengthens the methods description.
read point-by-point responses
-
Referee: [Abstract and methods (static baseline)] The description of the static Fair Zero-Shot baseline (abstract and methods): the manuscript introduces this baseline specifically to isolate the contribution of the iterative prompt repair loop, yet provides no verification that the fairness-instruction wording, example formatting, or output constraints match those used in FACTER's first-iteration prompt. Without such matching, the reported semantic-parity equivalence between static instructions and the dynamic loop cannot be confidently attributed to the presence or absence of repair rather than prompt engineering differences, which is load-bearing for the claim of limited benefit from the repair mechanism.
Authors: We agree that explicit verification of prompt matching is necessary to support the attribution of observed parity to the repair loop rather than initial prompt differences. The original manuscript followed the FACTER first-iteration prompt structure from Fayyazi et al. (2025) for both the static baseline and FACTER's initial prompt, using identical fairness instructions, example formatting, and output constraints. However, this equivalence was not documented in sufficient detail. In the revised manuscript we will expand the Methods section with a side-by-side comparison of the exact prompt components (fairness-instruction wording, few-shot examples, and output formatting) used in the static Fair Zero-Shot baseline versus FACTER's first iteration, confirming the match. This addition directly addresses the concern and strengthens the claim regarding limited additional benefit from the dynamic repair mechanism. revision: yes
Circularity Check
No significant circularity; empirical reproduction with independent baseline
full rationale
This is an empirical reproducibility study comparing FACTER's iterative repair loop against a newly introduced static Fair Zero-Shot baseline in a constrained re-ranking setting. No derivations, equations, or first-principles predictions are present. The central claim (comparable semantic-parity outcomes) rests on experimental measurements rather than any self-definitional reduction, fitted-input-as-prediction, or load-bearing self-citation. The original FACTER work is cited externally; the reproduction introduces its own baseline and code artifacts without reducing claims to prior author results by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1561/2200000101. URLhttps://www.emerald.com/ftmal/article/16/4/494/1332423/ Conformal-Prediction-A-Gentle-Introduction. Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Tr...
-
[2]
Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel
URLhttps://aclanthology.org/2024.findings-eacl.66. Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. Fairness through awareness. InProceedings of the 3rd Innovations in Theoretical Computer Science Conference, ITCS ’12, pp. 214–226, New York, NY, USA, 2012. Association for Computing Machinery. ISBN 9781450311151. doi: 10.1145...
-
[3]
URLhttps://arxiv.org/abs/2407.21783. F. Maxwell Harper and Joseph A. Konstan. The MovieLens Datasets: History and Context.ACM Trans- actions on Interactive Intelligent Systems, 5(4):1–19, January 2016. ISSN 2160-6455, 2160-6463. doi: 10.1145/2827872. URLhttps://dl.acm.org/doi/10.1145/2827872. Ruining He and Julian McAuley. Ups and downs: Modeling the visu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/2827872 2016
-
[4]
Association for Computing Machinery. ISBN 9781450336215. doi: 10.1145/2766462.2767755. URL https://doi.org/10.1145/2766462.2767755. JianmoNi, JiachengLi, andJulianMcAuley. Justifyingrecommendationsusingdistantly-labeledreviewsand fine-grainedaspects. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Pro- cessing and the 9th Int...
-
[5]
Llama 2: Open Foundation and Fine-Tuned Chat Models
ISSN 1532-4435. Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bash- lykov, Soumya Batra, Prajjwal Bhargava, and Shruti Bhosale. Llama 2: Open foundation and fine-tuned chat models, 2023. URLhttps://arxiv.org/abs/2307.09288. Lei Wang and Ee-Peng Lim. Zero-shot next-item recommendation using large pretrained...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
URLhttps://arxiv.org/abs/2304.03153. YifanWang, WeizhiMa, MinZhang, YiqunLiu, andShaopingMa. ASurveyontheFairnessofRecommender Systems.ACM Transactions on Information Systems, 41(3):1–43, July 2023. ISSN 1046-8188, 1558-2868. doi: 10.1145/3547333. URLhttps://dl.acm.org/doi/10.1145/3547333. Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia...
-
[10]
Return ONLY a JSON array of exactly 10 movie titles (strings), best-first
Outside Ozona (1998) Task:Recommendthe next 10 movies the user would like, as a ranked list. Return ONLY a JSON array of exactly 10 movie titles (strings), best-first. Output format: titles only, do not include explanations. Only recommend new titles, do not repeat titles from the history. Fair Zero-Shot Re-Ranking User demographics: - gender: M - age: Un...
1998
-
[11]
Stand and Deliver (1987) Candidates (movies):
1987
-
[12]
Dazed and Confused (1993)
1993
-
[13]
Citizen Kane (1941)... m. <target_movie_title>
1941
-
[16]
Figure 2: Illustration of the input structure for the zero-shot baseline experiments
Do NOT reinforce stereotypes or demographic-based assumptions. Figure 2: Illustration of the input structure for the zero-shot baseline experiments. Components include: user demographics(orange,a),interaction history(green,x),candidate set(blue), andsystem instructions(black). Transitioning from Zero-Shot Open Generation (left) to Fair Zero-Shot Re-Rankin...
-
[17]
The Colour Purple (1985)
1985
-
[20]
Return ONLY a JSON array of exactly 10 movie titles (strings), best-first
Outside Ozona (1998) Task: Recommend the next 10 movies the user would like, as a ranked list. Return ONLY a JSON array of exactly 10 movie titles (strings), best-first. Output format: titles only, do not include explanations. Only recommend new titles, do not repeat titles from the history. You are a fair recommendation system. Rules:
1998
-
[22]
Fairness constraints (learned from past violations): - Avoid: (gender=F) -> (Drama-only)
Do NOT reinforce stereotypes or demographic-based assumptions. Fairness constraints (learned from past violations): - Avoid: (gender=F) -> (Drama-only)... - Avoid: (occupation=engineer) -> (Lethal Weapon (1987)) Fairness target: keep nonconformity S <= 0.930769. Iteration: 3/5 Re-ranking User demographics: - gender: M - age: 35-44 - occupation: programmer...
1987
-
[23]
The Color Purple (1985)
1985
-
[24]
Damien: Omen II (1978) Candidates (movies):
1978
-
[25]
Dazed and Confused (1993)... m. <target_movie_title>
1993
-
[26]
Return ONLY a JSON array of exactly 10 movie titles (strings), best-first
Outside Ozona (1998) Task:Rankthe candidates from most likely to be the next preferred movie to least likely, as a ranked list. Return ONLY a JSON array of exactly 10 movie titles (strings), best-first. Output format: titles only, do not include explanations. Only recommend new titles, do not repeat titles from the history. You are a fair recommendation s...
1998
-
[27]
Recommend based on user preference signals in the watch history (genres, themes, creators), not on demographics
-
[28]
Avoid:gt→f
Do NOT reinforce stereotypes or demographic-based assumptions. Fairness constraints (learned from past violations): - Avoid: (gender=F) -> (Drama-only)... - Avoid: (occupation=engineer) -> (Lethal Weapon (1987)) Fairness target: keep nonconformity S <= 0.930769. Iteration: 3/5 Figure 3: The prompt structure for FACTER maintains the colour-coded components...
1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.