CCRC: A Change-Aware Captioning and Reasoning Chain for Image Change Captioning and Segmentation
Pith reviewed 2026-06-30 09:55 UTC · model grok-4.3
The pith
A dual-chain framework decouples semantic reasoning from spatial segmentation to jointly caption and localize changes between image pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
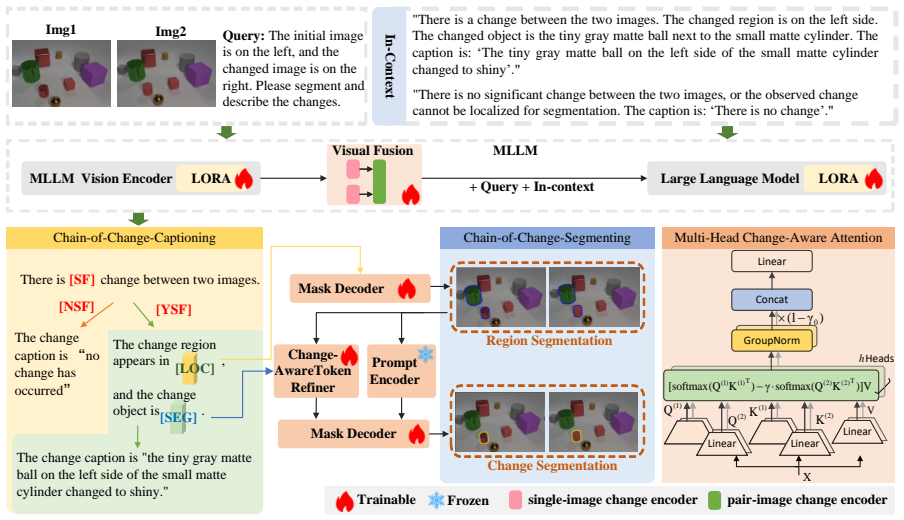
The CCRC framework decouples semantic reasoning from spatial segmentation through two chains. Chain-of-Change-Captioning enhances fine-grained change perception via a visual fusion module based on Multi-Head Change-aware Attention inserted between the visual and language components of an MLLM and determines whether a change is segmentable. If segmentable, Chain-of-Change-Segmenting activates, leveraging spatial priors from the first chain and refining masks with a Change-aware Token Refiner for accurate boundary localization.
What carries the argument
The dual-chain structure of Chain-of-Change-Captioning using Multi-Head Change-aware Attention to handle perception and segmentability decisions, plus Chain-of-Change-Segmenting with Change-aware Token Refiner activated conditionally to refine boundaries.
If this is right
- Produces both structured change descriptions and pixel-level localizations in a single pipeline.
- Achieves state-of-the-art performance on synthetic and real-world change detection benchmarks under pixel-level supervision.
- Activates the segmentation chain only when the captioning chain determines the change is segmentable.
- Uses spatial priors from the captioning chain to improve mask boundary accuracy.
Where Pith is reading between the lines
- The conditional activation pattern could extend to other multimodal tasks that mix language output with optional localization, such as grounded visual question answering.
- The attention insertion pattern suggests a way to add spatial capabilities to existing MLLMs without full retraining.
- Similar dual chains might be tested on video change detection where temporal reasoning precedes spatial refinement.
Load-bearing premise
Inserting the Multi-Head Change-aware Attention module between visual and language components and activating the segmentation chain only when needed produces accurate boundary localization without new errors from the decoupling decision.
What would settle it
A controlled experiment in which an integrated single-model baseline achieves higher boundary accuracy metrics such as IoU or boundary F-score than CCRC on the same pixel-supervised benchmarks.
Figures


read the original abstract
Understanding and localizing subtle changes between paired images is critical for tasks such as surveillance and image editing. However, traditional Image Change Captioning (ICC) methods lack spatial grounding, limiting their precision. We introduce Image Change Captioning and Segmentation (ICCS), a new multimodal task that jointly requires structured change description and pixel-level localization. To address ICCS, we propose the Change-aware Captioning and Reasoning Chain (CCRC), a dual-chain framework that decouples semantic reasoning from spatial segmentation. The first chain, Chain-of-Change-Captioning (CCC), enhances fine-grained change perception via a visual fusion module based on Multi-Head Change-aware Attention inserted between the visual and language components of a Multimodal Large Language Model (MLLM). CCC also determines whether a change is segmentable. If not, it alone generates the caption. Otherwise, the second chain, Chain-of-Change-Segmenting (CCS), is activated, leveraging spatial priors from CCC and refining masks with a Change-aware Token Refiner for accurate boundary localization. We evaluate CCRC on both synthetic and real-world change detection benchmarks with pixel-level supervision. Experiments show CCRC achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ICCS task requiring joint structured change description and pixel-level localization. It proposes CCRC, a dual-chain framework: CCC uses Multi-Head Change-aware Attention inserted in an MLLM for fine-grained change perception and captioning while also outputting a binary segmentability decision; if segmentable, CCS is activated to refine masks via a Change-aware Token Refiner using spatial priors from CCC. The paper evaluates on synthetic and real-world change detection benchmarks with pixel-level supervision and claims SOTA performance.
Significance. The joint ICCS task and the explicit decoupling of semantic reasoning from spatial segmentation via a segmentability classifier represent a novel architectural direction for multimodal change understanding, with potential utility in surveillance and editing. Credit is due for the dual-chain design that activates the segmentation component conditionally. However, the significance of the SOTA claim cannot be assessed without quantitative evidence.
major comments (2)
- [Abstract] Abstract: the claim that CCRC achieves state-of-the-art performance supplies no quantitative metrics, baseline comparisons, ablation studies, or error analysis, rendering the central performance claim unverifiable from the provided description.
- [Abstract (CCRC description)] Abstract (CCRC description): the central claim requires that CCC's binary segmentability output reliably routes to CCS only when beneficial. The architecture description does not include an ablation isolating the decision module's accuracy or its downstream effect on the reported SOTA metrics; misclassifications could degrade caption quality or produce spurious masks.
minor comments (1)
- [Abstract] Abstract: the specific benchmarks and supervision details could be named to allow immediate contextualization of the performance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major comments point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CCRC achieves state-of-the-art performance supplies no quantitative metrics, baseline comparisons, ablation studies, or error analysis, rendering the central performance claim unverifiable from the provided description.
Authors: We agree that the abstract's SOTA claim would be stronger if accompanied by key quantitative results. The full manuscript provides these details in the Experiments section, including baseline comparisons and ablations. To make the abstract self-contained, we will revise it to include representative metrics demonstrating the performance gains. revision: yes
-
Referee: [Abstract (CCRC description)] Abstract (CCRC description): the central claim requires that CCC's binary segmentability output reliably routes to CCS only when beneficial. The architecture description does not include an ablation isolating the decision module's accuracy or its downstream effect on the reported SOTA metrics; misclassifications could degrade caption quality or produce spurious masks.
Authors: The segmentability decision is a core part of the dual-chain design to conditionally activate CCS. We acknowledge that an explicit ablation on its accuracy and downstream effects would better validate the routing mechanism and address potential misclassification concerns. We will add such an ablation study to the revised manuscript, including accuracy metrics and impact on final captioning and segmentation performance. revision: yes
Circularity Check
No significant circularity; architecture proposal is self-contained
full rationale
The paper proposes a dual-chain MLLM architecture (CCC + conditional CCS) with a new attention module and token refiner for the ICCS task. No equations, fitted parameters, or first-principles derivations are described that reduce to their own inputs by construction. Performance claims rest on empirical benchmarks rather than any self-referential prediction or self-citation chain. The decoupling decision is an architectural choice whose correctness is evaluated externally via reported metrics, not assumed by definition. This is the normal case for an applied CV architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Banerjee and A
S. Banerjee and A. Lavie. Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments. InACL Work- shop on MT Evaluation, pages 65–72, 2005
2005
-
[2]
X. Bao, S. Sun, S. Ma, K. Zheng, Y . Guo, G. Zhao, Y . Zheng, and X. Wang. Cores: Orchestrating the dance of reasoning and segmen- tation. InECCV, pages 187–204. Springer, 2024
2024
-
[3]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners.In NeurIPS, 33:1877–1901, 2020
1901
- [4]
-
[5]
Chin-Yew
L. Chin-Yew. Rouge: A package for automatic evaluation of summaries. InACL Workshop on Text Summarization, 2004
2004
-
[6]
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi. InstructBLIP: Towards general-purpose vision-language models with instruction tuning. InIn NeurIPS, 2023
2023
-
[7]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. NeurIPS, 33:6840–6851, 2020
2020
-
[8]
Hosseinzadeh and Y
M. Hosseinzadeh and Y . Wang. Image change captioning by learning from an auxiliary task. InCVPR, pages 2725–2734, 2021
2021
-
[9]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
J. Hu, G. Zhong, J. Yuan, W. Pan, and X. Wang. Mct-ccdiff: Context- aware contrastive diffusion model with mediator-bridging cross-modal transformer for image change captioning.IEEE TIP, 2025
2025
-
[11]
R. Hu, M. Rohrbach, and T. Darrell. Segmentation from natural lan- guage expressions. InIn ECCV, pages 108–124, 2016
2016
-
[12]
Huang, Y
Q. Huang, Y . Liang, J. Wei, Y . Cai, H. Liang, H.-f. Leung, and Q. Li. Im- age difference captioning with instance-level fine-grained feature repre- sentation.IEEE TMM, 24:2004–2017, 2021
2004
-
[13]
Kazemzadeh, V
S. Kazemzadeh, V . Ordonez, M. Matten, and T. Berg. Referitgame: Referring to objects in photographs of natural scenes. InIn EMNLP, pages 787–798, 2014
2014
-
[14]
H. Kim, J. Kim, H. Lee, H. Park, and G. Kim. Agnostic change cap- tioning with cycle consistency. InICCV, pages 2095–2104, 2021
2095
-
[15]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, et al. Segment anything. InIn ICCV, pages 4015–4026, 2023
2023
-
[16]
X. Lai, Z. Tian, Y . Chen, Y . Li, Y . Yuan, S. Liu, and J. Jia. Lisa: Reason- ing segmentation via large language model. InIn CVPR, pages 9579– 9589, 2024
2024
-
[17]
C. Liu, H. Ding, and X. Jiang. Gres: Generalized referring expression segmentation. InCVPR, pages 23592–23601, 2023
2023
-
[18]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning.In CVPR, 36, 2024
2024
-
[19]
J. Mao, J. Huang, A. Toshev, O. Camburu, A. L. Yuille, and K. Murphy. Generation and comprehension of unambiguous object descriptions. In In CVPR, pages 11–20, 2016
2016
-
[20]
Papineni, S
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu. Bleu: A method for automatic evaluation of machine translation. InACL, pages 311–318, 2002
2002
-
[21]
D. H. Park, T. Darrell, and A. Rohrbach. Robust change captioning. In ICCV, pages 4624–4633, 2019
2019
-
[22]
Y . Qiu, S. Yamamoto, K. Nakashima, R. Suzuki, K. Iwata, H. Kataoka, and Y . Satoh. Describing and localizing multiple changes with trans- formers. InICCV, pages 1951–1960, 2021
1951
-
[23]
X. Shi, X. Yang, J. Gu, S. Joty, and J. Cai. Finding it at another side: A viewpoint-adapted matching encoder for change captioning. InECCV, pages 574–590. Springer, 2020
2020
-
[24]
H. Tan, F. Dernoncourt, Z. Lin, T. Bui, and M. Bansal. Expressing visual relationships via language. InACL, pages 1873–1883, 2019
2019
-
[25]
J. Tang, G. Zheng, C. Shi, and S. Yang. Contrastive grouping with trans- former for referring image segmentation. InIn CVPR, pages 23570– 23580, 2023
2023
-
[26]
Y . Tu, L. Li, C. Yan, S. Gao, and Z. Yu. R^3net: Relation-embedded rep- resentation reconstruction network for change captioning. InEMNLP, pages 9319–9329, 2021
2021
-
[27]
Y . Tu, T. Yao, L. Li, J. Lou, S. Gao, Z. Yu, and C. Yan. Semantic relation-aware difference representation learning for change captioning. InFindings of the Association for Computational Linguistics, pages 63– 73, 2021
2021
-
[28]
Y . Tu, L. Li, L. Su, J. Du, K. Lu, and Q. Huang. Viewpoint-adaptive representation disentanglement network for change captioning.IEEE TIP, 2023
2023
-
[29]
Y . Tu, L. Li, L. Su, K. Lu, and Q. Huang. Neighborhood contrastive transformer for change captioning.IEEE TMM, 2023
2023
-
[30]
Y . Tu, L. Li, L. Su, Z.-J. Zha, C. Yan, and Q. Huang. Self-supervised cross-view representation reconstruction for change captioning. In ICCV, pages 2805–2815, 2023
2023
-
[31]
Y . Tu, L. Li, L. Su, C. Yan, and Q. Huang. Distractors-immune represen- tation learning with cross-modal contrastive regularization for change captioning. InECCV, pages 311–328. Springer, 2024
2024
-
[32]
Y . Tu, L. Li, L. Su, Z.-J. Zha, and Q. Huang. Smart: Syntax-calibrated multi-aspect relation transformer for change captioning.IEEE TPAMI, 2024
2024
-
[33]
Y . Tu, L. Li, L. Su, Z.-J. Zha, C. Yan, and Q. Huang. Context-aware difference distilling for multi-change captioning. InACL, pages 7941– 7956, 2024
2024
-
[34]
Vedantam, C
R. Vedantam, C. Lawrence Zitnick, and D. Parikh. Cider: Consensus- based image description evaluation. InCVPR, pages 4566–4575, 2015
2015
-
[35]
T.-H. Wu, G. Biamby, D. Chan, L. Dunlap, R. Gupta, X. Wang, J. E. Gonzalez, and T. Darrell. See say and segment: Teaching lmms to over- come false premises. InCVPR, pages 13459–13469, 2024
2024
-
[36]
Z. Xia, D. Han, Y . Han, X. Pan, S. Song, and G. Huang. Gsva: General- ized segmentation via multimodal large language models. InIn CVPR, pages 3858–3869, 2024
2024
-
[37]
Z. Xu, Z. Chen, Y . Zhang, Y . Song, X. Wan, and G. Li. Bridging vision and language encoders: Parameter-efficient tuning for referring image segmentation. InICCV, pages 17503–17512, 2023
2023
- [38]
-
[39]
L. Yao, W. Wang, and Q. Jin. Image difference captioning with pre- training and contrastive learning. InAAAI, volume 36, pages 3108– 3116, 2022
2022
-
[40]
Zhang, H
X. Zhang, H. Wen, J. Wu, P. Qin, H. Xue’, and L. Nie. Differential- perceptive and retrieval-augmented mllm for change captioning. In ACM MM, pages 4148–4157, 2024
2024
-
[41]
Zhong, J
G. Zhong, J. Hu, J. Chen, J. Yuan, and W. Pan. Decider: Difference- aware contrastive diffusion model with adversarial perturbations for im- age change captioning. InAAAI, 2025
2025
-
[42]
Zou, Z.-Y
X. Zou, Z.-Y . Dou, J. Yang, Z. Gan, L. Li, C. Li, X. Dai, H. Behl, J. Wang, L. Yuan, et al. Generalized decoding for pixel, image, and language. InCVPR, pages 15116–15127, 2023
2023
-
[43]
X. Zou, J. Yang, H. Zhang, F. Li, L. Li, J. Wang, L. Wang, J. Gao, and Y . J. Lee. Segment everything everywhere all at once.NeurIPS, 36: 19769–19782, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.