LNN-Fly: Continuous-Time UAV Navigation for Robust Obstacle Avoidance under Timing Mismatch
Pith reviewed 2026-06-30 09:53 UTC · model grok-4.3
The pith
A continuous-time UAV policy with explicit interval conditioning and adaptive forgetting maintains obstacle avoidance under timing mismatches and stale observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
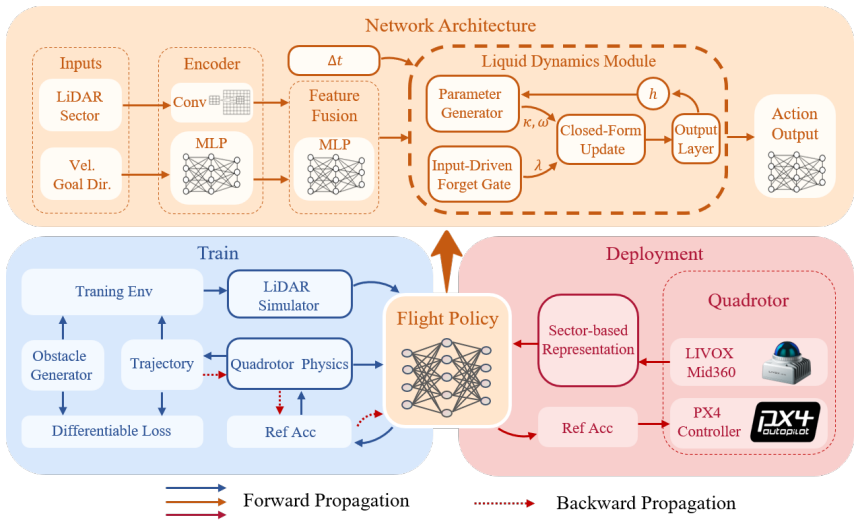
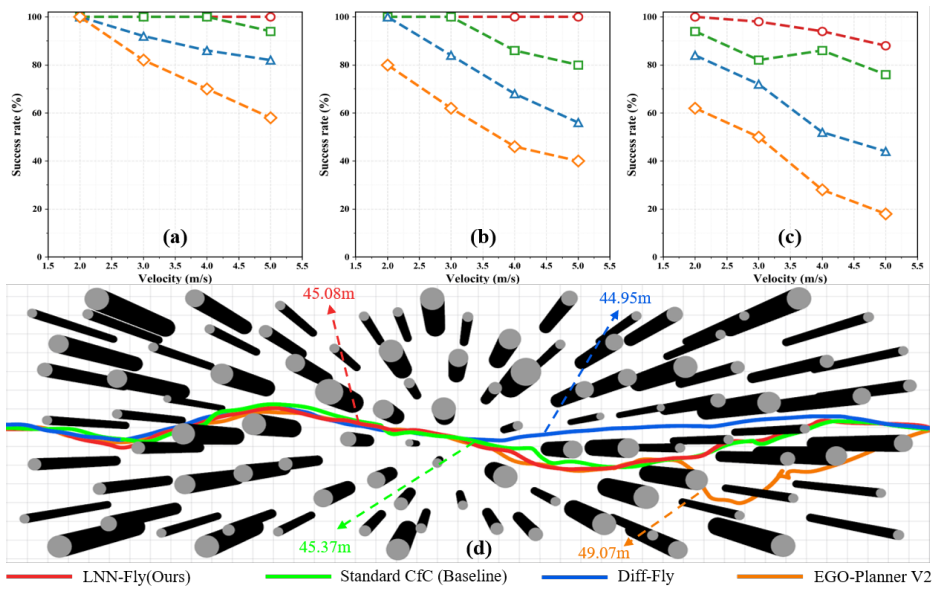
LNN-Fly combines a dynamic-programming-inspired structured recurrent update, explicit conditioning on the elapsed control interval Δt, and an input-driven adaptive forgetting gate that refreshes stale latent state near hazards while preserving consistency during sustained maneuvers. Trained with differentiable rollouts that incorporate deployment-relevant sensing and timing perturbations, the policy improves obstacle-avoidance performance under reduced control frequency, sparse observations, and control-period jitter. It transfers zero-shot to a physical quadrotor and achieves 100% success over 20 flights in indoor cross-frequency real-world tests.
What carries the argument
Dynamic-programming-inspired structured recurrent update with explicit Δt conditioning and input-driven adaptive forgetting gate that manages latent state consistency under variable timing.
If this is right
- Improves obstacle-avoidance performance under reduced control frequency, sparse observations, and control-period jitter in simulation.
- Transfers zero-shot from a simplified differentiable simulator to a physical quadrotor.
- Achieves 100% success over 20 flights in indoor cross-frequency real-world tests.
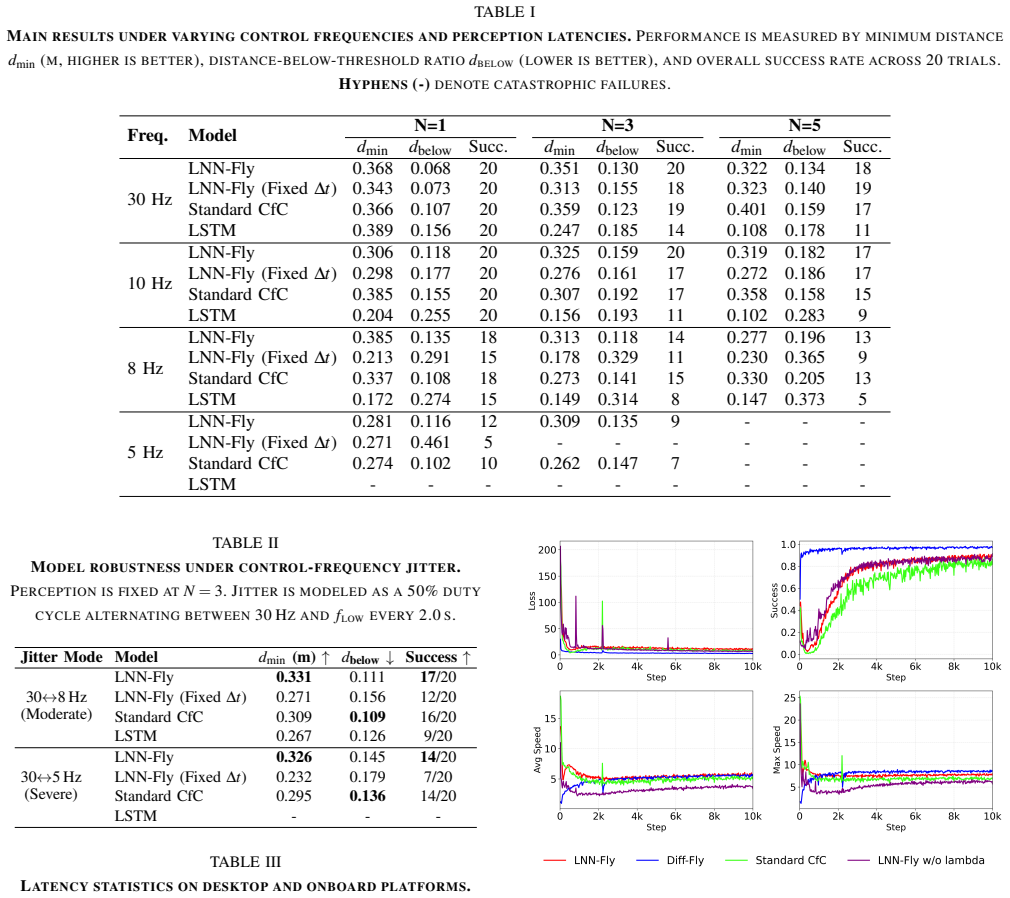
- Maintains low inference latency with median 0.514 ms on GPU, about 2.5 ms on CPU, and onboard P95 below 30 ms.
Where Pith is reading between the lines
- The training approach of injecting explicit timing perturbations could apply to other continuous-control robots that experience variable update rates.
- The adaptive forgetting gate may extend usefully to policies using sensors other than LiDAR when input staleness is an issue.
- Success of zero-shot transfer suggests that modeling deployment mismatches in simulation can lessen dependence on post-training adaptation.
- Further tests in outdoor or wind-affected settings would reveal whether the timing robustness generalizes beyond controlled indoor flights.
Load-bearing premise
The sensing irregularity and variable-rate control perturbations added during training are representative of the actual timing mismatches and observation staleness that occur on the physical platform.
What would settle it
Real-world flights under deliberately varied control periods and reduced observation rates that produce any collisions would show the robustness does not hold.
Figures


read the original abstract
End-to-end unmanned aerial vehicle (UAV) navigation can achieve impressive agility in simulation, yet its obstacle-avoidance behavior often degrades after deployment because the policy must tolerate simulator mismatch, sensing irregularity, and variable-rate control. These effects are especially dangerous in cluttered environments, where stale observations or short control irregularities can directly lead to collisions. We present LNN-Fly, a deployment-oriented continuous-time navigation policy for LiDAR-based UAV obstacle avoidance. The policy combines a dynamic-programming-inspired structured recurrent update, explicit conditioning on the elapsed control interval {\Delta}t, and an input-driven adaptive forgetting gate that refreshes stale latent state near hazards while preserving consistency during sustained maneuvers. It is trained with differentiable rollouts that incorporate deployment-relevant sensing and timing perturbations. In simulation, LNN-Fly improves obstacle-avoidance performance in the tested settings and shows better tolerance to reduced control frequency, sparse observations, and control-period jitter. It also transfers zero-shot from a simplified differentiable simulator to a physical quadrotor. In indoor cross-frequency real-world tests, the system achieves 100% success over 20 flights, while policy inference has a median latency of 0.514 ms on a desktop graphics processing unit (GPU) and about 2.5 ms on the onboard central processing unit (CPU), with onboard P95 latency below 30 ms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LNN-Fly, a continuous-time LiDAR-based UAV obstacle-avoidance policy that combines a dynamic-programming-inspired structured recurrent update, explicit conditioning on the elapsed control interval Δt, and an input-driven adaptive forgetting gate. It is trained end-to-end via differentiable rollouts that inject sensing irregularity and variable-rate control perturbations, and the authors report improved robustness to reduced control frequency, sparse observations, and jitter in simulation, plus zero-shot transfer to a physical quadrotor that achieves 100% success across 20 indoor cross-frequency flights with low inference latency.
Significance. If the central empirical claims are substantiated with adequate quantitative detail and verification that the injected perturbations match physical timing statistics, the work would address a practically important gap in deploying learned continuous-time policies on resource-constrained UAVs where control-period jitter and observation staleness are common failure modes.
major comments (2)
- [Abstract] Abstract: the headline claim of 100% success over 20 real-world flights is presented without any accompanying quantitative metrics (collision distance, path length, success rate versus baselines, or variance across trials), preventing assessment of effect size or comparison to prior art.
- [Training and evaluation sections] Training and evaluation sections: the perturbations for sensing irregularity and variable-rate control are described as 'deployment-relevant,' yet no quantitative matching (empirical CDFs, moment statistics, or Kolmogorov-Smirnov tests) is supplied between the simulated Δt and observation-age distributions and those logged from the physical platform. This directly bears on the validity of the zero-shot transfer and robustness claims.
minor comments (1)
- [Abstract] Abstract: the reported median latency of 0.514 ms on GPU should clarify whether this figure includes the full sensing-to-actuation pipeline or only the policy forward pass.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 100% success over 20 real-world flights is presented without any accompanying quantitative metrics (collision distance, path length, success rate versus baselines, or variance across trials), preventing assessment of effect size or comparison to prior art.
Authors: We agree that the abstract would benefit from additional quantitative context to allow readers to assess effect size. In the revised manuscript we will expand the abstract to include median minimum collision distances, average path lengths, success rates versus the main baselines, and standard deviation across the 20 trials while retaining the 100% success statement. The detailed per-trial data already appear in the experimental section and will be cross-referenced. revision: yes
-
Referee: [Training and evaluation sections] Training and evaluation sections: the perturbations for sensing irregularity and variable-rate control are described as 'deployment-relevant,' yet no quantitative matching (empirical CDFs, moment statistics, or Kolmogorov-Smirnov tests) is supplied between the simulated Δt and observation-age distributions and those logged from the physical platform. This directly bears on the validity of the zero-shot transfer and robustness claims.
Authors: The observation is correct; the original submission does not supply direct distributional comparisons. We will add, in the revised training and evaluation sections, empirical CDF plots, first- and second-moment statistics, and Kolmogorov-Smirnov test p-values between the simulated perturbation distributions and the logged physical-platform timing traces. These additions will be placed immediately after the description of the perturbation model. revision: yes
Circularity Check
No circularity; empirical results from trained policy with no derivation chain reducing to inputs
full rationale
The paper describes an end-to-end trained continuous-time policy using differentiable rollouts with injected perturbations for timing and sensing mismatch. Performance claims (simulation improvements, zero-shot transfer, 100% real-world success) are presented as experimental outcomes rather than analytical predictions or derivations. No equations, self-citations, or fitted parameters are shown that reduce reported metrics to quantities defined by construction from the inputs. The work is self-contained against external benchmarks via direct testing.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Champion-level drone racing using deep reinforce- ment learning,
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Champion-level drone racing using deep reinforce- ment learning,”Nature, vol. 620, no. 7976, pp. 982–987, 2023
2023
-
[2]
Reaching the limit in autonomous racing: Optimal control versus reinforcement learning,
Y . Song, A. Romero, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Reaching the limit in autonomous racing: Optimal control versus reinforcement learning,”Science Robotics, vol. 8, no. 82, p. eadg1462, 2023
2023
-
[3]
Learning high-speed flight in the wild,
A. Loquercio, E. Kaufmann, R. Ranftl, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Learning high-speed flight in the wild,”Science Robotics, vol. 6, no. 59, p. eabg5810, 2021
2021
-
[4]
Learning vision-based agile flight via differentiable physics,
Y . Zhang, Y . Hu, Y . Song, D. Zou, and W. Lin, “Learning vision-based agile flight via differentiable physics,”Nature Machine Intelligence, vol. 7, no. 6, pp. 954–966, 2025
2025
-
[5]
Seeing through pixel motion: Learning obstacle avoidance from optical flow with one camera,
Y . Hu, Y . Zhang, Y . Song, Y . Deng, F. Yu, L. Zhang, W. Lin, D. Zou, and W. Yu, “Seeing through pixel motion: Learning obstacle avoidance from optical flow with one camera,”IEEE Robotics and Automation Letters, 2025
2025
-
[6]
A fully-autonomous aerial robot for search and rescue applications in indoor environments using learning-based techniques,
C. Sampedro, A. Rodriguez-Ramos, H. Bavle, A. Carrio, P. De la Puente, and P. Campoy, “A fully-autonomous aerial robot for search and rescue applications in indoor environments using learning-based techniques,”Journal of Intelligent & Robotic Systems, vol. 95, no. 2, pp. 601–627, 2019
2019
-
[7]
Learning to fly by myself: A self- supervised cnn-based approach for autonomous navigation,
A. Kouris and C.-S. Bouganis, “Learning to fly by myself: A self- supervised cnn-based approach for autonomous navigation,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1–9
2018
-
[8]
Shrinking pomcp: A framework for real-time uav search and rescue,
Y . Zhang, B. Luo, A. Mukhopadhyay, D. Stojcsics, D. Elenius, A. Roy, S. Jha, M. Maroti, X. Koutsoukos, G. Karsaiet al., “Shrinking pomcp: A framework for real-time uav search and rescue,” in2024 International Conference on Assured Autonomy (ICAA). IEEE, 2024, pp. 48–57
2024
-
[9]
Uav path planning for wildfires-sustainably fighting wildfires with automated path planning for uavs,
Z. Hasan, S. Kumar, V . Patel, N. Poplavskyy, P. Subbaraman, and N. Xue, “Uav path planning for wildfires-sustainably fighting wildfires with automated path planning for uavs,” 2022
2022
-
[10]
Crossing the reality gap: A survey on sim-to-real transferability of robot controllers in reinforcement learning,
E. Salvato, G. Fenu, E. Medvet, and F. A. Pellegrino, “Crossing the reality gap: A survey on sim-to-real transferability of robot controllers in reinforcement learning,”IEEE Access, vol. 9, pp. 153 171–153 187, 2021
2021
-
[11]
Model-free uav navigation in unknown complex environments using vision-based reinforcement learning,
H. Wu, W. Wang, T. Wang, and S. Suzuki, “Model-free uav navigation in unknown complex environments using vision-based reinforcement learning,”Drones, vol. 9, no. 8, p. 566, 2025
2025
-
[12]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[13]
Gaussian splatting to real world flight navigation transfer with liquid networks,
A. Quach, M. Chahine, A. Amini, R. Hasani, and D. Rus, “Gaussian splatting to real world flight navigation transfer with liquid networks,” arXiv preprint arXiv:2406.15149, 2024
-
[14]
Latent ordinary differential equations for irregularly-sampled time series,
Y . Rubanova, R. T. Chen, and D. K. Duvenaud, “Latent ordinary differential equations for irregularly-sampled time series,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[15]
Learning on the fly: Rapid policy adaptation via differentiable simu- lation,
J. Pan, J. Xing, R. Reiter, Y . Zhai, E. Aljalbout, and D. Scaramuzza, “Learning on the fly: Rapid policy adaptation via differentiable simu- lation,”IEEE Robotics and Automation Letters, 2026
2026
-
[16]
Robust and efficient quadrotor trajectory generation for fast autonomous flight,
B. Zhou, F. Gao, L. Wang, C. Liu, and S. Shen, “Robust and efficient quadrotor trajectory generation for fast autonomous flight,”IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 3529–3536, 2019
2019
-
[17]
Ego-planner: An esdf- free gradient-based local planner for quadrotors,
X. Zhou, Z. Wang, H. Ye, C. Xu, and F. Gao, “Ego-planner: An esdf- free gradient-based local planner for quadrotors,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 478–485, 2020
2020
-
[18]
Ego-swarm: A fully autonomous and decentralized quadrotor swarm system in cluttered environments,
X. Zhou, J. Zhu, H. Zhou, C. Xu, and F. Gao, “Ego-swarm: A fully autonomous and decentralized quadrotor swarm system in cluttered environments,” in2021 IEEE international conference on robotics and automation (ICRA). IEEE, 2021, pp. 4101–4107
2021
-
[19]
Toward low-flying autonomous mav trail navigation using deep neural net- works for environmental awareness,
N. Smolyanskiy, A. Kamenev, J. Smith, and S. Birchfield, “Toward low-flying autonomous mav trail navigation using deep neural net- works for environmental awareness,” in2017 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2017, pp. 4241–4247
2017
-
[20]
You only plan once: A learning-based one-stage planner with guidance learning,
J. Lu, X. Zhang, H. Shen, L. Xu, and B. Tian, “You only plan once: A learning-based one-stage planner with guidance learning,”IEEE Robotics and Automation Letters, vol. 9, no. 7, pp. 6083–6090, 2024
2024
-
[21]
Yopov2-tracker: An end-to-end agile tracking and navigation frame- work from perception to action,
J. Lu, Y . Hui, X. Zhang, W. Feng, H. Shen, Z. Li, and B. Tian, “Yopov2-tracker: An end-to-end agile tracking and navigation frame- work from perception to action,”arXiv preprint arXiv:2505.06923, 2025
-
[22]
Vision transformers for end-to-end vision- based quadrotor obstacle avoidance,
A. Bhattacharya, N. Rao, D. Parikh, P. Kunapuli, Y . Wu, Y . Tao, N. Matni, and V . Kumar, “Vision transformers for end-to-end vision- based quadrotor obstacle avoidance,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 1–8
2025
-
[23]
Dream to Fly: Model-Based Reinforcement Learning for Vision-Based Drone Flight
A. Romero, A. Shenai, I. Geles, E. Aljalbout, and D. Scaramuzza, “Dream to fly: Model-based reinforcement learning for vision-based drone flight,”arXiv preprint arXiv:2501.14377, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Singer: An onboard generalist vision-language navigation policy for drones,
M. Adang, J. Low, O. Shorinwa, and M. Schwager, “Singer: An onboard generalist vision-language navigation policy for drones,” arXiv preprint arXiv:2509.18610, 2025
-
[25]
Xu,Reasoning for Representations for Learning-Based Control
Z. Xu,Reasoning for Representations for Learning-Based Control. University of California, Berkeley, 2021
2021
-
[26]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in2017 IEEE/RSJ international con- ference on intelligent robots and systems (IROS). IEEE, 2017, pp. 23–30
2017
-
[27]
Solving Rubik's Cube with a Robot Hand
I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribaset al., “Solving rubik’s cube with a robot hand,”arXiv preprint arXiv:1910.07113, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[28]
Contrastive learning for enhancing robust scene transfer in vision- based agile flight,
J. Xing, L. Bauersfeld, Y . Song, C. Xing, and D. Scaramuzza, “Contrastive learning for enhancing robust scene transfer in vision- based agile flight,” in2024 IEEE international conference on robotics and automation (ICRA). IEEE, 2024, pp. 5330–5337
2024
-
[29]
Environ- ment as policy: Learning to race in unseen tracks,
H. Wang, J. Xing, N. Messikommer, and D. Scaramuzza, “Environ- ment as policy: Learning to race in unseen tracks,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 333–11 339
2025
-
[30]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inInternational conference on machine learning. PMLR, 2017, pp. 1126–1135
2017
-
[31]
RMA: Rapid Motor Adaptation for Legged Robots
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “Rma: Rapid motor adaptation for legged robots,”arXiv preprint arXiv:2107.04034, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Neurobem: Hybrid aerodynamic quadrotor model,
L. Bauersfeld, E. Kaufmann, P. Foehn, S. Sun, and D. Scaramuzza, “Neurobem: Hybrid aerodynamic quadrotor model,”arXiv preprint arXiv:2106.08015, 2021
-
[33]
Safe reinforcement learning via shielding,
M. Alshiekh, R. Bloem, R. Ehlers, B. K ¨onighofer, S. Niekum, and U. Topcu, “Safe reinforcement learning via shielding,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
2018
-
[34]
Navrl: Learning safe flight in dynamic environments,
Z. Xu, X. Han, H. Shen, H. Jin, and K. Shimada, “Navrl: Learning safe flight in dynamic environments,”IEEE Robotics and Automation Letters, 2025
2025
-
[35]
Autonomous quadrotor obstacle avoidance based on dueling double deep recurrent q-learning with monocular vision,
J. Ou, X. Guo, M. Zhu, and W. Lou, “Autonomous quadrotor obstacle avoidance based on dueling double deep recurrent q-learning with monocular vision,”Neurocomputing, vol. 441, pp. 300–310, 2021
2021
-
[36]
Neu- ral ordinary differential equations,
R. T. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neu- ral ordinary differential equations,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[37]
Neural controlled differential equations for irregular time series,
P. Kidger, J. Morrill, J. Foster, and T. Lyons, “Neural controlled differential equations for irregular time series,”Advances in neural information processing systems, vol. 33, pp. 6696–6707, 2020
2020
-
[38]
Liquid time-constant networks,
R. Hasani, M. Lechner, A. Amini, D. Rus, and R. Grosu, “Liquid time-constant networks,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 9, 2021, pp. 7657–7666
2021
-
[39]
Closed-form continuous- time neural networks,
R. Hasani, M. Lechner, A. Amini, L. Liebenwein, A. Ray, M. Tschaikowski, G. Teschl, and D. Rus, “Closed-form continuous- time neural networks,”Nature Machine Intelligence, vol. 4, no. 11, pp. 992–1003, 2022
2022
-
[40]
Robust flight navigation with liquid neural networks,
P. Kao, “Robust flight navigation with liquid neural networks,” Ph.D. dissertation, Massachusetts Institute of Technology, 2022
2022
-
[41]
Flying on point clouds with reinforcement learning,
G. Xu, T. Wu, Z. Wang, Q. Wang, and F. Gao, “Flying on point clouds with reinforcement learning,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 7231–7238
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.