TrafficAlign: Aligning Large Language Models for Traffic Scenario Generation
Pith reviewed 2026-06-30 09:17 UTC · model grok-4.3
The pith
TrafficAlign aligns LLMs with real driving videos to generate traffic scenarios that expose more collisions in autonomous models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
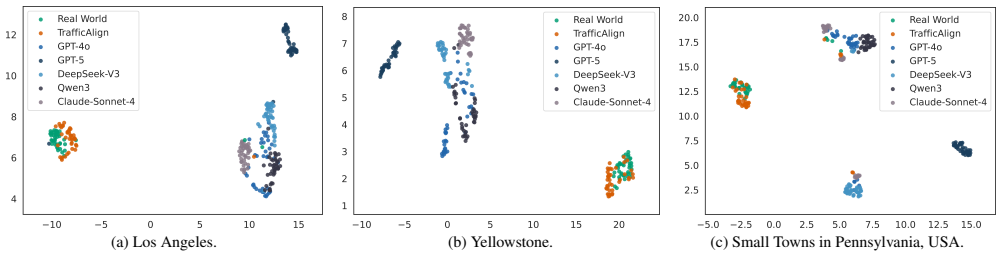
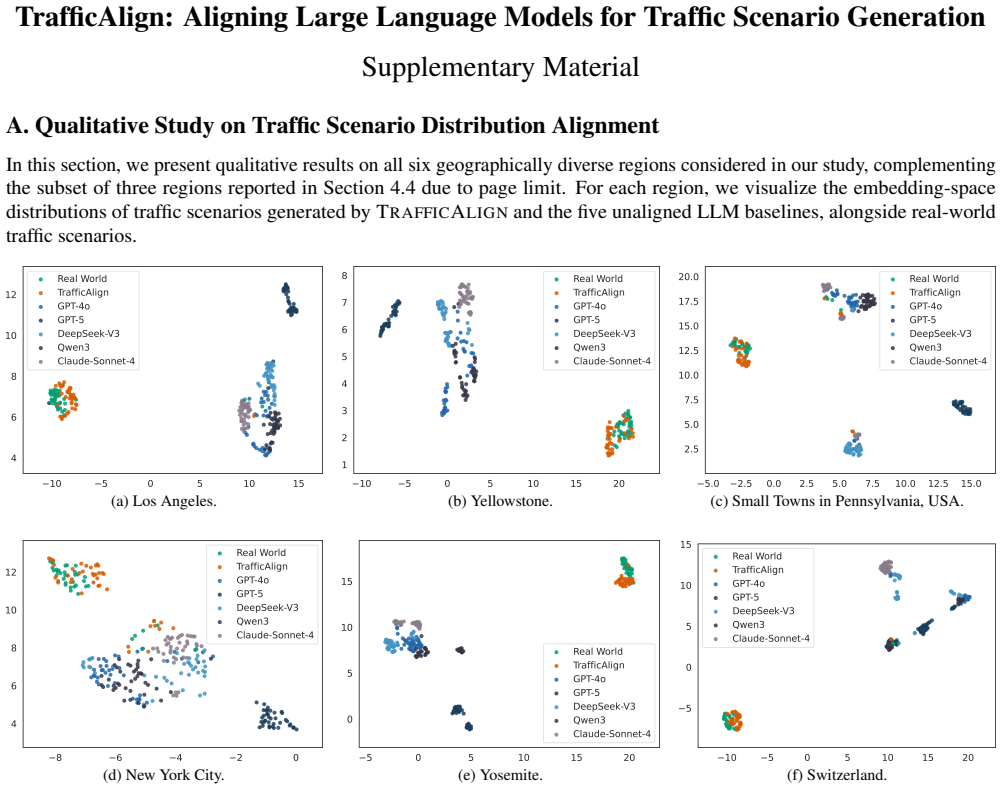
TrafficAlign is an automated framework that synthesizes traffic scenarios based on real-world driving videos, performs data validation, and aligns large language models with the synthesized scenarios. Scenarios generated this way reveal up to 10.8 percent more collisions on average across three autonomous driving models than prior methods. Fine-tuning the driving models on these scenarios reduces their collision rates by 36.1 percent relative to the original models. A study across traffic datasets from six geographic regions confirms that the generated scenarios align strongly with local traffic distributions.
What carries the argument
TrafficAlign framework that synthesizes scenarios from videos, validates the data, and aligns LLMs to the resulting scenarios.
If this is right
- Autonomous driving models encounter more collision cases when tested against the generated scenarios.
- Fine-tuning autonomous models on the scenarios produces versions with measurably lower collision rates.
- The scenarios maintain alignment with traffic patterns observed in multiple geographic regions.
- The method supplies a route to improve safety testing of driving models using synthetic data.
Where Pith is reading between the lines
- The alignment process could be adapted to generate test cases for other domains that rely on simulation, such as robotic navigation.
- If the bias-free assumption holds, the technique might reduce reliance on large-scale real-world data collection for model improvement.
- Extending the video synthesis step with additional sensor inputs could produce even richer scenario sets for edge-case discovery.
Load-bearing premise
The synthesized scenarios and data validation produce distributions that match real-world traffic without systematic bias from the source videos or the synthesis process.
What would settle it
Independent real-world driving data from the same regions shows no increase in detected collisions or no reduction in collision rates after fine-tuning on TrafficAlign scenarios.
Figures


read the original abstract
Recent research has investigated the use of large language models (LLMs) to generate traffic scenarios for autonomous driving. However, pretrained LLMs often fail to align with real-world traffic distributions. In this work, we present TrafficAlign, an automated framework that synthesizes traffic scenarios based on real-world driving videos, performs data validation, and aligns LLMs with the synthesized scenarios. The evaluation shows that traffic scenarios generated by TrafficAlign are highly effective, revealing up to 10.8% more collisions on average across three autonomous driving models than state-of-the-art methods. Furthermore, fine-tuning these driving models with TrafficAlign-generated scenarios significantly reduced collision rates by 36.1% compared with the original models. A qualitative study using traffic datasets from six geographically diverse regions shows that TrafficAlign-generated scenarios exhibit strong alignment with corresponding traffic distributions in these regions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TrafficAlign, an automated framework that synthesizes traffic scenarios from real-world driving videos, performs data validation, and aligns LLMs with the resulting scenarios. It reports that the generated scenarios reveal up to 10.8% more collisions on average across three autonomous driving models than state-of-the-art methods, that fine-tuning the models on these scenarios reduces collision rates by 36.1%, and that a qualitative study across six geographically diverse regions shows strong distributional alignment.
Significance. If the synthesized scenarios prove representative without systematic bias from the source videos or synthesis process, the work could meaningfully advance LLM-based scenario generation for autonomous driving safety testing and fine-tuning, with the reported collision exposure and reduction figures indicating practical utility.
major comments (2)
- [Abstract] Abstract: the headline claims of 10.8% more collisions revealed and 36.1% collision-rate reduction after fine-tuning rest on the unexamined assumption that the validation step produces physically plausible, kinematically consistent scenarios; without explicit checks for these properties the elevated collision counts could reflect artifacts rather than improved coverage.
- [Framework description] Framework description paragraph: the data validation step is described only at high level; if it is limited to surface statistics or output format rather than enforcing traffic-rule compliance and physical constraints, the representativeness claim (and therefore both effectiveness numbers) is load-bearing and unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the importance of the data validation step. We agree that the current description is high-level and will revise the manuscript to provide more explicit details and evidence on physical plausibility and constraint enforcement.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 10.8% more collisions revealed and 36.1% collision-rate reduction after fine-tuning rest on the unexamined assumption that the validation step produces physically plausible, kinematically consistent scenarios; without explicit checks for these properties the elevated collision counts could reflect artifacts rather than improved coverage.
Authors: We agree that the headline results depend on the validation producing valid scenarios and that the manuscript does not provide explicit verification of physical plausibility or kinematic consistency. In revision we will expand the abstract and add a new subsection detailing the validation criteria (including kinematic checks derived from source videos and traffic-rule filters) along with supporting quantitative analysis to confirm the scenarios are not artifacts. revision: yes
-
Referee: [Framework description] Framework description paragraph: the data validation step is described only at high level; if it is limited to surface statistics or output format rather than enforcing traffic-rule compliance and physical constraints, the representativeness claim (and therefore both effectiveness numbers) is load-bearing and unverified.
Authors: The referee is correct that the framework paragraph describes validation at a high level. While the process incorporates rule-based filters for traffic compliance and kinematic modeling from the videos, these are not elaborated. We will revise the section to explicitly list the validation mechanisms and include evidence (e.g., pass rates or examples) demonstrating enforcement of physical constraints and rules, thereby supporting the representativeness claims. revision: yes
Circularity Check
No circularity: derivation relies on external video data and independent evaluation metrics
full rationale
The provided abstract and framework description outline a pipeline of synthesizing scenarios from real-world videos, performing data validation, aligning the LLM, and then measuring effectiveness via collision revelation on autonomous driving models and fine-tuning improvements. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems are present in the text that would reduce any claimed result to its own inputs by construction. The evaluation metrics (collision rates, fine-tuning gains) are distinct from the synthesis source and can be externally falsified, making the chain self-contained against the given material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Testing autonomous cars for feature interaction failures using many-objective search
Raja Ben Abdessalem, Annibale Panichella, Shiva Nejati, Li- onel C Briand, and Thomas Stifter. Testing autonomous cars for feature interaction failures using many-objective search. InProceedings of the 33rd ACM/IEEE International Confer- ence on Automated Software Engineering, pages 143–154,
-
[2]
Generating adversarial driving scenarios in high- fidelity simulators
Yasasa Abeysirigoonawardena, Florian Shkurti, and Gregory Dudek. Generating adversarial driving scenarios in high- fidelity simulators. In2019 International Conference on Robotics and Automation (ICRA), pages 8271–8277, 2019. 2
2019
-
[3]
Generating traffic scenarios via in- context learning to learn better motion planner
Aizierjiang Aiersilan. Generating traffic scenarios via in- context learning to learn better motion planner. InAAAI-25, Sponsored by the Association for the Advancement of Artifi- cial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 14539–14547. AAAI Press, 2025. 1
2025
-
[4]
System card: Claude opus 4 & claude sonnet 4
Anthropic. System card: Claude opus 4 & claude sonnet 4. https : / / www - cdn . anthropic . com / 6be99a52cb68eb70eb9572b4cafad13df32ed995. pdf, 2025. Accessed: 2025-10-27. 5
2025
-
[5]
Ontology based scene creation for the development of automated ve- hicles
Gerrit Bagschik, Till Menzel, and Markus Maurer. Ontology based scene creation for the development of automated ve- hicles. In2018 IEEE Intelligent Vehicles Symposium (IV), pages 1813–1820, 2018. 2
2018
-
[6]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020. 3
1901
-
[7]
Behavexplor: Behavior diversity guided testing for autonomous driving systems
Mingfei Cheng, Yuan Zhou, and Xiaofei Xie. Behavexplor: Behavior diversity guided testing for autonomous driving systems. InProceedings of the 32nd ACM SIGSOFT Interna- tional Symposium on Software Testing and Analysis, pages 488–500, 2023. 2
2023
-
[8]
Sledge: Synthesizing driving environments with generative models and rule-based traffic
Kashyap Chitta, Daniel Dauner, and Andreas Geiger. Sledge: Synthesizing driving environments with generative models and rule-based traffic. InEuropean Conference on Computer Vision, pages 57–74. Springer, 2024. 2
2024
-
[9]
Deepseek-v3 technical report, 2024
DeepSeek-AI. Deepseek-v3 technical report, 2024. 5
2024
-
[10]
TARGET: traffic rule-based test generation for autonomous driving via validated llm-guided knowledge extraction.IEEE Trans
Yao Deng, Zhi Tu, Jiaohong Yao, Mengshi Zhang, Tianyi Zhang, and James Xi Zheng. TARGET: traffic rule-based test generation for autonomous driving via validated llm-guided knowledge extraction.IEEE Trans. Software Eng., 51(7): 1950–1968, 2025. 1, 2, 4, 7
1950
-
[11]
Meta-sim2: Unsupervised learning of scene structure for synthetic data generation
Jeevan Devaranjan, Amlan Kar, and Sanja Fidler. Meta-sim2: Unsupervised learning of scene structure for synthetic data generation. InEuropean Conference on Computer Vision, pages 715–733. Springer, 2020. 2
2020
-
[12]
Learning to collide: An adaptive safety-critical scenarios gen- erating method
Wenhao Ding, Baiming Chen, Minjun Xu, and Ding Zhao. Learning to collide: An adaptive safety-critical scenarios gen- erating method. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2243–2250. IEEE, 2020. 1, 5, 6, 7
2020
-
[13]
Cmts: A condi- tional multiple trajectory synthesizer for generating safety- critical driving scenarios
Wenhao Ding, Mengdi Xu, and Ding Zhao. Cmts: A condi- tional multiple trajectory synthesizer for generating safety- critical driving scenarios. In2020 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 4314–4321,
-
[14]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InProceedings of the 1st Annual Conference on Robot Learning, pages 1–16. PMLR, 2017. 5
2017
-
[15]
Karim Elmaaroufi, Devan Shanker, Ana Cismaru, Marcell Vazquez-Chanlatte, Alberto Sangiovanni-Vincentelli, Matei Zaharia, and Sanjit A Seshia. Scenicnl: generating probabilis- tic scenario programs from natural language.arXiv preprint arXiv:2405.03709, 2024. 1, 2
-
[16]
Fremont, Edward Kim, Tommaso Dreossi, Shromona Ghosh, Xiangyu Yue, Alberto L
Daniel J. Fremont, Edward Kim, Tommaso Dreossi, Shromona Ghosh, Xiangyu Yue, Alberto L. Sangiovanni- Vincentelli, and Sanjit A. Seshia. Scenic: a language for scenario specification and data generation.Mach. Learn., 112 (10):3805–3849, 2023. 2, 5
2023
-
[17]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInter- national conference on machine learning, pages 1587–1596. PMLR, 2018. 5
2018
-
[18]
Generating effective test cases for self-driving cars from police reports
Alessio Gambi, Tri Huynh, and Gordon Fraser. Generating effective test cases for self-driving cars from police reports. InProceedings of the 2019 27th ACM Joint Meeting on Euro- pean Software Engineering Conference and Symposium on the Foundations of Software Engineering, page 257–267, New York, NY , USA, 2019. Association for Computing Machinery. 2
2019
-
[19]
Sovar: Build generalizable scenarios from accident reports for autonomous driving testing
An Guo, Yuan Zhou, Haoxiang Tian, Chunrong Fang, Yunjian Sun, Weisong Sun, Xinyu Gao, Anh Tuan Luu, Yang Liu, and Zhenyu Chen. Sovar: Build generalizable scenarios from accident reports for autonomous driving testing. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pages 268–280, 2024. 2
2024
-
[20]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInterna- tional conference on machine learning, pages 1861–1870. Pmlr, 2018. 5
2018
-
[21]
Liao, Esin Durmus, Alex Tamkin, and Deep Ganguli
Saffron Huang, Divya Siddarth, Liane Lovitt, Thomas I. Liao, Esin Durmus, Alex Tamkin, and Deep Ganguli. Collective constitutional AI: aligning a language model with public input. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency, FAccT 2024, Rio de Janeiro, Brazil, June 3-6, 2024, pages 1395–1417. ACM, 2024. 2
2024
-
[22]
Meta-sim: Learning to generate synthetic datasets
Amlan Kar, Aayush Prakash, Ming-Yu Liu, Eric Cameracci, Justin Yuan, Matt Rusiniak, David Acuna, Antonio Torralba, and Sanja Fidler. Meta-sim: Learning to generate synthetic datasets. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), 2019. 2
2019
-
[23]
Drivefuzz: Discovering autonomous driving bugs through driving quality- guided fuzzing
Seulbae Kim, Major Liu, Junghwan” John” Rhee, Yuseok Jeon, Yonghwi Kwon, and Chung Hwan Kim. Drivefuzz: Discovering autonomous driving bugs through driving quality- guided fuzzing. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 1753–1767, 2022. 2
2022
-
[24]
Hannah Rose Kirk, Alexander Whitefield, Paul R¨ottger, An- drew Bean, Katerina Margatina, Juan Ciro, Rafael Mosquera, 9 Max Bartolo, Adina Williams, He He, Bertie Vidgen, and Scott A. Hale. The prism alignment dataset: What partic- ipatory, representative and individualised human feedback reveals about the subjective and multicultural alignment of large l...
2024
-
[25]
Scenario factory: Creating safety-critical traffic scenarios for automated vehicles
Moritz Klischat, Edmond Irani Liu, Fabian Holtke, and Matthias Althoff. Scenario factory: Creating safety-critical traffic scenarios for automated vehicles. In2020 IEEE 23rd International Conference on Intelligent Transportation Sys- tems (ITSC), pages 1–7, 2020. 2
2020
-
[26]
Kochenderfer, Ole J
Ritchie Lee, Mykel J. Kochenderfer, Ole J. Mengshoel, Guil- laume P. Brat, and Michael P. Owen. Adaptive stress testing of airborne collision avoidance systems. In2015 IEEE/AIAA 34th Digital Avionics Systems Conference (DASC), pages 6C2–1–6C2–13, 2015. 2
2015
-
[27]
Av-fuzzer: Finding safety violations in autonomous driving systems
Guanpeng Li, Yiran Li, Saurabh Jha, Timothy Tsai, Michael Sullivan, Siva Kumar Sastry Hari, Zbigniew Kalbarczyk, and Ravishankar Iyer. Av-fuzzer: Finding safety violations in autonomous driving systems. In2020 IEEE 31st international symposium on software reliability engineering (ISSRE), pages 25–36. IEEE, 2020. 2
2020
-
[28]
Flame: Factuality- aware alignment for large language models.Advances in Neural Information Processing Systems, 37:115588–115614,
Sheng-Chieh Lin, Luyu Gao, Barlas Oguz, Wenhan Xiong, Jimmy Lin, Wen-tau Yih, and Xilun Chen. Flame: Factuality- aware alignment for large language models.Advances in Neural Information Processing Systems, 37:115588–115614,
-
[29]
Targeting requirements violations of autonomous driving systems by dynamic evolutionary search
Yixing Luo, Xiao-Yi Zhang, Paolo Arcaini, Zhi Jin, Haiyan Zhao, Fuyuki Ishikawa, Rongxin Wu, and Tao Xie. Targeting requirements violations of autonomous driving systems by dynamic evolutionary search. In2021 36th IEEE/ACM In- ternational Conference on Automated Software Engineering (ASE), pages 279–291. IEEE, 2021. 2
2021
-
[30]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimen- sion reduction.arXiv preprint arXiv:1802.03426, 2018. 8
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Llama-3.2-3B-Instruct
Meta. Llama-3.2-3B-Instruct. https://huggingface. co/meta-llama/Llama-3.2-3B-Instruct , 2024. Hugging Face model card, accessed March, 2026. 4
2024
-
[32]
Standing general order on crash reporting
NHTSA. Standing general order on crash reporting. https://www.nhtsa.gov/laws- regulations/ standing - general - order - crash - reporting,
-
[33]
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
GPT-4.1 nano
OpenAI. GPT-4.1 nano. https://platform.openai. com/docs/models/gpt-4.1-nano, 2025. 3
2025
-
[35]
GPT-5 system card
OpenAI. GPT-5 system card. https://cdn.openai. com/gpt-5-system-card.pdf, 2025. 4, 5
2025
-
[36]
Scenario diffusion: Controllable driving scenario gen- eration with diffusion
Ethan Pronovost, Meghana Reddy Ganesina, Noureldin Hendy, Zeyu Wang, Andres Morales, Kai Wang, and Nick Roy. Scenario diffusion: Controllable driving scenario gen- eration with diffusion. InAdvances in Neural Information Processing Systems, pages 68873–68894. Curran Associates, Inc., 2023. 2
2023
-
[37]
Qwen3-32b-fp8
Qwen Team. Qwen3-32b-fp8. https://huggingface. co/Qwen/Qwen3- 32B- FP8, 2025. FP8-quantized re- lease; Apache-2.0 license. 5
2025
-
[38]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Lan- guage Processing. Association for Computational Linguistics,
2019
-
[39]
Generating useful accident-prone driving scenarios via a learned traffic prior
Davis Rempe, Jonah Philion, Leonidas J Guibas, Sanja Fi- dler, and Or Litany. Generating useful accident-prone driving scenarios via a learned traffic prior. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 17305–17315, 2022. 2
2022
-
[40]
Automated scenario generation for regression testing of autonomous vehicles
Elias Rocklage, Heiko Kraft, Abdullah Karatas, and J ¨org Seewig. Automated scenario generation for regression testing of autonomous vehicles. In2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), pages 476–483, 2017. 2
2017
-
[41]
Scanlon, Kristofer D
John M. Scanlon, Kristofer D. Kusano, Tom Daniel, Christo- pher Alderson, Alexander Ogle, and Trent Victor. Waymo sim- ulated driving behavior in reconstructed fatal crashes within an autonomous vehicle operating domain.Accident Analysis & Prevention, 163:106454, 2021. 2
2021
-
[42]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Role- play with large language models, 2023
Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role- play with large language models, 2023. 3
2023
-
[44]
Talk2traffic: Interactive and editable traffic scenario generation for autonomous driving with multimodal large lan- guage model
Zihao Sheng, Zilin Huang, Yansong Qu, Yue Leng, and Sikai Chen. Talk2traffic: Interactive and editable traffic scenario generation for autonomous driving with multimodal large lan- guage model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 3827–3836, 2025. 1
2025
-
[45]
Lawbreaker: An approach for specifying traffic laws and fuzzing autonomous vehicles
Yang Sun, Christopher M Poskitt, Jun Sun, Yuqi Chen, and Zijiang Yang. Lawbreaker: An approach for specifying traffic laws and fuzzing autonomous vehicles. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, pages 1–12, 2022. 2
2022
-
[46]
Trafficsim: Learning to simulate realistic multi- agent behaviors
Simon Suo, Sebastian Regalado, Sergio Casas, and Raquel Urtasun. Trafficsim: Learning to simulate realistic multi- agent behaviors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10400–10409, 2021. 2
2021
-
[47]
Language conditioned traffic gen- eration
Shuhan Tan, Boris Ivanovic, Xinshuo Weng, Marco Pavone, and Philipp Kr¨ahenb¨uhl. Language conditioned traffic gen- eration. InConference on Robot Learning, CoRL 2023, 6-9 November 2023, Atlanta, GA, USA, pages 2714–2752. PMLR,
2023
-
[48]
Legend: A top-down approach to scenario generation of autonomous driving systems as- sisted by large language models
Shuncheng Tang, Zhenya Zhang, Jixiang Zhou, Lei Lei, Yuan Zhou, and Yinxing Xue. Legend: A top-down approach to scenario generation of autonomous driving systems as- sisted by large language models. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pages 1497–1508, 2024. 1
2024
-
[49]
Carla scenario run- ner
CARLA Scenario Runner Team. Carla scenario run- ner. https://github.com/carla- simulator/ scenario_runner, 2019. 1, 5, 6, 7 10
2019
-
[50]
sentence-transformers/all- mpnet-base-v2
SentenceTransformers Team. sentence-transformers/all- mpnet-base-v2. https : / / huggingface . co / sentence-transformers/all-mpnet-base-v2 ,
-
[51]
Accessed: 2025-11-07. 8
2025
-
[52]
Generating critical test scenarios for autonomous driving systems via influential be- havior patterns
Haoxiang Tian, Guoquan Wu, Jiren Yan, Yan Jiang, Jun Wei, Wei Chen, Shuo Li, and Dan Ye. Generating critical test scenarios for autonomous driving systems via influential be- havior patterns. InProceedings of the 37th IEEE/ACM In- ternational Conference on Automated Software Engineering, pages 1–12, 2022. 2
2022
-
[53]
Multi- modal traffic scenario generation for autonomous driving system testing.Proc
Zhi Tu, Liangkun Niu, Wei Fan, and Tianyi Zhang. Multi- modal traffic scenario generation for autonomous driving system testing.Proc. ACM Softw. Eng., 2(FSE), 2025. 1, 2, 5
2025
-
[54]
Automated generation of virtual driving scenarios from test drive data
Robin Van Der Made, Martijn Tideman, Ulrich Lages, Roman Katz, and Martin Spencer. Automated generation of virtual driving scenarios from test drive data. In24th International Technical Conference on the Enhanced Safety of Vehicles (ESV) National Highway Traffic Safety Administration, 2015. 2
2015
-
[55]
Advsim: Generating safety-critical scenarios for self-driving vehicles
Jingkang Wang, Ava Pun, James Tu, Sivabalan Manivasagam, Abbas Sadat, Sergio Casas, Mengye Ren, and Raquel Urtasun. Advsim: Generating safety-critical scenarios for self-driving vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9909–9918,
-
[56]
Self-instruct: Aligning language models with self-generated instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023. 2
2023
-
[57]
Adversarial prefer- ence learning for robust LLM alignment
Yuanfu Wang, Pengyu Wang, Chenyang Xi, Bo Tang, Junyi Zhu, Wenqiang Wei, Chen Chen, Chao Yang, Jingfeng Zhang, Chaochao Lu, Yijun Niu, Keming Mao, Zhiyu Li, Feiyu Xiong, Jie Hu, and Mingchuan Yang. Adversarial prefer- ence learning for robust LLM alignment. InFindings of the Association for Computational Linguistics, ACL 2025, Vi- enna, Austria, July 27 -...
2025
-
[58]
Codeclm: Aligning language models with tailored synthetic data.arXiv preprint arXiv:2404.05875, 2024
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, and Tomas Pfister. Codeclm: Aligning language models with tailored synthetic data.arXiv preprint arXiv:2404.05875, 2024. 2
-
[59]
Chain-of- thought prompting elicits reasoning in large language mod- els.Advances in Neural Information Processing Systems, 35: 24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of- thought prompting elicits reasoning in large language mod- els.Advances in Neural Information Processing Systems, 35: 24824–24837, 2022. 3
2022
-
[60]
Selfcodealign: Self-alignment for code generation.Advances in Neural In- formation Processing Systems, 37:62787–62874, 2024
Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Zachary Mueller, Harm de Vries, Leandro V on Werra, Arjun Guha, and Lingming Zhang. Selfcodealign: Self-alignment for code generation.Advances in Neural In- formation Processing Systems, 37:62787–62874, 2024. 2
2024
-
[61]
Safebench: a benchmarking platform for safety evaluation of autonomous vehicles
Chejian Xu, Wenhao Ding, Weijie Lyu, Zuxin Liu, Shuai Wang, Yihan He, Hanjiang Hu, Ding Zhao, and Bo Li. Safebench: a benchmarking platform for safety evaluation of autonomous vehicles. InProceedings of the 36th Interna- tional Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2022. Curran Associates Inc. 1, 5, 6, 7
2022
-
[62]
Wizardlm: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 2
2024
-
[63]
An Yang, Anfeng Li, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Surfelgan: Synthesizing realistic sensor data for autonomous driving
Zhenpei Yang, Yuning Chai, Dragomir Anguelov, Yin Zhou, Pei Sun, Dumitru Erhan, Sean Rafferty, and Henrik Kret- zschmar. Surfelgan: Synthesizing realistic sensor data for autonomous driving. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR),
-
[65]
Youtube.https://www.youtube.com, 2025
YouTube. Youtube.https://www.youtube.com, 2025. 3
2025
-
[66]
Self- rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self- rewarding language models. InForty-first International Con- ference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. 2
2024
-
[67]
Chatscene: Knowledge- enabled safety-critical scenario generation for autonomous vehicles
Jiawei Zhang, Chejian Xu, and Bo Li. Chatscene: Knowledge- enabled safety-critical scenario generation for autonomous vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15459–15469, 2024. 1, 2, 5, 6, 7
2024
-
[68]
Cat: Closed-loop adversarial training for safe end-to-end driving
Linrui Zhang, Zhenghao Peng, Quanyi Li, and Bolei Zhou. Cat: Closed-loop adversarial training for safe end-to-end driving. InProceedings of The 7th Conference on Robot Learning, pages 2357–2372. PMLR, 2023. 2
2023
-
[69]
Qingzhao Zhang, Shengtuo Hu, Jiachen Sun, Qi Alfred Chen, and Z Morley Mao. On adversarial robustness of trajec- tory prediction for autonomous vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15159–15168, 2022. 1, 5, 6, 7 11 TrafficAlign: Aligning Large Language Models for Traffic Scenario Generation Su...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.