Flow Reasoning Models: Scaling Reasoning Through Iterative Self-Refinement
Pith reviewed 2026-06-30 07:53 UTC · model grok-4.3
The pith
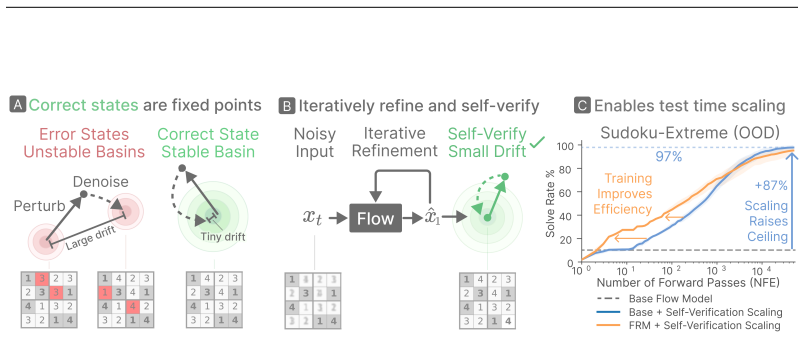
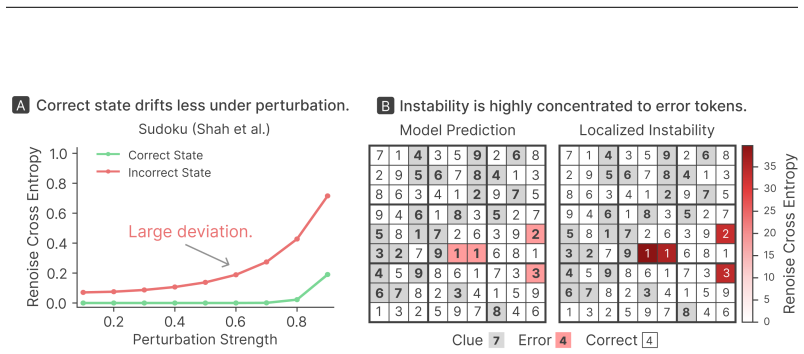
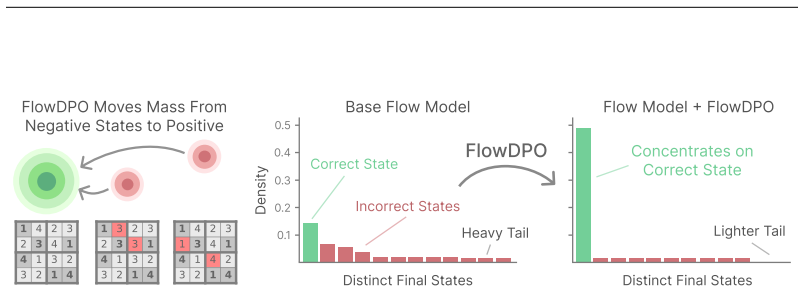
Correct answers are stable fixed points under discrete flow model denoising, so selecting only those that return to themselves after re-noising solves Sudoku and Zebra puzzles at 96-100%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
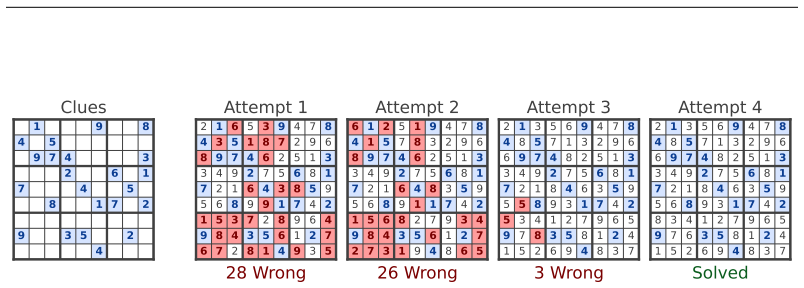
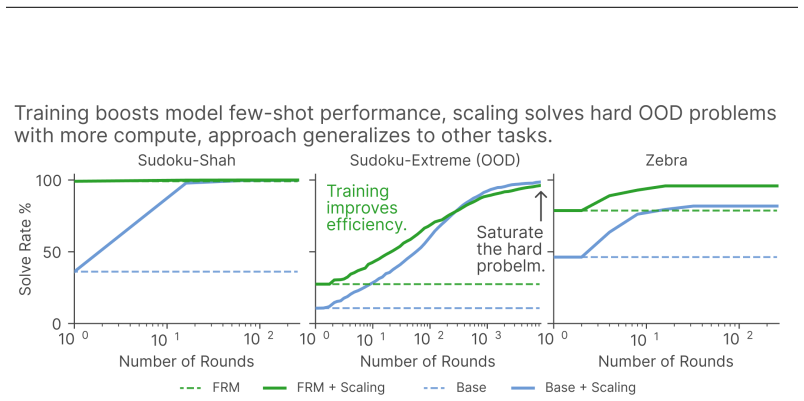
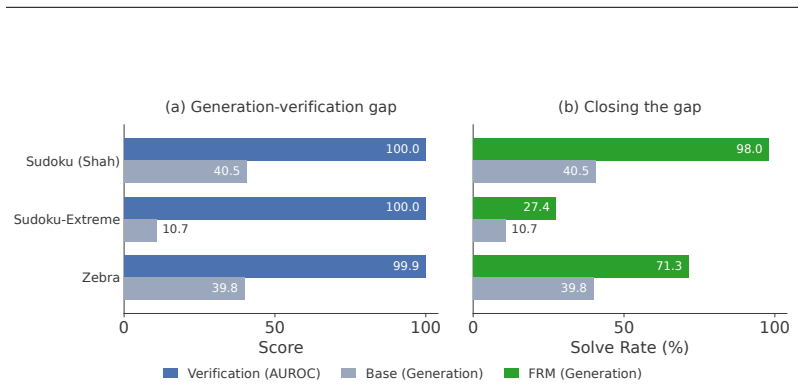
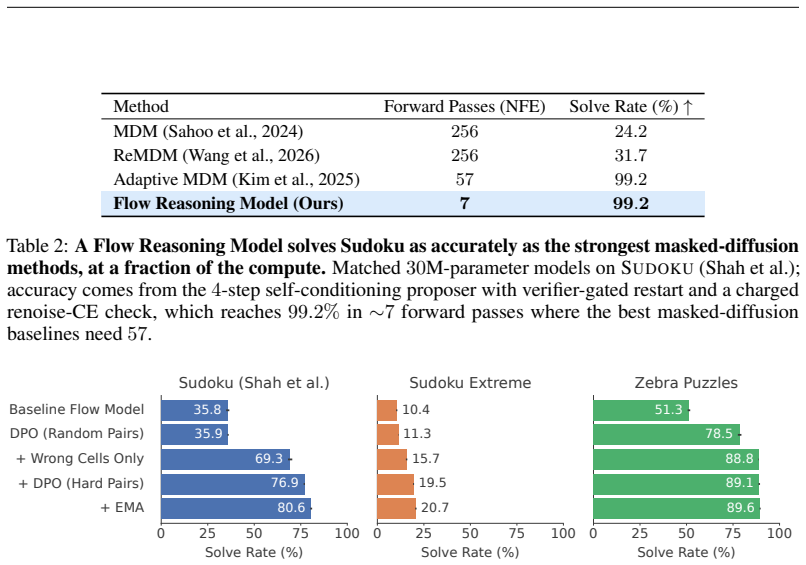
A correct answer is a stable fixed point of the denoising dynamics, returning to itself when re-noised and re-solved. Selecting such stable candidates alone reaches high solve rates on Sudoku-Shah (~100%) and Zebra (95.9%), and generalizes to Sudoku-Extreme (96.1%) without training on that distribution. Training flow models with a self-conditioning channel and direct preference optimization improves the base model's efficiency to reach 99.2% on Sudoku in just 7 forward passes.
What carries the argument
The stable fixed point property of correct solutions under repeated re-noising and re-solving in discrete flow model denoising dynamics, serving as an internal verification signal for candidate selection.
If this is right
- Selecting only dynamically stable candidates produces ~100% solve rate on Sudoku-Shah and 95.9% on Zebra without additional training.
- The same selection procedure generalizes to harder out-of-distribution puzzles such as Sudoku-Extreme at 96.1%.
- Closing a self-conditioning channel at inference lets the model iteratively refine its own earlier predictions.
- Direct preference optimization against the model's own failed generations reduces the number of forward passes needed for high accuracy.
- Combining the trained model with stability-based selection solves hard puzzles with far fewer total steps than pure search or matched baselines.
Where Pith is reading between the lines
- Stability selection could be layered on top of other search or sampling strategies to further cut the number of proposals examined.
- The fixed-point test might apply to any discrete structured generation task where repeated perturbation and regeneration is cheap.
- Preference optimization against self-generated errors could be extended to other signals such as partial correctness or step-wise consistency.
- If stability proves a general proxy for solution quality, it could reduce dependence on external verifiers or reward models in reasoning systems.
Load-bearing premise
That an answer remaining unchanged after re-noising and re-solving reliably signals correctness rather than merely correlating with correctness on the tested puzzle distributions.
What would settle it
A collection of puzzles in which many incorrect answers remain unchanged after re-noising and re-solving, or many correct answers change, would show that stability does not track correctness.
Figures
read the original abstract
Discrete flow models have recently shown promising performance on few-step text generation; however, when naively applied to structured reasoning tasks such as Sudoku and Zebra puzzles, they converge confidently to incorrect answers (solving only $\sim$36% of Sudoku puzzles). We introduce Flow Reasoning Models (FRMs), a training and test-time-scaling framework for structured reasoning with flow models. We make the observation that, despite their poor solve rate, flow models can act as their own verifiers. A correct answer is a stable fixed point of the denoising dynamics, returning to itself when re-noised and re-solved. This enables a test-time-scaling paradigm: propose many candidate solutions and keep those that are dynamically stable, which alone reaches high solve rates on Sudoku-Shah (~$100\%$) and Zebra ($95.9\%$). This even generalizes to harder out-of-distribution puzzles like Sudoku-Extreme ($96.1\%$), without ever training on that distribution. This pure search, however, wastes a great deal of computation generating incorrect candidate solutions. We therefore design a training recipe to improve the base model's efficiency. First, we train flow models with a self-conditioning channel and close it at inference, letting them refine their own past predictions. Second, we train models to avoid their own failed generations using direct preference optimization. These changes substantially improve the base model's efficiency, letting it reach $99.2\%$ on Sudoku in just $7$ forward passes, over $8\times$ fewer than the strongest matched masked-diffusion baseline we compare needs for the same accuracy. When combined with test-time scaling, this lets flow models solve hard out-of-distribution puzzles (e.g. Sudoku-Extreme) far more efficiently.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Flow Reasoning Models (FRMs) as a training and test-time scaling framework for discrete flow models on structured reasoning tasks such as Sudoku and Zebra puzzles. It observes that correct answers form stable fixed points under the model's denoising dynamics (returning to themselves after re-noising and re-solving), enabling a pure search method that filters many candidate solutions to reach ~100% on Sudoku-Shah, 95.9% on Zebra, and 96.1% on OOD Sudoku-Extreme. It further proposes self-conditioning during training (closed at inference) and direct preference optimization to avoid failed generations, yielding efficiency gains such as 99.2% Sudoku accuracy in 7 forward passes (over 8x fewer than a matched masked-diffusion baseline).
Significance. If the stability-based filtering and efficiency improvements hold under broader conditions, the work provides a label-free test-time scaling approach for flow models on reasoning and demonstrates concrete efficiency advantages over baselines. The OOD generalization result is notable as an empirical measurement on held-out puzzles rather than a self-referential fit, and the absence of free parameters or invented entities in the core observation strengthens the claim.
major comments (3)
- [Abstract] Abstract, fixed-point observation paragraph: the central claim that selecting dynamically stable candidates identifies correct answers (enabling the reported ~100% and 95.9% solve rates) rests on the untested assumption that incorrect answers cannot also be stable fixed points of the same denoising dynamics; no experiments on false-positive rates or adversarial candidates are described, which is load-bearing for interpreting the filter as a correctness proxy rather than a distribution-specific correlate.
- [Abstract] Abstract, results on Sudoku-Extreme: the 96.1% OOD generalization is reported without error bars, variance across runs, or exact details on the candidate selection procedure (e.g., number of proposals, stability threshold, or re-noising schedule), undermining assessment of robustness to distribution shift as flagged in the soundness evaluation.
- [Abstract] Abstract, efficiency comparison: the claim of reaching 99.2% accuracy in 7 forward passes (over 8x fewer than the strongest matched masked-diffusion baseline) lacks specification of the baseline's exact configuration and whether the comparison controls for total compute or proposal count, which is load-bearing for the training-recipe contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract, fixed-point observation paragraph: the central claim that selecting dynamically stable candidates identifies correct answers (enabling the reported ~100% and 95.9% solve rates) rests on the untested assumption that incorrect answers cannot also be stable fixed points of the same denoising dynamics; no experiments on false-positive rates or adversarial candidates are described, which is load-bearing for interpreting the filter as a correctness proxy rather than a distribution-specific correlate.
Authors: We agree that the manuscript does not include explicit experiments on false-positive rates for the stability filter or tests with adversarial candidates. The reported accuracies are empirical observations on the Sudoku and Zebra distributions (including OOD). We will add an explicit discussion of this limitation in the revised manuscript, including any feasible additional analysis of false positives. revision: yes
-
Referee: [Abstract] Abstract, results on Sudoku-Extreme: the 96.1% OOD generalization is reported without error bars, variance across runs, or exact details on the candidate selection procedure (e.g., number of proposals, stability threshold, or re-noising schedule), undermining assessment of robustness to distribution shift as flagged in the soundness evaluation.
Authors: We will revise the abstract and methods to report error bars, variance across runs, and full details of the candidate selection procedure, including the number of proposals, stability threshold, and re-noising schedule. revision: yes
-
Referee: [Abstract] Abstract, efficiency comparison: the claim of reaching 99.2% accuracy in 7 forward passes (over 8x fewer than the strongest matched masked-diffusion baseline) lacks specification of the baseline's exact configuration and whether the comparison controls for total compute or proposal count, which is load-bearing for the training-recipe contribution.
Authors: We will update the abstract and relevant sections to specify the exact configuration of the masked-diffusion baseline and confirm that the comparison controls for total compute and proposal count. revision: yes
Circularity Check
No circularity: core results are empirical measurements on held-out instances
full rationale
The paper reports measured solve rates (e.g., ~100% on Sudoku-Shah, 95.9% on Zebra, 96.1% on Sudoku-Extreme) obtained by filtering candidates according to an observed dynamical property. The stability observation is presented as an empirical finding rather than a derived theorem, and the reported accuracies are direct counts on test puzzles, not quantities obtained by fitting parameters inside the method's own equations and then relabeling them as predictions. Training steps (self-conditioning channel, DPO) are standard preference and conditioning techniques whose efficiency gains are likewise measured empirically. No load-bearing self-citation chain or self-definitional reduction is visible in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Discrete flow models can be trained to produce structured outputs on grid puzzles
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
URLhttps://arxiv.org/abs/2303.08797. Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. Deep equilibrium models. InAdvances in Neural Information Processing Systems, volume 32,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://arxiv.org/abs/2402.18491. Nicholas M. Boffi, Michael S. Albergo, and Eric Vanden-Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models,
-
[3]
URL https://arxiv. org/abs/2406.07507. Umberto Borso, Davide Paglieri, Jude Wells, and Tim Rocktäschel. Preference-based alignment of discrete diffusion models,
-
[4]
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton
URLhttps://arxiv.org/abs/2503.08295. Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning,
-
[5]
Yuxin Chen, Chumeng Liang, Hangke Sui, Ruihan Guo, Chaoran Cheng, Jiaxuan You, and Ge Liu
URLhttps://arxiv.org/abs/2208.04202. Yuxin Chen, Chumeng Liang, Hangke Sui, Ruihan Guo, Chaoran Cheng, Jiaxuan You, and Ge Liu. Langflow: Continuous diffusion rivals discrete in language modeling,
-
[6]
URL https:// arxiv.org/abs/2604.11748. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Training Verifiers to Solve Math Word Problems
URL https://arxiv.org/ abs/2110.14168. Jacob Fein-Ashley and Paria Rashidinejad. Solve the loop: Attractor models for language and reasoning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Solve the Loop: Attractor Models for Language and Reasoning
URLhttps://arxiv.org/abs/2605.12466. Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
URLhttps://arxiv.org/abs/2502.05171. Keya Hu, Linlu Qiu, Yiyang Lu, Hanhong Zhao, Tianhong Li, Yoon Kim, Jacob Andreas, and Kaiming He. Elf: Embedded language flows,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://arxiv.org/abs/2605.10938. Zhewei Kang, Xuandong Zhao, and Dawn Song. Scalable best-of-n selection for large language models via self-certainty,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
12 Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen
URLhttps://arxiv.org/abs/2502.18581. 12 Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the worst, plan for the best: Understanding token ordering in masked diffusions,
-
[12]
URL https: //arxiv.org/abs/2502.06768. Jaeyeon Kim, Seunggeun Kim, Taekyun Lee, David Z. Pan, Hyeji Kim, Sham Kakade, and Sitan Chen. Fine-tuning masked diffusion for provable self-correction,
-
[13]
Fine-Tuning Masked Diffusion for Provable Self-Correction
URL https://arxiv. org/abs/2510.01384. Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, and Jiaya Jia. Step-dpo: Step- wise preference optimization for long-chain reasoning of llms,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
URL https://arxiv.org/ abs/2406.18629. Chanhyuk Lee, Jaehoon Yoo, Manan Agarwal, Sheel Shah, Jerry Huang, Aditi Raghunathan, Se- unghoon Hong, Nicholas M. Boffi, and Jinwoo Kim. Flow map language models: One-step lan- guage modeling via continuous denoising,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Flow Map Language Models: One-step Language Modeling via Continuous Denoising
URL https://arxiv.org/abs/2602.16813. Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https://arxiv.org/abs/2305.20050. Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Flow Matching for Generative Modeling
URLhttps://arxiv.org/abs/2210.02747. Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
URLhttps://arxiv.org/abs/2310.16834. Sajad Movahedi, Vera Milovanovi ´c, Shlomo Libo Feigin, Alexander Theus, Thomas Hofmann, Valentina Boeva, T. Konstantin Rusch, and Antonio Orvieto. Fixed-point reasoners: Stable and adaptive deep looped transformers,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Fixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
URLhttps://arxiv.org/abs/2606.18206. Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Large Language Diffusion Models
URL https://arxiv. org/abs/2502.09992. Zhengkai Pan, Peter Potaptchik, Wenxi Yao, Michael S. Albergo, and Jakiw Pidstrigach. Itô maps for any-step sdes,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URLhttps://arxiv.org/abs/2606.11156. Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, and Jason Weston. Iterative reasoning preference optimization,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Bao Pham, Gabriel Raya, Matteo Negri, Mohammed J
URL https://arxiv.org/abs/ 2404.19733. Bao Pham, Gabriel Raya, Matteo Negri, Mohammed J. Zaki, Luca Ambrogioni, and Dmitry Krotov. Memorization to generalization: Emergence of diffusion models from associative memory,
-
[23]
Peter Potaptchik, Jason Yim, Adhi Saravanan, Peter Holderrieth, Eric Vanden-Eijnden, and Michael S
URLhttps://arxiv.org/abs/2505.21777. Peter Potaptchik, Jason Yim, Adhi Saravanan, Peter Holderrieth, Eric Vanden-Eijnden, and Michael S. Albergo. Discrete flow maps,
-
[24]
URLhttps://arxiv.org/abs/2604.09784. Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
URL https://arxiv.org/abs/2305.18290. Jiaoyang Ruan, Xin Gao, Yinda Chen, Hengyu Zeng, Liang Du, Guanghao Li, Jie Fu, and Jian Pu. Reasoning on the manifold: Bidirectional consistency for self-verification in diffusion language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
URLhttps://arxiv.org/abs/2604.16565. Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Chiu, Alexander Rush, and Volodymyr Kuleshov
URLhttps://arxiv.org/abs/2406.07524. Kulin Shah, Nishanth Dikkala, Xin Wang, and Rina Panigrahy. Causal language modeling can elicit search and reasoning capabilities on logic puzzles,
-
[28]
Cyclic Denoising Reveals Ultrastable Memories in Diffusion Models
URLhttps://arxiv.org/abs/2606.24000. Fahim Tajwar, Anikait Singh, Archit Sharma, Rafael Rafailov, Jeff Schneider, Tengyang Xie, Stefano Ermon, Chelsea Finn, and Aviral Kumar. Preference fine-tuning of llms should leverage suboptimal, on-policy data,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
URLhttps://arxiv.org/abs/2404.14367. Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization,
-
[30]
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov
URLhttps://arxiv.org/abs/2311.12908. Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling,
-
[31]
URLhttps://arxiv.org/abs/2404.11999. Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Llada 1.5: Variance-reduced preference optimization for large language diffusion models,
-
[32]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
URLhttps://arxiv.org/abs/2505.19223. A SELF-CONDITIONING:TRAINING,REPRESENTATION,AND STABILITY This appendix collects the self-conditioning details deferred from Section 2.1. The channel and its training.Self-conditioning adds a singlezero-initializedinput channel that carries the model’s own previous-pass raw logitss=ℓ prev, embedded and added to the sta...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
D RENOISE-CESELECTION AFTERFLOWDPO Table 4 shows the vote-versus-renoise-CE contrast for thebasemodel
The renoise-CE again selects the correct grid almost always while the vote lags.n=128puzzles. D RENOISE-CESELECTION AFTERFLOWDPO Table 4 shows the vote-versus-renoise-CE contrast for thebasemodel. Table 5 repeats the measure- ment for the FLOWDPO model, each evaluated at itsown(smaller) saturation pool N ∗: the same contrast holds, in that the renoise-CE ...
2025
-
[34]
The preference loss and the denoising log-score.FLOWDPO is the direct preference loss (Rafailov et al., 2024), a logistic contrast on pairs (y+, y−) over the denoising log-score ratio to a reference model, LDPO(θ) =−E (y+,y−) logσ β log πθ(y+) πθref (y+) −log πθ(y−) πθref (y−) ,(11) with the logπ slot instantiated by the train-matched categorical denoisin...
2024
-
[35]
The default mask is the answer-position maskM
and no absorbing-state ELBO reweighting as in masked-diffusion preference methods (Zhu et al., 2025; Borso et al., 2025). The default mask is the answer-position maskM. In the wrong-cells objective used for the reported ablations, we swap in the gold-supervised mask Wi =M i1[y − i ̸=y + i ], corrupt the mined negative to x− t :=x t(y−;ε) with clue cells c...
2025
-
[36]
restricted to the decisive cells W . The (1−σ(β b∆t,ε)) prefactor gates the update by hardness, vanishing for negatives the model already deems unlikely and largest for the self-mined confident mistakes it ranks near gold (Section 3). Total objective and the optional anchor.Writing LFlowDPO for the averaged multi-negative contrast of Eq. (14), the full ob...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.