Robust Zero-shot Anomaly Detection under Limited Auxiliary Anomaly Priors
Pith reviewed 2026-06-30 07:52 UTC · model grok-4.3
The pith
DIVE learns generic anomaly concepts from limited auxiliary priors via text embedding injection and disentanglement to enable zero-shot detection in novel domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
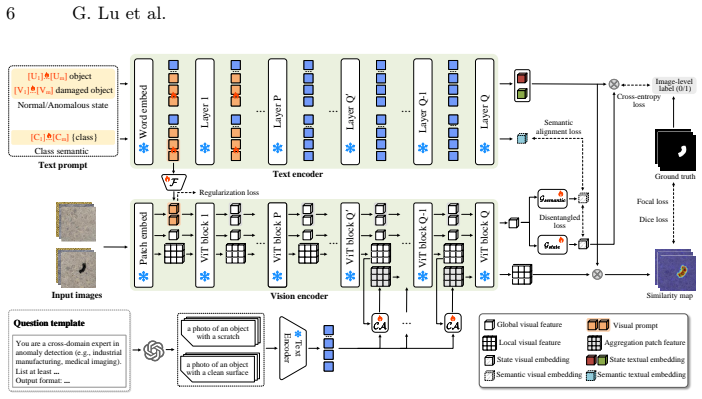
Under the setting of limited anomaly patterns in auxiliary data, DIVE abstracts generic anomaly concepts shared across the auxiliary training domain and diverse target domains through a shallow-and-deep text embedding injection strategy during visual encoding and a disentanglement mechanism that resolves suboptimal alignment between visual embeddings entangled with object semantics and object-agnostic textual prompts.
What carries the argument
Shallow-and-deep text embedding injection strategy paired with a disentanglement mechanism that separates object semantics from anomaly cues.
If this is right
- DIVE raises average classification performance by up to 16.2 percent and 28.5 percent across twelve datasets when auxiliary anomaly patterns are restricted.
- It raises average segmentation performance by up to 23.4 percent, 24.1 percent, and 47.0 percent on the same datasets under the limited-prior regime.
- Performance remains competitive with existing methods once auxiliary data regains full anomaly diversity.
- The approach directly targets the performance collapse that occurs when auxiliary collections fail to cover the unpredictable variations found in real target domains.
Where Pith is reading between the lines
- The same injection-plus-disentanglement pattern may extend to other zero-shot visual tasks that suffer from sparse auxiliary exemplars.
- Success hinges on the textual prompts remaining sufficiently object-agnostic; stronger object-specific prompts would likely weaken the transfer.
- If the disentanglement step is removed, alignment between visual features and anomaly descriptions would be expected to degrade on domains whose objects differ markedly from the auxiliary set.
Load-bearing premise
The shallow-and-deep text embedding injection strategy combined with the disentanglement mechanism successfully abstracts generic anomaly concepts that transfer from the limited-prior auxiliary domain to diverse target domains.
What would settle it
On a held-out target domain containing anomaly types absent from the limited auxiliary set, the method produces no measurable lift in either classification or segmentation metrics relative to baselines that lack the injection and disentanglement steps.
Figures

read the original abstract
Zero-shot anomaly detection aims to identify defects in arbitrary novel domains; however, existing models assume that the auxiliary data contains a rich diversity of anomalies, neglecting the far more complex and unpredictable variations in real-world target domains. This study introduces DIVE, the first approach to investigate the scenario of limited auxiliary anomaly priors and resolve the resulting substantial performance degradation. Through a shallow-and-deep text embedding injection strategy during visual encoding, DIVE learns to abstract generic anomaly concepts shared across the auxiliary training domain and diverse target domains. Moreover, we propose a disentanglement mechanism to tackle the suboptimal alignment between visual embeddings entangled with object semantics and object-agnostic textual prompts. Experiments demonstrate that, under the setting of limited anomaly patterns in auxiliary data, DIVE outperforms SOTA baselines by up to 16.2% and 28.5% on two classification metrics, and 23.4%, 24.1%, and 47.0% on three segmentation metrics, in terms of average performance across twelve datasets. Furthermore, it maintains highly competitive performance when auxiliary data exhibits sufficient anomaly diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DIVE for zero-shot anomaly detection under limited auxiliary anomaly priors. It employs a shallow-and-deep text embedding injection strategy in visual encoding to abstract generic anomaly concepts transferable across domains, paired with a disentanglement mechanism to improve alignment between visual embeddings and object-agnostic textual prompts. Under limited anomaly patterns, it reports average gains of up to 16.2% and 28.5% on two classification metrics and 23.4%, 24.1%, and 47.0% on three segmentation metrics across twelve datasets, while remaining competitive when auxiliary data has sufficient diversity.
Significance. If the claimed gains hold under rigorous validation, the work targets a realistic and underexplored limitation in zero-shot anomaly detection—performance degradation from sparse auxiliary anomaly patterns—potentially improving applicability to real-world target domains with unpredictable variations.
minor comments (1)
- The abstract states quantitative improvements but provides no method equations, ablation details, or statistical significance tests; these should be added in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for reviewing our manuscript on DIVE for robust zero-shot anomaly detection under limited auxiliary anomaly priors. The report provides a concise summary and notes the potential significance but lists no specific major comments requiring point-by-point rebuttal. We remain available to supply further experimental details or clarifications should any concerns arise regarding validation of the reported gains.
Circularity Check
No significant circularity
full rationale
The abstract and supplied context contain no equations, derivations, or first-principles claims. The paper describes an empirical method (shallow-and-deep text embedding injection plus disentanglement) and reports metric improvements on twelve datasets; no self-definitional construction, fitted-input prediction, or load-bearing self-citation chain is visible that would reduce any claimed result to its own inputs by construction. The derivation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: WACV
Aota, T., Tong, L.T.T., Okatani, T.: Zero-shot versus many-shot: Unsupervised texture anomaly detection. In: WACV. pp. 5564–5572 (2023)
2023
-
[2]
In: CVPR
Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. In: CVPR. pp. 9592–9600 (2019)
2019
-
[3]
In: CVPR
Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In: CVPR. pp. 4183–4192 (2020) 16 G. Lu et al
2020
-
[4]
In: MICCAI
Cai, Y., Chen, H., Cheng, K.T.: Rethinking autoencoders for medical anomaly detection from a theoretical perspective. In: MICCAI. pp. 544–554 (2024)
2024
-
[5]
A survey on visual anomaly detection: Challenge, approach, and prospect,
Cao, Y., Xu, X., Zhang, J., Cheng, Y., Huang, X., Pang, G., Shen, W.: A survey on visual anomaly detection: Challenge, approach, and prospect. arXiv preprint arXiv:2401.16402 (2024)
-
[6]
In: ECCV
Cao, Y., Zhang, J., Frittoli, L., Cheng, Y., Shen, W., Boracchi, G.: Adaclip: Adapt- ing clip with hybrid learnable prompts for zero-shot anomaly detection. In: ECCV. pp. 55–72 (2024)
2024
-
[7]
In: ICLR (2023)
Chen, G., Yao, W., Song, X., Li, X., Rao, Y., Zhang, K.: Plot: Prompt learning with optimal transport for vision-language models. In: ICLR (2023)
2023
-
[8]
arXiv preprint arXiv:2305.17382 (2023)
Chen, X., Han, Y., Zhang, J.: A zero-/few-shot anomaly classification and segmen- tation method for cvpr 2023 vand workshop challenge tracks 1&2: 1st place on zero-shot ad and 4th place on few-shot ad. arXiv preprint arXiv:2305.17382 (2023)
-
[9]
arXiv preprint arXiv:2308.15939 (2023)
Deng, H., Zhang, Z., Bao, J., Li, X.: Anovl: Adapting vision-language models for unified zero-shot anomaly localization. arXiv preprint arXiv:2308.15939 (2023)
-
[10]
In: ACM MM
Fang, Q., Lv, W., Su, Q.: Af-clip: Zero-shot anomaly detection via anomaly-focused clip adaptation. In: ACM MM. pp. 4846–4855 (2025)
2025
-
[11]
In: ISBI
Gong, H., Chen, G., Wang, R., Xie, X., Mao, M., Yu, Y., Chen, F., Li, G.: Multi- task learning for thyroid nodule segmentation with thyroid region prior. In: ISBI. pp. 257–261 (2021)
2021
-
[12]
In: ICCV
Gong, T., Chu, Q., Liu, B., Zhou, W., Yu, N.: Fe-clip: Frequency enhanced clip model for zero-shot anomaly detection and segmentation. In: ICCV. pp. 21220– 21230 (2025)
2025
-
[13]
In: AAAI
Gu, Z., Zhu, B., Zhu, G., Chen, Y., Tang, M., Wang, J.: Anomalygpt: Detecting industrial anomalies using large vision-language models. In: AAAI. vol. 38, pp. 1932–1940 (2024)
1932
-
[14]
In: CVPR
Guo, J., Lu, S., Zhang, W., Chen, F., Li, H., Liao, H.: Dinomaly: The less is more philosophy in multi-class unsupervised anomaly detection. In: CVPR. pp. 20405–20415 (2025)
2025
-
[15]
Gutman, D., Codella, N.C., Celebi, E., Helba, B., Marchetti, M., Mishra, N., Halpern, A.: Skin lesion analysis toward melanoma detection: A challenge at the international symposium on biomedical imaging (isbi) 2016, hosted by the inter- national skin imaging collaboration (isic). arXiv preprint arXiv:1605.01397 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
Hamada, A.: Br35h: Brain tumor detection 2020.https://www.kaggle.com/ datasets/ahmedhamada0/brain-tumor-detection(2020), kaggle dataset
2020
-
[17]
In: ICCV
He,J.,Cao,M.,Peng,S.,Xie,Q.:Rareclip:Rarity-awareonlinezero-shotindustrial anomaly detection. In: ICCV. pp. 24478–24487 (2025)
2025
-
[18]
In: CVPR
Ho, C.H., Peng, K.C., Vasconcelos, N.: Long-tailed anomaly detection with learn- able class names. In: CVPR. pp. 12435–12446 (2024)
2024
-
[19]
In: CVPR
Jeong, J., Zou, Y., Kim, T., Zhang, D., Ravichandran, A., Dabeer, O.: Winclip: Zero-/few-shot anomaly classification and segmentation. In: CVPR. pp. 19606– 19616 (2023)
2023
-
[20]
In: ICUMT
Jezek, S., Jonak, M., Burget, R., Dvorak, P., Skotak, M.: Deep learning-based defect detection of metal parts: evaluating current methods in complex conditions. In: ICUMT. pp. 66–71 (2021)
2021
-
[21]
In: SIGKDD
Jiang, M., Han, S., Huang, H.: Anomaly detection with score distribution discrim- ination. In: SIGKDD. pp. 984–996 (2023)
2023
-
[22]
In: CVPR
Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S.: Maple: Multi-modal prompt learning. In: CVPR. pp. 19113–19122 (2023) DIVE 17
2023
-
[23]
In: CVPR
Li, X., Zhang, Z., Tan, X., Chen, C., Qu, Y., Xie, Y., Ma, L.: Promptad: Learning prompts with only normal samples for few-shot anomaly detection. In: CVPR. pp. 16838–16848 (2024)
2024
-
[24]
Li, X., Sun, X., Meng, Y., Liang, J., Wu, F., Li, J.: Dice loss for data-imbalanced nlp tasks. In: ACL. pp. 465–476 (2020)
2020
-
[25]
Li, Z., Yan, Y., Wang, X., Ge, Y., Meng, L.: A survey of deep learning for industrial visual anomaly detection. Artif. Intell. Rev.58(9), 279 (2025)
2025
-
[26]
In: ICCV
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: ICCV. pp. 2980–2988 (2017)
2017
-
[27]
In: IEEE BigData
Lu, G., Lin, X., Pavlovski, M., Zhang, X., Zhou, F.: Targeted detection of anoma- lous merchants on integrated payment platforms via multifaceted transaction rep- resentation learning. In: IEEE BigData. pp. 2170–2178 (2024)
2024
-
[28]
In: ICDE
Lu, G., Zhou, F., Pavlovski, M., Zhou, C., Jin, C.: A robust prioritized anomaly detection when not all anomalies are of primary interest. In: ICDE. pp. 775–788 (2024)
2024
-
[29]
In: CVPR
Lu, Y., Liu, J., Zhang, Y., Liu, Y., Tian, X.: Prompt distribution learning. In: CVPR. pp. 5206–5215 (2022)
2022
-
[30]
In: AAAI
Ma, J., Xie, W., Ye, H., Li, D., Fang, L.: Aligning and prompting anything for zero-shot generalized anomaly detection. In: AAAI. vol. 39, pp. 5964–5972 (2025)
2025
-
[31]
In: CVPR
Ma, W., Zhang, X., Yao, Q., Tang, F., Wu, C., Li, Y., Yan, R., Jiang, Z., Zhou, S.K.: Aa-clip: Enhancing zero-shot anomaly detection via anomaly-aware clip. In: CVPR. pp. 4744–4754 (2025)
2025
-
[32]
In: ISIE
Mishra, P., Verk, R., Fornasier, D., Piciarelli, C., Foresti, G.L.: Vt-adl: A vision transformer network for image anomaly detection and localization. In: ISIE. pp. 01–06 (2021)
2021
-
[33]
In: ICML
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML. pp. 8748–8763 (2021)
2021
-
[34]
In: CVPR
Salehi, M., Sadjadi, N., Baselizadeh, S., Rohban, M.H., Rabiee, H.R.: Multireso- lution knowledge distillation for anomaly detection. In: CVPR. pp. 14902–14912 (2021)
2021
-
[35]
In: SIGKDD
Shou, H., Lu, G., Pavlovski, M., Zhou, F.: Read: Robust and efficient anomaly detection under data contamination and limited supervision. In: SIGKDD. pp. 2586–2596 (2025)
2025
-
[36]
Tabernik, D., Šela, S., Skvarč, J., Skočaj, D.: Segmentation-based deep-learning approach for surface-defect detection. J. Intell. Manuf.31(3), 759–776 (2020)
2020
-
[37]
IEEE Trans
Tajbakhsh, N., Gurudu, S.R., Liang, J.: Automated polyp detection in colonoscopy videos using shape and context information. IEEE Trans. Med. Imaging35(2), 630–644 (2015)
2015
-
[38]
In: CIKM
Wei,R.,He,Z.,Pavlovski,M.,Zhou,F.:Gad:Ageneralizedframeworkforanomaly detection at different risk levels. In: CIKM. pp. 2513–2522 (2024)
2024
-
[39]
IEEE Trans
Xu, H., Pang, G., Wang, Y., Wang, Y.: Deep isolation forest for anomaly detection. IEEE Trans. Knowl. Data Eng.35(12), 12591–12604 (2023)
2023
-
[40]
In: ICML
Xu, H., Wang, Y., Wei, J., Jian, S., Li, Y., Liu, N.: Fascinating supervisory signals and where to find them: Deep anomaly detection with scale learning. In: ICML. pp. 38655–38673 (2023)
2023
-
[41]
In: CVPR
Yao, H., Zhang, R., Xu, C.: Visual-language prompt tuning with knowledge-guided context optimization. In: CVPR. pp. 6757–6767 (2023)
2023
-
[42]
In: IJCAI
Zhang, J., He, H., Chen, X., Xue, Z., Wang, Y., Wang, C., Xie, L., Liu, Y.: Gpt- 4v-ad: Exploring grounding potential of vqa-oriented gpt-4v for zero-shot anomaly detection. In: IJCAI. pp. 3–16 (2024) 18 G. Lu et al
2024
-
[43]
In: MICCAI
Zhang, X., Xu, M., Qiu, D., Yan, R., Lang, N., Zhou, X.: Mediclip: Adapting clip for few-shot medical image anomaly detection. In: MICCAI. pp. 458–468 (2024)
2024
-
[44]
In: CVPR
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Conditional prompt learning for vision- language models. In: CVPR. pp. 16816–16825 (2022)
2022
-
[45]
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. Int. J. Comput. Vis.130(9), 2337–2348 (2022)
2022
-
[46]
In: ICLR (2024)
Zhou, Q., Pang, G., Tian, Y., He, S., Chen, J.: Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection. In: ICLR (2024)
2024
-
[47]
IEEE Trans
Zhou, Y., Xu, X., Song, J., Shen, F., Shen, H.T.: Msflow: Multiscale flow-based framework for unsupervised anomaly detection. IEEE Trans. Neural Netw. Learn. Syst. (2024)
2024
-
[48]
In: ICCV
Zhu, J., Ong, Y.S., Shen, C., Pang, G.: Fine-grained abnormality prompt learning for zero-shot anomaly detection. In: ICCV. pp. 22241–22251 (2025)
2025
-
[49]
In: CVPR
Zhu, J., Pang, G.: Toward generalist anomaly detection via in-context residual learning with few-shot sample prompts. In: CVPR. pp. 17826–17836 (2024)
2024
-
[50]
Abnormal Lexicon
Zou, Y., Jeong, J., Pemula, L., Zhang, D., Dabeer, O.: Spot-the-difference self- supervised pre-training for anomaly detection and segmentation. In: ECCV. pp. 392–408 (2022) DIVE 19 A Appendix A.1 Prompt Template for Generating Descriptions of Normality and Abnormality As detailed in the main manuscript, DIVE utilizes a deep-level text embedding injection...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.