Structured Proper Loss Geometries for Multiclass Classification: Theory and Controlled Empirical Evaluation
Pith reviewed 2026-06-30 07:48 UTC · model grok-4.3
The pith
Structured proper losses for multiclass classification yield explicit bounds but show no general superiority over cross-entropy
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The mathematical analysis establishes the stated properties for CAPM, HPG, and APMS, and the experiments delimit the empirical evidence; together they do not support a claim of general superiority.
What carries the argument
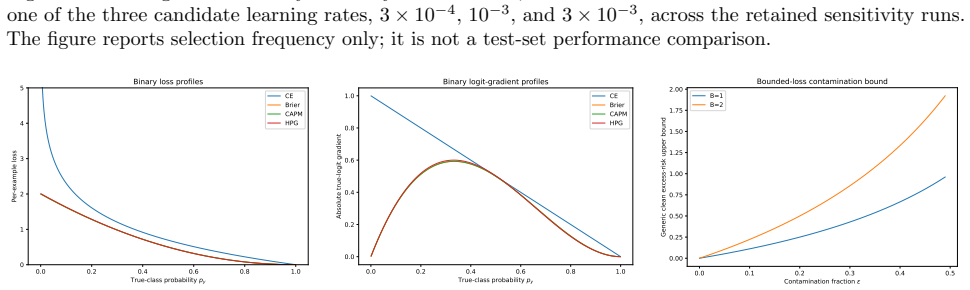
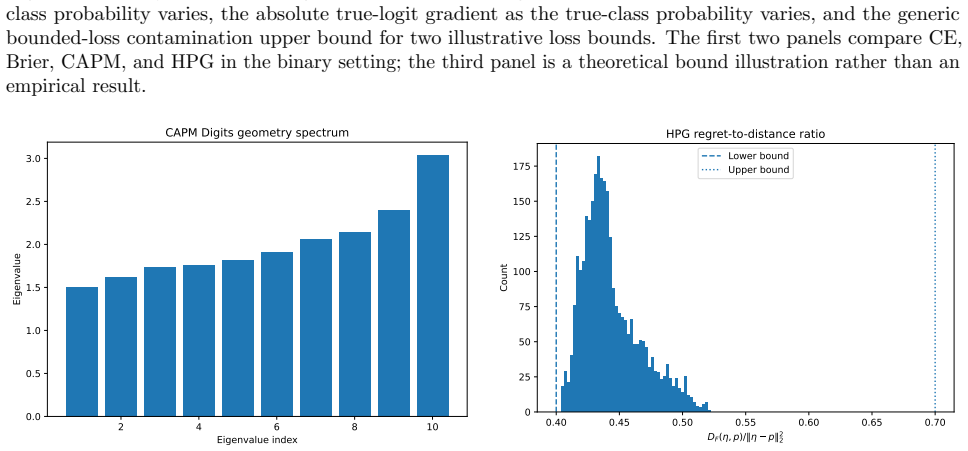
The three structured proper loss geometries (CAPM as class-aware quadratic Bregman score, HPG as strongly convex generator with constrained log-cosh ridges, APMS as HPG with annealed probability-margin penalty)
If this is right
- The bounds on conditional regret, curvature, range, and logit gradients hold for the population-level conditional distributions of the three objectives.
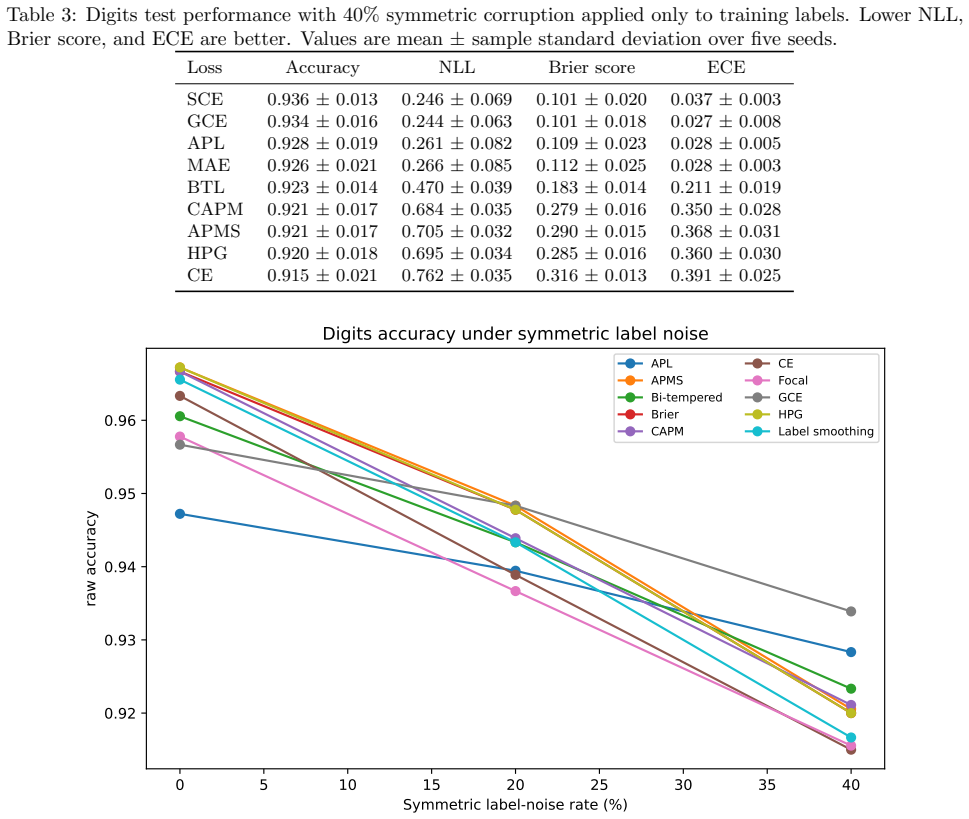
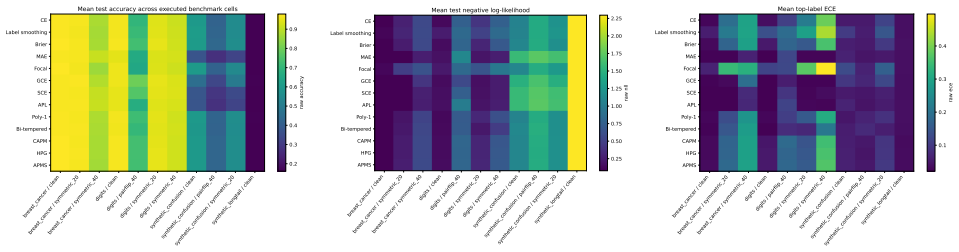
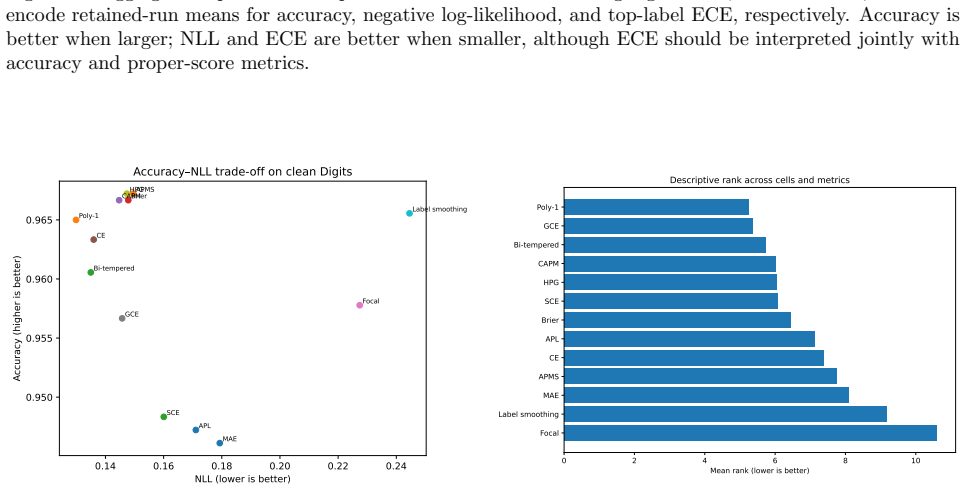
- Performance of the candidates remains close to cross-entropy on clean-label versions of the tested datasets.
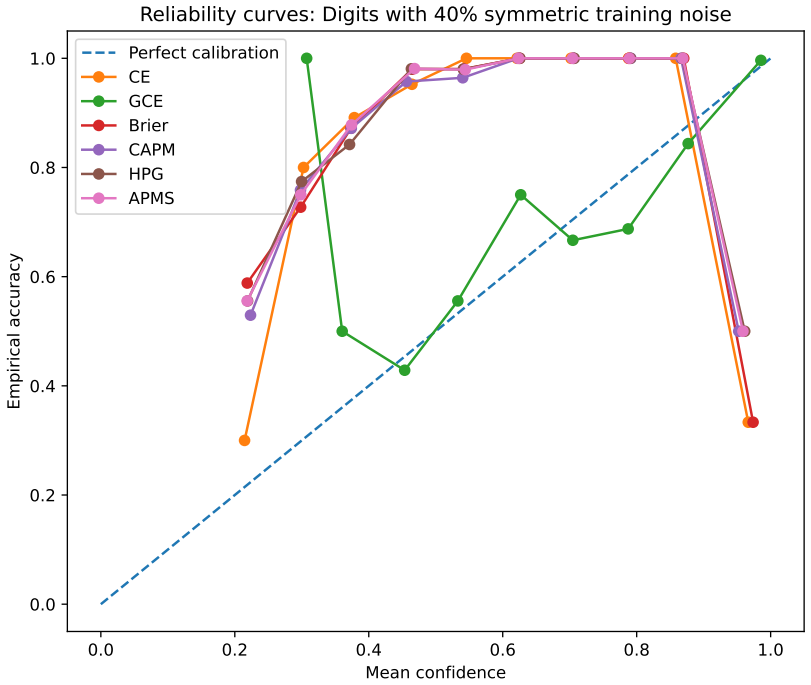
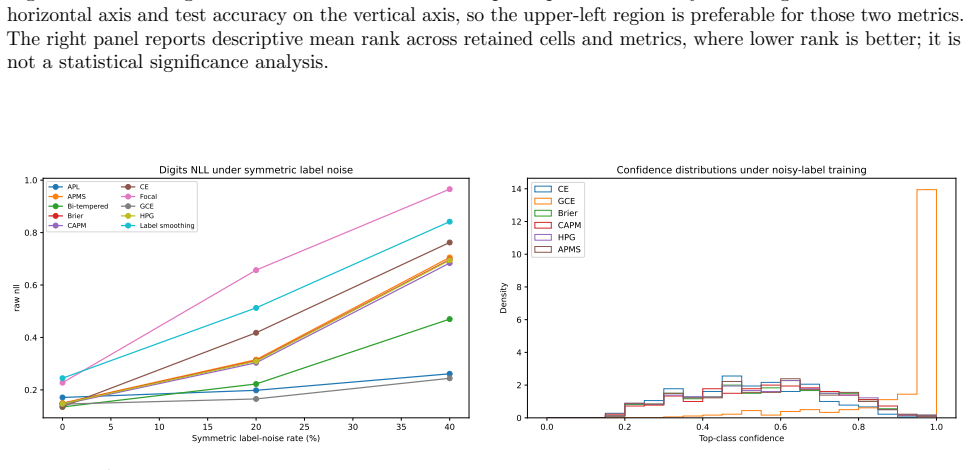
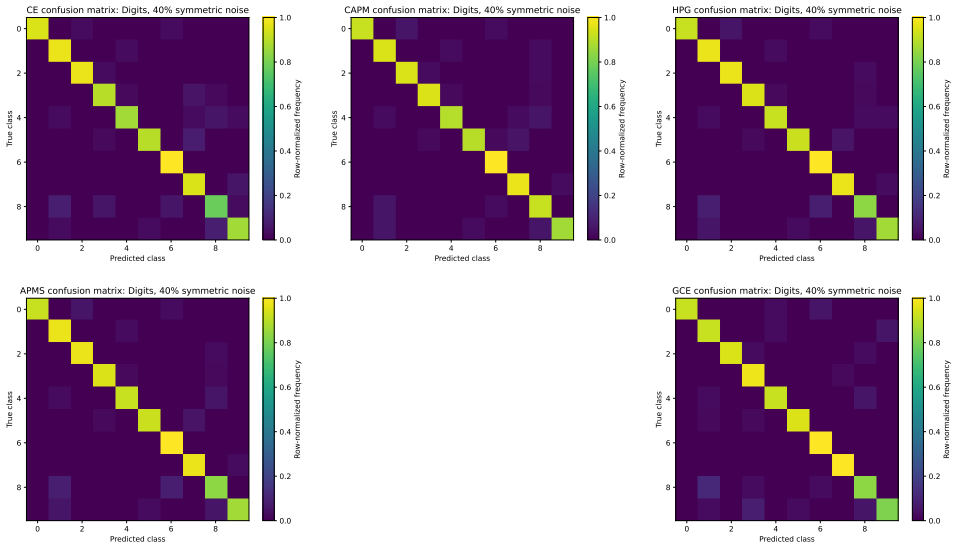
- Descriptive gains appear in some cells with symmetric label noise on the Digits dataset.
- Ablations indicate no consistent benefit from the candidate-specific graph, ridge, or margin components.
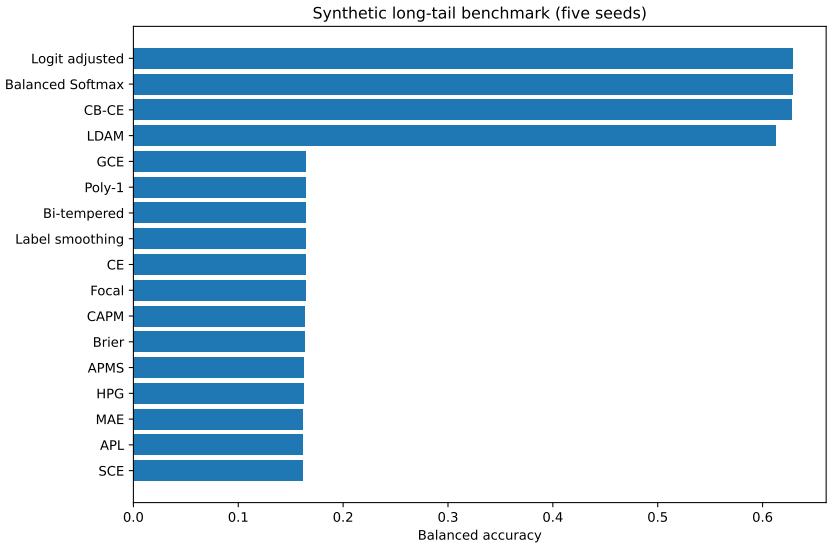
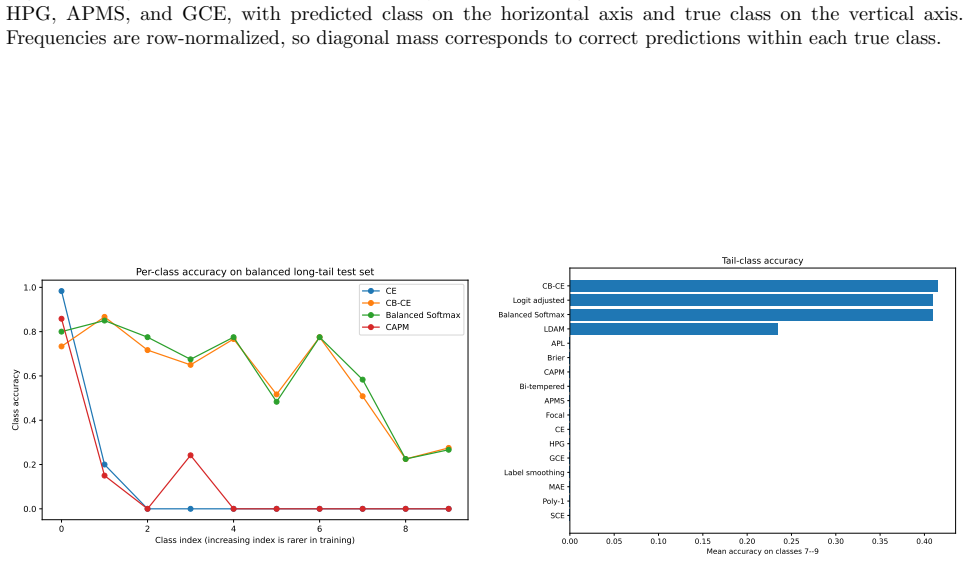
- Explicit prior-adjustment methods outperform the candidates in the 30:1 synthetic long-tail experiment.
Where Pith is reading between the lines
- The derivation techniques for regret and curvature bounds could be applied to additional families of proper scoring rules to produce new structured losses.
- The absence of consistent finite-sample gains suggests that controlling curvature alone may be insufficient to improve robustness under label noise without further adjustments.
- Testing the same losses on larger models or with more random seeds might detect smaller advantages not visible in the five-seed design.
- The controlled experimental protocol could serve as a template for evaluating other loss modifications in multiclass settings with corruption.
Load-bearing premise
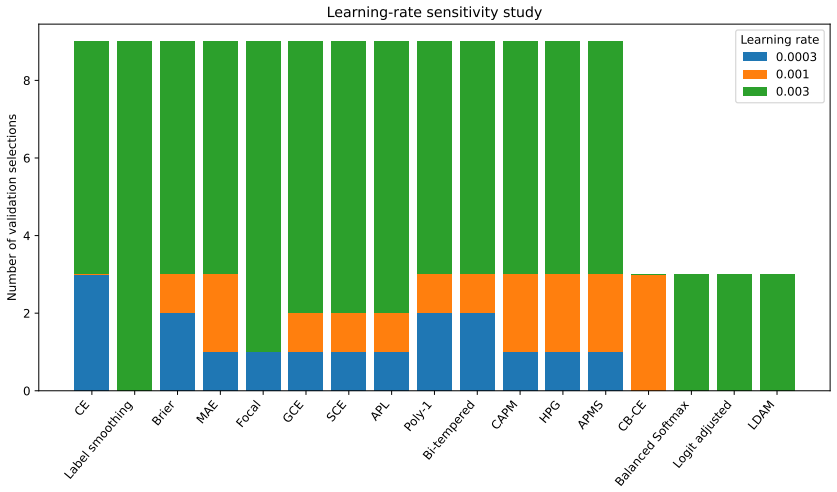
The derived conditional-regret, curvature, and penalty bounds will produce observable advantages in finite-sample optimization or robustness that can be detected in the chosen five-seed experimental design.
What would settle it
A higher-powered experiment with more seeds or additional datasets that shows consistent outperformance of these losses over cross-entropy across all tested corruption and imbalance regimes would challenge the conclusion that the evidence delimits general superiority.
Figures
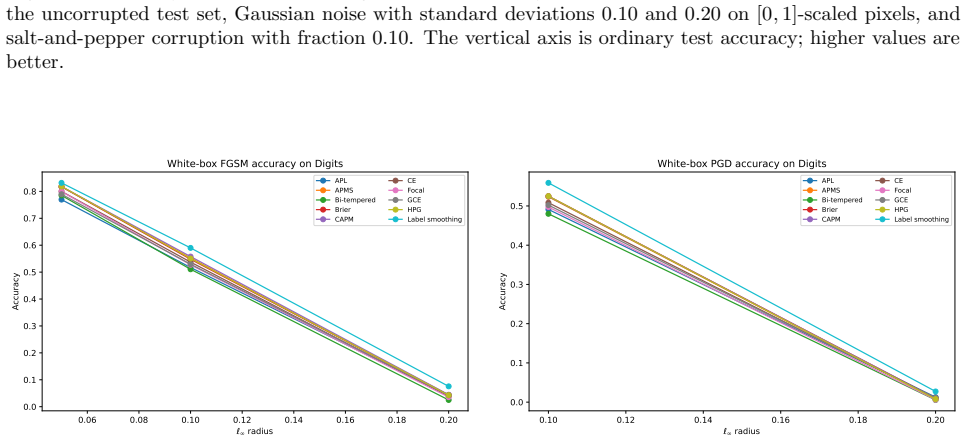
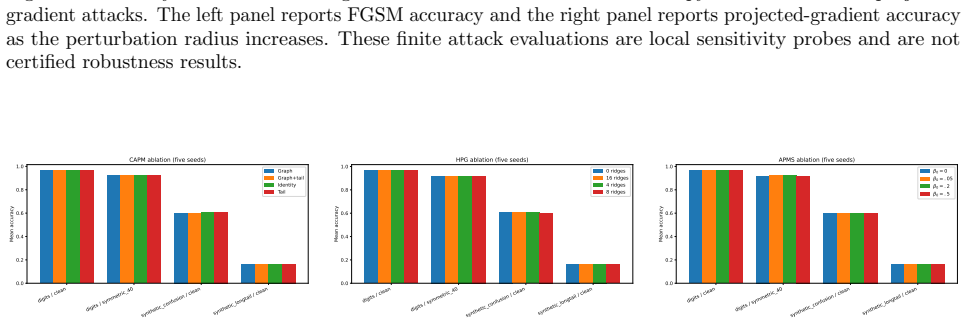
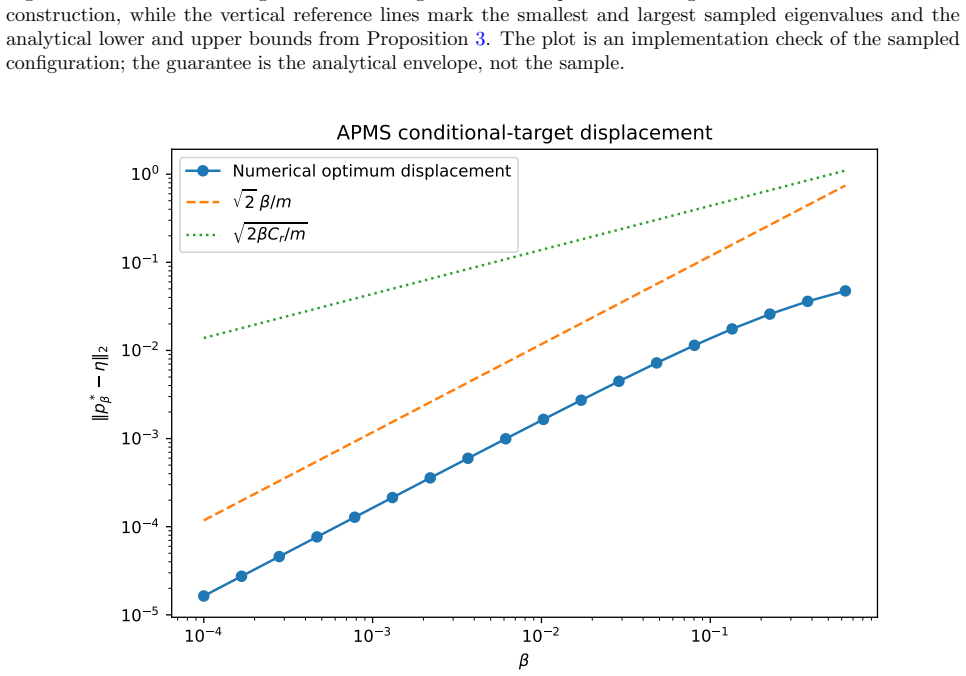
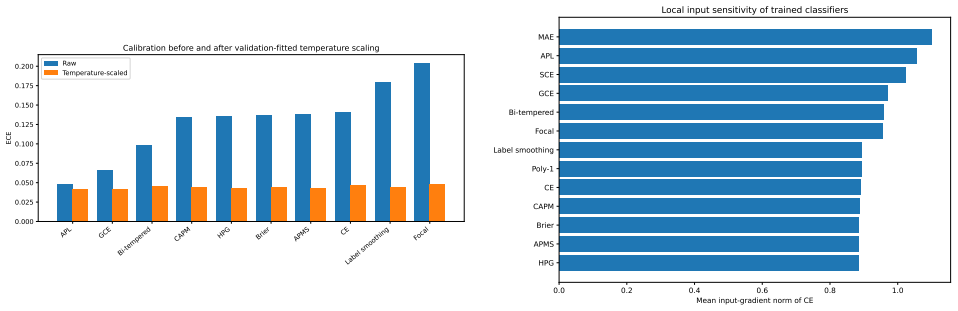
read the original abstract
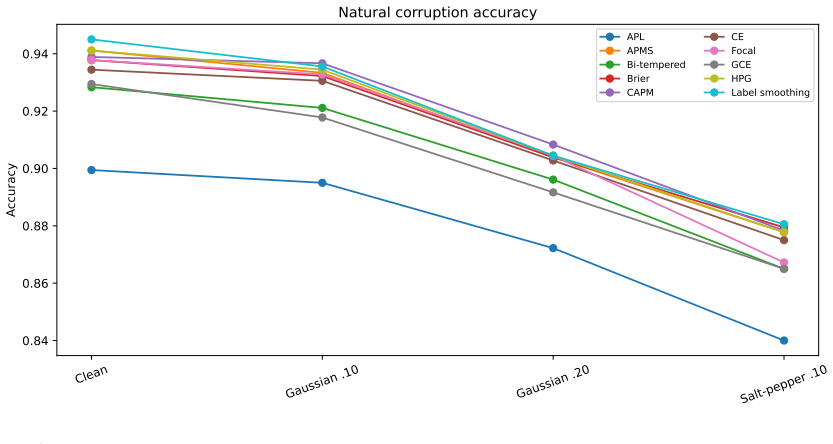
Strictly proper scoring rules identify the true conditional class distribution at population level, but their curvature can alter optimization and finite-sample behavior. We study three multiclass objectives: a class-aware quadratic Bregman score (CAPM), a strongly convex generator with constrained log-cosh ridges (HPG), and an HPG objective with an annealed probability-margin penalty (APMS). CAPM is treated as a structured instance of established quadratic scoring-rule theory. We derive conditional-regret, curvature, range, and logit-gradient bounds for CAPM and HPG, and prove exact penalty-range and conditional-target displacement bounds for APMS. Controlled five-seed experiments use Digits, Wisconsin breast cancer, and synthetic confusion and long-tail problems under clean labels, symmetric and pair-flip corruption, class imbalance, calibration evaluation, input corruption, and first-order adversarial perturbations. The candidates are close to cross-entropy on clean data and show descriptive gains in some noisy-label cells, but the five-seed comparisons are interpreted descriptively rather than as significance evidence. The selected noisy-label baselines perform better on Digits with 40% symmetric label noise, and explicit prior-adjustment methods perform better in the 30:1 synthetic long-tail experiment. Ablations do not show a consistent benefit from the candidate-specific graph, ridge, or margin components. The mathematical analysis establishes the stated properties, and the experiments delimit the empirical evidence; together they do not support a claim of general superiority.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CAPM (class-aware quadratic Bregman), HPG (strongly convex generator with log-cosh ridges), and APMS (HPG with annealed probability-margin penalty) as structured multiclass proper losses. It derives conditional-regret, curvature, range, logit-gradient bounds for CAPM/HPG and exact penalty-range/conditional-target displacement bounds for APMS, treating CAPM as an instance of quadratic scoring-rule theory. Five-seed controlled experiments on Digits, Wisconsin breast cancer, and synthetic confusion/long-tail data under clean labels, symmetric/pair-flip noise, imbalance, calibration, input corruption, and adversarial perturbations show the candidates close to cross-entropy on clean data, with only descriptive gains in some noisy cells; selected baselines outperform on 40% symmetric noise (Digits) and 30:1 long-tail; ablations show no consistent benefit from graph/ridge/margin components. The paper states that the mathematical analysis establishes the properties and the experiments delimit the evidence against general superiority.
Significance. If the derived bounds hold, they supply concrete curvature and penalty characterizations that clarify how structured proper losses differ from cross-entropy in optimization and finite-sample regimes. The delimited empirical picture is useful for practitioners deciding when to adopt such losses versus explicit prior-adjustment methods, though the five-seed descriptive design limits the strength of negative conclusions.
major comments (1)
- [Experiments paragraph] Experiments paragraph (abstract and main text): the claim that the five-seed descriptive comparisons 'delimit the empirical evidence' against general superiority is load-bearing for the final conclusion, yet the design reports no power analysis and interprets all results descriptively; given that the derived conditional-regret/curvature/penalty bounds are presented as implying potential finite-sample advantages, the low replication count on Digits/Wisconsin/synthetic data may simply fail to surface modest gains, weakening the inference that the evidence supports delimitation rather than inconclusiveness.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the experimental claims. We address it point-by-point below and propose a targeted revision to the language around empirical delimitation.
read point-by-point responses
-
Referee: [Experiments paragraph] Experiments paragraph (abstract and main text): the claim that the five-seed descriptive comparisons 'delimit the empirical evidence' against general superiority is load-bearing for the final conclusion, yet the design reports no power analysis and interprets all results descriptively; given that the derived conditional-regret/curvature/penalty bounds are presented as implying potential finite-sample advantages, the low replication count on Digits/Wisconsin/synthetic data may simply fail to surface modest gains, weakening the inference that the evidence supports delimitation rather than inconclusiveness.
Authors: We agree that the five-seed design is descriptive only and that no power analysis is reported; the manuscript already states that results are 'interpreted descriptively rather than as significance evidence.' However, the derived bounds are characterizations of conditional regret, curvature, range, logit gradients, penalty range, and target displacement; they are not presented as implying finite-sample advantages over cross-entropy. The paper's conclusion is that the mathematical properties plus the observed pattern (candidates close to CE on clean data, no consistent gains from graph/ridge/margin components, and selected baselines outperforming on specific noisy/long-tail cells) do not support a claim of general superiority. We acknowledge that modest gains could be missed with five seeds, so the results are best read as providing no evidence of superiority rather than conclusively delimiting against it. We will revise the abstract and conclusion to replace 'delimit the empirical evidence against general superiority' with 'provide no evidence supporting general superiority,' making the descriptive limitation explicit. This is a partial revision. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper positions CAPM explicitly as a structured instance of established quadratic scoring-rule theory from prior literature and derives conditional-regret, curvature, range, logit-gradient, penalty-range, and conditional-target displacement bounds directly from the definitions of the losses (CAPM, HPG, APMS). No quoted step reduces a claimed prediction or bound to a fitted parameter, self-citation chain, or ansatz imported from the authors' own prior work; the experiments are presented as descriptive delimiters rather than forced confirmations. The derivation therefore remains self-contained against external benchmarks of proper scoring rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Strictly Proper Scoring Rules, Prediction, and Estima- tion
Tilmann Gneiting and Adrian E. Raftery. “Strictly Proper Scoring Rules, Prediction, and Estima- tion”. In:Journal of the American Statistical Association102.477 (2007), pp. 359–378.doi: 10.1198/ 016214506000001437
2007
-
[2]
On Calibration of Modern Neural Networks
Chuan Guo et al. “On Calibration of Modern Neural Networks”. In:Proceedings of the 34th International Conference on Machine Learning. 2017
2017
-
[3]
A Closer Look at Memorization in Deep Networks
Devansh Arpit et al. “A Closer Look at Memorization in Deep Networks”. In:Proceedings of the 34th International Conference on Machine Learning. Vol. 70. Proceedings of Machine Learning Research. 2017, pp. 233–242
2017
-
[4]
Focal Loss for Dense Object Detection
Tsung-Yi Lin et al. “Focal Loss for Dense Object Detection”. In:Proceedings of the IEEE International Conference on Computer Vision. 2017
2017
-
[5]
Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels
Zhilu Zhang and Mert R. Sabuncu. “Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels”. In:Advances in Neural Information Processing Systems. 2018
2018
-
[6]
Symmetric Cross Entropy for Robust Learning with Noisy Labels
Yisen Wang et al. “Symmetric Cross Entropy for Robust Learning with Noisy Labels”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019
2019
-
[7]
Class-Balanced Loss Based on Effective Number of Samples
Yin Cui et al. “Class-Balanced Loss Based on Effective Number of Samples”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019
2019
-
[8]
Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
Kaidi Cao et al. “Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss”. In:Advances in Neural Information Processing Systems. 2019
2019
-
[9]
Balanced Meta-Softmax for Long-Tailed Visual Recognition
Jiawei Ren et al. “Balanced Meta-Softmax for Long-Tailed Visual Recognition”. In:Advances in Neural Information Processing Systems. 2020
2020
-
[10]
Long-Tail Learning via Logit Adjustment
Aditya Krishna Menon et al. “Long-Tail Learning via Logit Adjustment”. In:International Conference on Learning Representations. 2021
2021
-
[11]
Proper Scoring Rules and Bregman Divergences
Evgeni Y. Ovcharov. “Proper Scoring Rules and Bregman Divergences”. In:Bernoulli24.1 (2018). Preprint first posted 2015, pp. 53–79
2018
-
[12]
Composite Binary Losses
Mark D. Reid and Robert C. Williamson. “Composite Binary Losses”. In:Journal of Machine Learning Research11 (2010), pp. 2387–2422
2010
-
[13]
The Convexity and Design of Composite Multiclass Losses
Mark Reid, Robert Williamson, and Peng Sun. “The Convexity and Design of Composite Multiclass Losses”. In:Proceedings of the 29th International Conference on Machine Learning. 2012
2012
-
[14]
LegendreTron: Uprising Proper Multiclass Loss Learning
Kevin Lam et al. “LegendreTron: Uprising Proper Multiclass Loss Learning”. In:Proceedings of the 40th International Conference on Machine Learning. Vol. 202. Proceedings of Machine Learning Research. 2023, pp. 18454–18470
2023
-
[15]
Tailoring Strictly Proper Scoring Rules for Downstream Tasks: An Application to Causal Inference
Roman Plaud et al. “Tailoring Strictly Proper Scoring Rules for Downstream Tasks: An Application to Causal Inference”. In:arXiv preprint arXiv:2606.03332(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Verification of Forecasts Expressed in Terms of Probability
Glenn W. Brier. “Verification of Forecasts Expressed in Terms of Probability”. In:Monthly Weather Review78.1 (1950), pp. 1–3
1950
-
[17]
Convexity, Classification, and Risk Bounds
Peter L. Bartlett, Michael I. Jordan, and Jon D. McAuliffe. “Convexity, Classification, and Risk Bounds”. In:Journal of the American Statistical Association101.473 (2006), pp. 138–156.doi: 10 . 1198/016214505000000907
2006
-
[18]
Language Generation with Strictly Proper Scoring Rules
Chenze Shao et al. “Language Generation with Strictly Proper Scoring Rules”. In:Proceedings of the 41st International Conference on Machine Learning. Vol. 235. Proceedings of Machine Learning Research. 2024, pp. 44474–44488
2024
-
[19]
Robust Loss Functions under Label Noise for Deep Neural Networks
Aritra Ghosh, Himanshu Kumar, and P. S. Sastry. “Robust Loss Functions under Label Noise for Deep Neural Networks”. In:Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. 2017, pp. 1919–1925
2017
-
[20]
Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach
Giorgio Patrini et al. “Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach”. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, pp. 1944–1952
2017
-
[21]
Robust Bi-Tempered Logistic Loss Based on Bregman Divergences
Ehsan Amid et al. “Robust Bi-Tempered Logistic Loss Based on Bregman Divergences”. In:Advances in Neural Information Processing Systems. 2019
2019
-
[22]
Normalized Loss Functions for Deep Learning with Noisy Labels
Xingjun Ma et al. “Normalized Loss Functions for Deep Learning with Noisy Labels”. In:Proceedings of the 37th International Conference on Machine Learning. 2020
2020
-
[23]
Learning with Noisy Labels Revisited: A Study Using Real-World Human Annotations
Jiaheng Wei et al. “Learning with Noisy Labels Revisited: A Study Using Real-World Human Annotations”. In:International Conference on Learning Representations. 2022. 11
2022
-
[24]
On Focal Loss for Class-Posterior Probability Estimation: A Theoretical Perspective
Nontawat Charoenphakdee et al. “On Focal Loss for Class-Posterior Probability Estimation: A Theoretical Perspective”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021, pp. 5202–5211
2021
-
[25]
arXiv preprint arXiv:2408.11598 , year=
Viacheslav Komisarenko and Meelis Kull. “Improving Calibration by Relating Focal Loss, Temperature Scaling, and Properness”. In:arXiv preprint arXiv:2408.11598(2024)
-
[26]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. “Explaining and Harnessing Adversarial Examples”. In:International Conference on Learning Representations. 2015
2015
-
[27]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry et al. “Towards Deep Learning Models Resistant to Adversarial Attacks”. In:Interna- tional Conference on Learning Representations. 2018
2018
-
[28]
Theoretically Principled Trade-off between Robustness and Accuracy
Hongyang Zhang et al. “Theoretically Principled Trade-off between Robustness and Accuracy”. In: Proceedings of the 36th International Conference on Machine Learning. 2019
2019
-
[29]
Reliable Evaluation of Adversarial Robustness with an Ensemble of Diverse Parameter-Free Attacks
Francesco Croce and Matthias Hein. “Reliable Evaluation of Adversarial Robustness with an Ensemble of Diverse Parameter-Free Attacks”. In:Proceedings of the 37th International Conference on Machine Learning. 2020
2020
-
[30]
Scikit-learn: Machine Learning in Python
Fabian Pedregosa et al. “Scikit-learn: Machine Learning in Python”. In:Journal of Machine Learning Research12 (2011), pp. 2825–2830
2011
-
[31]
Rethinking the Inception Architecture for Computer Vision
Christian Szegedy et al. “Rethinking the Inception Architecture for Computer Vision”. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016, pp. 2818–2826
2016
-
[32]
PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions
Zhaoqi Leng et al. “PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions”. In: International Conference on Learning Representations. 2022
2022
-
[33]
Individual Comparisons by Ranking Methods
Frank Wilcoxon. “Individual Comparisons by Ranking Methods”. In:Biometrics Bulletin1.6 (1945), pp. 80–83
1945
-
[34]
A Simple Sequentially Rejective Multiple Test Procedure
Sture Holm. “A Simple Sequentially Rejective Multiple Test Procedure”. In:Scandinavian Journal of Statistics6.2 (1979), pp. 65–70. 12 A Proofs A.1 Proof of Lemma 1 Linearity of expectation gives RF (η, p) = X y ηyF(e y)−F(p)− ⟨∇F(p), η−p⟩,(24) RF (η, η) = X y ηyF(e y)−F(η).(25) Subtracting yields Eq. (3). Strict convexity makes DF (η, p) = 0 if and only i...
1979
-
[35]
The derivative of the outer softplus with respect to mτ has magnitude at most one, so the norm of the conditional penalty gradient is at most √
-
[36]
The Bregman identity gives∇ pR0(η, p) =H F (p)(p−η), and therefore ⟨∇pR0(η, p⋆ β), p⋆ β −η⟩ ≥m∥p ⋆ β −η∥ 2 2.(36) Combining this inequality with the first-order variational inequality atp ⋆ β gives m∥p⋆ β −η∥ 2 2 ≤β √ 2∥p⋆ β −η∥ 2,(37) which proves Eq. (23). A.6 Why APMS with a positive margin coefficient is not generally proper A binary counterexample is...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.