Does Role Specialization Matter for Explanation Faithfulness in Mixture-of-Experts?
Pith reviewed 2026-06-30 07:09 UTC · model grok-4.3
The pith
Representation decorrelation in mixture-of-experts models raises explanation faithfulness scores while preserving task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
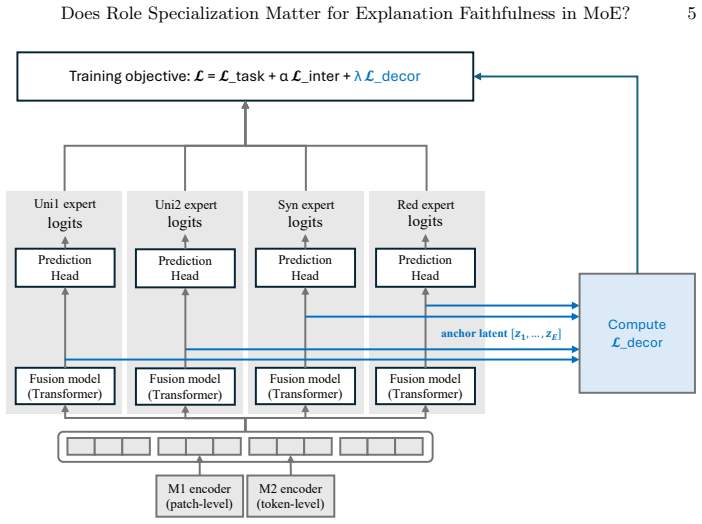
The authors claim that inter-expert representation overlap weakens effective role separation and degrades attribution-based faithfulness even when semantic roles are explicitly defined, and that representation-level decorrelation regularization, by minimizing this overlap, consistently improves faithfulness metrics across multimodal benchmarks while preserving task performance; they further claim that the same gains appear in ordinary sparse MoE baselines, indicating that structural role decomposition alone is insufficient.
What carries the argument
representation-level decorrelation regularization, which minimizes inter-expert similarity in latent space to encourage clearer specialization
If this is right
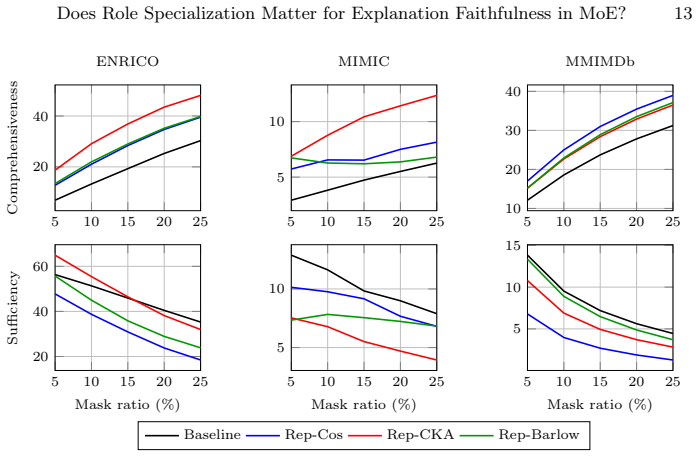
- Faithfulness measured by comprehensiveness, sufficiency, and AOPC improves across multiple multimodal benchmarks.
- Task performance stays the same after the regularization is added.
- The improvement appears in both role-based MoE variants and standard sparse MoE models.
- Structural assignment of semantic roles by itself does not guarantee faithful explanations.
Where Pith is reading between the lines
- The same decorrelation step could be tested in non-MoE modular networks to check whether reduced representation overlap improves faithfulness more generally.
- If representation overlap is the dominant obstacle, then other independence-promoting losses might produce similar gains without needing explicit role labels.
- The method might be combined with post-hoc explanation techniques to see whether the two approaches compound.
Load-bearing premise
The chosen faithfulness metrics based on input perturbations correctly measure whether an explanation matches the model's actual internal decision process.
What would settle it
An experiment on the same models where decorrelation is applied, faithfulness metric scores rise, yet human inspection of the resulting attributions shows they still omit or mis-rank the factors the model actually used.
Figures
read the original abstract
Mixture-of-Experts (MoE) architectures have recently been extended with role-based mechanisms for interpretability. This is typically done by assigning semantic roles to individual expert components, for example roles like synergy, redundancy, and uniqueness in multimodal settings. However, whether such structural role decomposition preserves explanation faithfulness of the overall architecture remains largely underexplored. We hypothesize that inter-expert representation overlap weakens effective role separation and degrades attribution-based faithfulness, even when semantic roles are explicitly defined. To address this limitation, we introduce representation-level decorrelation regularization to explicitly reduce inter-expert similarity in latent space. Using representation decorrelation objectives, we encourage clearer specialization among experts by minimizing representation overlap. Our experiments show that across multiple multimodal benchmarks, this separation consistently improves explanation faithfulness, as measured by comprehensiveness, sufficiency, and their Area Over the Perturbation Curve (AOPC) summaries, while preserving task performance. We further show that these improvements are not limited to role-based architectures such as Interpretable Multimodal Interaction-aware MoE (I2MoE). Similar trends are observed in a standard sparse MoE baseline, suggesting that representation-level separation may provide a more general mechanism for enhancing explanation faithfulness in MoE systems. Overall, our findings suggest that structural role decomposition alone may be insufficient to guarantee faithful explanations and that representation-level separation helps improve explanation faithfulness. To support reproducibility, the source code and supplementary material are publicly available at https://github.com/dut0817/FL-I2MoE_Decor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that inter-expert representation overlap in Mixture-of-Experts (MoE) models weakens attribution-based explanation faithfulness even when semantic roles (e.g., synergy, redundancy, uniqueness) are explicitly assigned, as in architectures like I2MoE. It introduces representation-level decorrelation regularization to minimize latent-space overlap and encourage specialization. Experiments across multimodal benchmarks show consistent gains in faithfulness metrics (comprehensiveness, sufficiency, and AOPC) while preserving task performance; similar trends hold in a standard sparse MoE baseline, suggesting the approach is more general than role-based decomposition alone. Code is released for reproducibility.
Significance. If the results are robust, the work would indicate that structural role assignment is insufficient to guarantee faithful explanations in MoE systems and that explicit representation separation offers a practical, general mechanism for improving attribution quality. The public code release supports reproducibility. Significance is limited by the absence of direct evidence that metric gains reflect improved alignment with internal routing rather than secondary effects on perturbation sensitivity.
major comments (2)
- [Abstract / experimental results] Abstract and experimental results: the central claim that decorrelation improves faithfulness rests on gains in comprehensiveness, sufficiency, and AOPC, yet no direct validation is described (e.g., correlation between attribution ranks and actual expert activation vectors or gating decisions on the same inputs) that would rule out the alternative that gains arise from altered perturbation sensitivity rather than better reflection of the model's decision process.
- [Methods] Methods / decorrelation objective: the regularization is applied to reduce inter-expert similarity, but the manuscript does not analyze how this interacts with the sparse gating mechanism (e.g., whether it changes expert selection probabilities or routing entropy), leaving open whether the faithfulness metric improvements are load-bearing on the claimed mechanism or on downstream changes in output sensitivity.
minor comments (2)
- [Abstract] The abstract refers to 'FL-I2MoE_Decor' without defining the acronym on first use.
- [Experiments] No mention of the number of runs, statistical significance tests, or variance across seeds for the reported metric improvements.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help clarify the connection between representation decorrelation and explanation faithfulness. We address the major comments point by point below, proposing revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract and experimental results: the central claim that decorrelation improves faithfulness rests on gains in comprehensiveness, sufficiency, and AOPC, yet no direct validation is described (e.g., correlation between attribution ranks and actual expert activation vectors or gating decisions on the same inputs) that would rule out the alternative that gains arise from altered perturbation sensitivity rather than better reflection of the model's decision process.
Authors: We agree that direct validation linking attributions to internal routing would provide stronger evidence. In the revised version, we will add an experiment computing the correlation between attribution ranks and expert activation vectors/gating decisions on the same inputs. This analysis will help confirm that the observed gains in faithfulness metrics reflect improved alignment with the model's decision process. revision: yes
-
Referee: [Methods] Methods / decorrelation objective: the regularization is applied to reduce inter-expert similarity, but the manuscript does not analyze how this interacts with the sparse gating mechanism (e.g., whether it changes expert selection probabilities or routing entropy), leaving open whether the faithfulness metric improvements are load-bearing on the claimed mechanism or on downstream changes in output sensitivity.
Authors: We acknowledge the need to examine the interaction with the gating mechanism. We will include additional analysis in the methods and results sections reporting expert selection probabilities and routing entropy with and without the decorrelation regularization. This will clarify the mechanism through which the regularization affects faithfulness. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivation chain
full rationale
The paper introduces representation decorrelation regularization as a method and reports experimental results on faithfulness metrics (comprehensiveness, sufficiency, AOPC) across multimodal benchmarks. No equations, predictions, or first-principles derivations are presented that could reduce to fitted inputs or self-citations by construction. The central claims rest on observed metric improvements that are independently measurable and falsifiable via the described experiments. Minor self-citation to I2MoE is not load-bearing for the reported gains.
Axiom & Free-Parameter Ledger
free parameters (1)
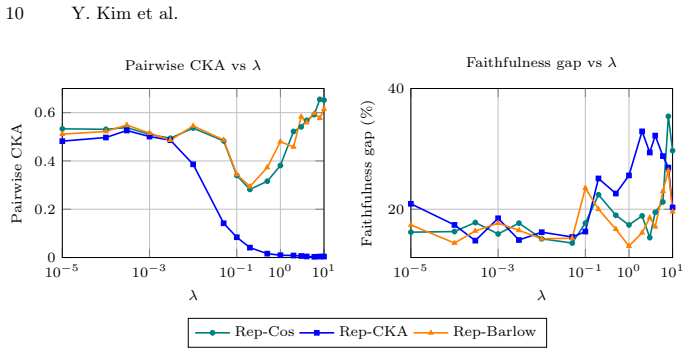
- decorrelation regularization strength
axioms (1)
- domain assumption Faithfulness metrics (comprehensiveness, sufficiency, AOPC) accurately reflect explanation quality
Reference graph
Works this paper leans on
-
[1]
In: Proceed- ings of the 58th Annual Meeting of the Association for Computational Linguistics
Abnar, S., Zuidema, W.: Quantifying attention flow in transformers. In: Proceed- ings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 4190–4197. Online (Jul 2020)
2020
-
[2]
On the Robustness of Interpretability Methods
Alvarez-Melis, D., Jaakkola, T.S.: On the robustness of interpretability methods. arXiv preprint arXiv:1806.08049 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Gated Multimodal Units for Information Fusion
Arevalo, J., Solorio, T., Montes-y Gómez, M., González, F.A.: Gated multimodal units for information fusion. arXiv preprint arXiv:1702.01992 (2017) 16 Y. Kim et al
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
IEEE Transactions on Knowledge and Data Engineering (2025)
Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., Huang, J.: A survey on mixture of experts in large language models. IEEE Transactions on Knowledge and Data Engineering (2025)
2025
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chefer, H., Gur, S., Wolf, L.: Generic attention-model explainability for interpret- ing bi-modal and encoder-decoder transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 397–406 (2021)
2021
-
[6]
Advances in neural information processing systems 35, 23049–23062 (2022)
Chen, Z., Deng, Y., Wu, Y., Gu, Q., Li, Y.: Towards understanding the mixture-of- experts layer in deep learning. Advances in neural information processing systems 35, 23049–23062 (2022)
2022
-
[7]
Advances in Neural Information Processing Systems35, 34600–34613 (2022)
Chi, Z., Dong, L., Huang, S., Dai, D., Ma, S., Patra, B., Singhal, S., Bajaj, P., Song, X., Mao, X.L., et al.: On the representation collapse of sparse mixture of experts. Advances in Neural Information Processing Systems35, 34600–34613 (2022)
2022
-
[8]
In: Proceedings of the 30th annual ACM symposium on user interface software and technology
Deka, B., Huang, Z., Franzen, C., Hibschman, J., Afergan, D., Li, Y., Nichols, J., Kumar, R.: Rico: A mobile app dataset for building data-driven design ap- plications. In: Proceedings of the 30th annual ACM symposium on user interface software and technology. pp. 845–854 (2017)
2017
-
[9]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
DeYoung, J., Jain, S., Rajani, N.F., Lehman, E., Xiong, C., Socher, R., Wallace, B.C.: Eraser: A benchmark to evaluate rationalized nlp models. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 4443–4458 (2020)
2020
-
[10]
Do, G., Le, H., Tran, T.: Simsmoe: Toward efficient training mixture of experts via solvingrepresentationalcollapse.In:FindingsoftheAssociationforComputational Linguistics: NAACL 2025. pp. 2012–2025 (2025)
2025
-
[11]
Journal of Machine Learning Research 23(120), 1–39 (2022)
Fedus,W.,Zoph,B.,Shazeer,N.:Switchtransformers:Scalingtotrillionparameter models with simple and efficient sparsity. Journal of Machine Learning Research 23(120), 1–39 (2022)
2022
-
[12]
arXiv preprint arXiv:2505.17553 (2025)
Feng, J., Wei, C., Qiu, T., Hu, T., Pu, Z.: Comoe: Contrastive represen- tation for mixture-of-experts in parameter-efficient fine-tuning. arXiv preprint arXiv:2505.17553 (2025)
-
[13]
Neural computation3(1), 79–87 (1991)
Jacobs, R.A., Jordan, M.I., Nowlan, S.J., Hinton, G.E.: Adaptive mixtures of local experts. Neural computation3(1), 79–87 (1991)
1991
-
[14]
Scientific data10(1), 1 (2023)
Johnson, A.E., Bulgarelli, L., Shen, L., Gayles, A., Shammout, A., Horng, S., Pollard, T.J., Hao, S., Moody, B., Gow, B., et al.: Mimic-iv, a freely accessible electronic health record dataset. Scientific data10(1), 1 (2023)
2023
-
[15]
Feature-level Interaction Explanations in Multimodal Transformers
Kim, Y., Babiker, H.K.B., Kim, M.Y., Goebel, R.: Feature-level interaction expla- nations in multimodal transformers. arXiv preprint arXiv:2603.13326 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
In: International conference on machine learning
Kornblith, S., Norouzi, M., Lee, H., Hinton, G.: Similarity of neural network rep- resentations revisited. In: International conference on machine learning. pp. 3519–
-
[17]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., Chen, Z.: Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[18]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Li, Y., Jiang, S., Hu, B., Wang, L., Zhong, W., Luo, W., Ma, L., Zhang, M.: Uni- moe: Scaling unified multimodal llms with mixture of experts. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[19]
Advances in neural information processing systems2021(DB1), 1 (2021) Does Role Specialization Matter for Explanation Faithfulness in MoE? 17
Liang, P.P., Lyu, Y., Fan, X., Wu, Z., Cheng, Y., Wu, J., Chen, L., Wu, P., Lee, M.A., Zhu, Y., et al.: Multibench: Multiscale benchmarks for multimodal represen- tation learning. Advances in neural information processing systems2021(DB1), 1 (2021) Does Role Specialization Matter for Explanation Faithfulness in MoE? 17
2021
-
[20]
IEEE Transactions on Multimedia (2026)
Lin, B., Tang, Z., Ye, Y., Huang, J., Zhang, J., Pang, Y., Jin, P., Ning, M., Luo, J., Yuan, L.: Moe-llava: Mixture of experts for large vision-language models. IEEE Transactions on Multimedia (2026)
2026
-
[21]
Lo, K.M., Huang, Z., Qiu, Z., Wang, Z., Fu, J.: A closer look into mixture-of- expertsinlargelanguagemodels.In:FindingsoftheAssociationforComputational Linguistics: NAACL 2025. pp. 4427–4447 (2025)
2025
-
[22]
Computational Linguistics50(2), 657–723 (2024)
Lyu, Q., Apidianaki, M., Callison-Burch, C.: Towards faithful model explanation in nlp: A survey. Computational Linguistics50(2), 657–723 (2024)
2024
-
[23]
Regularizing CNNs with Locally Constrained Decorrelations
Rodríguez, P., Gonzalez, J., Cucurull, G., Gonfaus, J.M., Roca, X.: Regulariz- ing cnns with locally constrained decorrelations. arXiv preprint arXiv:1611.01967 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
IEEE transactions on neural networks and learning systems28(11), 2660–2673 (2016)
Samek, W., Binder, A., Montavon, G., Lapuschkin, S., Müller, K.R.: Evaluating the visualization of what a deep neural network has learned. IEEE transactions on neural networks and learning systems28(11), 2660–2673 (2016)
2016
-
[25]
In: 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA)
Shahapure, K.R., Nicholas, C.: Cluster quality analysis using silhouette score. In: 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA). pp. 747–748 (2020). https://doi.org/10.1109/DSAA49011.2020.00096
-
[26]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
In: International conference on machine learning
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic attribution for deep networks. In: International conference on machine learning. pp. 3319–3328. PMLR (2017)
2017
-
[28]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wenderoth, L., Hemker, K., Simidjievski, N., Jamnik, M.: Measuring cross-modal interactions in multimodal models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 21501–21509 (2025)
2025
-
[29]
Wollstadt, P., Schmitt, S., Wibral, M.: A rigorous information-theoretic definition of redundancy and relevancy in feature selection based on (partial) information decomposition. J. Mach. Learn. Res.24(1) (Jan 2023)
2023
-
[30]
In: Proceedings of the 42nd International Conference on Machine Learning
Xin, J., Yun, S., Peng, J., Choi, I., Ballard, J.L., Chen, T., Long, Q.:I2MoE: In- terpretable multimodal interaction-aware mixture-of-experts. In: Proceedings of the 42nd International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 267, pp. 68870–68888. PMLR (13–19 Jul 2025)
2025
-
[31]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Yu, H., Qi, Z., Jang, L.K., Salakhutdinov, R., Morency, L.P., Liang, P.P.: MMoE: Enhancing multimodal models with mixtures of multimodal interaction experts. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 10006–10030. Miami, Florida, USA (Nov 2024)
2024
-
[32]
In: International conference on machine learn- ing
Zbontar, J., Jing, L., Misra, I., LeCun, Y., Deny, S.: Barlow twins: Self-supervised learning via redundancy reduction. In: International conference on machine learn- ing. pp. 12310–12320. PMLR (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.