How Far Can You Get Without a GPU? A Systematic Benchmark of Lightweight Hallucination Detection Across Question Answering, Dialogue, and Summarisation
Pith reviewed 2026-06-30 06:20 UTC · model grok-4.3
The pith
Lightweight CPU methods detect hallucinations well on QA but near-random on summarisation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
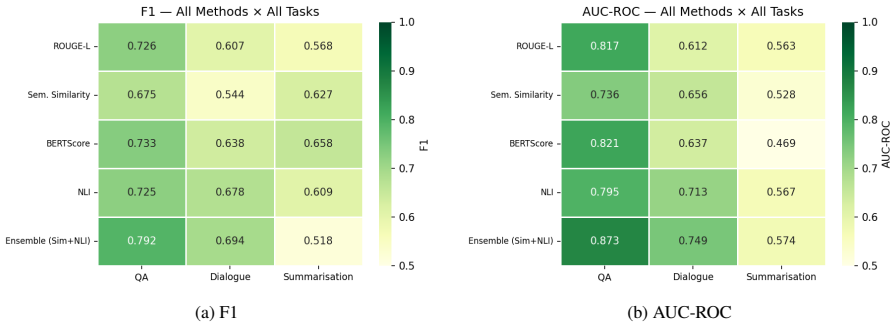
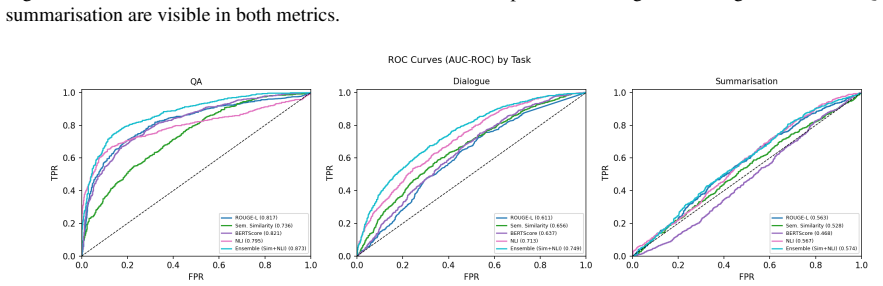
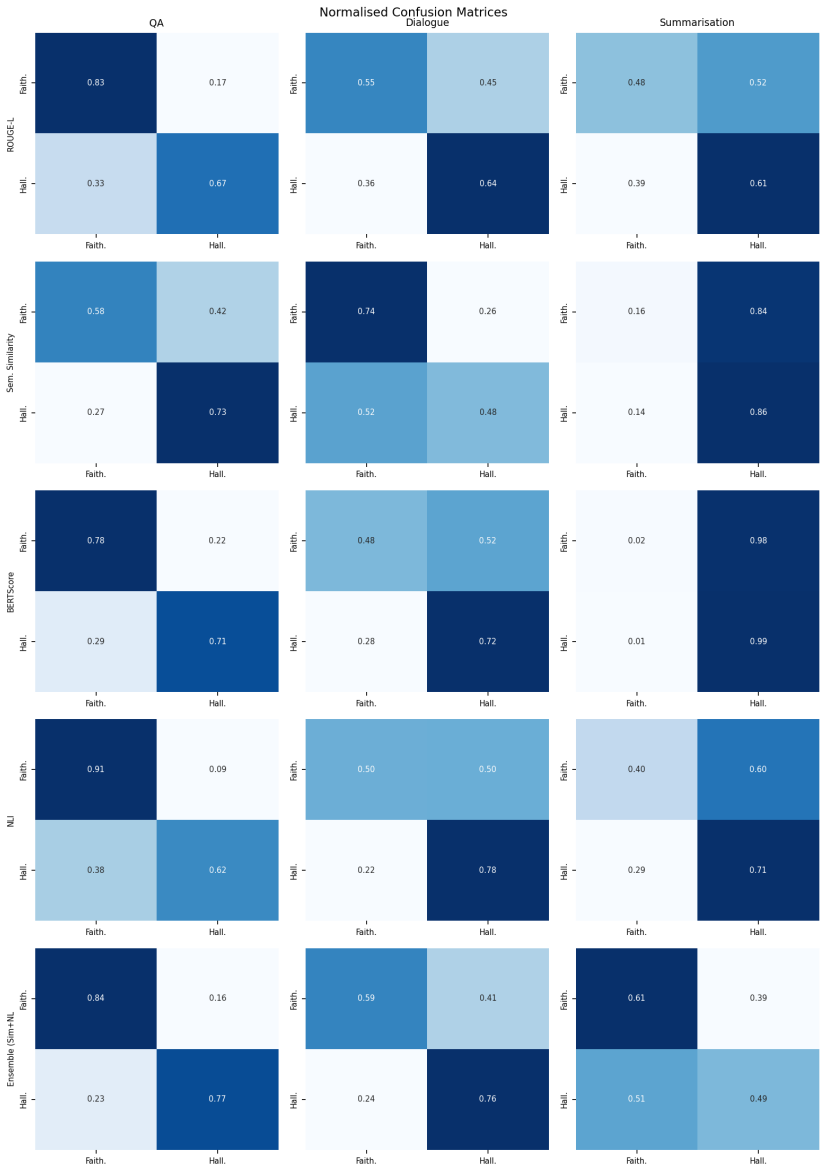
No single lightweight detector dominates; performance is sharply task-dependent, with the ensemble reaching F1 0.792 and AUC-ROC 0.873 on QA, the NLI detector reaching AUC-ROC 0.713 on dialogue, and all five methods falling to AUC-ROC values between 0.469 and 0.574 on summarisation.
What carries the argument
The five-method benchmark (ROUGE-L, semantic similarity, BERTScore, FEVER-trained DeBERTa NLI detector, and their score-level ensemble) run on HaluEval's three tasks with CPU-only inference and public models.
If this is right
- For QA tasks under CPU constraints, the ensemble of similarity and NLI scores is the strongest available option.
- For dialogue, the standalone NLI detector based on the FEVER-trained DeBERTa model outperforms the other four methods.
- None of the tested methods can be trusted for summarisation without additional GPU-heavy techniques.
- Calibration on a held-out validation split is required to obtain the reported performance levels.
Where Pith is reading between the lines
- Task-specific method selection, rather than a single universal detector, becomes the practical strategy when GPU resources are absent.
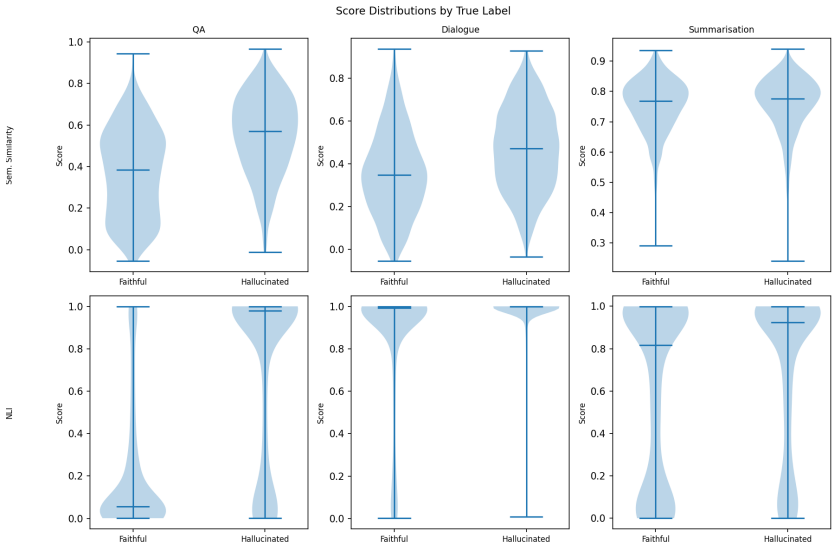
- The consistent failure on summarisation suggests that hallucination phenomena in summaries may differ in structure from those in QA or dialogue, pointing to a need for summarisation-specific lightweight signals.
- If HaluEval labels contain systematic bias on the summarisation portion, re-annotation could reopen the possibility of effective CPU-only detection there.
Load-bearing premise
The HaluEval benchmark supplies accurate, unbiased ground-truth labels that correctly identify hallucinations and apply equally across QA, dialogue, and summarisation.
What would settle it
Re-annotating the HaluEval summarisation test instances with fresh human judges and finding that any of the five methods then achieves AUC-ROC above 0.65 would falsify the claim of systematic near-random performance on that task.
Figures
read the original abstract
Hallucination detection has become a pressing requirement for trustworthy AI deployment at scale. The most accurate detection methods depend on GPU-intensive inference, proprietary API calls, or white-box access to the generating model. This puts them out of reach for resource-constrained researchers and practitioners. In this paper, we explore a practical alternative: how well can hallucination detection perform using only lightweight, CPU-feasible methods built on publicly available models? We systematically benchmark five such methods: ROUGE-L, semantic similarity, BERTScore, a Natural Language Inference (NLI) detector based on a FEVER-trained DeBERTa model, and a score-level ensemble of similarity and NLI. We evaluate them across all three tasks of the HaluEval benchmark: question answering (QA), dialogue, and summarisation. We calibrate each method on a held-out validation split and evaluate it on 2,000 test instances per task. We find that no single method dominates and performance is highly task-dependent. The ensemble performs best on QA (F1 = 0.792, AUC-ROC = 0.873), the NLI detector leads on dialogue (AUC-ROC = 0.713), and all five methods degrade to near-random performance on summarisation (AUC-ROC between 0.469 and 0.574). This task-dependence and the systematic failure on summarisation map the practical frontier of GPU-free hallucination detection. They give practical guidance for method selection under computational constraints. All experiments run on a standard laptop CPU using public models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks five lightweight, CPU-only hallucination detectors (ROUGE-L, semantic similarity, BERTScore, a FEVER-trained DeBERTa NLI model, and a score-level ensemble) on the HaluEval benchmark across its QA, dialogue, and summarisation tasks. Thresholds are calibrated on held-out validation data and evaluated on 2,000 test instances per task, yielding the claim that no method dominates, performance is highly task-dependent, the ensemble reaches F1=0.792 / AUC-ROC=0.873 on QA, NLI leads on dialogue (AUC-ROC=0.713), and all methods fall to near-random on summarisation (AUC-ROC 0.469–0.574).
Significance. If the HaluEval labels are reliable, the work supplies concrete, actionable guidance on the practical limits of GPU-free detection and correctly credits the systematic design, use of public models, held-out calibration, and large per-task test sets. The explicit task-wise F1 and AUC-ROC numbers and the reproducible CPU-only protocol are strengths that would remain useful even if the absolute numbers shift.
major comments (1)
- [Abstract] Abstract and evaluation protocol: the central claim that summarisation performance is intrinsically near-random (AUC-ROC 0.469–0.574) and that the ensemble/NLI results on QA and dialogue are trustworthy rests on the unexamined assumption that HaluEval supplies accurate, unbiased ground-truth labels. The manuscript reports no human validation, inter-annotator agreement, or label-noise analysis for any task, particularly summarisation; without this, the observed degradation cannot be confidently attributed to method limitations rather than label quality.
minor comments (2)
- [Methods] The description of the ensemble (score-level combination of similarity and NLI) does not specify the exact weighting or aggregation rule used to produce the reported F1 and AUC values.
- [Results] Table or figure captions should explicitly state the number of validation instances used for threshold calibration per task.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address the single major comment below, acknowledging its validity and outlining planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation protocol: the central claim that summarisation performance is intrinsically near-random (AUC-ROC 0.469–0.574) and that the ensemble/NLI results on QA and dialogue are trustworthy rests on the unexamined assumption that HaluEval supplies accurate, unbiased ground-truth labels. The manuscript reports no human validation, inter-annotator agreement, or label-noise analysis for any task, particularly summarisation; without this, the observed degradation cannot be confidently attributed to method limitations rather than label quality.
Authors: We agree that the manuscript relies on HaluEval labels without providing independent validation, inter-annotator agreement statistics, or label-noise analysis. The original HaluEval construction involved human annotation, but our work does not re-examine or quantify label reliability, especially on the summarisation task. This means the near-random performance cannot be attributed solely to detector limitations. We will revise the abstract to state that all methods achieve near-random performance on the HaluEval summarisation task (rather than implying intrinsic failure of the methods) and add a new Limitations subsection discussing benchmark label quality as a confounding factor. These changes will make the claims more precise while retaining the task-dependent performance comparisons. New human annotation or label analysis is outside the scope of this revision. revision: partial
Circularity Check
No circularity: purely empirical benchmark with independent evaluation protocol.
full rationale
The paper performs a standard held-out calibration and test evaluation of five lightweight detectors on the external HaluEval benchmark across three tasks. No equations, derivations, or first-principles claims exist; performance numbers are direct empirical measurements on fixed test splits after validation-based threshold selection. No self-citations are load-bearing, no fitted parameters are renamed as predictions, and no uniqueness theorems or ansatzes are invoked. The evaluation protocol is self-contained against external benchmarks and does not reduce any result to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- decision thresholds =
optimized on validation
axioms (1)
- domain assumption HaluEval provides accurate ground-truth hallucination labels across all three tasks
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Language models are few-shot learners , author =. Advances in Neural Information Processing Systems , volume =
-
[3]
ACM Computing Surveys , volume =
Survey of hallucination in natural language generation , author =. ACM Computing Surveys , volume =
-
[4]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
On faithfulness and factuality in abstractive summarization , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
-
[5]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =
-
[6]
Manakul, Potsawee and Liusie, Adian and Gales, Mark J. F. , booktitle =
-
[7]
Nature , volume =
Detecting hallucinations in large language models using semantic entropy , author =. Nature , volume =
-
[8]
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang Wei and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh , booktitle =
-
[9]
Li, Junyi and Cheng, Xiaoxue and Zhao, Wayne Xin and Nie, Jian-Yun and Wen, Ji-Rong , booktitle =
-
[10]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =
Ranking generated summaries by correctness: An interesting but challenging application for natural language inference , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =
-
[11]
Thorne, James and Vlachos, Andreas and Christodoulopoulos, Christos and Mittal, Arpit , booktitle =
-
[12]
Less annotating, more classifying: Addressing the data scarcity issue of supervised machine learning with deep transfer learning and
Laurer, Moritz and Van Atteveldt, Wouter and Casas, Andreu and Welbers, Kasper , journal =. Less annotating, more classifying: Addressing the data scarcity issue of supervised machine learning with deep transfer learning and
-
[13]
and Hearst, Marti A
Laban, Philippe and Schnabel, Tobias and Bennett, Paul N. and Hearst, Marti A. , journal =
-
[14]
Lin, Chin-Yew , booktitle =
-
[15]
and Artzi, Yoav , booktitle =
Zhang, Tianyi and Kishore, Varsha and Wu, Felix and Weinberger, Kilian Q. and Artzi, Yoav , booktitle =
-
[16]
Reimers, Nils and Gurevych, Iryna , booktitle =
-
[17]
Scikit-learn: Machine learning in
Pedregosa, Fabian and Varoquaux, Ga. Scikit-learn: Machine learning in. Journal of Machine Learning Research , volume =
-
[18]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, and Dario Amodei. 2020. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877--1901
2020
-
[19]
Tobias Falke, Leonardo F. R. Ribeiro, Prasetya Ajie Utama, Ido Dagan, and Iryna Gurevych. 2019. Ranking generated summaries by correctness: An interesting but challenging application for natural language inference. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2214--2220
2019
-
[20]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625--630
2024
-
[21]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1--38
2023
-
[22]
Bennett, and Marti A
Philippe Laban, Tobias Schnabel, Paul N. Bennett, and Marti A. Hearst. 2022. SummaC : Re-visiting NLI -based models for inconsistency detection in summarization. Transactions of the Association for Computational Linguistics, 10:163--177
2022
-
[23]
Moritz Laurer, Wouter Van Atteveldt, Andreu Casas, and Kasper Welbers. 2024. Less annotating, more classifying: Addressing the data scarcity issue of supervised machine learning with deep transfer learning and BERT-NLI . Political Analysis, 32(1):84--100
2024
-
[24]
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. HaluEval : A large-scale hallucination evaluation benchmark for large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6449--6464
2023
-
[25]
Chin-Yew Lin. 2004. ROUGE : A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74--81
2004
-
[26]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval : NLG evaluation using GPT-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511--2522
2023
-
[27]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. 2023. SelfCheckGPT : Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004--9017
2023
-
[28]
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On faithfulness and factuality in abstractive summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906--1919
2020
-
[29]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. FactScore : Fine-grained atomic evaluation of factual precision in long-form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076--12100
2023
-
[30]
Fabian Pedregosa, Ga \"e l Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, and \'E douard Duchesnay. 2011. Scikit-learn: Machine learning in Python . Journal of Machine Learning Research, 12:2825--2830
2011
-
[31]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT : Sentence embeddings using Siamese BERT -networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 3982--3992
2019
-
[32]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER : A large-scale dataset for fact extraction and verification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 809--819
2018
-
[33]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, and Guillaume Lample. 2023. LLaMA : Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore : Evaluating text generation with BERT . In Proceedings of the 8th International Conference on Learning Representations
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.