AI Training Manager: Bounded Closed-Loop Control of Adaptive Training Recipes
Pith reviewed 2026-06-30 06:32 UTC · model grok-4.3
The pith
A schema-conditioned LLM reads training telemetry and returns bounded parameter updates to fix issues like overfitting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
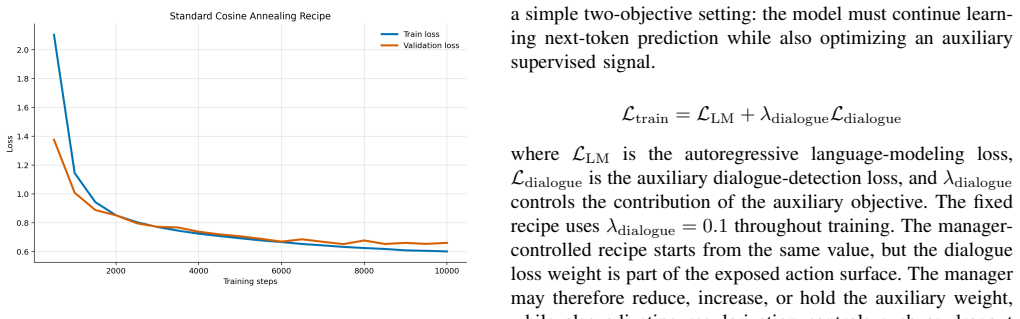
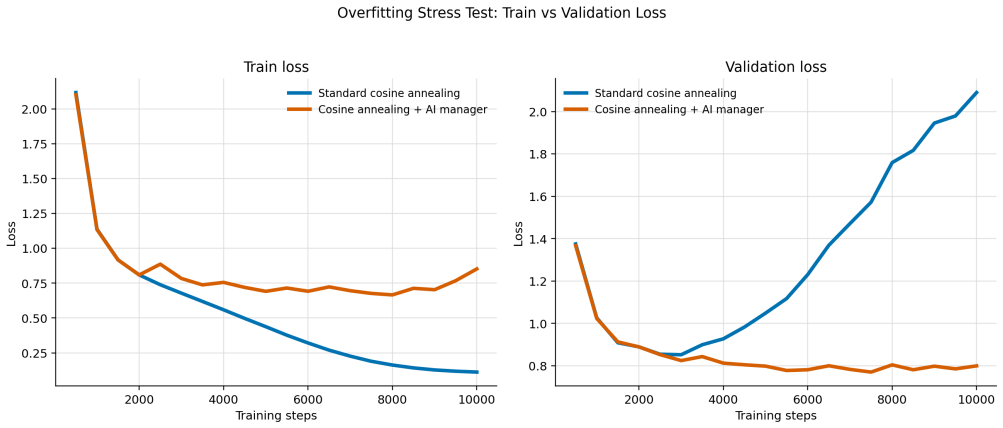
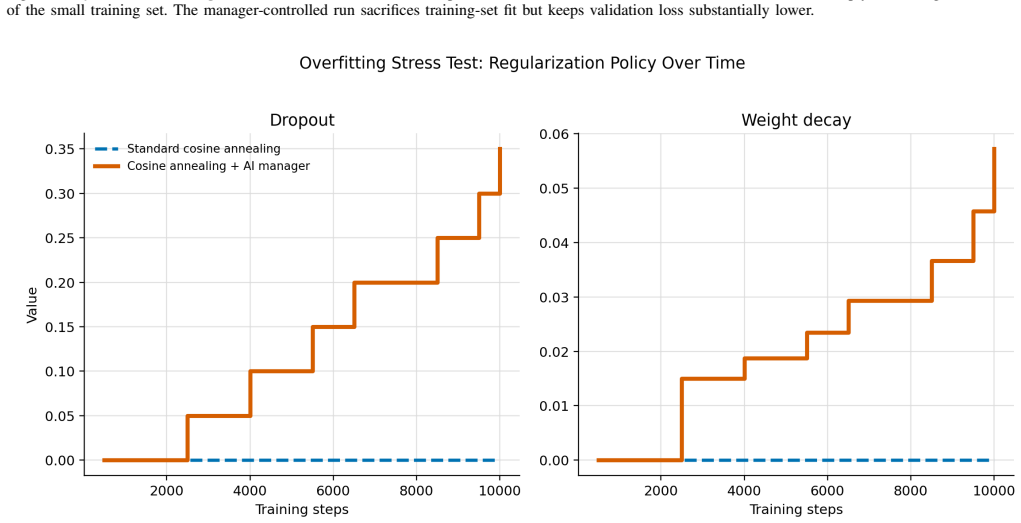
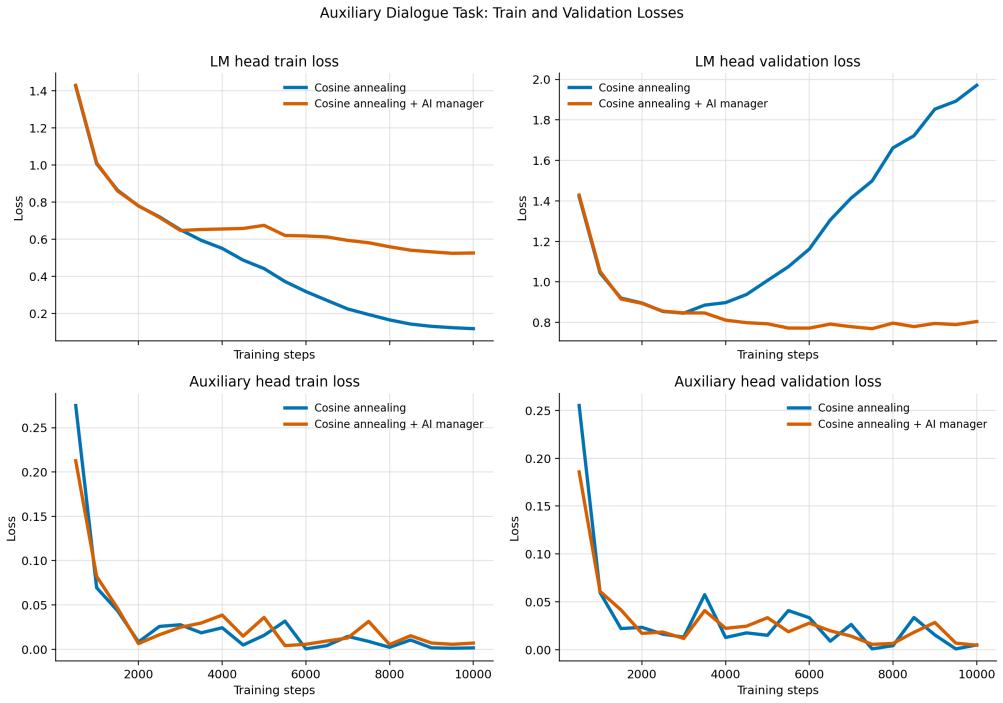
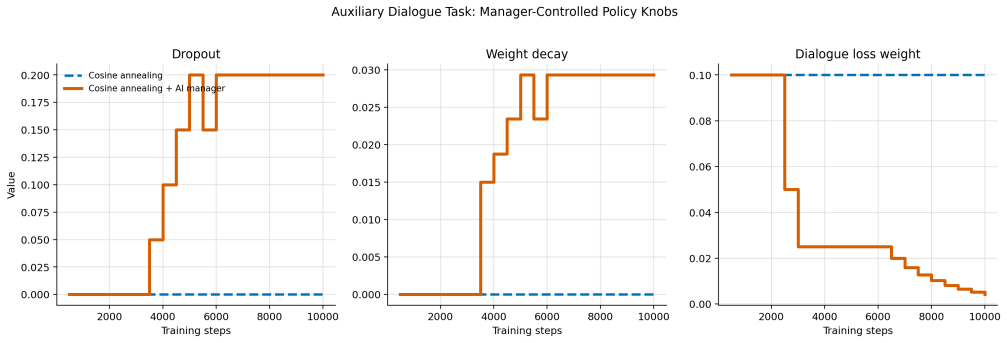
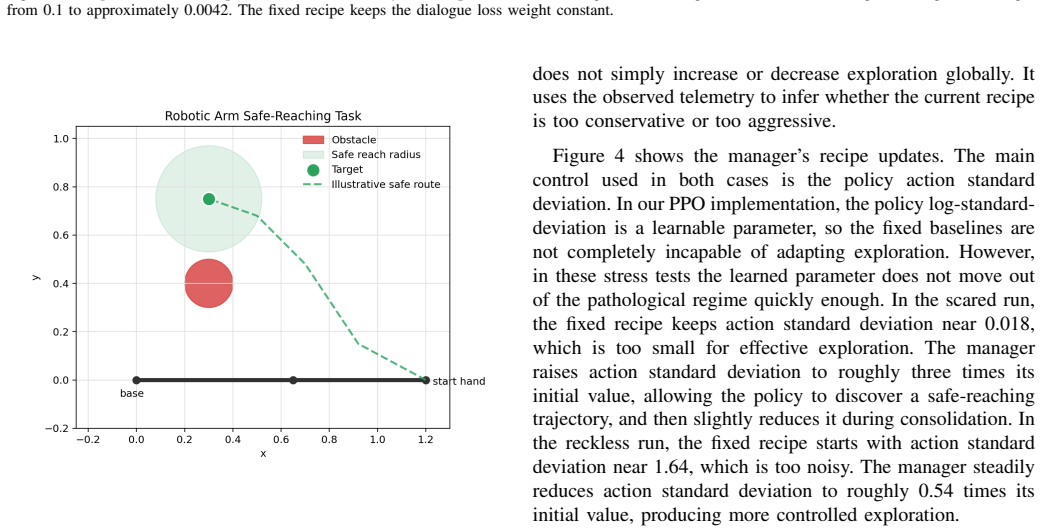
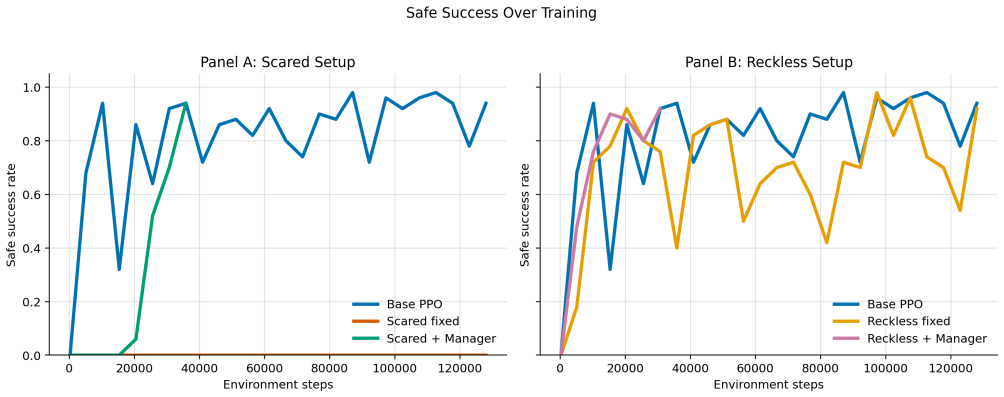
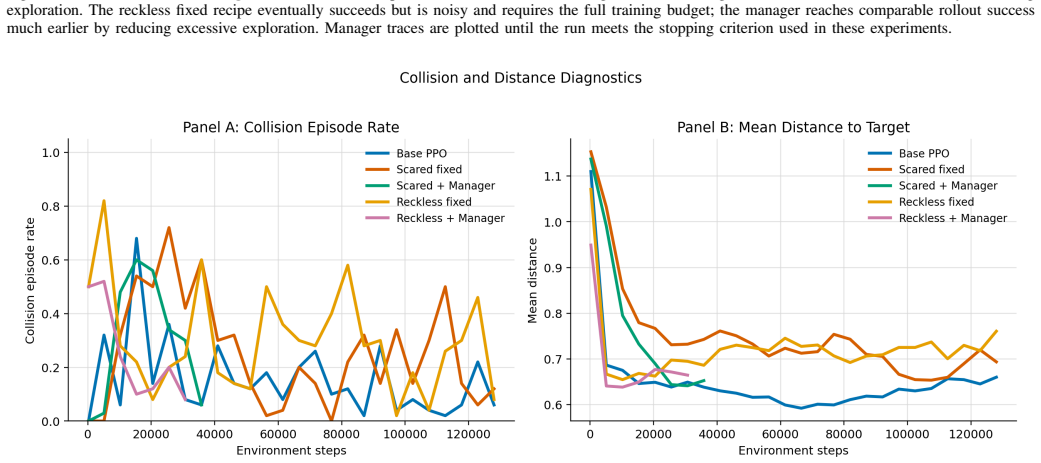
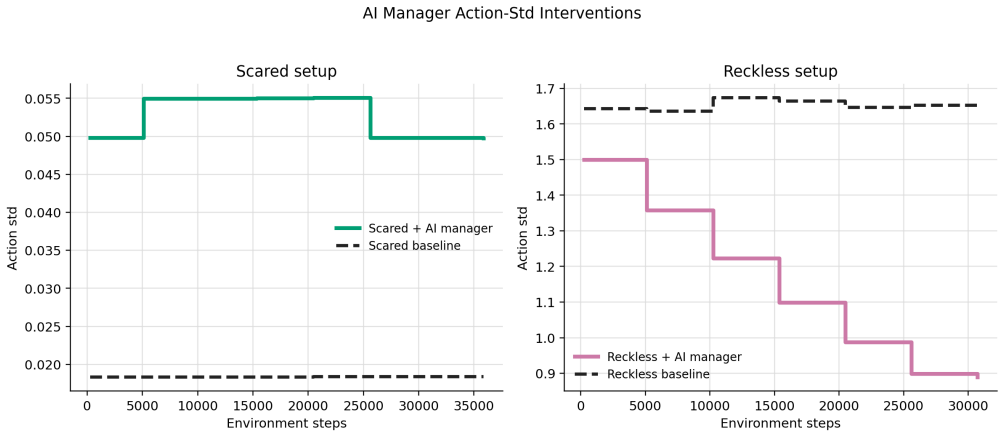
The AI Training Manager operates as a bounded LLM-based supervisory controller that reads structured telemetry snapshots from an active training run, audits a constrained action space, and returns validated updates to parameters including learning rate, regularization strength, loss weights, and exploration settings. On TinyStories this produces a 60 percent lower validation loss than the baseline by detecting and correcting overfitting, with the updates applied asynchronously so training need not pause. The same interface, used episodically at checkpoints in a robotic manipulation reinforcement learning task, mitigates both overly conservative and unsafe exploration regimes while generating
What carries the argument
The schema-conditioned interface, which forces the LLM to consume telemetry snapshots and emit only updates that pass through a predefined constrained action space.
If this is right
- Training can continue without blocking while a manager response is pending, with validated updates applied asynchronously when available.
- The same bounded decision interface works for both supervised language modeling and episodic reinforcement learning at evaluation or checkpoint boundaries.
- Manager interventions generate auditable logs that document every parameter change made during the run.
- Overfitting can be detected and corrected mid-run, and exploration regimes can be shifted away from both conservative and unsafe behaviors.
Where Pith is reading between the lines
- The approach could be tested on larger models or longer training runs to check whether the same constraint schema remains sufficient.
- Combining the manager with conventional schedulers might allow routine adjustments to stay automated while the LLM handles only exceptional cases.
- Extending the telemetry schema to include new signals could support control over additional training axes not examined in the current experiments.
Load-bearing premise
The schema-conditioned LLM can reliably interpret telemetry snapshots and select safe, effective parameter updates without domain-specific fine-tuning or introducing errors that the constraints fail to catch.
What would settle it
A controlled run on TinyStories or the robotic task in which the manager's updates produce higher validation loss or unsafe exploration states even after the constraint checks are applied.
Figures
read the original abstract
We present the AI Training Manager, a bounded LLM-based supervisory controller for adaptive machine learning training. Standard training pipelines often rely on fixed recipes or single-axis schedulers, which can struggle with mid-run failures such as severe overfitting, loss imbalance, exploration collapse, or unsafe exploration. Rather than replacing mathematical optimizers or acting as an unconstrained coding agent, the manager operates through a schema-conditioned interface: it reads structured telemetry snapshots from an active run, audits a constrained action space, and returns validated updates to training parameters such as learning rate, regularization strength, loss-weight coefficients, and exploration settings. We evaluate this architecture across supervised language modeling and reinforcement learning. On TinyStories, the manager detects and corrects overfitting, achieving a validation loss 60% lower than the baseline while producing auditable intervention logs. In this supervised setting, we additionally show that manager inference does not need to block the training loop: training can continue while a manager response is pending, and validated updates can be applied asynchronously once available. In a robotic manipulation reinforcement-learning task, we use the same bounded decision interface in an episodic closed-loop setting, where manager updates are applied at evaluation or checkpoint boundaries. The manager mitigates both conservative and unsafe exploration regimes. These results suggest that schema-conditioned LLMs can serve as bounded supervisory managers for live training runs, complementing conventional optimizers and schedulers with interpretable, multi-axis intervention capabilities
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the AI Training Manager, a schema-conditioned LLM acting as a bounded closed-loop supervisory controller for adaptive ML training. It reads structured telemetry snapshots, audits a constrained action space, and outputs validated updates to parameters including learning rate, regularization strength, loss weights, and exploration settings. The central claim is that on TinyStories the manager detects and corrects overfitting to achieve 60% lower validation loss than baseline while generating auditable logs; asynchronous updates are shown in the supervised case, and the same interface mitigates conservative/unsafe exploration in a robotic RL task.
Significance. If substantiated, the work would demonstrate that off-the-shelf LLMs can function as interpretable, multi-axis supervisory controllers within training loops, complementing mathematical optimizers with bounded, auditable interventions. The schema-conditioning and explicit action-space constraints are presented as mechanisms that keep the LLM within safe operating bounds without domain-specific fine-tuning.
major comments (3)
- [Abstract] Abstract: the claim of a 60% lower validation loss on TinyStories is stated without any experimental details (baseline definition, number of runs, statistical measures, controls for prompt sensitivity, or implementation of the constraint validator), leaving the central empirical result unsupported.
- [Abstract] Abstract: no evidence is supplied on failure modes of the LLM interpreter (e.g., updates that pass validation yet fail to reduce overfitting) or on whether the observed gain exceeds what a simple rule-based scheduler could achieve, which is load-bearing for the claim that the schema-conditioned LLM provides reliable supervisory capability.
- [Abstract] Abstract: the assumption that the LLM can reliably map telemetry snapshots to safe, effective parameter updates without domain-specific fine-tuning is asserted but not tested or evidenced in the reported results.
minor comments (2)
- The abstract mentions 'supervised language modeling and reinforcement learning' evaluations but does not name the precise models, datasets beyond TinyStories, or RL environment details.
- Clarification on whether the constraint validator performs only syntactic checks or also semantic safety checks would strengthen the bounded-control description.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the abstract's presentation of our central empirical claims. We address each comment below and commit to revisions that strengthen the abstract and related sections without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 60% lower validation loss on TinyStories is stated without any experimental details (baseline definition, number of runs, statistical measures, controls for prompt sensitivity, or implementation of the constraint validator), leaving the central empirical result unsupported.
Authors: The abstract is a concise summary, but we agree it should better support the claim. The full manuscript details the baseline (fixed-recipe training with constant LR), results over 5 independent runs with mean/std, prompt sensitivity controls via fixed prompt templates, and the constraint validator (Pydantic schema enforcement) in Section 4.1 and Appendix B. We will revise the abstract to include a brief parenthetical on the experimental setup and controls. revision: yes
-
Referee: [Abstract] Abstract: no evidence is supplied on failure modes of the LLM interpreter (e.g., updates that pass validation yet fail to reduce overfitting) or on whether the observed gain exceeds what a simple rule-based scheduler could achieve, which is load-bearing for the claim that the schema-conditioned LLM provides reliable supervisory capability.
Authors: We acknowledge these are important for substantiating the LLM's added value. The current results focus on demonstrated successes, but we will add a new paragraph in the discussion section addressing observed failure modes (e.g., cases of noisy telemetry leading to ineffective updates) and include a direct comparison experiment against a rule-based scheduler (validation-loss plateau detection for LR adjustment) in the revised experiments. revision: yes
-
Referee: [Abstract] Abstract: the assumption that the LLM can reliably map telemetry snapshots to safe, effective parameter updates without domain-specific fine-tuning is asserted but not tested or evidenced in the reported results.
Authors: The experiments in Sections 4.1 (TinyStories) and 4.2 (robotic RL) directly test this by using an off-the-shelf LLM with only schema conditioning and no fine-tuning, applying it to live telemetry and showing effective, bounded interventions that correct overfitting and exploration issues. We will revise the abstract to explicitly note that these results provide evidence for the assumption in the evaluated domains. revision: partial
Circularity Check
No circularity: empirical claims rest on reported experimental outcomes with no derivations or self-referential fits
full rationale
The paper presents an LLM-based supervisory controller architecture and reports empirical results on TinyStories (60% validation loss reduction) and a robotic RL task. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims are grounded in observed intervention logs and performance metrics rather than any self-definitional reduction or ansatz smuggled via prior work. The architecture is described as schema-conditioned with bounded actions, but the central results are presented as direct experimental findings without circular construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Schema-conditioned LLMs can interpret training telemetry and produce validated parameter updates that improve outcomes without external fine-tuning.
invented entities (1)
-
AI Training Manager
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Loshchilov, I., & Hutter, F. (2017). SGDR: Stochastic Gradient Descent with Warm Restarts.International Conference on Learning Represen- tations (ICLR)
2017
-
[2]
Bengio, Y ., Louradour, J., Collobert, R., & Weston, J. (2009). Curricu- lum learning.Proceedings of the 26th Annual International Conference on Machine Learning (ICML), 41–48
2009
-
[3]
Kendall, A., Gal, Y ., & Cipolla, R. (2018). Multi-task learning using un- certainty to weigh losses for scene geometry and semantics.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 7482–7491
2018
-
[4]
Chen, Z., Badrinarayanan, V ., Lee, C.-Y ., & Rabinovich, A. (2018). GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks.Proceedings of the 35th International Conference on Machine Learning (ICML), 794–803
2018
-
[5]
Snoek, J., Larochelle, H., & Adams, R. P. (2012). Practical Bayesian optimization of machine learning algorithms.Advances in Neural Information Processing Systems (NeurIPS), 25
2012
-
[6]
Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A., & Talwalkar, A. (2018). Hyperband: A novel bandit-based approach to hyperparameter optimization.Journal of Machine Learning Research, 18(185), 1–52
2018
-
[7]
Population Based Training of Neural Networks
Jaderberg, M., Dalibard, V ., Osindero, S., Czarnecki, W. M., Donahue, J., Razavi, A., Vinyals, O., Green, T., Dunning, I., Simonyan, K., Fernando, C., & Kavukcuoglu, K. (2017). Population based training of neural networks.arXiv preprint arXiv:1711.09846
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Adriaensen, S., Biedenkapp, A., Shala, G., Awad, N., Eimer, T., Lindauer, M., & Hutter, F. (2022). Automated dynamic algorithm configuration.Journal of Artificial Intelligence Research, 75, 1633– 1699
2022
-
[9]
Parker-Holder, J., Rajan, R., Song, X., Biedenkapp, A., Miao, Y ., Eimer, T., Zhang, B., Nguyen, V ., Calandra, R., Faust, A., Hutter, F., & Lindauer, M. (2022). Automated reinforcement learning (AutoRL): A survey and open problems.Journal of Artificial Intelligence Research, 74, 517–568
2022
-
[10]
Mohan, A., Benjamins, C., Wienecke, K., Dockhorn, A., & Lindauer, M. (2023). AutoRL hyperparameter landscapes.Proceedings of the Second International Conference on Automated Machine Learning, PMLR 224, 13/1–27
2023
-
[11]
Garc’ia, J., & Fern’andez, F. (2015). A comprehensive survey on safe reinforcement learning.Journal of Machine Learning Research, 16(42), 1437–1480
2015
-
[12]
Achiam, J., Held, D., Tamar, A., & Abbeel, P. (2017). Constrained policy optimization.Proceedings of the 34th International Conference on Machine Learning (ICML), 22–31
2017
-
[13]
W., Pfau, D., Schaul, T., Shillingford, B., & de Freitas, N
Andrychowicz, M., Denil, M., Gomez, S., Hoffman, M. W., Pfau, D., Schaul, T., Shillingford, B., & de Freitas, N. (2016). Learning to learn by gradient descent by gradient descent.Advances in Neural Information Processing Systems (NeurIPS), 29
2016
-
[14]
Li, K., & Malik, J. (2016). Learning to optimize.arXiv preprint arXiv:1606.01885
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
Bello, I., Zoph, B., Vasudevan, V ., & Le, Q. V . (2017). Neural optimizer search with reinforcement learning.Proceedings of the 34th International Conference on Machine Learning (ICML), 459–468
2017
-
[16]
Metz, L., Harrison, J., Freeman, C. D., Merchant, A., Beyer, L., Bradbury, J., Agrawal, N., Poole, B., Mordatch, I., Roberts, A., & Sohl- Dickstein, J. (2022). VeLO: Training versatile learned optimizers by scaling up.arXiv preprint arXiv:2211.09760
-
[17]
Lan, Q., Mahmood, A. R., Yan, S., & Xu, Z. (2023). Learning to optimize for reinforcement learning.arXiv preprint arXiv:2302.01470
-
[18]
Large Language Models as Optimizers
Yang, C., Wang, X., Lu, Y ., Liu, H., Le, Q. V ., Zhou, D., & Chen, X. (2023). Large language models as optimizers.arXiv preprint arXiv:2309.03409
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
R., Desai, N., Bae, J., Lorraine, J., & Ba, J
Zhang, M. R., Desai, N., Bae, J., Lorraine, J., & Ba, J. (2023). Using large language models for hyperparameter optimization.arXiv preprint arXiv:2312.04528
- [20]
- [21]
-
[22]
Wang, G., Xie, Y ., Jiang, Y ., Mandlekar, A., Xiao, C., Zhu, Y ., Fan, L., & Anandkumar, A. (2023). V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Lu, C., Lu, C., Lange, R. T., Foerster, J., Clune, J., & Ha, D. (2024). The AI Scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
S., Hutter, F., & Doerr, C
Biedenkapp, A., Dang, N., Krejca, M. S., Hutter, F., & Doerr, C. (2022). Theory-inspired parameter control benchmarks for dynamic algorithm configuration.Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), 766–775
2022
-
[25]
Liu, S., Gao, C., & Li, Y . (2025). AgentHPO: Large language model agent for hyper-parameter optimization.Proceedings of the Conference on Parsimony and Learning, PMLR 280, 1146–1169
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.