Flying to Image-Specified Objects: 3D Quadrotor Navigation via Cross-Graph Memory and Viewpoint Planning
Pith reviewed 2026-06-30 05:47 UTC · model grok-4.3
The pith
Quadrotor navigation framework selects viewpoint-aware nodes using semantic memory to reach image-specified objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
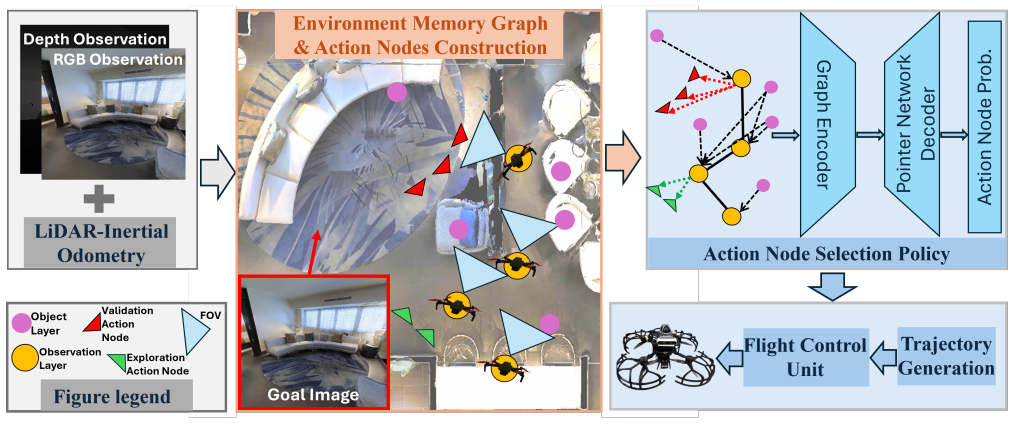
A hierarchical navigation framework for quadrotor InstanceImageNav separates high-level decision making from low-level motion execution by generating viewpoint-aware action nodes around frontier regions and potential target objects, maintains a lightweight semantic memory that propagates object-level and observation-level cues to candidate nodes, and employs a learning-based policy to select the most promising node for execution via a trajectory planner.
What carries the argument
Viewpoint-aware action nodes around frontiers and objects together with cross-graph semantic memory that propagates cues for policy selection.
If this is right
- The system produces higher success rates than prior methods on InstanceImageNav benchmarks in simulation.
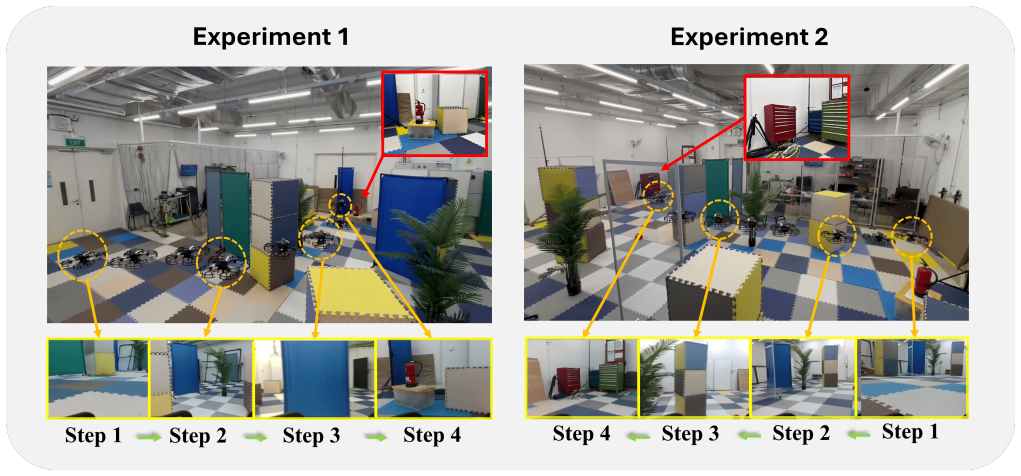
- Real quadrotor flights confirm the generated paths remain dynamically feasible and collision-free.
- Separating viewpoint selection from motion control allows the robot to explore while keeping the target likely visible.
- The memory structure supports decision making without storing full maps or dense point clouds.
Where Pith is reading between the lines
- The same node-and-memory structure could be tested on other camera-equipped flying robots that must inspect specific objects.
- Adding explicit uncertainty estimates to the memory cues might reduce failures when the target is partially occluded.
- Running the policy at lower frequency while keeping the planner fast could lower onboard compute without losing navigation performance.
Load-bearing premise
Generating viewpoint-aware nodes near frontiers and objects plus propagating semantic cues through memory is enough for a learning policy to choose viewpoints that detect the target reliably under continuous 3D motion, narrow camera view, and obstacle avoidance.
What would settle it
Repeated trials in which the quadrotor reaches the target image object in fewer than half the episodes under varied lighting or obstacle density would show the policy and memory combination does not reliably solve the task.
Figures
read the original abstract
Instance-Specific Image-Goal Navigation (InstanceImageNav) requires a robot to navigate toward the exact object instance depicted in a query image. Extending this task to quadrotors is challenging due to continuous 3D control, limited field of view (FOV), and safety constraints, which make successful navigation highly dependent on selecting informative viewpoints. We propose a hierarchical navigation framework for quadrotor InstanceImageNav that separates high-level decision making from low-level motion execution. Instead of navigating directly to spatial locations, the system generates viewpoint-aware action nodes around frontier regions and potential target objects, enabling the robot to explore while maintaining informative viewpoints for detecting the target instance. A lightweight semantic memory maintains object-level and observation-level context, allowing semantic cues to propagate to candidate action nodes for decision making. A learning-based policy selects the most promising action node, and a trajectory planner generates dynamically feasible 3D flight paths for safe execution. Experiments in simulation demonstrate consistent improvements over strong baselines, and real-world quadrotor flights validate the practicality and robustness of the proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hierarchical navigation framework for quadrotor InstanceImageNav that decouples high-level viewpoint selection—via generation of viewpoint-aware action nodes around frontiers and potential target objects, combined with a lightweight semantic (cross-graph) memory for propagating object- and observation-level cues—from low-level dynamically feasible trajectory planning. A learning-based policy selects among the action nodes, with claims of consistent improvements over strong baselines in simulation and successful real-world validation on physical quadrotors under continuous 3D control, limited FOV, and safety constraints.
Significance. If the quantitative claims hold with proper metrics and ablations, the separation of viewpoint planning from motion execution could meaningfully advance practical InstanceImageNav for aerial platforms, where FOV and safety constraints make direct navigation unreliable. The use of semantic memory propagation to candidate nodes is a plausible mechanism for improving informativeness, but its impact remains unverified without supporting data.
major comments (3)
- Abstract: the central claim of 'consistent improvements over strong baselines' and 'real-world validation' is asserted without any quantitative results, success rates, error bars, baseline names, or statistical details. This directly undermines assessment of whether the learning-based policy reliably selects informative viewpoints under the stated constraints.
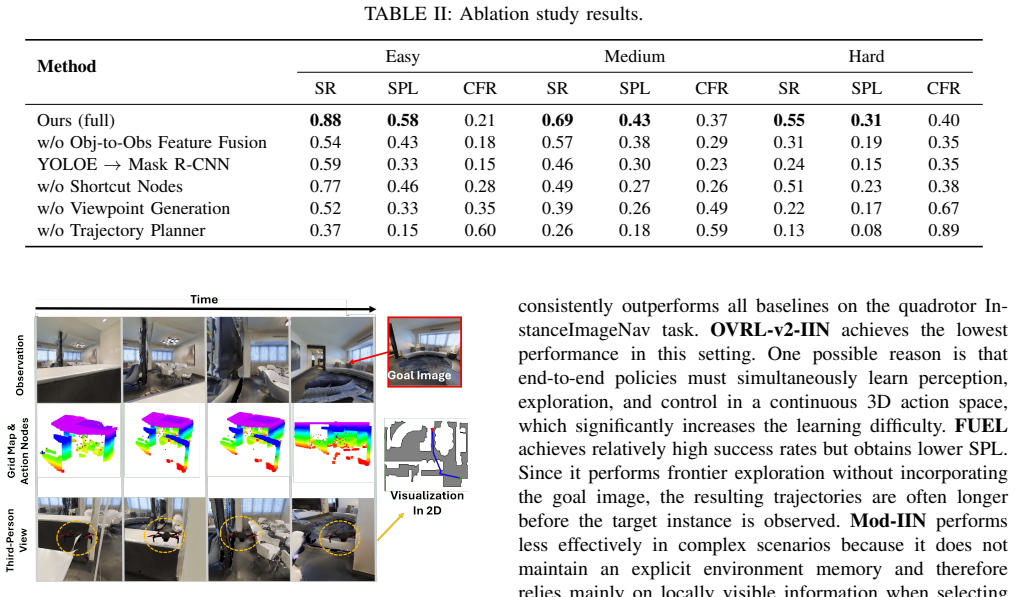
- §5 (Experiments): no details are supplied on policy training procedure, ablation studies isolating the cross-graph memory or viewpoint node generation, or the precise metrics used to demonstrate superiority. Without these, the claim that the framework enables reliable target detection cannot be evaluated.
- §4.3 (Policy): the description of how the learning-based policy selects among viewpoint-aware nodes lacks specification of the observation space, reward function, or training environment, which are load-bearing for the assertion that the policy improves viewpoint informativeness over baselines.
minor comments (2)
- The abstract refers to 'lightweight semantic memory' while the title uses 'Cross-Graph Memory'; consistent terminology and a brief definition on first use would improve clarity.
- Figure captions and axis labels in the experimental results should explicitly state the number of trials and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the manuscript would benefit from additional quantitative and methodological details to support the claims and will revise accordingly.
read point-by-point responses
-
Referee: Abstract: the central claim of 'consistent improvements over strong baselines' and 'real-world validation' is asserted without any quantitative results, success rates, error bars, baseline names, or statistical details. This directly undermines assessment of whether the learning-based policy reliably selects informative viewpoints under the stated constraints.
Authors: We acknowledge that the abstract summarizes contributions without specific numbers. In the revision we will add key quantitative results including success rates, baseline names, and statistical details to better support the claims. revision: yes
-
Referee: §5 (Experiments): no details are supplied on policy training procedure, ablation studies isolating the cross-graph memory or viewpoint node generation, or the precise metrics used to demonstrate superiority. Without these, the claim that the framework enables reliable target detection cannot be evaluated.
Authors: We will expand §5 with details on the policy training procedure, ablation studies isolating the cross-graph memory and viewpoint node generation, and the precise metrics used. revision: yes
-
Referee: §4.3 (Policy): the description of how the learning-based policy selects among viewpoint-aware nodes lacks specification of the observation space, reward function, or training environment, which are load-bearing for the assertion that the policy improves viewpoint informativeness over baselines.
Authors: We will expand §4.3 to specify the observation space, reward function, and training environment for the learning-based policy. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript presents a hierarchical navigation system for quadrotor InstanceImageNav consisting of viewpoint-aware action nodes, cross-graph semantic memory, a learning-based policy, and a trajectory planner. No equations, parameter-fitting procedures, or derivation chains appear in the provided text. All load-bearing claims rest on empirical validation against external baselines in simulation and real-world flights rather than on any self-referential construction, self-citation of uniqueness theorems, or renaming of known results. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
E., Hasegawa, S., and Taniguchi, T
Sakaguchi, T., Taniguchi, A., Hagiwara, Y ., Hafi, L. E., Hasegawa, S., and Taniguchi, T. (2024). Real-world Instance-specific Image Goal Navigation for Service Robots: Bridging the Domain Gap with Contrastive Learning. arXiv preprint arXiv:2404.09645
-
[2]
Autonomous visual naviga- tion of unmanned aerial vehicle for wind turbine inspection[C]//2015 International Conference on Unmanned Aircraft Systems (ICUAS)
Stokkeland M, Klausen K, Johansen T A. Autonomous visual naviga- tion of unmanned aerial vehicle for wind turbine inspection[C]//2015 International Conference on Unmanned Aircraft Systems (ICUAS). IEEE, 2015: 998-1007
2015
-
[3]
Collaborative target search with a visual drone swarm: An adaptive curriculum embedded multistage reinforcement learning approach[J]
Xiao J, Pisutsin P, Feroskhan M. Collaborative target search with a visual drone swarm: An adaptive curriculum embedded multistage reinforcement learning approach[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023
2023
- [4]
-
[5]
Instance-aware Exploration- Verification-Exploitation for Instance ImageGoal Naviga- tion[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lei X, Wang M, Zhou W, et al. Instance-aware Exploration- Verification-Exploitation for Instance ImageGoal Naviga- tion[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 16329-16339
2024
-
[6]
Last-mile embodied visual navigation[C]//Conference on Robot Learning
Wasserman J, Yadav K, Chowdhary G, et al. Last-mile embodied visual navigation[C]//Conference on Robot Learning. PMLR, 2023: 666-678
2023
-
[7]
FGPrompt: fine-grained goal prompting for image-goal navigation[J]
Sun X, Chen P, Fan J, et al. FGPrompt: fine-grained goal prompting for image-goal navigation[J]. Advances in Neural Information Processing Systems, 2024, 36
2024
-
[8]
Topological semantic graph memory for image-goal navigation[C]//Conference on Robot Learning
Kim N, Kwon O, Yoo H, et al. Topological semantic graph memory for image-goal navigation[C]//Conference on Robot Learning. PMLR, 2023: 393-402
2023
-
[9]
RGBD-based Image Goal Navigation with Pose Drift: A Topo-metric Graph based Approach[C]//2024 IEEE International Conference on Robotics and Automation (ICRA)
Ye S, Cui Y , Sha H, et al. RGBD-based Image Goal Navigation with Pose Drift: A Topo-metric Graph based Approach[C]//2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024: 18391-18397
2024
-
[10]
SIGN: Safety-Aware Image-Goal Navigation for Autonomous Drones via Reinforcement Learning[J]
Yan Z, Huang R, He L, et al. SIGN: Safety-Aware Image-Goal Navigation for Autonomous Drones via Reinforcement Learning[J]. arXiv preprint arXiv:2508.12394, 2025
-
[11]
Navigating to objects in the real world[J]
Gervet T, Chintala S, Batra D, et al. Navigating to objects in the real world[J]. Science Robotics, 2023, 8(79): eadf6991
2023
-
[12]
Image-goal navigation in complex environments via modular learning[J]
Wu Q, Wang J, Liang J, et al. Image-goal navigation in complex environments via modular learning[J]. IEEE Robotics and Automation Letters, 2022, 7(3): 6902-6909
2022
-
[13]
Neural topological slam for visual navigation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chaplot D S, Salakhutdinov R, Gupta A, et al. Neural topological slam for visual navigation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 12875-12884
2020
-
[14]
Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav[J]
Yadav K, Majumdar A, Ramrakhya R, et al. Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav[J]. arXiv preprint arXiv:2303.07798, 2023
-
[15]
A Behavioral Approach to Visual Navigation with Graph Localization Networks
Chen, K., De Vicente, J. P., Sepulveda, G., Xia, F., Soto, A., V´azquez, M., and Savarese, S. (2019). A behavioral approach to visual navigation with graph localization networks. arXiv preprint arXiv:1903.00445
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[16]
Ving: Learning open-world navigation with visual goals[C]//2021 IEEE International Conference on Robotics and Automation (ICRA)
Shah D, Eysenbach B, Kahn G, et al. Ving: Learning open-world navigation with visual goals[C]//2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021: 13215-13222
2021
-
[17]
Placenav: Topological navigation through place recognition[C]//2024 IEEE International Conference on Robotics and Automation (ICRA)
Suomela L, Kalliola J, Edelman H, et al. Placenav: Topological navigation through place recognition[C]//2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024: 5205- 5213
2024
-
[18]
Frontier-based exploration using multiple robots[C]//Proceedings of the second international conference on Autonomous agents
Yamauchi B. Frontier-based exploration using multiple robots[C]//Proceedings of the second international conference on Autonomous agents. 1998: 47-53
1998
-
[19]
Fuel: Fast uav exploration using incre- mental frontier structure and hierarchical planning[J]
Zhou B, Zhang Y , Chen X, et al. Fuel: Fast uav exploration using incre- mental frontier structure and hierarchical planning[J]. IEEE Robotics and Automation Letters, 2021, 6(2): 779-786
2021
-
[20]
Thda: Treasure hunt data augmentation for semantic navigation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision
Maksymets O, Cartillier V , Gokaslan A, et al. Thda: Treasure hunt data augmentation for semantic navigation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 15374-15383
2021
-
[21]
End-to-end (instance)- image goal navigation through correspondence as an emergent phe- nomenon[J]
Bono G, Antsfeld L, Chidlovskii B, et al. End-to-end (instance)- image goal navigation through correspondence as an emergent phe- nomenon[J]. arXiv preprint arXiv:2309.16634, 2023
-
[22]
Memory-augmented re- inforcement learning for image-goal navigation[C]//2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Mezghan L, Sukhbaatar S, Lavril T, et al. Memory-augmented re- inforcement learning for image-goal navigation[C]//2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022: 3316-3323
2022
-
[23]
Poni: Poten- tial functions for objectgoal navigation with interaction-free learn- ing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ramakrishnan S K, Chaplot D S, Al-Halah Z, et al. Poni: Poten- tial functions for objectgoal navigation with interaction-free learn- ing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 18890-18900
2022
-
[24]
S., Gandhi, D., Gupta, S., Gupta, A., and Salakhutdinov, R
Chaplot, D. S., Gandhi, D., Gupta, S., Gupta, A., and Salakhutdinov, R. (2020). Learning to explore using active neural slam. arXiv preprint arXiv:2004.05155
-
[25]
Chen, T., Gupta, S., and Gupta, A. (2019). Learning exploration policies for navigation. arXiv preprint arXiv:1903.01959
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
Ravichandran Z, Peng L, Hughes N, et al. Hierarchical representa- tions and explicit memory: Learning effective navigation policies on 3d scene graphs using graph neural networks[C]//2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 9272- 9279
2022
-
[27]
Etpnav: Evolving topological planning for vision-language navigation in continuous environments[J]
An D, Wang H, Wang W, et al. Etpnav: Evolving topological planning for vision-language navigation in continuous environments[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[28]
Hierarchical Open-V ocabulary 3D Scene Graphs for Language-Grounded Robot Navigation[C]//First Workshop on Vision-Language Models for Navigation and Manipula- tion at ICRA 2024
Werby A, Huang C, B ¨uchner M, et al. Hierarchical Open-V ocabulary 3D Scene Graphs for Language-Grounded Robot Navigation[C]//First Workshop on Vision-Language Models for Navigation and Manipula- tion at ICRA 2024. 2024
2024
-
[29]
A formal basis for the heuristic determination of minimum cost paths[J]
Hart P E, Nilsson N J, Raphael B. A formal basis for the heuristic determination of minimum cost paths[J]. IEEE transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107
1968
-
[30]
XFeat: Accelerated Features for Lightweight Image Matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Potje G, Cadar F, Araujo A, et al. XFeat: Accelerated Features for Lightweight Image Matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 2682- 2691
2024
-
[31]
Lightglue: Local feature matching at light speed[C]//Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Lindenberger P, Sarlin P E, Pollefeys M. Lightglue: Local feature matching at light speed[C]//Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. 2023: 17627-17638
2023
-
[32]
Proximal Policy Optimization Algorithms
Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Wang Z, Chen J, Chen H. EGAT: Edge-featured graph attention net- work[C]//Artificial Neural Networks and Machine Learning–ICANN 2021: 30th International Conference on Artificial Neural Networks, Bratislava, Slovakia, September 14–17, 2021, Proceedings, Part I 30. Springer International Publishing, 2021: 253-264
2021
-
[34]
Pointer networks[J]
Vinyals O, Fortunato M, Jaitly N. Pointer networks[J]. Advances in neural information processing systems, 2015, 28
2015
-
[35]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Chang A, Dai A, Funkhouser T, et al. Matterport3d: Learn- ing from rgb-d data in indoor environments[J]. arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [36]
-
[37]
Habitat: A platform for embodied ai research[C]//Proceedings of the IEEE/CVF international conference on computer vision
Savva M, Kadian A, Maksymets O, et al. Habitat: A platform for embodied ai research[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 9339-9347
2019
-
[38]
Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision
He K, Gkioxari G, Doll ´ar P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969
2017
-
[39]
J. Li, P. Zhou, C. Xiong, and S. C. Hoi. Prototypical Contrastive Learning of Unsupervised Representations. International Conference on Learning Representations (ICLR), 2021
2021
-
[40]
Yoloe: Real-time seeing anything,
Wang A, Liu L, Chen H, et al. Yoloe: Real-time seeing anything[J]. arXiv preprint arXiv:2503.07465, 2025
-
[41]
Learning transferable visual models from natural language supervision[C]//International conference on machine learning
Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PmLR, 2021: 8748-8763
2021
-
[42]
Navigating to objects specified by images[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision
Krantz J, Gervet T, Yadav K, et al. Navigating to objects specified by images[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 10916-10925
2023
-
[43]
Fast-lio: A fast, robust lidar-inertial odometry pack- age by tightly-coupled iterated kalman filter[J]
Xu W, Zhang F. Fast-lio: A fast, robust lidar-inertial odometry pack- age by tightly-coupled iterated kalman filter[J]. IEEE Robotics and Automation Letters, 2021, 6(2): 3317-3324
2021
-
[44]
Vision-based learning for drones: A survey[J]
Xiao J, Zhang R, Zhang Y , et al. Vision-based learning for drones: A survey[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.