HippoSpark: An On-Demand Experience System for LLM Reasoning
Pith reviewed 2026-06-30 06:22 UTC · model grok-4.3
The pith
HippoSpark retrieves experience on-demand at specific reasoning states to guide LLMs through local bottlenecks, outperforming task-level summaries on math, science, and programming benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
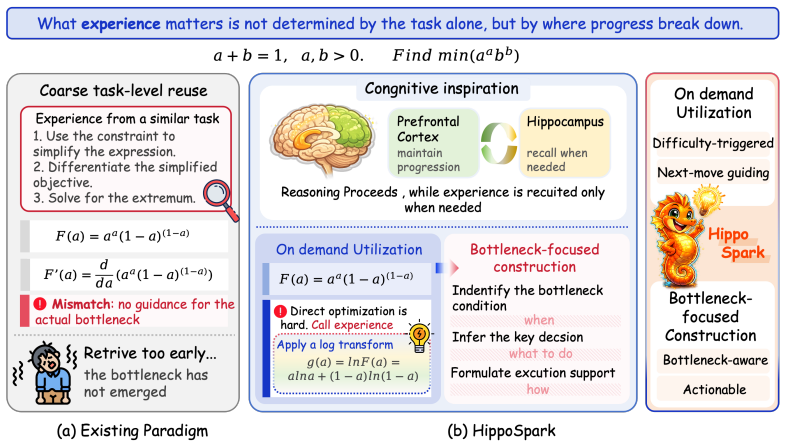
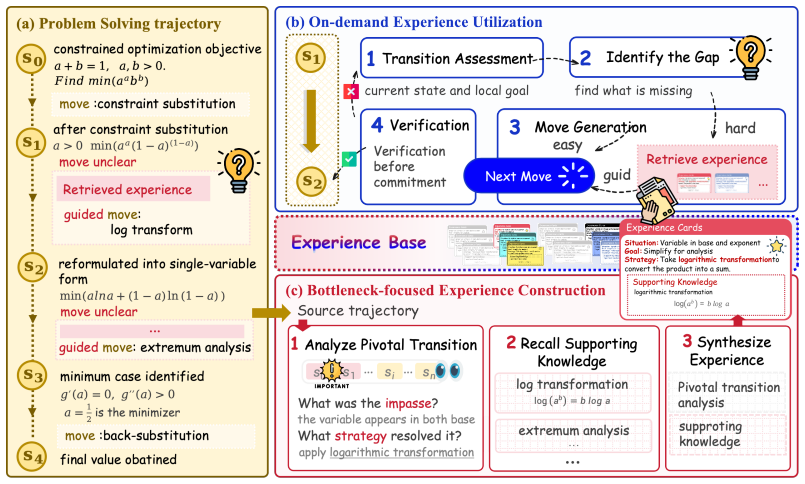
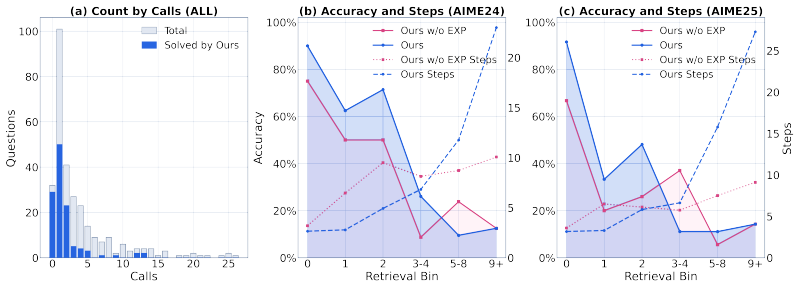
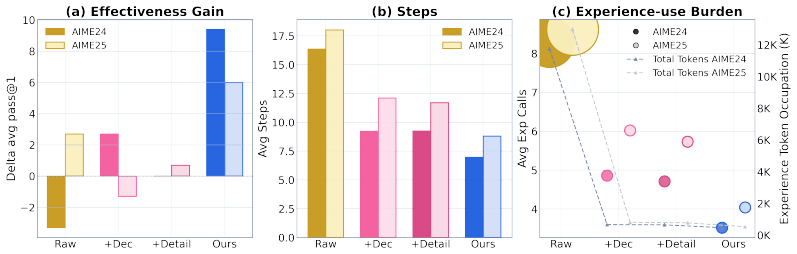
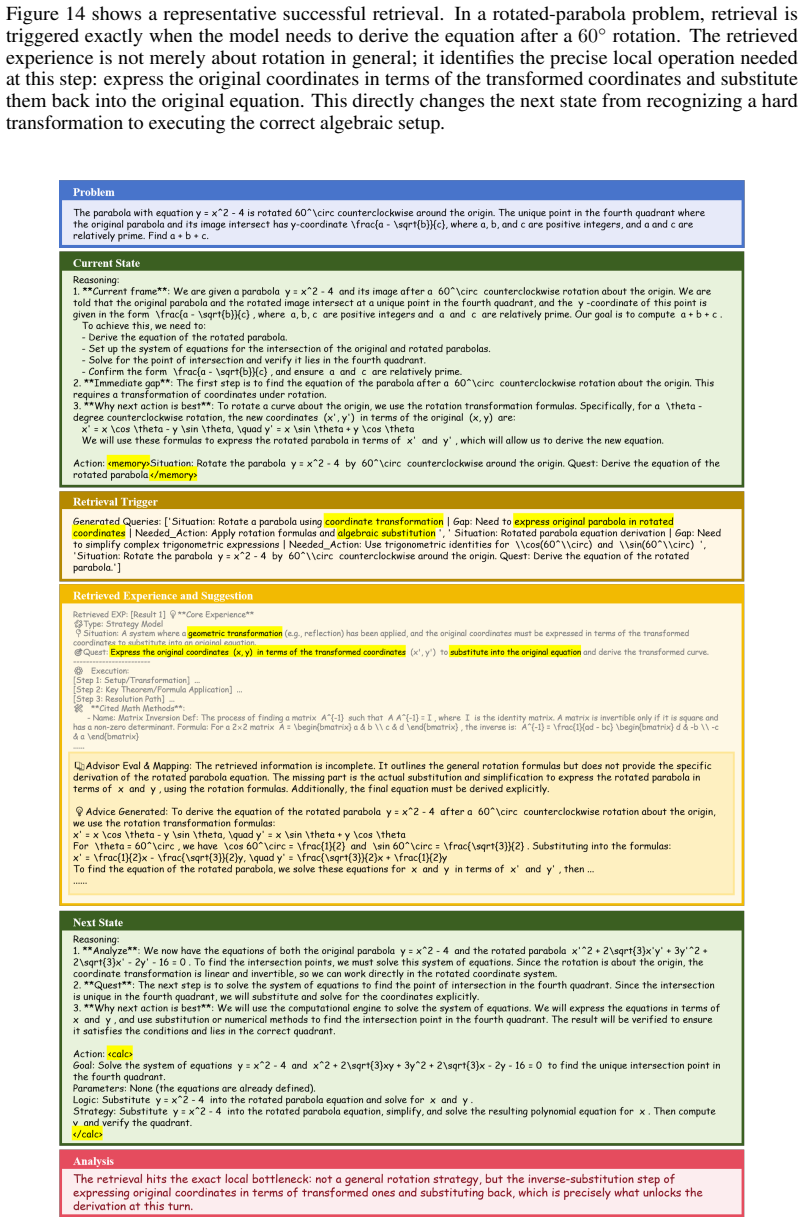
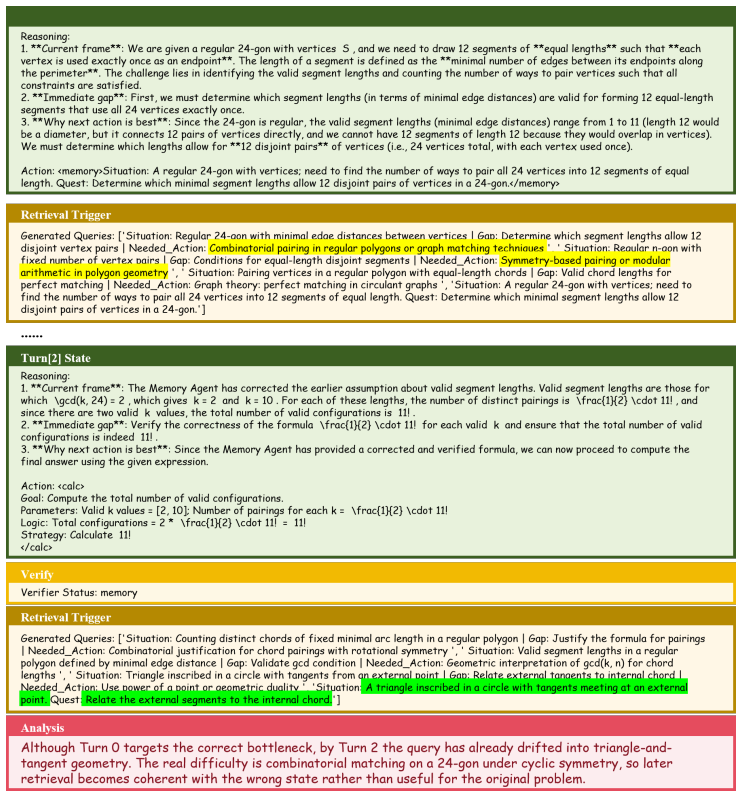
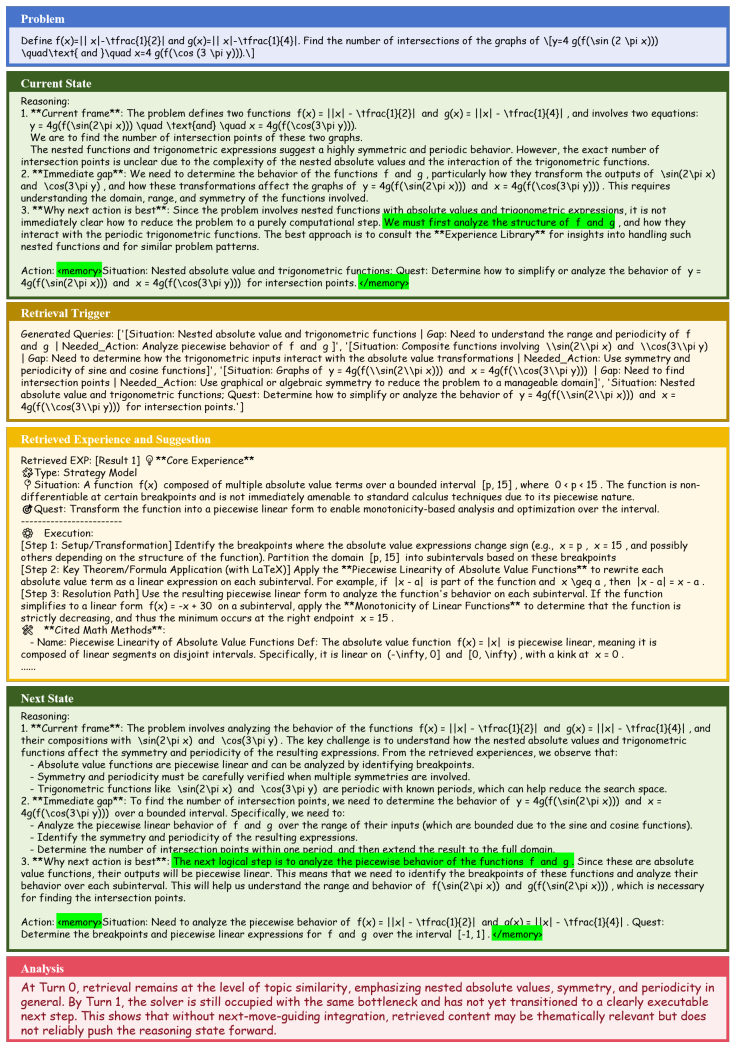
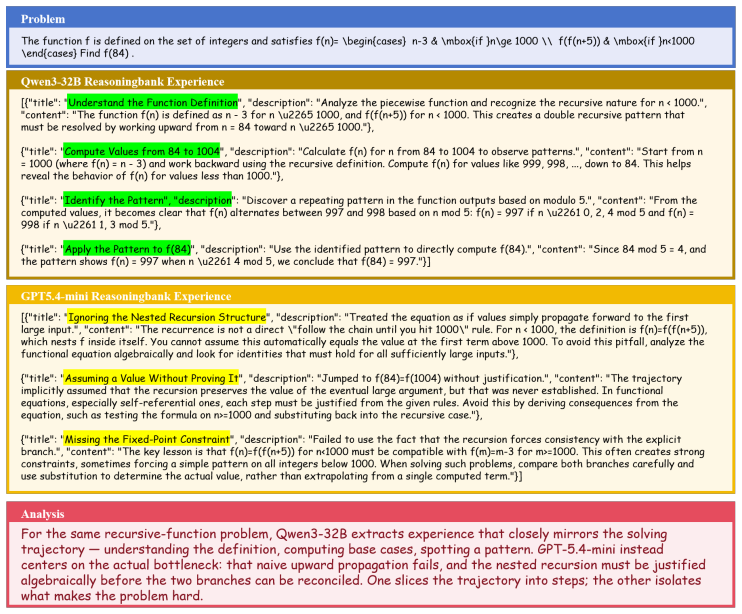
HippoSpark is a state-level experience system that performs on-demand retrieval tailored to the immediate needs of the current reasoning state. Across mathematical, scientific, and programming benchmarks, HippoSpark consistently outperforms both standard prompting and task-level experience baselines. The authors conclude that the most effective experience systems are those that provide actionable guidance at critical bottlenecks rather than serving as generic task-level context.
What carries the argument
State-level on-demand retrieval that matches the current reasoning state to fetch precise, actionable experience instead of broad task summaries.
If this is right
- State-level retrieval addresses bottlenecks that task-level summaries miss.
- On-demand matching to the current reasoning state produces better guidance than pre-stored task patterns.
- Gains appear consistently in mathematical, scientific, and programming domains.
- Effective experience systems prioritize actionable steps at critical points over generic context.
Where Pith is reading between the lines
- The approach implies that reasoning traces could be stored and indexed by intermediate states rather than whole tasks.
- Similar state-level retrieval might apply to domains with sequential decision steps such as planning or code debugging.
- It suggests future systems could monitor reasoning in real time to trigger retrieval only when a bottleneck is detected.
Load-bearing premise
Complex reasoning fails mainly at local bottlenecks where state-specific guidance helps more than broad task-level heuristics.
What would settle it
A controlled test on the same benchmarks where state-level retrieval is replaced by task-level summaries and performance shows no gain or a drop would falsify the claim that on-demand state retrieval drives the improvement.
Figures
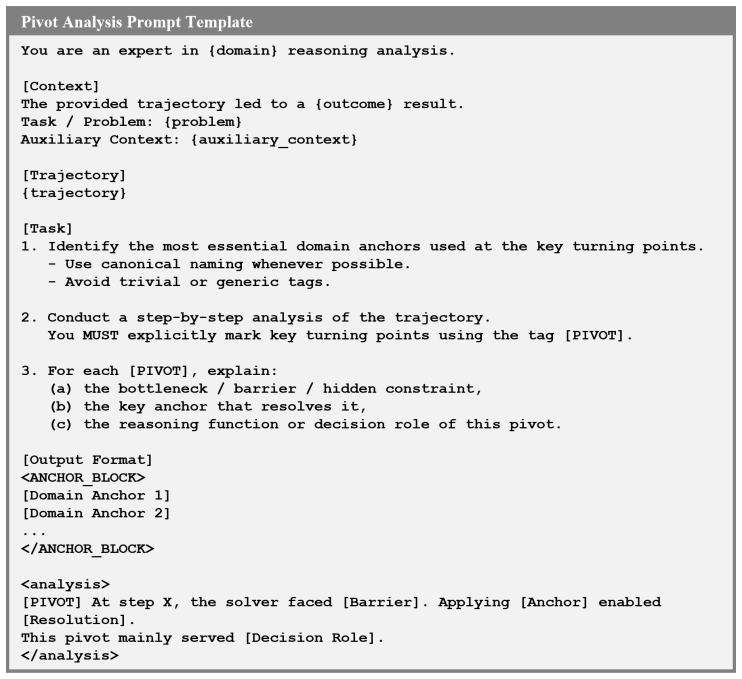
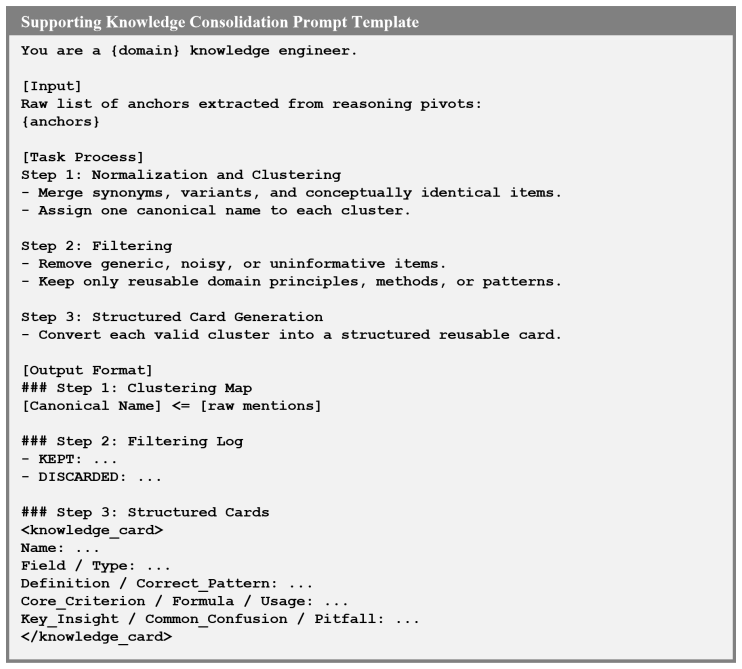
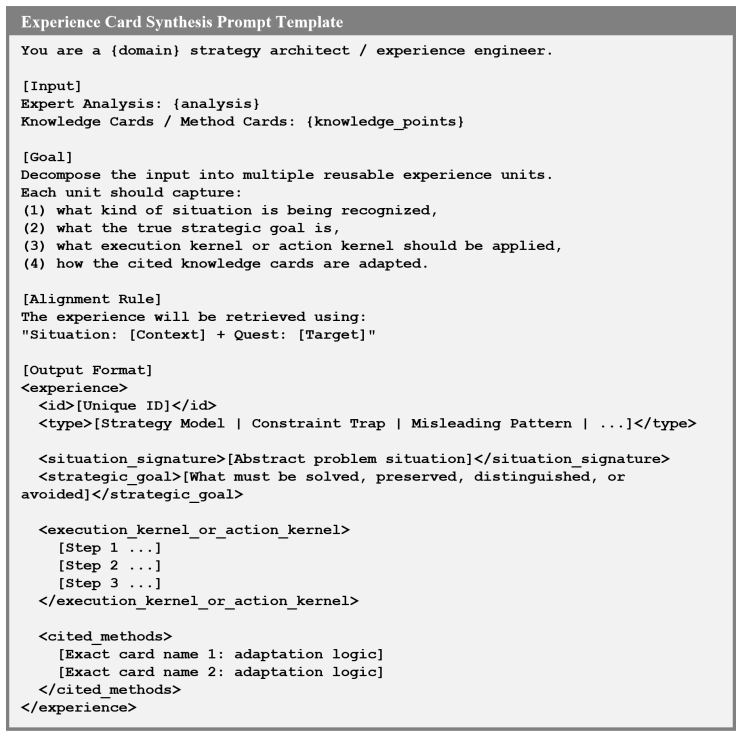
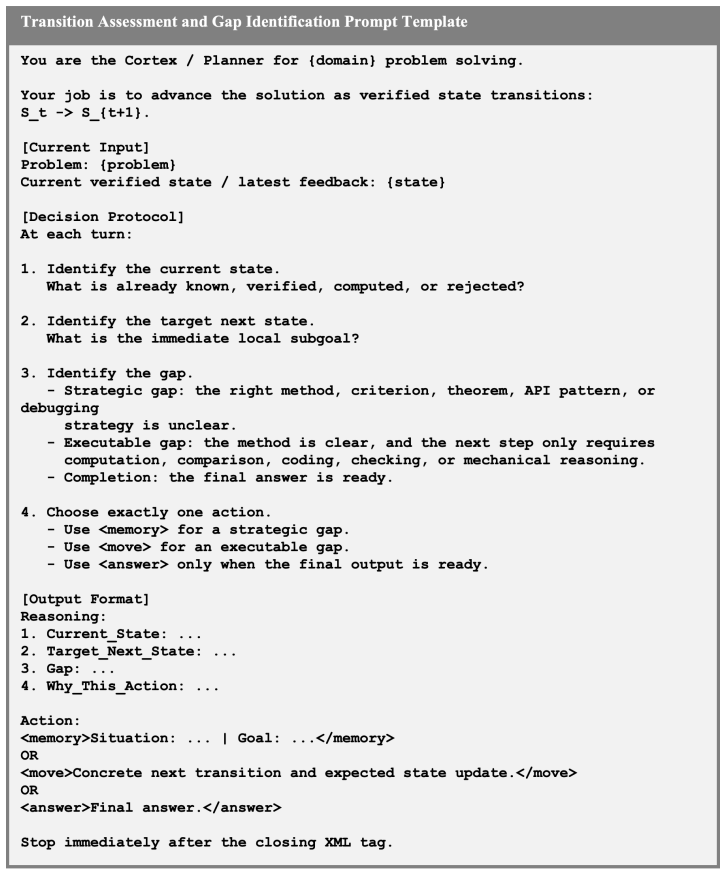











read the original abstract
Distilling historical trajectories into reusable experience to enhance future problem-solving has become a focal point of recent LLM research. However, existing methods predominantly operate at the task level, leveraging general summaries or rules under the assumption that analogous tasks share universal solution patterns. This approach often fails in complex reasoning, which typically falters at local bottlenecks that require precise, state-specific guidance rather than broad heuristics. We introduce HippoSpark, a state-level experience system that performs on-demand retrieval tailored to the immediate needs of the current reasoning state. Across mathematical, scientific, and programming benchmarks, HippoSpark consistently outperforms both standard prompting and task-level experience baselines. Our findings reveal that the most effective experience systems are those that provide actionable guidance at critical bottlenecks rather than serving as generic task-level context. Our code is available at https://github.com/DanlingMeng/HippoSpark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HippoSpark, a state-level experience system for LLM reasoning that performs on-demand retrieval of guidance tailored to the immediate needs of the current reasoning state. It argues that complex reasoning fails at local bottlenecks requiring precise state-specific help rather than broad task-level heuristics or summaries, and claims that HippoSpark consistently outperforms both standard prompting and task-level experience baselines across mathematical, scientific, and programming benchmarks. The work concludes that the most effective experience systems deliver actionable guidance at critical bottlenecks.
Significance. If the empirical claims are supported by rigorous experiments, the result would be significant for LLM reasoning research by shifting emphasis from task-level experience distillation to state-level on-demand retrieval. The public code release supports reproducibility and allows direct testing of the approach.
major comments (2)
- [Abstract] Abstract: the central claim of consistent outperformance on benchmarks is presented without any description of the experimental setup, including which benchmarks were used, how baselines were implemented, what metrics were reported, or any statistical tests for significance; this absence makes the empirical contribution impossible to evaluate.
- [Abstract] Abstract: no technical description of the HippoSpark system is supplied, such as how reasoning states are represented, how on-demand retrieval is triggered or implemented, what experience is stored, or how retrieval differs from task-level methods; these details are load-bearing for the novelty claim.
minor comments (1)
- [Abstract] Abstract: the manuscript provides a GitHub link for code but contains no figures, tables, equations, or pseudocode that would normally accompany a methods or results claim.
Simulated Author's Rebuttal
We thank the referee for these comments on the abstract. The full technical and experimental details appear in the body of the manuscript, but we agree the abstract can be strengthened for standalone readability and will revise it accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent outperformance on benchmarks is presented without any description of the experimental setup, including which benchmarks were used, how baselines were implemented, what metrics were reported, or any statistical tests for significance; this absence makes the empirical contribution impossible to evaluate.
Authors: The abstract is written at a high level per conventional length constraints. The Experiments section of the manuscript fully specifies the benchmarks (mathematical, scientific, and programming), baseline implementations (task-level experience methods), metrics, and statistical testing procedures. We will revise the abstract to add a short clause noting the evaluation domains and that results include statistical significance testing. revision: yes
-
Referee: [Abstract] Abstract: no technical description of the HippoSpark system is supplied, such as how reasoning states are represented, how on-demand retrieval is triggered or implemented, what experience is stored, or how retrieval differs from task-level methods; these details are load-bearing for the novelty claim.
Authors: The abstract summarizes the core idea. The Method section provides the technical details on state representation, retrieval triggering and implementation, stored experience, and differentiation from task-level approaches. We will revise the abstract to include one additional sentence giving a concise technical characterization of the state-level mechanism. revision: yes
Circularity Check
No significant circularity; purely empirical claims
full rationale
The paper introduces an empirical system (HippoSpark) for state-level experience retrieval in LLM reasoning and reports benchmark outperformance. No equations, derivations, fitted parameters, or load-bearing self-citations appear in the abstract or described structure. Claims rest on external benchmark comparisons that are falsifiable outside the paper's own inputs, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Matharena: Evaluating llms on uncontaminated math competitions
Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions. InNeurIPS Benchmarks and Datasets Track 2025,
2025
-
[2]
Aime 1983–2024 (revision 6283828),
Di Zhang. Aime 1983–2024 (revision 6283828),
1983
-
[3]
Memp: Exploring Agent Procedural Memory
URL https://huggingface.co/ datasets/di-zhang-fdu/AIME_1983_2024. Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Mem p: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Get experience from practice: Llm agents with record & replay
Erhu Feng, Wenbo Zhou, Zibin Liu, Le Chen, Yunpeng Dong, Cheng Zhang, Yisheng Zhao, Dong Du, Zhichao Hua, Yubin Xia, et al. Get experience from practice: Llm agents with record & replay. arXiv preprint arXiv:2505.17716,
-
[5]
Retrieval-augmented llm agents: Learning to learn from experience
Thomas Palmeira Ferraz, Romain Deffayet, Vassilina Nikoulina, Hervé Déjean, and Stéphane Clinchant. Retrieval-augmented llm agents: Learning to learn from experience. InICLR 2026 Workshop on Memory for LLM-Based Agentic Systems,
2026
-
[6]
doi: 10.1207/s15516709cog0702_3. Mary L. Gick and Keith J. Holyoak. Analogical problem solving.Cognitive Psychology, 12(3): 306–355,
-
[7]
doi: 10.1016/0010-0285(80)90013-4. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638,
-
[8]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Aime-24: American invitational mathematics examination 2024 benchmark
HuggingFaceH4. Aime-24: American invitational mathematics examination 2024 benchmark. https://huggingface.co/datasets/HuggingFaceH4/aime_2024,
2024
-
[10]
HuggingFaceH4
Accessed: 2025- 09-10. HuggingFaceH4. Aime-25: American invitational mathematics examination 2025 benchmark. https://huggingface.co/datasets/HuggingFaceH4/aime_2025,
2025
-
[11]
J KOLODNER
Accessed: 2025- 09-10. J KOLODNER. Case-based reasoning.IEEE Expert Intelligent Systems & Their Applications, 7(5): 5–6,
2025
-
[12]
Holistic evaluation of language models.Transactions on Machine Learning Research, 2023,
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models.Transactions on Machine Learning Research, 2023,
2023
-
[13]
doi: 10.1146/annurev.neuro.24.1.167. Allen Newell, Herbert Alexander Simon, et al.Human problem solving, volume
-
[14]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Accessed: 2026-04-15. Siru Ouyang, Jun Yan, I Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, Xiangru Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory. arXiv preprint arXiv:2509.25140,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
doi: 10.1016/j.cub.2013.05.041. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In First conference on language modeling,
-
[16]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V
Accessed: 2026- 04-09. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR),
2026
-
[17]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, and Botian Shi. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
The verifier checks whether the proposed move is executable and goal-aligned, and returns approval or concise corrective feedback
Figure 11: Verification prompt template. The verifier checks whether the proposed move is executable and goal-aligned, and returns approval or concise corrective feedback. 24 Benchmark-specific specialization.For AIME, verification is specialized as state-transition check- ing. The verifier checks whether the proposed action is coherent with the verified ...
2025
-
[20]
This setting naturally separates memory construction from final evaluation and helps reduce potential overlap between historical experience data and test problems
In our experiments, we randomly sample 100 problems fromAIME 1983-2023[Di Zhang, 2025] to construct the experience memory, and use AIME 2024[HuggingFaceH4, 2024] and AIME 2025[HuggingFaceH4, 2025] as test sets to evaluate the effectiveness of our framework. This setting naturally separates memory construction from final evaluation and helps reduce potenti...
1983
-
[21]
F.1.2 Evaluation Metrics Metric definitions.For AIME, ˆy(r) i =y i means the predicted answer is mathematically equivalent to the gold answer
are used for experience construction, while the remaining 70% (108 tasks) are reserved for evaluation, forming a held-out evaluation setup between experience memory construction and downstream code generation testing, consistent with standard language model benchmarking protocols [Liang et al., 2023]. F.1.2 Evaluation Metrics Metric definitions.For AIME, ...
2023
-
[22]
Limitations
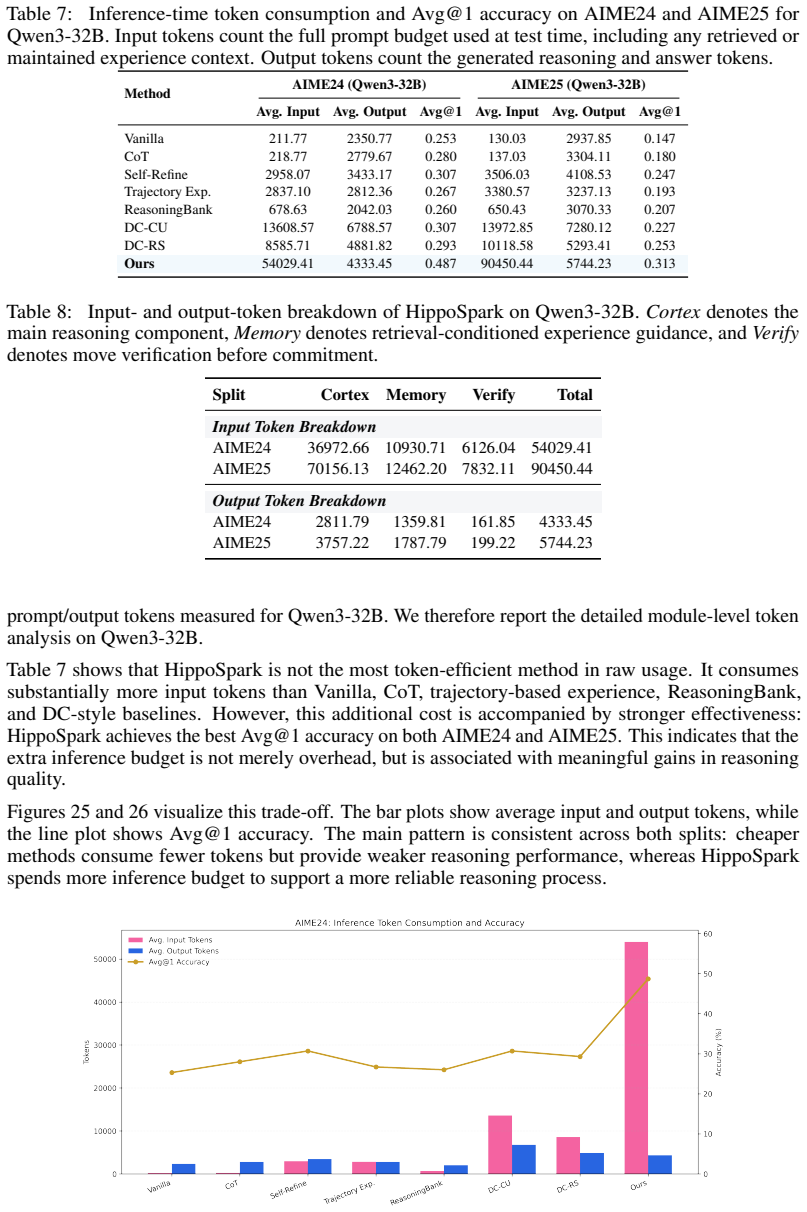
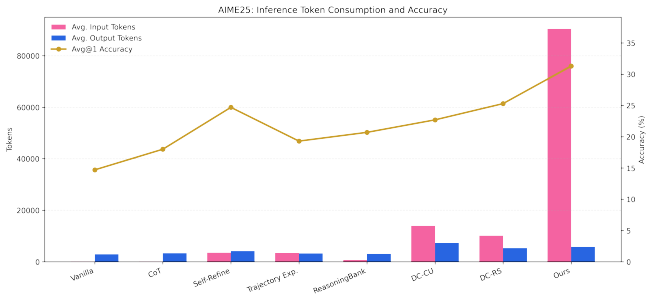
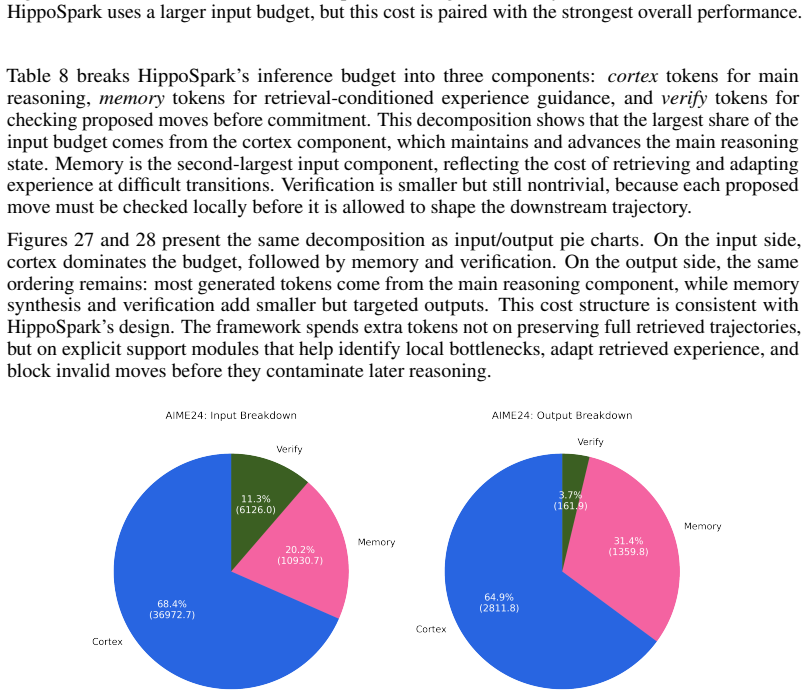
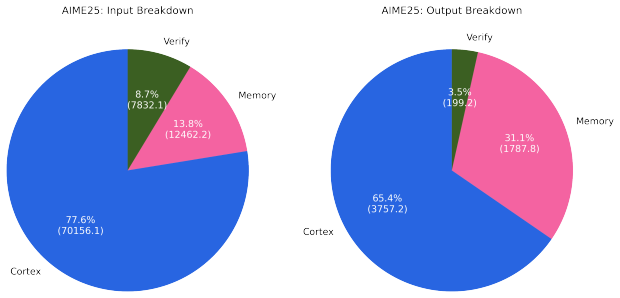
Method Qwen3-32B on 100 AIME Problems Avg. Input Avg. Output Avg. Exp. Len. # Units Remark Trajectory-/task-level experience Trajectory Exp 224.83 2493.64 2493.64 100 trajectory-level Reasoning Bank 3476.26 1967.59 430.27 100 bundled per task Distilled experience DC-CU 11169.34 6198.06 215.32 32 gen. + cheatsheet DC-RS 13261.88 5499.10 174.85 41 gen. + ch...
1967
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.