Stabilizing Extrapolation in Looped Transformers via Learned Stochastic Stopping
Pith reviewed 2026-06-30 07:26 UTC · model grok-4.3
The pith
Stochastic loop counts during training sharply reduce OOD variance in looped transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
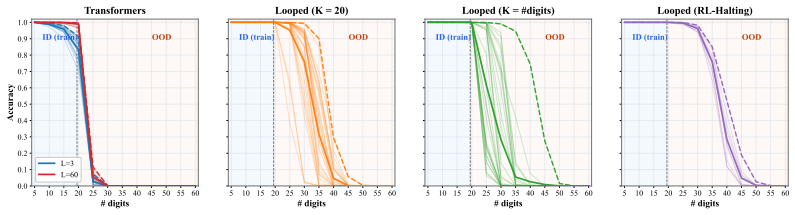
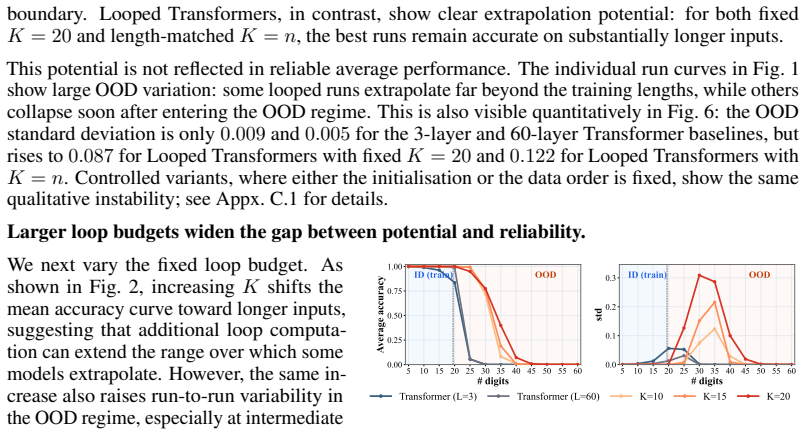
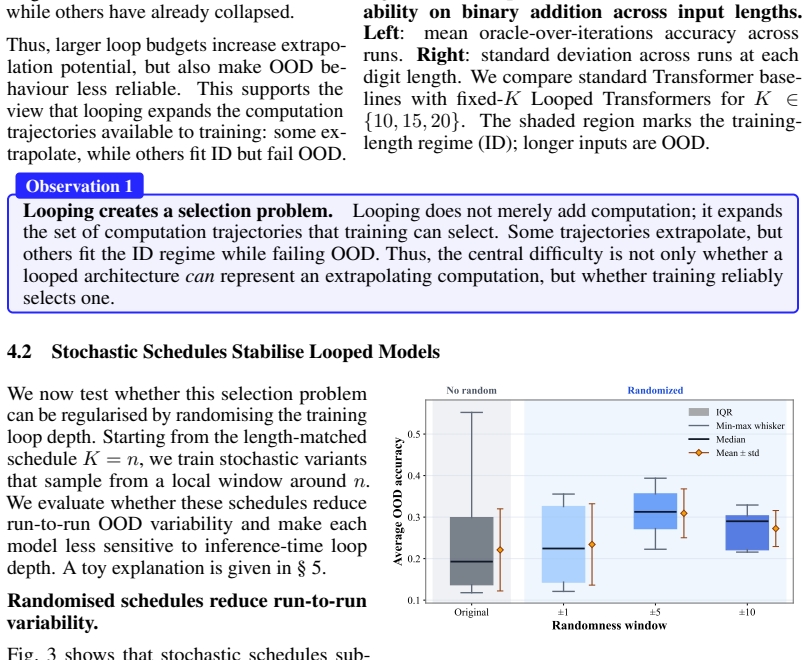
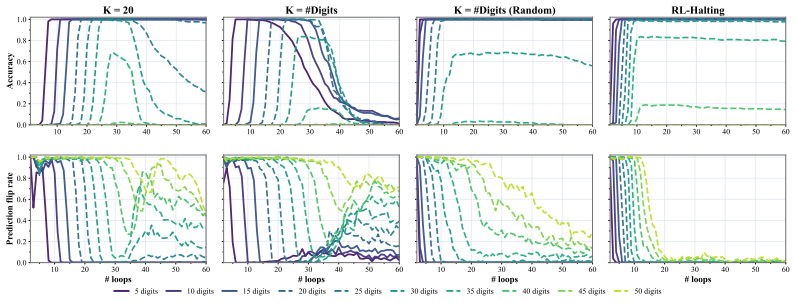
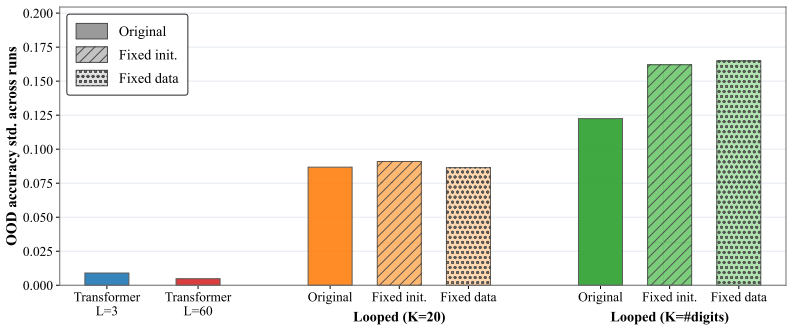
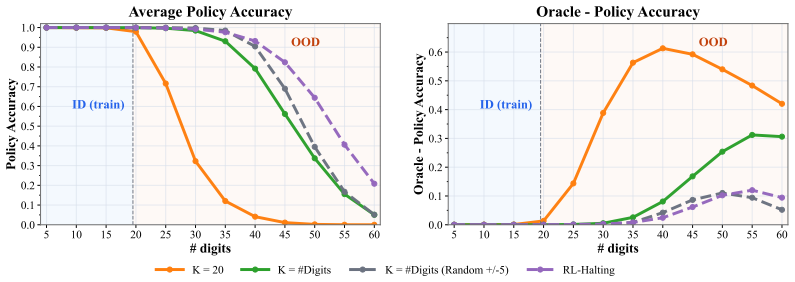
The paper establishes that looped transformers exhibit brittle length generalization because training creates a spurious correlation between sequence length and loop count; introducing stochasticity into the loop count at training time removes this correlation and stabilizes extrapolation, while replacing heuristic randomization with a learned stochastic schedule (RL-Halting) improves the accuracy-stability trade-off on binary addition, Dyck-1, Unique Set, and Copy.
What carries the argument
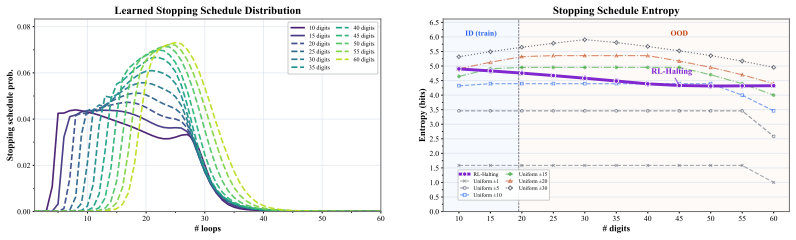
RL-Halting, a reinforcement-learning method that learns a stochastic schedule for deciding when to stop looping.
If this is right
- Stochastic loop counts at training time reduce OOD variance and make performance consistent across different inference-time loop numbers.
- RL-Halting learned schedules improve the accuracy-stability trade-off on binary addition, Dyck-1, Unique Set, and Copy.
- The approach can stabilize a suboptimal computation on some tasks.
- Treating the decision of when to stop as a training-time design choice rather than an inference-time rule aids extrapolation.
Where Pith is reading between the lines
- The same stochastic-iteration idea could be tested in other iterative architectures such as recurrent networks.
- The result points to a broader need to audit training distributions for unintended correlations between input features and computation depth.
- Combining learned stochastic stopping with other length-generalization techniques might yield further gains on harder algorithmic problems.
Load-bearing premise
The observed out-of-distribution variance is caused mainly by the correlation between sequence length and number of loops.
What would settle it
Train models with loop counts that are fixed yet matched to length in a way that removes the correlation, then check whether high OOD variance still appears.
Figures

read the original abstract
Looped Transformers, which repeatedly apply a shared transformer block, are an architecturally natural fit for variable-length algorithmic tasks. Although they can exhibit strong length generalization beyond the length of training sequences, this behavior is brittle, yielding high out-of-distribution (OOD) variance, even across well-performing in-distribution solutions. We trace this variance to the spurious correlation in simple algorithmic tasks between sequence length and number of loops. Introducing stochasticity into the number of loops during training sharply reduces OOD variance and stabilizes predictions across inference-time loop counts. To improve upon heuristic randomization schemes, we further analyze RL-Halting as a learned stochastic schedule and find that it generally improves the accuracy-stability trade-off. Across binary addition, Dyck-1, Unique Set, and Copy, learned stochastic stopping often improves this trade-off but can also stabilize a suboptimal computation. Our work suggests that "when to stop" should be treated as a training-time design choice, not merely an inference-time computation-allocation rule.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that looped transformers exhibit brittle length generalization with high OOD variance on algorithmic tasks, which it traces to a spurious correlation between training sequence length and the number of loop iterations. Introducing stochasticity over the number of loops during training reduces this variance and stabilizes predictions at inference-time loop counts; a learned RL-Halting schedule is shown to improve the accuracy-stability trade-off on binary addition, Dyck-1, Unique Set, and Copy, though it can also stabilize suboptimal computations. The work concludes that halting should be treated as a training-time design choice.
Significance. If the empirical findings hold after proper isolation of the causal factor, the result would offer a concrete training modification that improves reliability of variable-depth computation in transformers without changing the architecture, with potential applicability to other recurrent or iterative models.
major comments (2)
- The central attribution of OOD variance to the spurious length-loop correlation (rather than optimization dynamics or representation capacity) is load-bearing for the claim that stochasticity is causal rather than incidental. The manuscript provides no ablation that holds the loop-count distribution fixed while varying other training factors, leaving the source of variance unisolated.
- The statement that RL-Halting 'generally improves the accuracy-stability trade-off' but 'can also stabilize a suboptimal computation' requires quantitative support (e.g., per-task tables showing both the improvement magnitude and the cases of suboptimal stabilization) to be load-bearing for the recommendation to treat halting as a training-time choice.
minor comments (2)
- Notation for the stochastic loop schedule and the RL-Halting objective should be introduced with explicit equations rather than prose descriptions.
- The abstract and introduction would benefit from a short table summarizing the four tasks, their training lengths, and the OOD lengths used for evaluation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. Below we address each major comment point by point, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: The central attribution of OOD variance to the spurious length-loop correlation (rather than optimization dynamics or representation capacity) is load-bearing for the claim that stochasticity is causal rather than incidental. The manuscript provides no ablation that holds the loop-count distribution fixed while varying other training factors, leaving the source of variance unisolated.
Authors: Our primary evidence consists of controlled comparisons between deterministic loop counts (which preserve the length-loop correlation) and stochastic loop counts (which break it), with all other training factors held fixed; the reduction in OOD variance under stochasticity supports the role of the correlation. We acknowledge, however, that this does not fully isolate the correlation from other potential contributors such as optimization dynamics. In the revision we will add an explicit discussion of this limitation and include an ablation that holds the loop-count distribution fixed while varying other training elements (e.g., optimizer settings or data ordering) where computationally feasible. revision: yes
-
Referee: The statement that RL-Halting 'generally improves the accuracy-stability trade-off' but 'can also stabilize a suboptimal computation' requires quantitative support (e.g., per-task tables showing both the improvement magnitude and the cases of suboptimal stabilization) to be load-bearing for the recommendation to treat halting as a training-time choice.
Authors: The manuscript already reports results across the four tasks (binary addition, Dyck-1, Unique Set, Copy) that illustrate the trade-off, including the observation that RL-Halting can stabilize suboptimal solutions. To strengthen the claim with the requested quantitative detail, the revised version will include per-task tables that explicitly list accuracy and stability metrics for each method, report the magnitude of improvements, and flag any instances of suboptimal stabilization. revision: yes
Circularity Check
No derivation chain present; purely empirical claims
full rationale
The paper reports experimental results on introducing stochastic loop counts during training of looped transformers to reduce OOD variance on algorithmic tasks. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. The central claims rest on observed accuracy-stability trade-offs across binary addition, Dyck-1, Unique Set, and Copy tasks, with no reduction of any result to its own inputs by construction. The work is therefore self-contained as an empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, 9 U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, ed- itors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. UR...
2017
-
[2]
Position: Understanding LLMs Requires More Than Statistical Generalization.arXiv,
Patrik Reizinger, Szilvia Ujváry, Anna Mészáros, Anna Kerekes, Wieland Brendel, and Ferenc Huszár. Position: Understanding LLMs Requires More Than Statistical Generalization.arXiv,
-
[3]
doi: 10.48550/arxiv.2405.01964
-
[4]
Generalization on the Unseen, Logic Reasoning and Degree Curriculum, November 2024
Emmanuel Abbe, Samy Bengio, Aryo Lotfi, and Kevin Rizk. Generalization on the Unseen, Logic Reasoning and Degree Curriculum, November 2024. URL http://arxiv.org/abs/ 2301.13105. arXiv:2301.13105 [cs]
-
[5]
What Algorithms can Transformers Learn? A Study in Length Gen- eralization, October 2023
Hattie Zhou, Arwen Bradley, Etai Littwin, Noam Razin, Omid Saremi, Josh Susskind, Samy Ben- gio, and Preetum Nakkiran. What Algorithms can Transformers Learn? A Study in Length Gen- eralization, October 2023. URLhttp://arxiv.org/abs/2310.16028. arXiv:2310.16028
-
[6]
Extrapolation by Association: Length Generalization Transfer in Transformers, August 2025
Ziyang Cai, Nayoung Lee, Avi Schwarzschild, Samet Oymak, and Dimitris Papailiopoulos. Extrapolation by Association: Length Generalization Transfer in Transformers, August 2025. URLhttp://arxiv.org/abs/2506.09251. arXiv:2506.09251 [cs]
-
[7]
Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges
Nayoung Lee, Ziyang Cai, Avi Schwarzschild, Kangwook Lee, and Dimitris Papailiopoulos. Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges. June 2025. URLhttps://openreview.net/forum?id=ZtX0MBT6mf
2025
-
[8]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal Transformers, July 2018. URLhttps://arxiv.org/abs/1807.03819v3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Avi Schwarzschild, Eitan Borgnia, Arjun Gupta, Furong Huang, Uzi Vishkin, Micah Goldblum, and Tom Goldstein. Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks, November 2021. URL http://arxiv.org/abs/2106.04537. arXiv:2106.04537 [cs]
-
[10]
Arpit Bansal, Avi Schwarzschild, Eitan Borgnia, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein. End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without Overthinking, October 2022. URL http://arxiv.org/abs/2202. 05826. arXiv:2202.05826 [cs]
-
[11]
Looped Transformers as Programmable Computers.arXiv, 2023
Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris Papailiopoulos. Looped Transformers as Programmable Computers.arXiv, 2023. doi: 10. 48550/arxiv.2301.13196
-
[12]
Looped Transformers for Length Generalization
Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped Transformers for Length Generalization. October 2024. URL https://openreview.net/forum?id= 2edigk8yoU
2024
-
[13]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bar- toldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, February 2025. URL http://arxiv.org/abs/2502.05171. arXiv:2502.05171 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Scaling Latent Reasoning via Looped Language Models
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai, Ge Zhang, Wenhao Huang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Looped transformers are better at learning learning al- gorithms.arXiv preprint arXiv:2311.12424,
Liu Yang, Kangwook Lee, Robert Nowak, and Dimitris Papailiopoulos. Looped Transformers are Better at Learning Learning Algorithms.arXiv, 2023. doi: 10.48550/arxiv.2311.12424
-
[16]
PonderNet: Learning to Ponder, September
Andrea Banino, Jan Balaguer, and Charles Blundell. PonderNet: Learning to Ponder, September
- [17]
-
[18]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. Reasoning with Latent Thoughts: On the Power of Looped Transformers. October 2024. URL https: //openreview.net/forum?id=din0lGfZFd
2024
-
[19]
Thinking Deeper With Recurrent Networks: Logical Extrapolation Without Overthinking
Arpit Bansal, Avi Schwarzschild, Eitan Borgnia, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein. Thinking Deeper With Recurrent Networks: Logical Extrapolation Without Overthinking. October 2021. URLhttps://openreview.net/forum?id=kDF4Owotj5j
2021
-
[20]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning
-
[21]
Reinforcement Learning: An Overview, May 2025
Kevin Murphy. Reinforcement Learning: An Overview, May 2025. URL http://arxiv. org/abs/2412.05265. arXiv:2412.05265 [cs]
-
[22]
Transformers Can Achieve Length Generalization But Not Robustly, February 2024
Yongchao Zhou, Uri Alon, Xinyun Chen, Xuezhi Wang, Rishabh Agarwal, and Denny Zhou. Transformers Can Achieve Length Generalization But Not Robustly, February 2024. URL http://arxiv.org/abs/2402.09371. arXiv:2402.09371 [cs]
-
[23]
Randomized Positional Encodings Boost Length Generalization of Transformers, May 2023
Anian Ruoss, Grégoire Delétang, Tim Genewein, Jordi Grau-Moya, Róbert Csordás, Mehdi Bennani, Shane Legg, and Joel Veness. Randomized Positional Encodings Boost Length Generalization of Transformers, May 2023. URL http://arxiv.org/abs/2305.16843. arXiv:2305.16843 [cs]
-
[24]
Position Coupling: Improving Length Generaliza- tion of Arithmetic Transformers Using Task Structure
Hanseul Cho, Jaeyoung Cha, Pranjal Awasthi, Srinadh Bhojanapalli, Anupam Gupta, and Chulhee Yun. Position Coupling: Improving Length Generaliza- tion of Arithmetic Transformers Using Task Structure. November 2024. URL https://openreview.net/forum?id=5cIRdGM1uG&referrer=%5Bthe%20profile% 20of%20Pranjal%20Awasthi%5D(%2Fprofile%3Fid%3D~Pranjal_Awasthi3)
2024
-
[25]
The Impact of Positional Encoding on Length Generalization in Transformers
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, and Siva Reddy. The Impact of Positional Encoding on Length Generalization in Transformers
-
[26]
ON V ANISHING V ARIANCE IN TRANSFORMER LENGTH GENERALIZATION
Ruining Li and Gabrijel Boduljak. ON V ANISHING V ARIANCE IN TRANSFORMER LENGTH GENERALIZATION. 2025
2025
-
[27]
How much does Initialization Affect Generalization? InProceedings of the 40th International Conference on Machine Learning, pages 28637–28655
Sameera Ramasinghe, Lachlan Ewen Macdonald, Moshiur Farazi, Hemanth Saratchandran, and Simon Lucey. How much does Initialization Affect Generalization? InProceedings of the 40th International Conference on Machine Learning, pages 28637–28655. PMLR, July 2023. URL https://proceedings.mlr.press/v202/ramasinghe23a.html
2023
-
[28]
On The Power of Curriculum Learning in Training Deep Networks
Guy Hacohen and Daphna Weinshall. On The Power of Curriculum Learning in Training Deep Networks. InProceedings of the 36th International Conference on Machine Learn- ing, pages 2535–2544. PMLR, May 2019. URL https://proceedings.mlr.press/v97/ hacohen19a.html
2019
-
[29]
Path Independent Equilibrium Models Can Better Exploit Test-Time Computation
Cem Anil, Ashwini Pokle, Kaiqu Liang, Johannes Treutlein, Yuhuai Wu, Shaojie Bai, Zico Kolter, and Roger Grosse. Path Independent Equilibrium Models Can Better Exploit Test-Time Computation
-
[30]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical Reasoning Model, July 2025. URL http://arxiv.org/ abs/2506.21734. arXiv:2506.21734 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive Computation Time for Recurrent Neural Networks, February 2017. URLhttp://arxiv.org/abs/1603.08983. arXiv:1603.08983 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting
-
[33]
Deep Networks with Stochastic Depth
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Weinberger. Deep Networks with Stochastic Depth, July 2016. URL http://arxiv.org/abs/1603.09382. arXiv:1603.09382 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
Angela Fan, Edouard Grave, and Armand Joulin. Reducing Transformer Depth on Demand with Structured Dropout, September 2019. URL http://arxiv.org/abs/1909.11556. arXiv:1909.11556 [cs]. 11 A Implementation Details Architecture and training.Our Looped Transformer implementation follows Fan et al. [ 11]. One looped block consists of three Transformer layers a...
-
[35]
Therefore, institutional review board approval or equivalent human-subjects review is not applicable
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.