T3R: Deeper Test-Time Adaptation for Graph Neural Networks via Gradient Rotation
Pith reviewed 2026-06-30 07:23 UTC · model grok-4.3
The pith
T3R rotates gradients from self-supervised signals via Rotograd matrices to enable deeper test-time adaptation across nearly all GNN parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
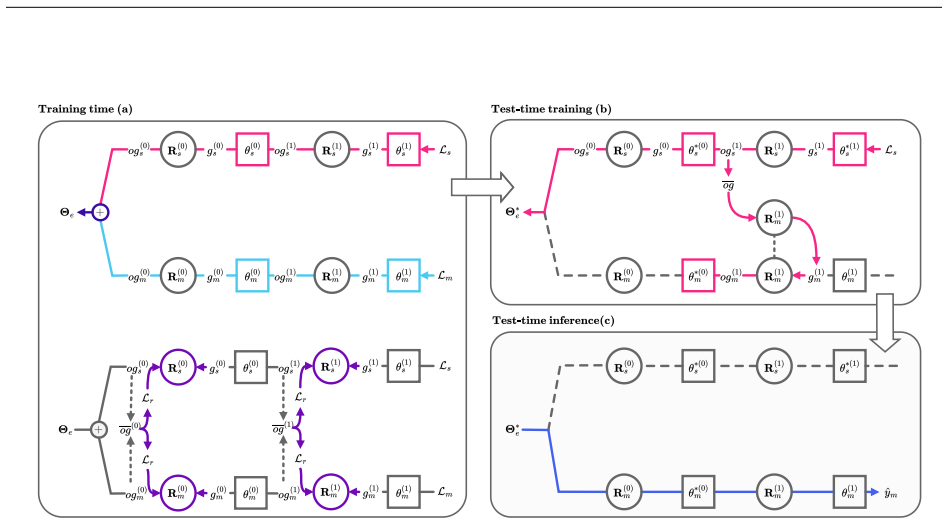
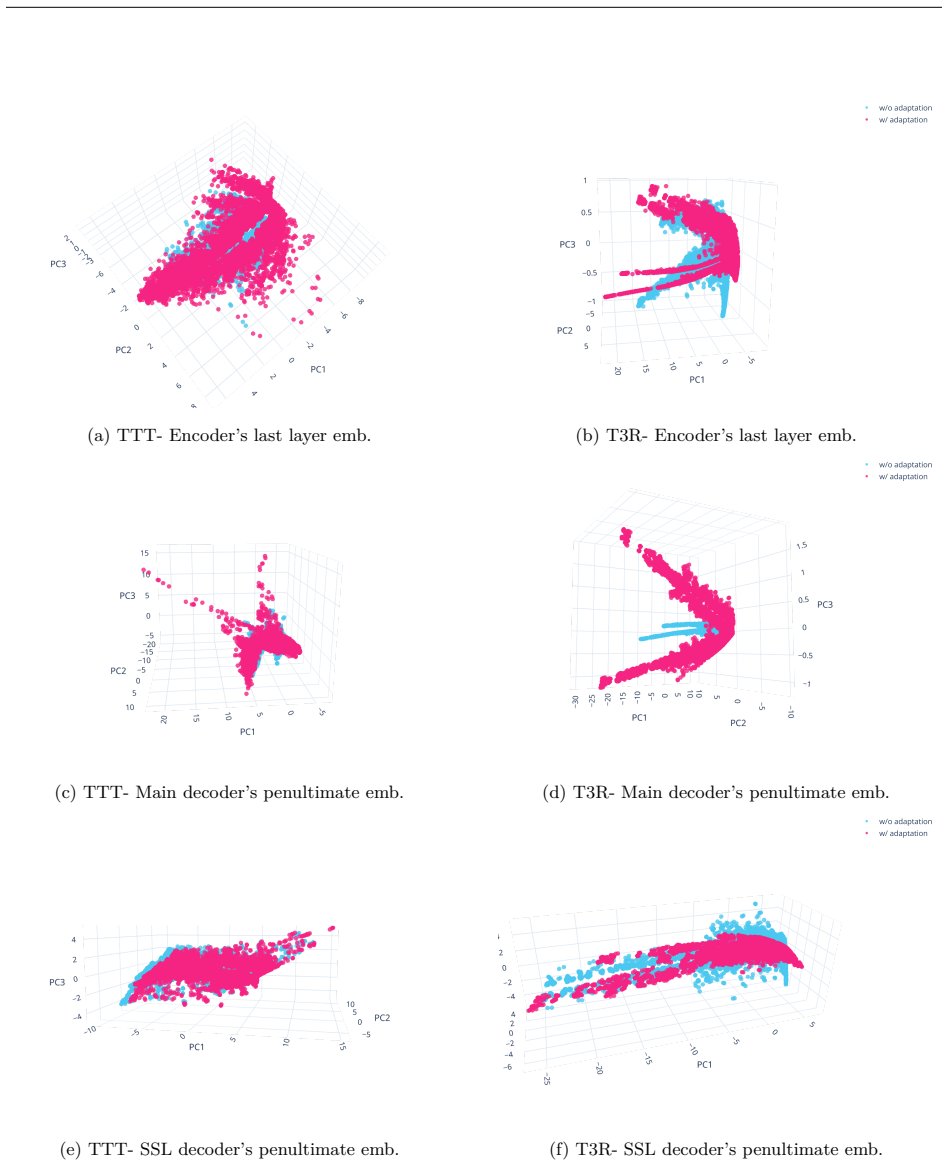
T3R leverages multiple Rotograd matrices to improve task affinity between the target and auxiliary tasks, essential for effective test-time training. T3R further introduces a rotation technique that reorients self-supervised signals using these matrices to create surrogate gradients for the target task, allowing deeper adaptation across nearly the entire architecture.
What carries the argument
The rotation technique that uses multiple Rotograd matrices to reorient self-supervised signals into surrogate gradients aligned with the target task.
If this is right
- Reduces MAE by 0.172 points over standard inference on regression datasets.
- Delivers at least 9.37% relative improvement on cross-domain OGB classification benchmarks versus no adaptation.
- Permits weight updates throughout nearly the full GNN architecture rather than only the final layers.
- Provides an adaptation pipeline usable when conventional fine-tuning or retraining is infeasible.
Where Pith is reading between the lines
- The same rotation approach could be tested on non-graph architectures that already use auxiliary self-supervised heads.
- If the matrices prove stable without validation labels, the method could be deployed in streaming settings where distribution shifts arrive continuously.
- Combining T3R with existing test-time augmentation techniques might compound the gains on node-level and graph-level tasks.
Load-bearing premise
The Rotograd matrices and rotation operation produce surrogate gradients that meaningfully improve the target task performance without introducing instability or requiring labeled validation data to tune the matrices.
What would settle it
Running T3R on a held-out cross-domain graph dataset and observing either higher error than the unadapted model or training divergence would falsify the central claim.
Figures
read the original abstract
Graph Neural Networks (GNNs) deployed in real-world systems typically have fixed weights, often leading to degraded performance under distribution shifts. This issue can be mitigated by conventional fine-tuning, but in many real-world cases, collecting labeled data is expensive or infeasible. A potential approach is Test-Time Training (TTT), which adapts models' weights using unlabeled test data, yet it is typically limited to shallow updates that affect only a subset of model parameters. We propose T3R, leveraging multiple Rotograd matrices to improve task affinity between the target and auxiliary tasks, essential for effective test-time training. T3R further introduces a rotation technique that reorients self-supervised signals using these matrices to create surrogate gradients for the target task, allowing deeper adaptation across nearly the entire architecture. Empirically, T3R reduces MAE by 0.172 points over standard inference in regression datasets and achieves at least 9.37% relative improvement on cross-domain OGB classification benchmarks compared to models without adaptation. These results highlight the potential to develop an adaptation pipeline for graph-based systems, particularly in settings where conventional fine-tuning or retraining is infeasible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes T3R for test-time adaptation of GNNs under distribution shifts. It uses multiple Rotograd matrices to improve task affinity between target and auxiliary tasks, combined with a rotation technique that reorients self-supervised signals to produce surrogate gradients. This enables deeper adaptation across nearly the full architecture rather than shallow updates. Empirical results claim an MAE reduction of 0.172 on regression datasets and at least 9.37% relative improvement on cross-domain OGB classification benchmarks compared to no adaptation.
Significance. If the mechanism and results hold, the work addresses a practical limitation in deploying GNNs by extending test-time training to deeper layers without requiring labels. The gradient rotation approach for generating surrogate gradients from auxiliary tasks represents a targeted extension of existing TTT ideas to graph models.
major comments (1)
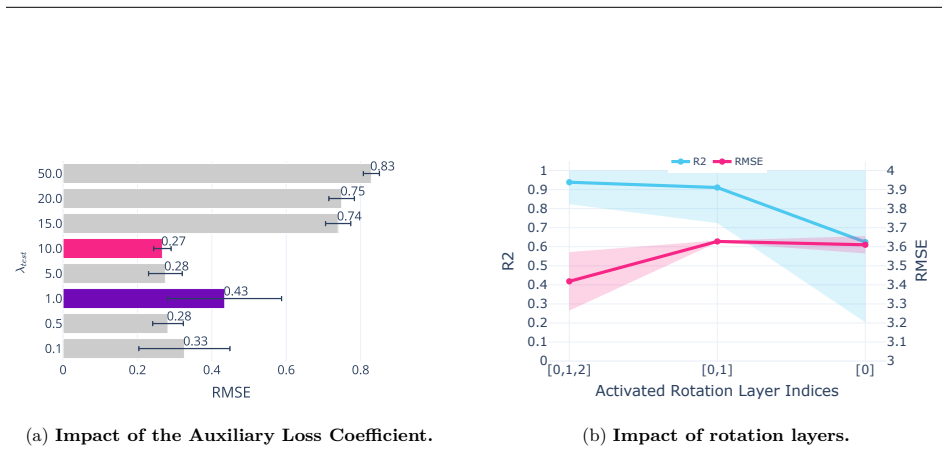
- [Experiments] Experiments section: the reported MAE reduction of 0.172 and ≥9.37% relative improvement are presented as direct evidence for the method but without error bars, ablation studies on the number of Rotograd matrices, or controls for the rotation operation. This is load-bearing for the central claim that the surrogate gradients enable effective deeper adaptation.
minor comments (2)
- [§2] The abstract and method description use terms like 'Rotograd matrices' and 'rotation technique' without initial definition or reference to prior work on Rotograd; add a brief background paragraph or citation in §2.
- [Method] Notation for the surrogate gradient construction should be clarified with a diagram or pseudocode, as the reorientation step is central but described at a high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concern regarding the strength of the experimental evidence is valid and we will strengthen the paper accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported MAE reduction of 0.172 and ≥9.37% relative improvement are presented as direct evidence for the method but without error bars, ablation studies on the number of Rotograd matrices, or controls for the rotation operation. This is load-bearing for the central claim that the surrogate gradients enable effective deeper adaptation.
Authors: We agree that the current presentation of results would benefit from additional statistical rigor and controls. In the revised manuscript we will report error bars computed over multiple random seeds for all main results. We will also add an ablation study varying the number of Rotograd matrices (e.g., 1, 2, 4, 8) and include a control experiment that disables the rotation operation while keeping the rest of the pipeline fixed. These additions will directly support the claim that the surrogate gradients produced by the rotation technique enable deeper adaptation. revision: yes
Circularity Check
No significant circularity
full rationale
The abstract and available description present only empirical performance claims (MAE reduction of 0.172, relative improvement of at least 9.37%) measured on regression and OGB classification benchmarks. No equations, derivations, fitted parameters, or self-citations are visible that would allow any claimed prediction or result to reduce to its own inputs by construction. The method description (Rotograd matrices and rotation for surrogate gradients) is stated as a proposed technique whose value is asserted via external measurements rather than internal self-definition or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://link.springer.com/chapter/10.1007/978-3-031-75390-9_5
ISBN 978-3-031-75390-9. URLhttps://link.springer.com/chapter/10.1007/978-3-031-75390-9_5. Yunshu Du, Wojciech M. Czarnecki, Siddhant M. Jayakumar, Mehrdad Farajtabar, Razvan Pascanu, and Balaji Lakshminarayanan. Adapting auxiliary losses using gradient similarity,
-
[2]
URLhttps://arxiv. org/abs/1812.02224. Wenzheng Feng, Jie Zhang, Yuxiao Dong, Yu Han, Huanbo Luan, Qian Xu, Qiang Yang, Evgeny Kharlamov, and Jie Tang. Graph random neural network for semi-supervised learning on graphs. InNeurIPS’20,
-
[3]
doi: https://doi.org/10.1016/j.comnet
ISSN 1389-1286. doi: https://doi.org/10.1016/j.comnet. 2022.109329. URLhttps://www.sciencedirect.com/science/article/pii/S1389128622003681. 11 Yossi Gandelsman, Yu Sun, Xinlei Chen, and Alexei A Efros. Test-time training with masked autoencoders. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.),Advances in Neural Information Proc...
-
[4]
Huang, G., Dai, G., Wang, Y ., and Yang, H
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs.arXiv preprint arXiv:2005.00687,
-
[5]
doi: https://doi.org/10.1016/j.watres.2024.121933
ISSN 0043-1354. doi: https://doi.org/10.1016/j.watres.2024.121933. URLhttps://www.sciencedirect.com/ science/article/pii/S0043135424008340. Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations,
-
[6]
URLhttps://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/ 1998WR900018
doi: https:// doi.org/10.1029/1998WR900018. URLhttps://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/ 1998WR900018. Dongyue Li, Aneesh Sharma, and Hongyang R. Zhang. Scalable multitask learning using gradient-based estimation of task affinity. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, pp. 1542–1553,...
-
[7]
Association for Computing Machinery. ISBN 9798400704901. doi: 10.1145/3637528.3671835. URLhttps://doi.org/10.1145/3637528.3671835. Guohao Li, Matthias Müller, Ali Thabet, and Bernard Ghanem. Deepgcns: Can gcns go as deep as cnns? In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9266–9275,
-
[8]
doi: 10.1109/ICCV.2019.00936. Jintang Li, Ruofan Wu, Wangbin Sun, Liang Chen, Sheng Tian, Liang Zhu, Changhua Meng, Zibin Zheng, and Weiqiang Wang. What’s behind the mask: Understanding masked graph modeling for graph autoencoders. InKDD, pp. 1268–1279. ACM,
-
[9]
Jian Liang, Dapeng Hu, Yunbo Wang, Ran He, and Jiashi Feng
URLhttps://proceedings.neurips.cc/paper_files/paper/ 2020/file/2f73168bf3656f697507752ec592c437-Paper.pdf. Jian Liang, Dapeng Hu, Yunbo Wang, Ran He, and Jiashi Feng. Source data-absent unsupervised domain adaptation through hypothesis transfer and labeling transfer,
2020
-
[10]
URLhttps://arxiv.org/abs/2012. 07297. Xi Lin, Hui-Ling Zhen, Zhenhua Li, Qingfu Zhang, and Sam Kwong. Pareto multi-task learning. InThirty-third Conference on Neural Information Processing Systems (NeurIPS), pp. 12037–12047,
2012
-
[11]
cc/paper_files/paper/2021/file/b618c3210e934362ac261db280128c22-Paper.pdf
URLhttps://proceedings.neurips. cc/paper_files/paper/2021/file/b618c3210e934362ac261db280128c22-Paper.pdf. Jie Lu, Anjin Liu, Fan Dong, Feng Gu, Joao Gama, and Guangquan Zhang. Learning under concept drift: A review.IEEE transactions on knowledge and data engineering, 31(12):2346–2363,
2021
-
[12]
Rami Luisto. A short survey on almost orthogonal vectors in a few specific large dimensions.arXiv preprint arXiv:2510.23609,
-
[13]
Association for Computing Machinery. ISBN 9781450379984. doi: 10.1145/3394486.3403168. URLhttps://doi.org/10.1145/3394486.3403168. Alec Radford, Jong Wook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from nat...
-
[14]
doi: https://doi.org/10.1016/j.engappai.2024.109426
ISSN 0952-1976. doi: https://doi.org/10.1016/j.engappai.2024.109426. URL https: //www.sciencedirect.com/science/article/pii/S0952197624015847. Yu Sun, Xiaolong Wang, Liu Zhuang, John Miller, Moritz Hardt, and Alexei A. Efros. Test-time training with self-supervision for generalization under distribution shifts. InICML,
-
[15]
End-to-end test-time training for long context, 2025
URLhttps://arxiv.org/abs/2512.23675. Huy Truong, Andrés Tello, Alexander Lazovik, and Victoria Degeler. Graph neural networks for pressure estimation in water distribution systems.Water Resources Research, 60(7):e2023WR036741,
-
[16]
URL https://agupubs.onlinelibrary.wiley.com/doi/abs/ 10.1029/2023WR036741
doi: https://doi.org/10.1029/2023WR036741. URL https://agupubs.onlinelibrary.wiley.com/doi/abs/ 10.1029/2023WR036741. e2023WR036741 2023WR036741. Huy Truong, Andrés Tello, Alexander Lazovik, and Victoria Degeler. Ditec-wdn: A large-scale dataset of hydraulic scenarios across multiple water distribution networks.Scientific Data, 12(1):1733,
-
[17]
URLhttps://doi.org/10.1038/s41597-025-06026-0
doi: 10.1038/s41597-025-06026-0. URLhttps://doi.org/10.1038/s41597-025-06026-0. 13 Petar Veličković, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. Deep Graph Infomax. InInternational Conference on Learning Representations,
-
[18]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka
doi: 10.1109/TII.2020.3047843. Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations,
-
[19]
Gradient surgery for multi-task learning, 2020
URL https://proceedings.neurips.cc/paper/2020/file/ 3fe230348e9a12c13120749e3f9fa4cd-Paper.pdf. Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.arXiv preprint arXiv:2001.06782,
-
[20]
doi: https://doi.org/10.1016/j.watres.2024.122142
ISSN 0043-1354. doi: https://doi.org/10.1016/j.watres.2024.122142. URL https: //www.sciencedirect.com/science/article/pii/S0043135424010418. A Appendix A.1 Dataset Description Both DWD and OGB include several datasets served for a variety of tasks. However, only datasets with compatible inputs and identical tasks are suitable for model adaptation. Table 5...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.