Little Brains, Big Feats: Exploring Compact Language Models
Pith reviewed 2026-06-30 06:16 UTC · model grok-4.3
The pith
Small language models can run a full RAG pipeline on ordinary hardware without GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A retrieval-augmented generation system that relies on small language models for the generation stage can execute entirely on non-GPU hardware and finish queries in reasonable time across the evaluated datasets.
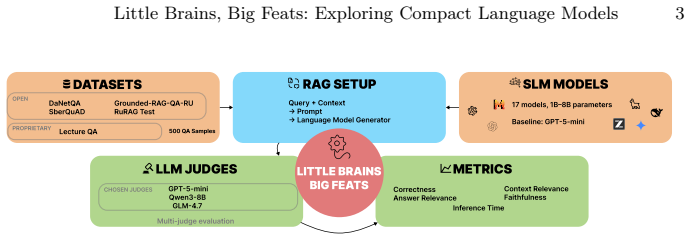
What carries the argument
The RAG pipeline in which retrieval precedes generation by a compact language model.
If this is right
- RAG systems become deployable on mobile phones and laptops without cloud or GPU support.
- Generation quality from small models holds across varied subject areas and question styles in the benchmarks.
- On-device RAG removes the need for constant network access during answer creation.
Where Pith is reading between the lines
- Local execution could keep user queries private by avoiding data transmission.
- The approach may extend to other edge devices if retrieval can also be made lightweight.
- Developers could combine this with model quantization to cut latency further.
Load-bearing premise
The quality of answers from the small models stays high enough for the intended tasks on the tested data.
What would settle it
A measurement showing that average query latency on a standard laptop exceeds ten seconds or that human raters judge answer accuracy below 70 percent on the same datasets.
Figures


read the original abstract
While large language models have been dominating the research landscape recently, small language models remain highly relevant across various domains; yet, they receive far less attention. In this study, we investigate how smaller language models perform during the generation stage within a Retrieval-Augmented Generation (RAG) system. To benchmark these models effectively, we utilised both open-source and proprietary datasets covering diverse subject areas and question types. Our findings demonstrate that a RAG system with small language models can be executed directly on-device without requiring any GPU hardware within a reasonable time. The experimental code and links to the supplementary materials can be accessed through the GitHub repository: https://github.com/SibNN/SLM-RAG-EVAL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the use of compact language models in the generation stage of Retrieval-Augmented Generation (RAG) pipelines. It benchmarks these models on open-source and proprietary datasets spanning diverse topics and question types, and reports that the resulting RAG systems can execute on CPU-only hardware without GPUs within a reasonable time; experimental code is released via a public GitHub repository.
Significance. If the reported timing results hold under scrutiny, the work would establish a concrete feasibility demonstration for on-device RAG with small models, supporting broader deployment of retrieval-augmented systems in GPU-scarce settings and adding to the empirical literature on efficient language-model pipelines.
major comments (1)
- [Abstract] Abstract: the performance claim that the RAG system 'can be executed directly on-device ... within a reasonable time' is asserted without any quantitative metrics (wall-clock latencies, hardware specifications, dataset statistics, or baseline timings), so the central empirical finding cannot be evaluated from the manuscript text.
minor comments (1)
- [Abstract] The abstract refers to 'both open-source and proprietary datasets' and 'diverse subject areas and question types' but supplies no names, sizes, or selection criteria for the datasets, which are needed to interpret the benchmarking results.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for quantitative support in the abstract. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claim that the RAG system 'can be executed directly on-device ... within a reasonable time' is asserted without any quantitative metrics (wall-clock latencies, hardware specifications, dataset statistics, or baseline timings), so the central empirical finding cannot be evaluated from the manuscript text.
Authors: We agree that the abstract should include concrete quantitative metrics to allow readers to evaluate the central claim. The full manuscript already reports wall-clock latencies, CPU hardware specifications (e.g., specific models and cores), dataset statistics, and baseline comparisons in the experimental sections. In the revised version we will add a concise summary of these metrics directly into the abstract so the performance claim is substantiated at the point of first reading. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmarking paper with no equations, parameters, or derivations. The central claim is a direct feasibility result from measured wall-clock latency on CPU hardware for a RAG pipeline using small models, supported by released code and datasets. No load-bearing steps reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The study is self-contained against external reproduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the acl work- shop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization
Banerjee, S., et al.: Meteor: An automatic metric for mt evaluation with im- proved correlation with human judgments. In: Proceedings of the acl work- shop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. pp. 65–72 (2005)
2005
-
[2]
Bolotova, V., et al.: A non-factoid question-answering taxonomy. In: Proceedings of the 45th International ACM SIGIR Conference on Re- search and Development in Information Retrieval. p. 1196–1207. SI- GIR ’22, Association for Computing Machinery, New York, NY, USA (2022).https://doi.org/10.1145/3477495.3531926,https://doi.org/ 10.1145/3477495.3531926
-
[3]
Bondarenko, I., Derunets, R., Sedukhin, O., Komarov, M., Chernov, I., Kulakov, M.: Raguteam at semeval-2026 task 8: Meno and friends in a judge-orchestrated llm ensemble for faithful multi-turn response generation (2026),https://arxiv.org/abs/2605.04523
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Bratchikov, S.: Grounded-rag-qa-ru.https://huggingface.co/datasets/ Vikhrmodels/Grounded-RAG-QA-RU(2024), dataset hosted on Hugging Face
2024
-
[5]
In: Proceedings of the 55th Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers)
Chen, D., et al.: Reading wikipedia to answer open-domain questions. In: Proceedings of the 55th Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers). pp. 1870–1879 (2017)
2017
- [6]
-
[7]
Investigations on applied mathematics and informatics
Derunets, R., Bondarenko, I., Kulakov, M., Prokopenko, V., Tikhunov, F.: Knowledge as recollection: advancing multimodal retrieval-augmented gen- eration. Investigations on applied mathematics and informatics. Part V, Zap. Nauchn. Sem. POMI546, 174–192 (2025)
2025
-
[8]
Efimov, P., et al.: Sberquad – russian reading comprehension dataset: De- scription and analysis. In: Experimental IR Meets Multilinguality, Mul- timodality, and Interaction: 11th International Conference of the CLEF Association, CLEF 2020, Thessaloniki, Greece, September 22–25, 2020, Proceedings. p. 3–15. Springer-Verlag, Berlin, Heidelberg (2020).https:...
-
[9]
In: Proceedings of the 18th conference of the european chapter of the association for computational linguistics: system demonstrations
Es, S., et al.: Ragas: Automated evaluation of retrieval augmented gener- ation. In: Proceedings of the 18th conference of the european chapter of the association for computational linguistics: system demonstrations. pp. 150–158 (2024)
2024
- [10]
-
[11]
In: Analysis of Images, Social Networks and Texts
Glushkova, T., et al.: Danetqa: A yes/no question answering dataset for the russian language. In: Analysis of Images, Social Networks and Texts. p. 57–68. Springer-Verlag, Berlin, Heidelberg (2020).https://doi.org/10. 1007/978-3-030-72610-2_4 16 Baturova et al
2020
-
[12]
In: In- ternational conference on machine learning
Guu, K., et al.: Retrieval augmented language model pre-training. In: In- ternational conference on machine learning. pp. 3929–3938. PMLR (2020)
2020
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E.J., et al.: Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021),https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
In: Findings of the Association for Computational Linguistics: ACL 2024
Jin, R., et al.: A comprehensive evaluation of quantization strategies for large language models. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 12186–12215. Association for Computational Linguistics, Bangkok, Thailand (aug 2024),https://aclanthology.org
2024
-
[15]
arXiv preprint arXiv:2412.15304 (2024)
Kandala, S.V., et al.: Tinyllm: A framework for training and deploying language models at the edge computers. arXiv preprint arXiv:2412.15304 (2024)
-
[16]
In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Karpukhin, V., et al.: Dense passage retrieval for open-domain question answering. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). pp. 6769–6781 (2020)
2020
- [17]
-
[18]
In: Proceedings of the 43rd Interna- tional ACM SIGIR conference on research and development in Information Retrieval
Khattab, O., et al.: Colbert: Efficient and effective passage search via con- textualized late interaction over bert. In: Proceedings of the 43rd Interna- tional ACM SIGIR conference on research and development in Information Retrieval. pp. 39–48 (2020)
2020
-
[19]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Lewis, P., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. pp. 9459–9474. NIPS ’20, Curran Asso- ciates Inc., Red Hook, NY, USA (2020)
2020
-
[20]
In: Text summarization branches out
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text summarization branches out. pp. 74–81 (2004)
2004
-
[21]
In: Proceedings of the 2023 conference on empirical methods in nat- ural language processing
Liu, Y., et al.: G-eval: Nlg evaluation using gpt-4 with better human align- ment. In: Proceedings of the 2023 conference on empirical methods in nat- ural language processing. pp. 2511–2522 (2023)
2023
-
[22]
In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics
Papineni, K., et al.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics. pp. 311–318 (2002)
2002
-
[23]
In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V
Pham, N.T., et al.: SLM-bench: A comprehensive benchmark of small language models on environmental impacts. In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2025. pp. 21369–21392. Associ- ation for Computational Linguistics, Suzhou, China (Nov 2025).https: //doi.org/10....
-
[24]
Pipitone, N., et al.: Legalbench-rag: A benchmark for retrieval-augmented generation in the legal domain (2024),https://arxiv.org/abs/2408. 10343
2024
-
[25]
In: Proceedings of the first instructional conference on machine learning
Ramos, J., et al.: Using tf-idf to determine word relevance in document queries. In: Proceedings of the first instructional conference on machine learning. vol. 242, pp. 29–48. Citeseer (2003) Little Brains, Big Feats: Exploring Compact Language Models 17
2003
-
[26]
Robertson, S., et al.: The probabilistic relevance framework: BM25 and beyond, vol. 4. Now Publishers Inc (2009)
2009
-
[27]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Sanh, V., et al.: Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
- [28]
-
[29]
slivka83: Rurag test dataset.https://github.com/slivka83/ru_rag_ test_dataset(2025), dataset hosted on GitHub
2025
- [30]
-
[31]
Tang, Y., Yang, Y.: Multihop-rag: Benchmarking retrieval-augmented gen- eration for multi-hop queries (2024),https://arxiv.org/abs/2401.15391
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Wang, F.,et al.: A comprehensive surveyof small language models in the era of large language models: Techniques, enhancements, applications, collab- oration with llms, and trustworthiness. ACM Trans. Intell. Syst. Technol. 16(6) (Nov 2025).https://doi.org/10.1145/3768165
-
[33]
In: Proceedings of the 3rd International Workshop on Rich Media With Generative AI
Wang, J., et al.: Slmquant: Benchmarking small language model quanti- zation for practical deployment. In: Proceedings of the 3rd International Workshop on Rich Media With Generative AI. p. 2–10. RichMediaGAI ’25, Association for Computing Machinery, New York, NY, USA (2025). https://doi.org/10.1145/3746262.3761973
- [34]
-
[35]
Wang, X., et al.: Healthslm-bench: Benchmarking small language models for mobile and wearable healthcare monitoring (2025),https://arxiv. org/abs/2509.07260
-
[36]
Wang, X., et al.: Empowering edge intelligence: A comprehensive survey on on-device ai models. ACM Comput. Surv.57(9) (Apr 2025).https: //doi.org/10.1145/3724420
-
[37]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Wasserman, N., et al.: REAL-MM-RAG: A real-world multi-modal retrieval benchmark. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Proceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers). pp. 31660–31683. Associ- ation for Computational Linguistics, Vienna, Austria (Jul 2025).https: //d...
-
[38]
Yang, A., et al.: Qwen3 technical report (2025),https://arxiv.org/abs/ 2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
-
[40]
Zhang, P., et al.: Tinyllama: An open-source small language model (2024), https://arxiv.org/abs/2401.02385
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Advances in neural information processing systems36, 46595–46623 (2023)
Zheng, L., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems36, 46595–46623 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.