SIR: Structured Image Representations for Explainable Robot Learning
Pith reviewed 2026-06-30 05:47 UTC · model grok-4.3
The pith
Robot policies learn to sparsify scene graphs from images end-to-end, raising task success while exposing dataset biases through the selected objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
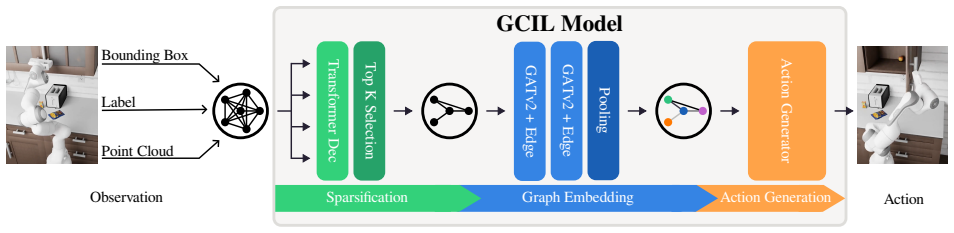
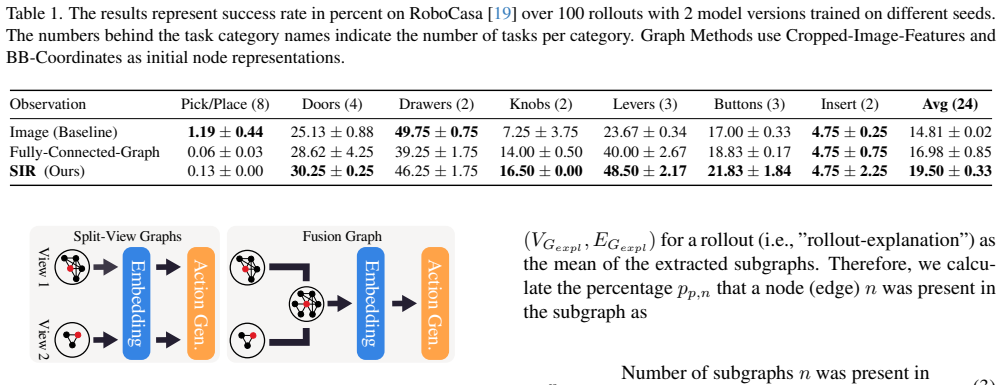
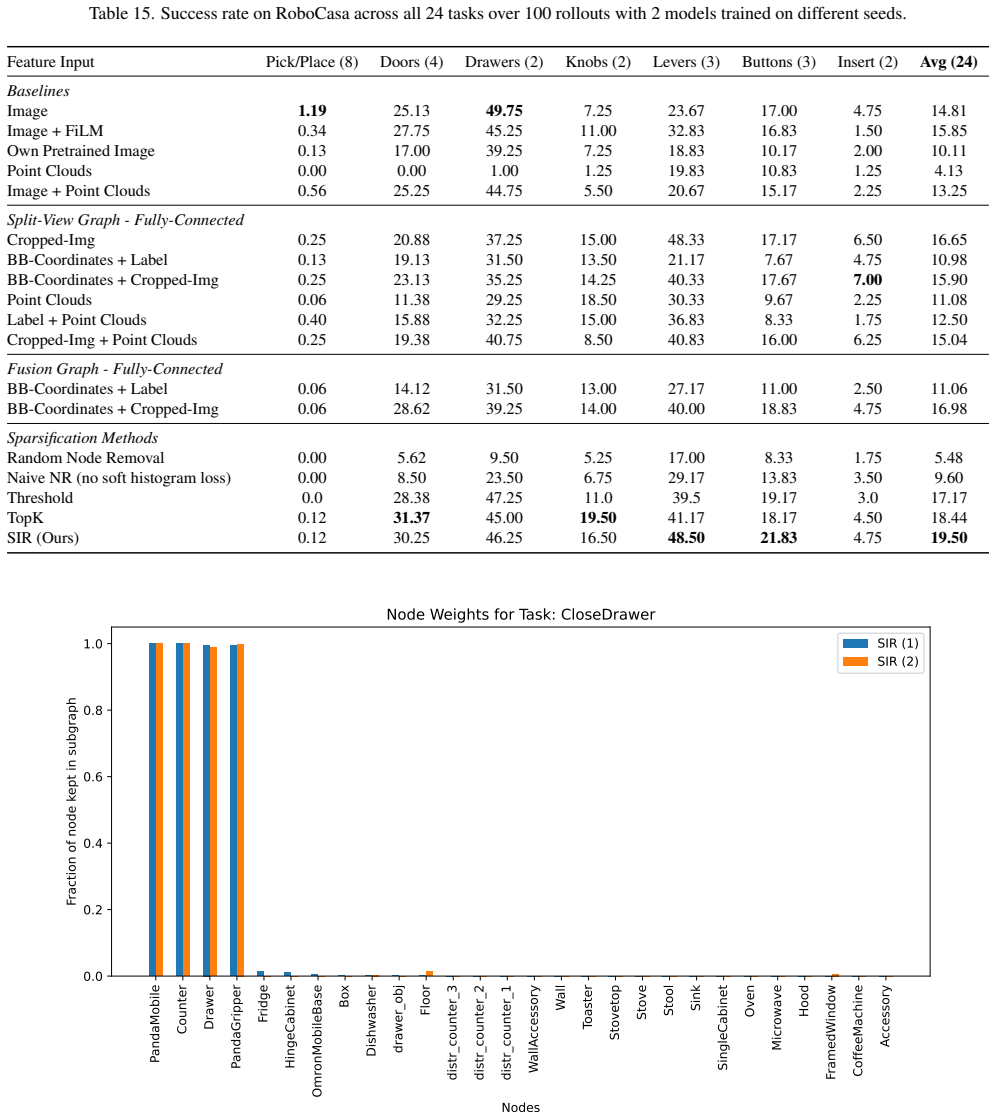
Our approach first constructs a fully connected graph, using image-derived features as initial node representations. Then, a module learns to sparsify this graph end-to-end, creating a task-relevant sub-graph that is passed to the action generation model. This process makes our model intrinsically explainable. Evaluations on RoboCasa show that our sparse graph policies outperform image-based baselines on average with 19.5% vs 14.81% success rate. Most importantly, we show that the learned sparse graphs are a powerful tool for model analysis. By analysing when the model's sub-graph deviates from human expectation, such as by including distractor nodes or omitting key objects, we successfully
What carries the argument
end-to-end learned sparsification module that prunes a fully connected scene graph of image features into a task-relevant sub-graph for the policy
If this is right
- Sparse graph policies reach 19.5 percent success versus 14.81 percent for image baselines on the RoboCasa benchmark.
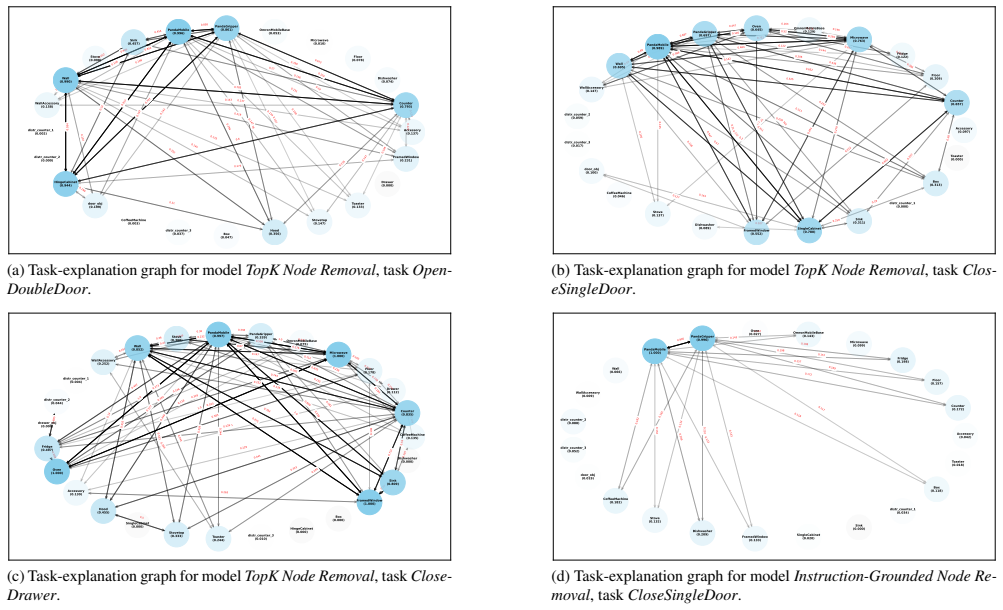
- Inspection of the learned sub-graphs reveals cases where the model includes distractor nodes or omits key objects.
- Such inspection identifies spurious correlations and positional biases present in the training dataset.
- The representation supplies intrinsic explainability because the policy's inputs are the explicit selected nodes rather than opaque embeddings.
Where Pith is reading between the lines
- If the sparsification proves stable across environments, the same graphs could serve as a bridge for transferring policies between simulation and real robots by focusing on object relations instead of pixel statistics.
- Dataset bias detection via graph inspection could be turned into an active data collection loop that flags and augments scenes where the model consistently selects the wrong nodes.
- The method suggests that many visual policy failures may stem from attending to the wrong objects, so similar sparsification layers might improve performance in other embodied tasks such as manipulation or navigation.
Load-bearing premise
The sparsification step selects sub-graphs that capture the true task-relevant objects and relations without omitting critical elements or adding distractors in ways the downstream policy cannot handle.
What would settle it
Re-training the identical policy head on the full unsparsified graph or on raw images and observing equal or higher success rates, or finding that the selected sub-graphs show no systematic relation to human-labeled task objects yet still produce the reported performance gains.
Figures


read the original abstract
Existing robot policies based on learned visual embeddings lack explicit structure and are sensitive to visual distractions. Thus, the representations that drive their behaviour are often opaque, making their decision-making process difficult to interpret. To address this, we introduce Structured Image Representations (SIR), a method that leverages Scene Graphs (SGs) as an intermediate representation for robot policy learning. Our approach first constructs a fully connected graph, using image-derived features as initial node representations. Then, a module learns to sparsify this graph end-to-end, creating a task-relevant sub-graph that is passed to the action generation model. This process makes our model intrinsically explainable. Evaluations on RoboCasa show that our sparse graph policies outperform image-based baselines on average with 19.5% vs 14.81% success rate. Most importantly, we show that the learned sparse graphs are a powerful tool for model analysis. By analysing when the model's sub-graph deviates from human expectation, such as by including distractor nodes or omitting key objects, we successfully uncover dataset biases, including spurious correlations and positional biases. https://github.com/intuitive-robots/SIR_Model
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Structured Image Representations (SIR) that build fully-connected scene graphs from image features, apply an end-to-end learned sparsification module to produce task-relevant sub-graphs, and feed these to an action-generation policy. On RoboCasa it reports average success rates of 19.5 % for the sparse-graph policies versus 14.81 % for image-based baselines and claims that analysis of deviations between the learned sub-graphs and human expectations reveals dataset biases such as spurious correlations and positional biases.
Significance. If the sparsified graphs can be shown to be both performance-critical and faithful to scene structure, the approach would supply a concrete mechanism for intrinsically explainable robot policies together with a diagnostic tool for data artifacts. The public code release is a clear asset. At present, however, the absence of statistical detail on the reported gains and the lack of controls that separate sparsifier behavior from policy behavior limit the strength of both the performance and the bias-analysis claims.
major comments (2)
- [Abstract] Abstract: aggregate success rates (19.5 % vs 14.81 %) are presented without variance, trial counts, statistical tests, or implementation details for the image-based baselines, so it is impossible to determine whether the reported lift is reliable or reproducible across seeds and environments.
- [Method (sparsification module)] Method description of the sparsification module: because the sparsifier is trained jointly with the policy on the same RoboCasa trajectories, any spurious correlation in the data can be exploited by node selection; the downstream policy then only needs to act on the selected nodes. This creates a circularity that affects both the performance attribution and the subsequent claim that graph deviations reliably expose dataset biases rather than model artifacts. No ablation that freezes the sparsifier, substitutes a fixed graph, or compares against human node labels is described.
Simulated Author's Rebuttal
We are grateful to the referee for highlighting issues with statistical reporting and the need for additional controls on the sparsification module. Below we provide point-by-point responses and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: aggregate success rates (19.5 % vs 14.81 %) are presented without variance, trial counts, statistical tests, or implementation details for the image-based baselines, so it is impossible to determine whether the reported lift is reliable or reproducible across seeds and environments.
Authors: We concur that the abstract would benefit from additional statistical information to allow readers to assess the reliability of the results. The full manuscript reports results over multiple seeds with standard deviations and specifies the number of evaluation episodes. We will revise the abstract to include these details, such as the number of trials and variance measures, along with a brief note on baseline implementations. revision: yes
-
Referee: [Method (sparsification module)] Method description of the sparsification module: because the sparsifier is trained jointly with the policy on the same RoboCasa trajectories, any spurious correlation in the data can be exploited by node selection; the downstream policy then only needs to act on the selected nodes. This creates a circularity that affects both the performance attribution and the subsequent claim that graph deviations reliably expose dataset biases rather than model artifacts. No ablation that freezes the sparsifier, substitutes a fixed graph, or compares against human node labels is described.
Authors: The referee correctly identifies a potential issue with joint end-to-end training. We will add text to the method section explaining that while the sparsifier can leverage data correlations, the resulting sub-graphs are still used to analyze model decisions by comparing them to human expectations. This comparison can reveal when the model attends to biased features. To further address the concern, we will include an ablation study comparing the learned sparsifier against a non-learned baseline (e.g., random sparsification) in the revised manuscript. We disagree that this necessarily invalidates the bias analysis, as the deviations are observed post-training and provide diagnostic value regardless of how the selection was learned. revision: partial
Circularity Check
No circularity; empirical pipeline with external benchmark evaluation
full rationale
The paper presents a learned end-to-end sparsification pipeline for scene graphs without any derivation chain, equations, or first-principles results. Performance claims rest on success-rate comparisons against image baselines on the external RoboCasa benchmark, and bias analysis is qualitative. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the text. The joint training of sparsifier and policy does not match any enumerated circularity pattern because no specific reduction to inputs by construction is exhibited.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scene graphs constructed from image-derived features contain nodes and edges that can be meaningfully sparsified for downstream control.
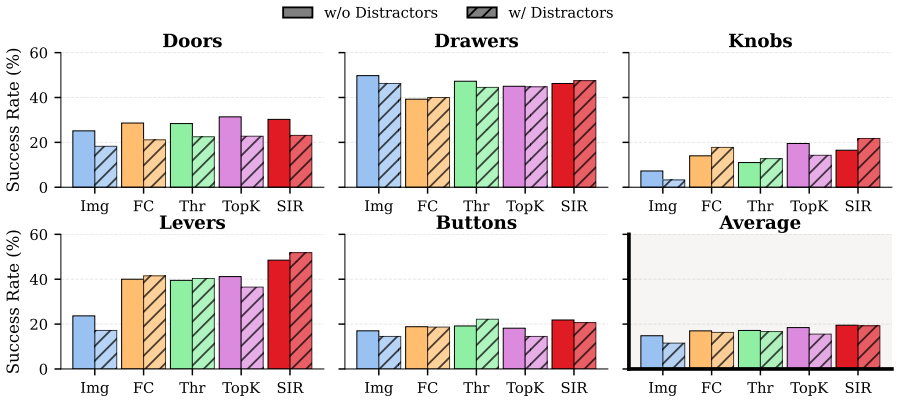
Reference graph
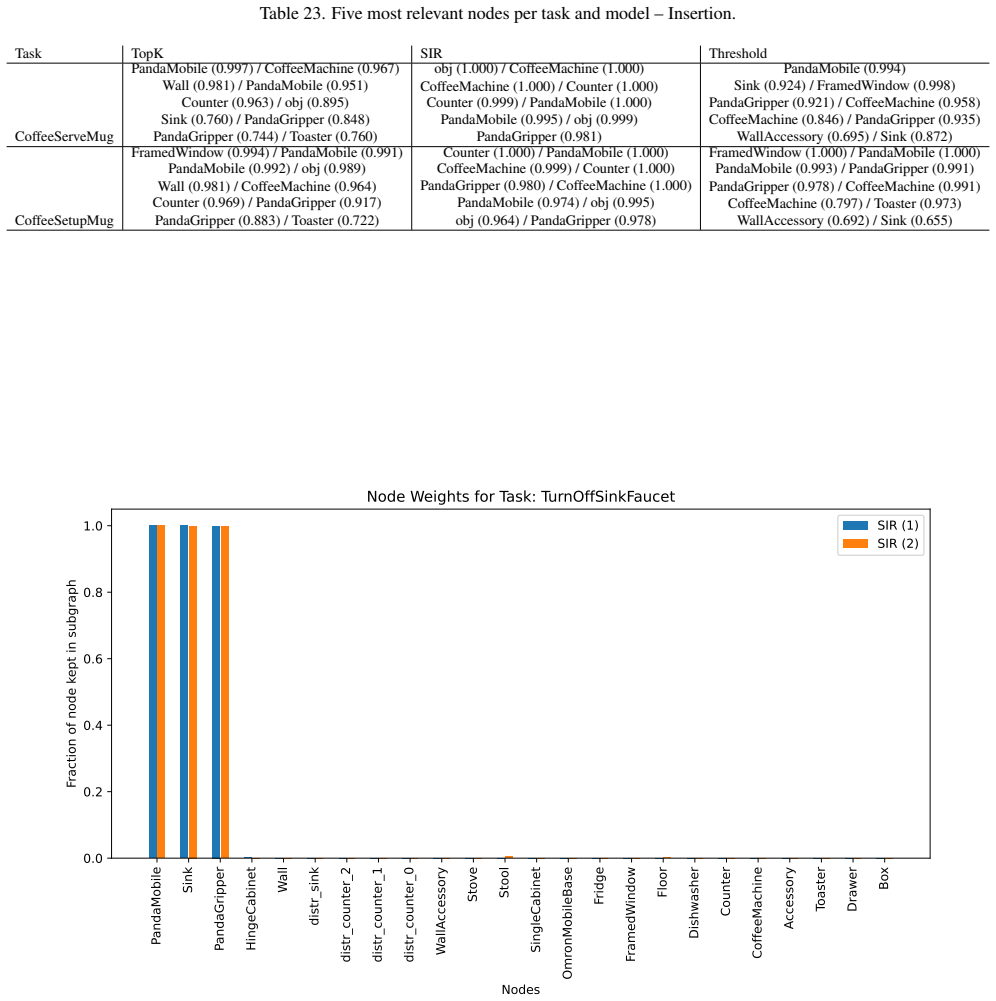
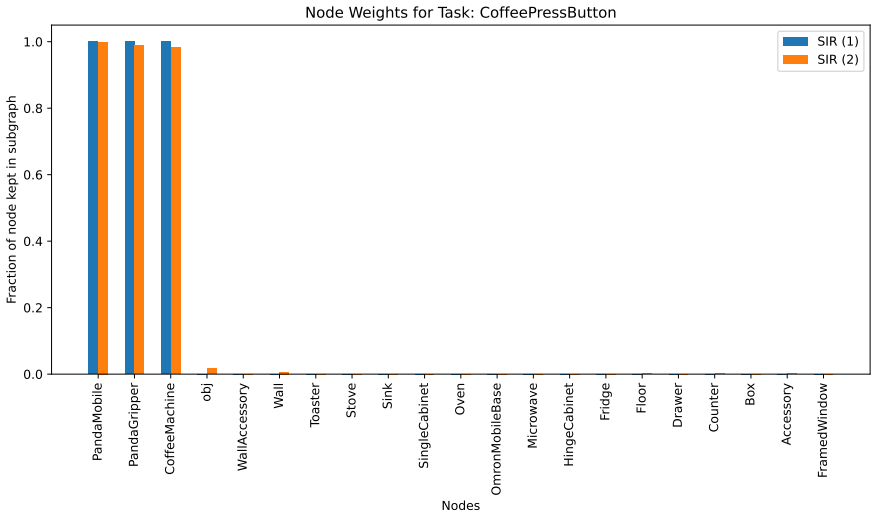
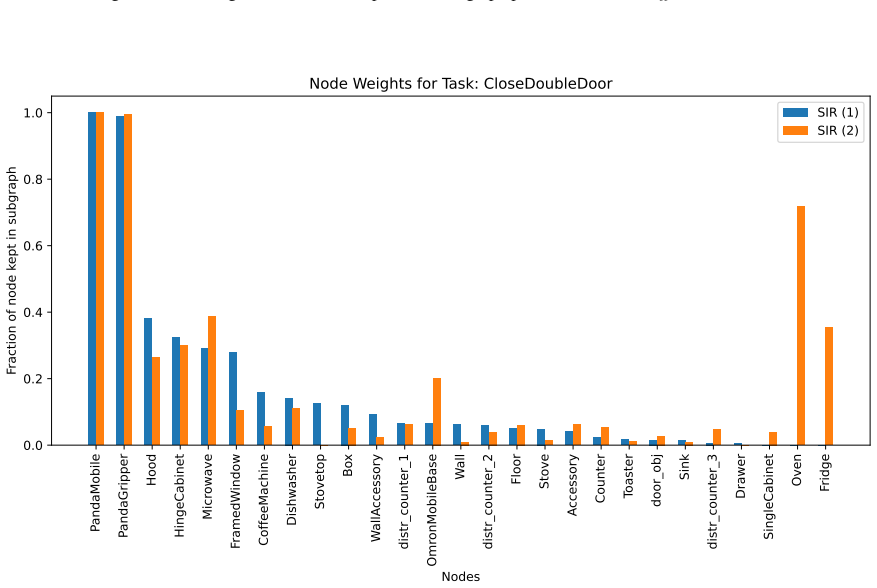
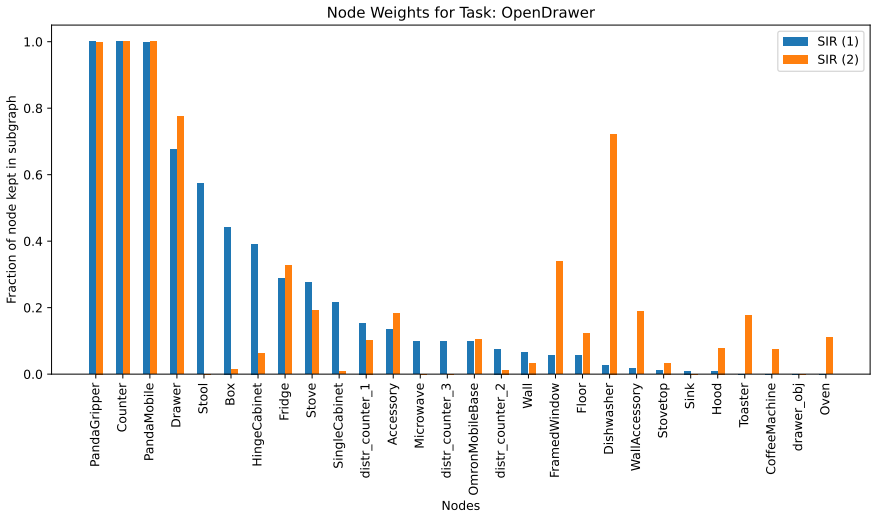
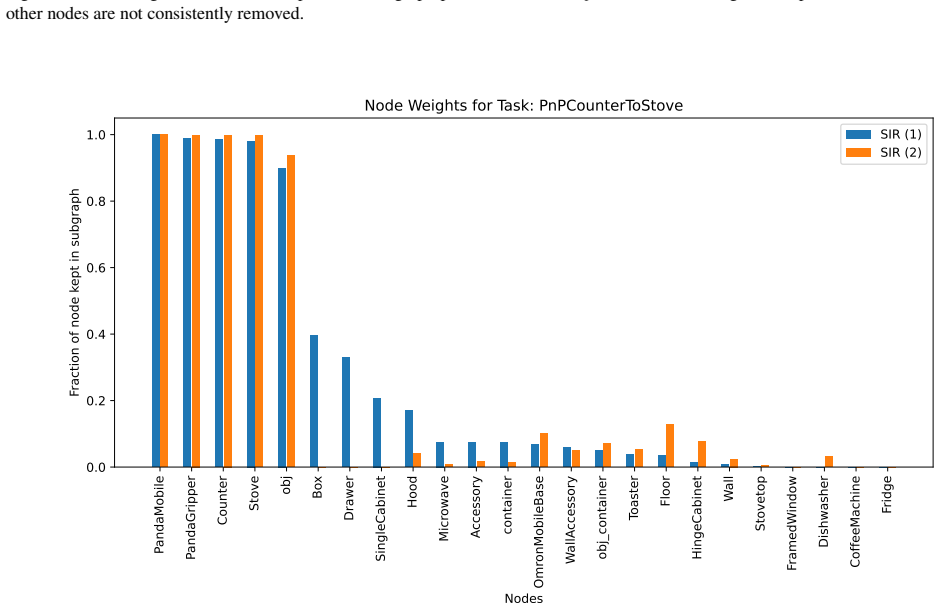
Works this paper leans on
-
[1]
A survey of robot learning from demon- stration.Robotics and autonomous systems, 57(5):469–483,
Brenna D Argall, Sonia Chernova, Manuela Veloso, and Brett Browning. A survey of robot learning from demon- stration.Robotics and autonomous systems, 57(5):469–483,
-
[2]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration. Open X-Embodiment: Robotic learning datasets and RT-X models.https:// arxiv.org/abs/2310.08864, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
One-shot imitation learning with graph neural networks for pick-and- place manipulation tasks.IEEE Robotics and Automation Letters, 2023
Francesco Di Felice, Salvatore D’Avella, Alberto Remus, Paolo Tripicchio, and Carlo Alberto Avizzano. One-shot imitation learning with graph neural networks for pick-and- place manipulation tasks.IEEE Robotics and Automation Letters, 2023. 2, 3
2023
-
[4]
Goal-conditioned imitation learning
Yiming Ding, Carlos Florensa, Pieter Abbeel, and Mari- ano Phielipp. Goal-conditioned imitation learning. InAd- vances in Neural Information Processing Systems. Curran Associates, Inc., 2019. 1
2019
-
[5]
Towards fusing point cloud and visual representations for imitation learning,
Atalay Donat, Xiaogang Jia, Xi Huang, Aleksandar Tara- novic, Denis Blessing, Ge Li, Hongyi Zhou, Hanyi Zhang, Rudolf Lioutikov, and Gerhard Neumann. Towards fusing point cloud and visual representations for imitation learning,
-
[6]
Imitation from observation using rl and graph-based repre- sentation of demonstrations
Yassine El Manyari, Patrick Le Callet, and Laurent Doll ´e. Imitation from observation using rl and graph-based repre- sentation of demonstrations. In2022 21st IEEE Interna- tional Conference on Machine Learning and Applications (ICMLA), pages 1258–1265. IEEE, 2022. 2
2022
-
[7]
Conceptgraphs: Open-vocabulary 3d scene graphs for per- ception and planning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for per- ception and planning. In2024 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 5021–5028. IEEE, 2024. 1, 3
2024
-
[8]
Aditya Prakash, and Wei Jin
Mohammad Hashemi, Shengbo Gong, Juntong Ni, Wenqi Fan, B. Aditya Prakash, and Wei Jin. A Comprehensive Survey on Graph Reduction: Sparsification, Coarsening, and Condensation. pages 8058–8066, 2024. ISSN: 1045-0823. 3
2024
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4, 1
2016
-
[10]
VIRL: Self-supervised visual graph inverse reinforcement learning
Lei Huang, Weijia Cai, Zihan Zhu, Chen Feng, Helge Rhodin, and Zhengbo Zou. VIRL: Self-supervised visual graph inverse reinforcement learning. In8th Annual Confer- ence on Robot Learning, 2024. 3
2024
-
[11]
Graph inverse reinforcement learning from diverse videos
Sateesh Kumar, Jonathan Zamora, Nicklas Hansen, Rishabh Jangir, and Xiaolong Wang. Graph inverse reinforcement learning from diverse videos. InProceedings of The 6th Con- ference on Robot Learning, pages 55–66. PMLR, 2023. 3
2023
-
[12]
Self-Attention Graph Pooling
Junhyun Lee, Inyeop Lee, and Jaewoo Kang. Self-Attention Graph Pooling. InProceedings of the 36th International Conference on Machine Learning, pages 3734–3743. PMLR,
-
[13]
Kai Li, Zhao Ma, Liang Li, and Shiyu Zhao. Collective behavior clone with visual attention via neural interaction graph prediction.arXiv preprint arXiv:2503.06869, 2025. 3
-
[14]
Multi-objective photoreal simulation (mops) dataset for computer vision in robotic manipulation
Maximilian Xiling Li, Paul Mattes, Nils Blank, Ko- rbinian Franz Rudolf, Paul Werner L ¨odige, and Rudolf Li- outikov. Multi-objective photoreal simulation (mops) dataset for computer vision in robotic manipulation. InStructured World Models for Robotic Manipulation, 2025. 1
2025
-
[15]
Efficient and interpretable robot manipulation with graph neural networks.IEEE Robotics and Automation Let- ters, 7(2):2740–2747, 2022
Yixin Lin, Austin S Wang, Eric Undersander, and Akshara Rai. Efficient and interpretable robot manipulation with graph neural networks.IEEE Robotics and Automation Let- ters, 7(2):2740–2747, 2022. 2, 3
2022
-
[16]
Chuang Liu, Wenhang Yu, Kuang Gao, Xueqi Ma, Yibing Zhan, Jia Wu, Bo Du, and Wenbin Hu. Careful Selection and Thoughtful Discarding: Graph Explicit Pooling Utiliz- ing Discarded Nodes, 2023. arXiv:2311.12644 [cs]. 3
-
[17]
What mat- ters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiri- any, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Mart´ın-Mart´ın. What mat- ters in learning from offline human demonstrations for robot manipulation. In5th Annual Conference on Robot Learning,
-
[18]
Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manip- ulation tasks.IEEE Robotics and Automation Letters, 7(3): 7327–7334, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wol- fram Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manip- ulation tasks.IEEE Robotics and Automation Letters, 7(3): 7327–7334, 2022. 2, 4, 1
2022
-
[19]
Robocasa: Large-scale simulation of every- day tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of every- day tasks for generalist robots. InRobotics: Science and Systems (RSS), 2024. 2, 4, 5, 6, 1
2024
-
[20]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherl...
2024
-
[21]
An algorithmic perspective on imitation learning.Foundations and Trends® in Robotics, 7(1-2):1–179, 2018
Takayuki Osa, Joni Pajarinen, Gerhard Neumann, J Andrew Bagnell, Pieter Abbeel, Jan Peters, et al. An algorithmic perspective on imitation learning.Foundations and Trends® in Robotics, 7(1-2):1–179, 2018. 1
2018
-
[22]
Imitating human behaviour with diffusion models
Tim Pearce, Tabish Rashid, Anssi Kanervisto, Dave Bignell, Mingfei Sun, Raluca Georgescu, Sergio Valcarcel Macua, Shan Zheng Tan, Ida Momennejad, Katja Hofmann, and Sam Devlin. Imitating human behaviour with diffusion models. In The Eleventh International Conference on Learning Repre- sentations, 2023. 1
2023
-
[23]
FiLM: Visual Reasoning with a General Conditioning Layer.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), 2018
Ethan Perez, Florian Strub, Harm de Vries, Vincent Du- moulin, and Aaron Courville. FiLM: Visual Reasoning with a General Conditioning Layer.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), 2018. 4
2018
-
[24]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660,
-
[25]
Compose by focus: Scene graph-based atomic skills, 2025
Han Qi, Changhe Chen, and Heng Yang. Compose by focus: Scene graph-based atomic skills, 2025. 2, 3, 8
2025
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, 2021. 4
2021
-
[27]
Learnt Sparsification for Inter- pretable Graph Neural Networks, 2021
Mandeep Rathee, Zijian Zhang, Thorben Funke, Megha Khosla, and Avishek Anand. Learnt Sparsification for Inter- pretable Graph Neural Networks, 2021. arXiv:2106.12920 [cs]. 3
-
[28]
Goal conditioned imitation learning using score- based diffusion policies
Moritz Reuss, Maximilian Li, Xiaogang Jia, and Rudolf Li- outikov. Goal conditioned imitation learning using score- based diffusion policies. InRobotics: Science and Systems,
-
[29]
Multimodal diffusion transformer: Learn- ing versatile behavior from multimodal goals
Moritz Reuss, ¨Omer Erdinc ¸ Ya˘gmurlu, Fabian Wenzel, and Rudolf Lioutikov. Multimodal diffusion transformer: Learn- ing versatile behavior from multimodal goals. InRobotics: Science and Systems, 2024. 1, 3, 4
2024
-
[30]
FLOWER: Democratizing generalist robot policies with efficient vision- language-flow models
Moritz Reuss, Hongyi Zhou, Marcel R ¨uhle, ¨Omer Erdinc ¸ Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. FLOWER: Democratizing generalist robot policies with efficient vision- language-flow models. In9th Annual Conference on Robot Learning, 2025. 1
2025
-
[31]
Behavior transformers: Cloning kmodes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Al- tanzaya, and Lerrel Pinto. Behavior transformers: Cloning kmodes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022. 1
2022
-
[32]
Graph-structured visual im- itation
Maximilian Sieb, Zhou Xian, Audrey Huang, Oliver Kroe- mer, and Katerina Fragkiadaki. Graph-structured visual im- itation. InConference on Robot Learning, pages 979–989. PMLR, 2020. 3
2020
-
[33]
Scene graph contrastive learning for embodied navigation
Kunal Pratap Singh, Jordi Salvador, Luca Weihs, and Aniruddha Kembhavi. Scene graph contrastive learning for embodied navigation. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 10884– 10894, 2023. 2
2023
-
[34]
Maximum likelihood training of score-based diffusion mod- els.Advances in neural information processing systems, 34: 1415–1428, 2021
Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum likelihood training of score-based diffusion mod- els.Advances in neural information processing systems, 34: 1415–1428, 2021. 1
2021
-
[35]
3d-oes: Viewpoint-invariant object-factorized environment simulators, 2020
Hsiao-Yu Fish Tung, Zhou Xian, Mihir Prabhudesai, Shamit Lal, and Katerina Fragkiadaki. 3d-oes: Viewpoint-invariant object-factorized environment simulators, 2020. 2, 3
2020
-
[36]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017. 1, 4
2017
-
[37]
Instant policy: In- context imitation learning via graph diffusion
Vitalis V osylius and Edward Johns. Instant policy: In- context imitation learning via graph diffusion. InThe Thir- teenth International Conference on Learning Representa- tions, 2025. 2, 3
2025
-
[38]
Learning to Reduce the Scale of Large Graphs: A Comprehensive Survey.ACM Trans
Hongjia Xu, Liangliang Zhang, Yao Ma, Sheng Zhou, Zhuo- nan Zheng, and Jiajun Bu. Learning to Reduce the Scale of Large Graphs: A Comprehensive Survey.ACM Trans. Knowl. Discov. Data, 19(5):101:1–101:25, 2025. 3
2025
-
[39]
Sparse Graph Attention Networks
Yang Ye and Shihao Ji. Sparse Graph Attention Networks. IEEE Transactions on Knowledge and Data Engineering, 35 (1):905–916, 2023. 3, 1
2023
-
[40]
A Recipe for Causal Graph Regression: Confounding Effects Revisited
Yujia Yin, Tianyi Qu, Zihao Wang, and Yifan Chen. A Recipe for Causal Graph Regression: Confounding Effects Revisited. 2025. 3, 1
2025
-
[41]
Hierarchical Graph Rep- resentation Learning with Differentiable Pooling
Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. Hierarchical Graph Rep- resentation Learning with Differentiable Pooling. InAd- vances in Neural Information Processing Systems. Curran Associates, Inc., 2018. 3
2018
-
[42]
Graph Sparsifi- cation via Mixture of Graphs, 2024
Guibin Zhang, Xiangguo Sun, Yanwei Yue, Chonghe Jiang, Kun Wang, Tianlong Chen, and Shirui Pan. Graph Sparsifi- cation via Mixture of Graphs, 2024. arXiv:2405.14260 [cs]. 3
-
[43]
Robust Graph Representation Learning via Neural Sparsification
Cheng Zheng, Bo Zong, Wei Cheng, Dongjin Song, Jingchao Ni, Wenchao Yu, Haifeng Chen, and Wei Wang. Robust Graph Representation Learning via Neural Sparsification. In Proceedings of the 37th International Conference on Ma- chine Learning, pages 11458–11468. PMLR, 2020. ISSN: 2640-3498. 3
2020
-
[44]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Mart ´ın- Mart´ın, Abhishek Joshi, Kevin Lin, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation frame- work and benchmark for robot learning. InarXiv preprint arXiv:2009.12293, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[45]
Hierarchical planning for long-horizon manipulation with geometric and symbolic scene graphs
Yifeng Zhu, Jonathan Tremblay, Stan Birchfield, and Yuke Zhu. Hierarchical planning for long-horizon manipulation with geometric and symbolic scene graphs. In2021 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 6541–6548. IEEE, 2021. 2, 3
2021
-
[46]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 1 SIR: Structured Image Representations for Explainable Robot Learning Supplementary Material
2023
-
[47]
Additional information Source code will be made publicly available upon accep- tance. Our GNN implementation employs residual connec- tions and normalization to mitigate oversmoothing, a phe- nomenon to which small, fully-connected graphs are partic- ularly susceptible. 8.1. Pre-Trained Models The pre-trained models for generating Cropped-Image- Features ...
-
[48]
How- ever, when combining Cropped-Image-Features with BB- Coordinates, we use a smaller ResNet8 backbone with an embedding dimension of 37
backbone with an embedding dimension of 256. How- ever, when combining Cropped-Image-Features with BB- Coordinates, we use a smaller ResNet8 backbone with an embedding dimension of 37. This lower dimension was chosen specifically to match the size of the object label vec- tors (one-hot encoded length of 37), allowing the visual fea- tures to serve as a di...
-
[49]
Ad- ditionally, we provide fine-grained performance metrics for Table 4
Additional Evaluation Results The following sections present results for SIR using BC, generated graphs and the CALVIN benchmark [18]. Ad- ditionally, we provide fine-grained performance metrics for Table 4. Ablation results on RoboCasa using generated graphs, which are predicted using a fine-tuned DETR model. Models are not trained on these generated gra...
-
[50]
Additional Explainability Results We further present additional explainability results for SIR on 6 tasks in RoboCasa, not present in the main paper, as well as a Grad-CAM visualization of the image baseline models. 10.1. Sub-Graph Statistics The generated explanations by the different models are pre- sented in Tab. 17, Tab. 18, Tab. 19, Tab. 20, Tab. 21,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.