KnowsTFM: Knowledge-Informed Fine-Tuning of Small Tabular Foundation Models
Pith reviewed 2026-06-30 07:40 UTC · model grok-4.3
The pith
Fine-tuning small tabular foundation models with knowledge graph priors yields gains in specialist domains but marginal benefits on general tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KnowsTFM adapts nanoscale TabPFN- and TabICL-style models by deriving structural attention priors from knowledge graphs and applying parameter-efficient low-rank updates. This yields meaningful gains over vanilla variants in specialist settings with scarce, high-dimensional, shifted data, while gains on general-domain tasks are marginal. Continual fine-tuning of frontier models can trigger collapse of pretrained knowledge and mechanisms.
What carries the argument
Structural attention priors derived from knowledge graphs, which are injected into the model via parameter-efficient low-rank updates to steer adaptation using relational domain knowledge.
If this is right
- Specialist tabular tasks receive meaningful performance lifts from the injected structural priors.
- General-domain tabular tasks receive only marginal additional benefit from the same priors.
- Continual fine-tuning of frontier-scale models can cause collapse of their pretrained knowledge and mechanisms.
- The approach applies to nanoscale variants pretrained under controlled synthetic priors.
Where Pith is reading between the lines
- Domains already equipped with knowledge graphs could adapt models with less new labeled data.
- The same graph-to-attention translation might be tested on sequence or graph-structured data beyond tables.
- Graph quality checks would likely be required before deployment to prevent noise injection.
- Scaling the method to medium-sized models could reveal whether the gains persist or diminish.
- keywords:[
- tabular foundation models
- knowledge graphs
- fine-tuning
Load-bearing premise
Curated knowledge graphs supply structural priors that translate cleanly into attention mechanisms and improve performance without introducing domain-specific noise.
What would settle it
Running the fine-tuning procedure on a specialist dataset with the knowledge graph priors removed or randomized, then observing no performance drop relative to the full method, would falsify the central benefit claim.
Figures





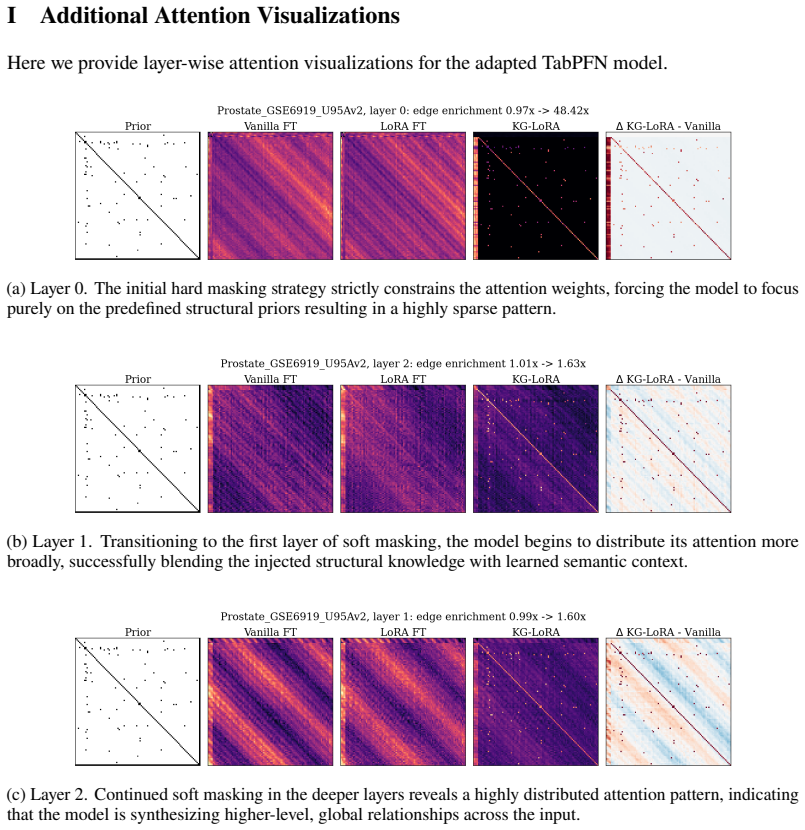
read the original abstract
Tabular foundation models have advanced deep learning for tabular data by delivering strong default performance across many small and medium tasks. Yet in niche domains, where data is scarce, high-dimensional, and shifted from the pretraining distribution, they may still fail to outperform carefully designed domain-specific methods. Many such domains also provide curated relational knowledge in the form of knowledge graphs and knowledge banks, but how to use this knowledge to improve and steer \textit{small} specialist tabular foundation models remains unclear. We address this problem through \textbf{Know}ledge-informed fine-tuning of \textbf{s}mall \textbf{T}abular \textbf{F}oundation \textbf{M}odels (\modelname). Specifically, we study nanoscale TabPFN- and TabICL-style variants, pretrained under controlled synthetic prior families and adapted using two complementary mechanisms: structural attention priors derived from knowledge graphs and parameter-efficient low-rank updates. We show that injecting domain-specific structural knowledge during fine-tuning yields meaningful gains over vanilla variants in specialist settings, whereas gains on general-domain tasks are marginal. We further observe that continual fine-tuning of frontier models can trigger collapse of pretrained knowledge and mechanisms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KnowsTFM, a method for knowledge-informed fine-tuning of small tabular foundation models (nanoscale TabPFN- and TabICL-style variants pretrained under controlled synthetic priors). It adapts these models via two mechanisms: structural attention priors derived from knowledge graphs and parameter-efficient low-rank updates. The central claim is that injecting domain-specific structural knowledge during fine-tuning yields meaningful gains over vanilla variants in specialist settings with scarce/high-dimensional/shifted data, while gains on general-domain tasks are marginal; it further observes that continual fine-tuning of frontier models can trigger collapse of pretrained knowledge.
Significance. If the empirical results hold with proper controls, this work would be significant for adapting tabular foundation models to niche domains where curated knowledge graphs exist. The emphasis on small models, controlled synthetic pretraining families, and the identification of collapse risks during continual adaptation are explicit strengths that could guide practical deployment and future research on domain-knowledge integration.
major comments (2)
- [Method (graph-to-attention construction)] The central claim of meaningful gains in specialist settings rests on the assumption that knowledge-graph structural priors translate cleanly into attention mechanisms without introducing domain-specific noise. The manuscript must include targeted ablations or validation of the graph-to-attention mapping (e.g., in the method section describing the prior construction) to substantiate this; absent such evidence the performance improvement cannot be confidently attributed to the proposed mechanism rather than other factors.
- [Experimental Results] The empirical support for the specialist-setting gains is load-bearing yet the provided abstract supplies no baselines, statistical tests, ablation results, or dataset details. The experimental section must report these (including quantitative effect sizes and controls for the low-rank updates) to allow assessment of whether the data actually support the claim; without them the central contribution remains unevaluable.
minor comments (1)
- [Abstract] The abstract would benefit from one sentence clarifying the scale of the 'nanoscale' variants and the specific specialist domains evaluated.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (graph-to-attention construction)] The central claim of meaningful gains in specialist settings rests on the assumption that knowledge-graph structural priors translate cleanly into attention mechanisms without introducing domain-specific noise. The manuscript must include targeted ablations or validation of the graph-to-attention mapping (e.g., in the method section describing the prior construction) to substantiate this; absent such evidence the performance improvement cannot be confidently attributed to the proposed mechanism rather than other factors.
Authors: We agree that explicit validation of the graph-to-attention construction is necessary to attribute gains specifically to the structural priors. The revised manuscript will add a new subsection in the method section containing targeted ablations: (i) the proposed knowledge-graph-derived priors, (ii) random graph priors with matched density, and (iii) shuffled edge variants. These will be evaluated on the specialist tasks to isolate the contribution of domain-specific structure from generic attention modifications. revision: yes
-
Referee: [Experimental Results] The empirical support for the specialist-setting gains is load-bearing yet the provided abstract supplies no baselines, statistical tests, ablation results, or dataset details. The experimental section must report these (including quantitative effect sizes and controls for the low-rank updates) to allow assessment of whether the data actually support the claim; without them the central contribution remains unevaluable.
Authors: Abstracts are intentionally concise and omit such details by convention. The experimental section (Section 4) already reports multiple baselines (vanilla TabPFN/TabICL, domain-specific tabular methods), ablation studies separating the structural prior from low-rank updates, full dataset descriptions, and quantitative performance numbers across specialist and general tasks. To further address the concern we will add: (a) paired statistical tests with p-values and effect sizes (Cohen’s d), and (b) an explicit control experiment that applies low-rank updates alone without the graph prior. These additions will be included in the revision. revision: partial
Circularity Check
No significant circularity; derivation relies on external knowledge graphs
full rationale
The paper proposes a fine-tuning method that injects structural priors from external knowledge graphs into small tabular foundation models via attention mechanisms and low-rank updates. No derivation step reduces to a self-definition, fitted input renamed as prediction, or self-citation chain; the central claim is an empirical demonstration of gains on specialist tasks using independently curated graphs. The approach is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from the authors' prior work as load-bearing justification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan,MohammadAflahKhan,ShivanshuPurohit,USPrashanth,EdwardRaff,etal. Pythia: A suite for analyzing large language models across training and scaling. InInternational Conference on Machine Learning, pages 2397–2423. PMLR, 2023
2023
-
[2]
Random forests.Mach
Leo Breiman. Random forests.Mach. Learn., 45(1):5–32, October 2001
2001
-
[3]
Building a knowledge graph to enable precision medicine.Scientific Data, 10:67, 2023
Payal Chandak, Kexin Huang, and Marinka Zitnik. Building a knowledge graph to enable precision medicine.Scientific Data, 10:67, 2023
2023
-
[4]
Extending the small-molecule similarity principle to all levels of biology with the chemical checker.Nature Biotechnology, 38(9):1087–1096, 2020
MiquelDuran-Frigola,EduardoPauls,OriolGuitart-Pla,MartinoBertoni,VíctorAlcalde,David Amat, Teresa Juan-Blanco, and Patrick Aloy. Extending the small-molecule similarity principle to all levels of biology with the chemical checker.Nature Biotechnology, 38(9):1087–1096, 2020
2020
-
[5]
Bruno César Feltes, Eduardo Bassani Chandelier, Bruno Iochins Grisci, and Márcio Dorn. Cumida: An extensively curated microarray database for benchmarking and testing of machine learning approaches in cancer research.Journal of Computational Biology, 26(4):376–386, 2019
2019
-
[6]
Tunetables: Context optimization for scalable prior-data fitted networks
Benjamin Feuer, Robin Tibor Schirrmeister, Valeriia Cherepanova, Chinmay Hegde, Frank Hutter, Micah Goldblum, Niv Cohen, and Colin White. Tunetables: Context optimization for scalable prior-data fitted networks. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[7]
Does fine-tuning llms on new knowledge encourage hallucinations? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7765–7784, 2024
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig. Does fine-tuning llms on new knowledge encourage hallucinations? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7765–7784, 2024
2024
-
[8]
Tabpfn-2.5: Advancing the state of the art in tabular foundation models, 2025
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger,DominikSafaric,SimoneAlessi,AdrianHayler,MihirManium,RosenYu,FelixJablonski, Shi Bin Hoo, Anurag Garg, Jake Robertson, Magnus Bühler, Vladyslav Moroshan, Lennart Purucker, Clara Cornu, Lilly Charlotte Wehrhahn, Alessandro Bonetto, Bernhard Schölkopf, Sauraj ...
2025
-
[9]
OLMo: Accelerating the science of language 10 models
Dirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Cry...
2024
-
[10]
GraphCodeBERT: Pre-training code representations with data flow
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. GraphCodeBERT: Pre-training code representations with data flow. InInternational Conference on Learning Representations, 2021
2021
-
[11]
Hellendoorn, Charles Sutton, Rishabh Singh, Miltiadis Allamanis, and Marc Brockschmidt
Vincent J. Hellendoorn, Charles Sutton, Rishabh Singh, Miltiadis Allamanis, and Marc Brockschmidt. Global relational models of source code. InInternational Conference on Learning Representations, 2020
2020
-
[12]
Autorank: A python package for automated ranking of classifiers.Journal of Open Source Software, 5(48):2173, 2020
Steffen Herbold. Autorank: A python package for automated ranking of classifiers.Journal of Open Source Software, 5(48):2173, 2020
2020
-
[13]
TabPFN: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InInternational ConferenceonLearningRepresentations,2023. OriginallypresentedattheTableRepresentation Learning Workshop at NeurIPS 2022
2023
-
[14]
Accurate predictions on small data with a tabular foundation model.Nature, 637:319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637:319–326, 2025
2025
-
[15]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giber, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. InInternational Conference on Machine Learning, pages 2790–2799, 2019
2019
-
[16]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[17]
Tabstruct: Measuring structural fidelityoftabulardata
Xiangjian Jiang, Nikola Simidjievski, and Mateja Jamnik. Tabstruct: Measuring structural fidelityoftabulardata. InTheFourteenthInternationalConferenceonLearningRepresentations, 2026
2026
-
[18]
CARTE: Pretraining and transfer for tabular learning
Myung Jun Kim, Leo Grinsztajn, and Gael Varoquaux. CARTE: Pretraining and transfer for tabular learning. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Res...
2024
-
[19]
Understanding catastrophic forgetting in languagemodelsviaimplicitinference.InInternationalConferenceonLearningRepresentations, 2024
Suhas Kotha, Jacob Springer, and Aditi Raghunathan. Understanding catastrophic forgetting in languagemodelsviaimplicitinference.InInternationalConferenceonLearningRepresentations, 2024
2024
-
[20]
Kuenzi, Jisoo Park, Samson H
Brent M. Kuenzi, Jisoo Park, Samson H. Fong, Kyle S. Sanchez, John Lee, Jason F. Kreisberg, JianzhuMa, andTreyIdeker. Predictingdrugresponseandsynergyusingadeeplearningmodel of human cancer cells.Cancer Cell, 38(5):672–684, 2020
2020
-
[21]
Revisiting catastrophic forgetting in large language model tuning
Hongyu Li, Liang Ding, Meng Fang, and Dacheng Tao. Revisiting catastrophic forgetting in large language model tuning. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4297–4308, Miami, Florida, USA, November 2024. Association for Computational Linguistics
2024
-
[22]
DeepCDR: A hybrid graph convolutional network for predicting cancer drug response.Bioinformatics, 36(Supplement_2):i911–i918, 2020
Qiao Liu, Zhiqiang Hu, Rui Jiang, and Mu Zhou. DeepCDR: A hybrid graph convolutional network for predicting cancer drug response.Bioinformatics, 36(Supplement_2):i911–i918, 2020. 11
2020
-
[23]
K-BERT: Enablinglanguagerepresentationwithknowledgegraph
WeijieLiu,PengZhou,ZheZhao,ZhiruoWang,QiJu,HaotangDeng,andPingWang. K-BERT: Enablinglanguagerepresentationwithknowledgegraph. InProceedingsoftheAAAIConference on Artificial Intelligence, volume 34, pages 2901–2908, 2020
2020
-
[24]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[25]
KnowLA: Enhancing parameter- efficientfinetuningwithknowledgeableadaptation
Xindi Luo, Zequn Sun, Jing Zhao, Zhe Zhao, and Wei Hu. KnowLA: Enhancing parameter- efficientfinetuningwithknowledgeableadaptation. InProceedingsofthe2024Conferenceofthe North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 7153–7166, 2024
2024
-
[26]
Tabdpt: Scaling tabular foundation models on real data
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Alex Labach, Jesse Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L Caterini, and Maks Volkovs. Tabdpt: Scaling tabular foundation models on real data. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume 38, pa...
2025
-
[27]
Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering, 36(7):3580–3599, 2024
Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering, 36(7):3580–3599, 2024
2024
-
[28]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[29]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[30]
Peters, Mark Neumann, Robert Logan, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A
Matthew E. Peters, Mark Neumann, Robert Logan, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A. Smith. Knowledge enhanced contextual word representations. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 43–54, 2019
2019
-
[31]
Alexander Pfefferle, Johannes Hog, Lennart Purucker, and Frank Hutter. nanotabpfn: A lightweight and educational reimplementation of tabpfn.arXiv preprint arXiv:2511.03634, 2025
-
[32]
TabICL: A tabular foundation model for in-context learning on large data, 2025
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data, 2025
2025
-
[33]
On finetuning tabular foundation models, 2025
Ivan Rubachev, Nikolay Kartashev, Yury Gorishniy, and Artem Babenko. On finetuning tabular foundation models, 2025
2025
-
[34]
PLATO: High dimensional, tabular deep learning with an auxiliary knowledge graph
Avi Rubin Ruiz, Hongyu Ren, Hao Huang, and Jure Leskovec. PLATO: High dimensional, tabular deep learning with an auxiliary knowledge graph. InAdvances in Neural Information Processing Systems, 2023
2023
-
[35]
Jihye Shin, Yinhua Piao, Dongmin Bang, Sungsoo Kim, and Kyuri Jo. DRPreter: Interpretable anticancer drug response prediction using knowledge-guided graph neural networks and transformer.International Journal of Molecular Sciences, 23(22):13919, 2022
2022
-
[36]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Caterini
Valentin Thomas, Junwei Ma, Rasa Hosseinzadeh, Keyvan Golestan, Guangwei Yu, Maksims Volkovs, and Anthony L. Caterini. Retrieval & fine-tuning for in-context tabular models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 12
2024
-
[38]
KG-Adapter: Enabling knowledge graph integration in large language models through parameter-efficient fine-tuning
Shiyu Tian, Yangyang Luo, Tianze Xu, Caixia Yuan, Huixing Jiang, Chen Wei, and Xiaojie Wang. KG-Adapter: Enabling knowledge graph integration in large language models through parameter-efficient fine-tuning. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3813–3828, 2024
2024
-
[39]
Kblam: Knowledge base augmented language model
Xi Wang, Taketomo Isazawa, Liana Mikaelyan, and James Hensman. Kblam: Knowledge base augmented language model. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors, International Conference on Learning Representations, volume 2025, pages 51629–51658, 2025
2025
-
[40]
Two-stage llm fine-tuning with less specialization and more generalization
Yihan Wang, Si Si, Daliang Li, Michal Lukasik, Felix Yu, Cho-Jui Hsieh, Inderjit Dhillon, and Sanjiv Kumar. Two-stage llm fine-tuning with less specialization and more generalization. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, editors,International Conference on Learning Representations, volume 2024, pages 20380–20398, 2024
2024
-
[41]
TransTab: Learning transferable tabular transformers across tables
Zifeng Wang and Jimeng Sun. TransTab: Learning transferable tabular transformers across tables. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[42]
Manning, Percy Liang, and Jure Leskovec
Michihiro Yasunaga, Antoine Bosselut, Hongyu Ren, Xikun Zhang, Christopher D. Manning, Percy Liang, and Jure Leskovec. Deep bidirectional language-knowledge graph pretraining. In Advances in Neural Information Processing Systems, volume 35, 2022
2022
-
[43]
LLMasentitydisambiguatorforbiomedicalentity-linking
ChristopheYeandCassieS.Mitchell. LLMasentitydisambiguatorforbiomedicalentity-linking. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedingsofthe63rdAnnualMeetingoftheAssociationforComputationalLinguistics(Volume 2: Short Papers), pages 301–312, Vienna, Austria, July 2025. Association for Computational Linguistics
2025
-
[44]
Manning, and Jure Leskovec
Xikun Zhang, Antoine Bosselut, Michihiro Yasunaga, Hongyu Ren, Percy Liang, Christopher D. Manning, and Jure Leskovec. GreaseLM: Graph reasoning enhanced language models. In International Conference on Learning Representations, 2022
2022
-
[45]
Mitra: Mixed synthetic priors for enhancing tabular foundation models
Xiyuan Zhang, Danielle Maddix Robinson, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael Mahoney, Tony Hu, Huzefa Rangwala, George Karypis, and Yuyang (Bernie) Wang. Mitra: Mixed synthetic priors for enhancing tabular foundation models. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Konius...
2025
-
[46]
Project the KG onto the feature axisSection 3.2) 1: for f∈c 1:F: qf ← MapToEntity(f,KG ) ▷biomedical: PrimeKG; general: agentic Wikidata; ∅if unmapped 2:S (ρ) ij ←⊮[ (q i,∗, q j)∈Ewithinρhops, q i, qj ̸=∅]
-
[47]
Build per-block injection slots(Section 3.3) 3:Φ← ∅▷trainable parameters 4:forℓ= 1, . . . , Ldo 5:ifσ ℓ =offthen 6:continue 7:else ifσ ℓ =hardthen 8:M (ℓ) ij ←0ifS (ρ) ij =1else−∞▷shared across heads, no params 9:else ifσ ℓ =softthen 10:initβ (ℓ) ∈R H ←0.5;Φ←Φ∪ {β (ℓ)} 11:M (ℓ,h) ij ←β (ℓ) h ·S (ρ) ij ▷differentiable, per-head gate 12:end if 13:end for
-
[48]
Attach LoRA on every linear projection(QKV, out_proj, FFN) 14:for each frozen projectionW: initL A ∼ N(0,1/r),L B ←0;W eff ←W+ α r LBLA 15:Φ←Φ∪ {L (ℓ,∗) A , L(ℓ,∗) B :ℓ∈[L]}
-
[49]
N” is the number of patient samples, “Kfull
Episodic in-context fine-tune(Section 4) 16:fort= 1, . . . , Tdo 17:sample stratified split(S c,S q)of(X, y) 18:forblockℓ∈[L], headh∈[H]in feature attentiondo 19:Z (ℓ,h) ←Q (ℓ,h)K(ℓ,h)⊤/√dh +M (ℓ,h) ▷ M (ℓ,h)=0ifσ ℓ=off 20:end for 21:ˆy q ←f θ(XSc , ySc , XSq)▷forward through KG-awaref θ 22:L ←CE(ˆy q, ySq) 23:Φ←AdamW(Φ, η∇ ΦL)▷ θandS (ρ) are frozen 24:en...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.