Sequential Fairness Auditing with Limited Output Access
Pith reviewed 2026-06-30 05:52 UTC · model grok-4.3
The pith
A sequential generalized likelihood-ratio test lets auditors stop querying once fairness evidence suffices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
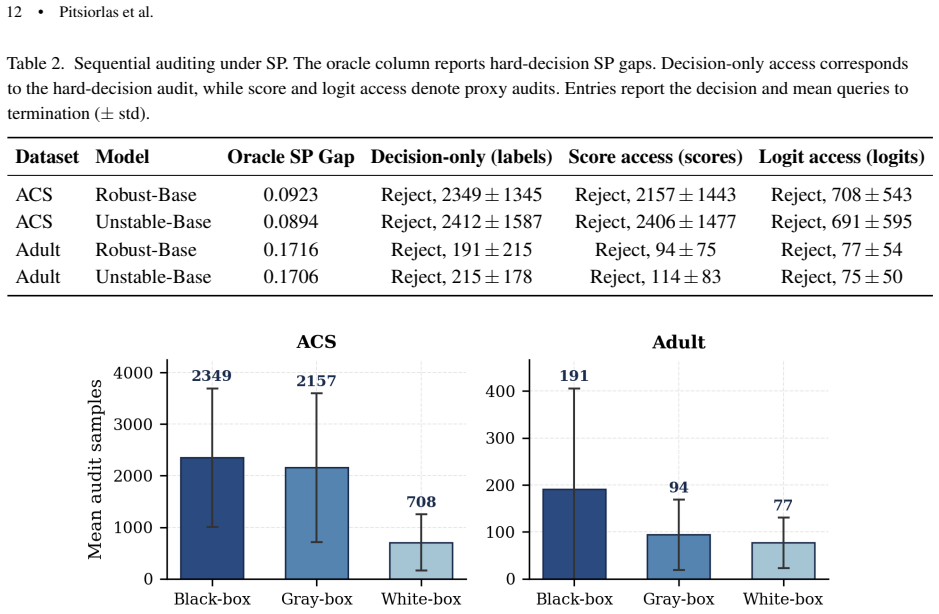
Fairness auditing under limited model access is formulated as a sequential hypothesis-testing problem in which a generalized likelihood-ratio statistic is updated after each query; the audit terminates at the first time the statistic crosses pre-specified thresholds that encode tolerance for false compliance or false violation declarations. The method is instantiated for binary decision outputs measuring statistical parity and equal opportunity and extended to cases where score or logit values are also observable. Empirical comparisons show that query efficiency varies with both the fairness metric and the richness of the returned outputs, with richer information yielding large savings in so
What carries the argument
Sequential generalized likelihood-ratio test that accumulates evidence from successive model queries and stops when the ratio crosses tolerance thresholds.
If this is right
- Auditors can reduce the number of model queries by stopping as soon as evidence is decisive rather than exhausting a preset sample size.
- Query savings depend on the fairness metric being audited and on whether decisions, scores, or logits are returned.
- Richer output information lowers required queries in many operating regimes but offers little help when the fairness value sits near the tolerance threshold.
- The same stopping rule works for both confirming compliance and detecting violations within one statistical framework.
Where Pith is reading between the lines
- The sequential stopping rule could be applied to other query-limited governance tasks such as robustness or privacy checks without changing the core likelihood machinery.
- Real deployments would still need separate checks that the chosen audit pool remains representative after early stopping occurs.
- Joint auditing of several fairness metrics at once would require either separate sequential tests or a multivariate extension of the likelihood ratio.
Load-bearing premise
Model outputs can be described by likelihood functions that support reliable sequential testing at the chosen tolerance levels, and the finite audit pool is representative of the population being audited.
What would settle it
A controlled experiment in which the sequential procedure stops and declares compliance, yet a fixed-sample test on the entire pool or on an independent larger sample rejects compliance at the same tolerance.
Figures
read the original abstract
External evaluations are becoming increasingly central to the governance of AI systems. In practice, however, independent auditors often have limited access to deployed models and must rely on query-based interactions. Most existing fairness evaluation methods assume static datasets and fixed-sample statistical tests, making them poorly suited to real-world auditing scenarios in which evidence must be collected sequentially under query constraints. In this work, we formulate fairness auditing as a tolerance-aware sequential hypothesis-testing problem under limited model output access. We develop a sequential generalized likelihood-ratio framework that allows auditors to accumulate evidence from a finite audit pool and stop once sufficient support for compliance or violation has been obtained. The framework is instantiated for decision-based Statistical Parity and Equal Opportunity audits, and extended to score- and logit-based proxy audits when richer observables are available. Our results show that both the fairness metric and the level of model access significantly affect audit efficiency, and that the benefits of richer output information are not uniform across auditing settings. In particular, richer outputs can substantially reduce the number of queries required for some fairness metrics and operating regimes, while offering limited gains in near-threshold cases. This work provides a practical statistical framework for sequential fairness auditing under realistic deployment constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a sequential generalized likelihood-ratio (GLR) framework for fairness auditing under limited model output access. Auditors accumulate evidence from a finite audit pool and stop once sufficient support for compliance or violation is obtained. The framework is instantiated for decision-based Statistical Parity and Equal Opportunity audits and extended to score- and logit-based proxy audits; results indicate that both the fairness metric and level of model access affect audit efficiency, with richer outputs reducing required queries in some regimes but offering limited gains near thresholds.
Significance. If the framework correctly controls error rates, it offers a practical advance over fixed-sample fairness tests by enabling early stopping under query constraints, which is directly relevant to real-world AI governance. The comparative analysis across output access levels provides actionable guidance on when richer observables yield efficiency gains. The work integrates sequential testing with fairness metrics in a way that could support more efficient external audits.
major comments (2)
- [§3] §3 (sequential GLR framework): The stopping boundaries and likelihood ratios appear to be derived under standard i.i.d. sampling assumptions from an infinite population. With a finite audit pool the sampling is without replacement, inducing dependence among observations; the joint likelihood is then a multivariate hypergeometric-style product rather than the product of independent marginals. This directly affects whether the nominal type-I and type-II error rates are guaranteed once the pool is exhausted or the sampling fraction is non-negligible. Please state explicitly whether a finite-population correction is applied and, if not, provide a bound or simulation showing that the approximation remains valid for the pool sizes used in the experiments.
- [§4–5] §4–5 (instantiations and experiments): The decision-based and score-based audit procedures are presented with the usual binomial or normal likelihoods. If these are used without adjustment, the reported efficiency gains (query reductions) may not be accompanied by valid error-rate control. The manuscript should include a verification (analytic or Monte-Carlo) that the realized error rates match the design levels under finite-pool sampling.
minor comments (2)
- [Abstract] Abstract: the phrase 'our results show' is not accompanied by any quantitative summary of the efficiency gains; a single sentence with the magnitude of query reduction (e.g., 'X% fewer queries on average') would improve clarity.
- [Notation] Notation: the tolerance parameter and the GLR threshold are introduced with different symbols in different sections; a consolidated table of symbols would reduce reader effort.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments on finite-population effects and error-rate verification under without-replacement sampling are well taken. We address each major comment below and will incorporate the requested clarifications and verifications in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (sequential GLR framework): The stopping boundaries and likelihood ratios appear to be derived under standard i.i.d. sampling assumptions from an infinite population. With a finite audit pool the sampling is without replacement, inducing dependence among observations; the joint likelihood is then a multivariate hypergeometric-style product rather than the product of independent marginals. This directly affects whether the nominal type-I and type-II error rates are guaranteed once the pool is exhausted or the sampling fraction is non-negligible. Please state explicitly whether a finite-population correction is applied and, if not, provide a bound or simulation showing that the approximation remains valid for the pool sizes used in the experiments.
Authors: The sequential GLR framework in §3 is derived under the standard i.i.d. sampling model for analytical tractability and to leverage existing sequential analysis results. No finite-population correction is applied in the current version. We will add a dedicated simulation study (new appendix or subsection in §5) that compares the i.i.d.-based GLR stopping boundaries against exact without-replacement sampling for the finite pool sizes used in the experiments. The simulations will report empirical type-I and type-II error rates as a function of sampling fraction, confirming that the approximation remains accurate for the regimes considered (small query-to-pool ratios). revision: yes
-
Referee: [§4–5] §4–5 (instantiations and experiments): The decision-based and score-based audit procedures are presented with the usual binomial or normal likelihoods. If these are used without adjustment, the reported efficiency gains (query reductions) may not be accompanied by valid error-rate control. The manuscript should include a verification (analytic or Monte-Carlo) that the realized error rates match the design levels under finite-pool sampling.
Authors: We agree that explicit verification is needed. In the revision we will augment §5 with Monte Carlo experiments that execute the full decision-based, score-based, and logit-based procedures under without-replacement sampling from finite pools matching the experimental setups. These will tabulate realized type-I and type-II error rates against the nominal design levels (α, β) and will be reported alongside the efficiency results. This will directly address whether the reported query reductions preserve error control. revision: yes
Circularity Check
No circularity; standard sequential testing applied to auditing domain
full rationale
The paper formulates fairness auditing as a tolerance-aware sequential hypothesis-testing problem and instantiates a generalized likelihood-ratio framework for decision-based and score-based audits. No equations, fitted parameters, or self-citations are visible in the provided text that would reduce any central claim to its own inputs by construction. The derivation relies on established sequential testing methods applied to the auditing setting rather than redefining quantities in terms of themselves or smuggling ansatzes via self-citation. The finite-pool aspect is presented as a practical constraint handled by the framework, with no evidence that the stopping rule or likelihoods are forced by the target result itself. This is a self-contained application against external statistical benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alekh Agarwal, Alina Beygelzimer, Miroslav Dudík, John Langford, and Hanna Wallach. 2018. A Reductions Approach to Fair Classification. InProceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, V ol. 80), Jennifer Dy and Andreas Krause (Eds.). PMLR, 60–69. https://proceedings.mlr.press/v80/agarwal18a.html
2018
-
[2]
Sarah Bird, Miroslav Dudík, Richard Edgar, Brandon Horn, Roman Lutz, Vanessa Milan, Mehrnoosh Sameki, Hanna Wallach, and Kathleen Walker. 2020. Fairlearn: A Toolkit for Assessing and Improving Fairness in AI. Microsoft Technical Report MSR-TR-2020-32. https://www.microsoft.com/en-us/research/publication/fairlearn-a-toolkit-for-assessing-and-improving-fair...
2020
-
[3]
Stephen Casper, Carson Ezell, Charlotte Siegmann, Noam Kolt, Taylor Lynn Curtis, Benjamin Bucknall, Andreas Haupt, Kevin Wei, Jérémy Scheurer, Marius Hobbhahn, Lee Sharkey, Satyapriya Krishna, Marvin V on Hagen, Silas Alberti, Alan Chan, Qinyi Sun, Michael Gerovitch, David Bau, Max Tegmark, David Krueger, and Dylan Hadfield-Menell. 2024. Black-Box Access ...
-
[4]
Sarah H. Cen and Rohan Alur. 2024. From Transparency to Accountability and Back: A Discussion of Access and Evidence in AI Auditing. InProceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization(San Luis Potosi, Mexico)(EAAMO ’24). Association for Computing Machinery, New York, NY , USA, Article 13, 14 pages. doi...
-
[5]
Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. 2021. Retiring Adult: New Datasets for Fair Machine Learning. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track. https://datasets-benchmarks-proceedings.neurips. cc/paper/2021/hash/68d30a9594728bc39aa24be94b319d21-Abstract-round2.html
2021
-
[6]
European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying Down Harmonised Rules on Artificial Intelligence (AI Act). Official Journal of the European Union. https://eur-lex.europa.eu/legal-content/EN/ TXT/?uri=CELEX:32024R1689
2024
-
[7]
Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian
Michael Feldman, Sorelle A. Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian. 2015. Certifying and Removing Disparate Impact. InProceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(Sydney, NSW, Australia)(KDD ’15). Association for Computing Machinery, New York, NY , USA, 259–268. doi:1...
-
[8]
Moritz Hardt, Eric Price, and Nati Srebro. 2016. Equality of Opportunity in Supervised Learning. InAdvances in Neural Information Processing Systems, D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett (Eds.), V ol. 29. Curran Associates, Inc. https: //proceedings.neurips.cc/paper_files/paper/2016/file/6a9659feb1216f14f7384ba499518b38-Paper.pdf
2016
- [9]
-
[10]
Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon
Steven R. Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. 2021. Time-uniform, nonparametric, nonasymptotic confidence sequences.The Annals of Statistics49, 2 (April 2021). doi:10.1214/20-aos1991
-
[11]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. InInternational Conference on Learning Representations. https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
New York City Council. 2023. New York City Local Law 144 of 2021: Automated Employment Decision Tools (AEDT) Law. NYC Department of Consumer and Worker Protection. https://rules.cityofnewyork.us/rule/automated-employment-decision-tools/
2023
-
[13]
Jean-Charles Rochet and Jean Tirole
Inioluwa Deborah Raji, Andrew Smart, Rebecca N. White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. 2020. Closing the AI accountability gap: defining an end-to-end framework for internal algorithmic auditing. InProceedings of the 2020 Conference on Fairness, Accountability, and Transparency(Barcelon...
-
[14]
Aaditya Ramdas, Peter Grünwald, Vladimir V ovk, and Glenn Shafer. 2023. Game-Theoretic Statistics and Safe Anytime-Valid Inference. Statist. Sci.38, 4 (2023), 576 – 601. doi:10.1214/23-STS894
-
[15]
Bahar Taskesen, Jose Blanchet, Daniel Kuhn, and Viet Anh Nguyen. 2021. A Statistical Test for Probabilistic Fairness. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency(Virtual Event, Canada)(F AccT ’21). Association for Computing Machinery, New York, NY , USA, 648–665. doi:10.1145/3442188.3445927
-
[16]
1947.Sequential Analysis
Abraham Wald. 1947.Sequential Analysis. Wiley
1947
-
[17]
Tom Yan and Chicheng Zhang. 2022. Active fairness auditing. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, V ol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato (Eds.). PMLR, 24929–24962. https://proceedings.mlr.press/v162/yan22c.html Proce...
2022
-
[18]
William Yik, Limnanthes Serafini, Timothy Lindsey, and George D. Montañez. 2022. Identifying Bias in Data Using Two-Distribution Hypothesis Tests. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society(Oxford, United Kingdom)(AIES ’22). Association for Computing Machinery, New York, NY , USA, 831–844. doi:10.1145/3514094.3534169 A GLR Op...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.