Residual-Guided Expert Specialization for Incomplete Multimodal Learning
Pith reviewed 2026-06-30 06:22 UTC · model grok-4.3
The pith
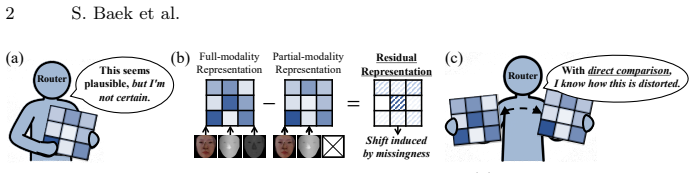
MARS routes multimodal samples to experts specialized on the representational shifts caused by missing modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
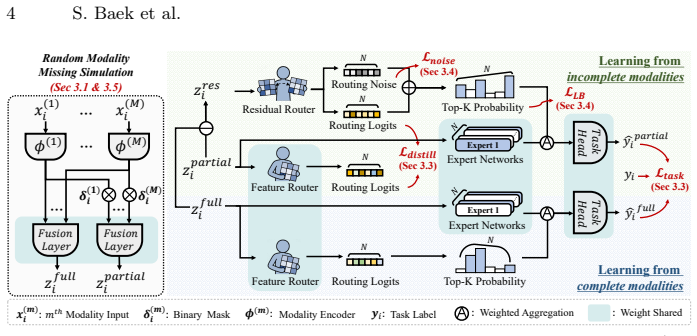
By deriving a residual signal that quantifies how missing modalities reshape task representations, MARS trains a residual router to allocate samples to deviation-specific experts; a feature router then imitates this allocation using only incomplete inputs, with discrepancy-aware noise regularization applied to the residual router to reduce the train-test routing gap and preserve expert specialization at deployment.
What carries the argument
MARS (Missingness-Aware Residual-guided Specialization), a mixture-of-experts architecture whose residual router receives both incomplete and complete representations to produce deviation-aware assignments that a feature router later imitates from incomplete inputs alone.
If this is right
- Expert parameters converge to handle distinct patterns of representational deviation induced by different missing-modality combinations.
- The same framework applies without modification to both classification and dense prediction tasks across multiple backbone architectures.
- At inference the model requires only the incomplete modalities that will actually be observed, with no need to reconstruct or impute missing inputs.
- The approach scales to any number of modalities provided the complete-modality pairs are available during training for residual computation.
Where Pith is reading between the lines
- The same residual-signal idea could be tested on sequential or temporal modalities where missingness occurs over time rather than across entire channels.
- If the residual router learns stable deviation clusters, those clusters might themselves become interpretable signatures of which modality combinations are most informative for a given task.
- The method implicitly assumes that the complete-modality data distribution during training matches the distribution of complete cases that would have been observed had no modalities been dropped, an assumption worth checking on real-world incomplete datasets.
Load-bearing premise
The discrepancy-aware noise regularization is strong enough to make the feature router's imitation of the residual router reliable enough that the specialized experts remain effective when only incomplete inputs are available.
What would settle it
A controlled ablation in which the noise regularization term is removed and the resulting drop in accuracy under missing-modality test conditions is measured on the same datasets and missingness patterns used in the paper.
Figures

read the original abstract
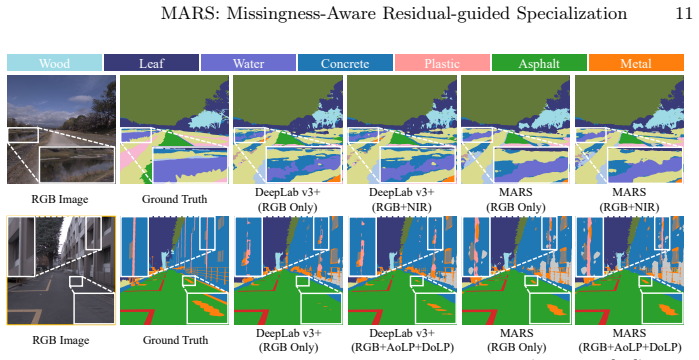
As real-world prediction systems often face missing modalities at inference, incomplete multimodal learning (IML) remains a practical challenge. While prior methods aim to learn representations robust to missing inputs, representations from incomplete modalities inevitably deviate from their full-modality counterparts due to missing evidence. To explicitly leverage these deviations, we propose MARS (Missingness-Aware Residual-guided Specialization), a mixture-of-experts framework that guides expert specialization based on how representations are reshaped by missingness. By contrasting task representations derived from incomplete inputs with their complete counterparts during training, we derive a privileged residual signal that captures this representational gap. The residual signal guides a residual router to assign samples to experts specialized for the corresponding deviation patterns. In parallel, a feature router learns to imitate this routing behavior using only incomplete inputs, enabling deployment without access to full modalities. To mitigate this train-test router gap, we develop a discrepancy-aware noise regularization that adaptively perturbs the residual router's decisions when the feature router deviates, enhancing expert robustness under imperfect imitation. Experiments on multimodal classification (CASIA-SURF, CREMA-D, UPMC Food-101) and segmentation (MCubeS) under missing scenarios show that MARS consistently surpasses baselines while remaining efficient and extensible to diverse backbones and tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MARS, a mixture-of-experts framework for incomplete multimodal learning. It derives a privileged residual signal by contrasting task representations from incomplete inputs against their complete counterparts to train a residual router that specializes experts for missingness-induced deviation patterns. A feature router is trained to imitate the residual router using only incomplete inputs, supported by a discrepancy-aware noise regularization term intended to close the train-test router gap. Experiments on CASIA-SURF, CREMA-D, and UPMC Food-101 (classification) plus MCubeS (segmentation) under missing-modality scenarios claim consistent outperformance over baselines, with the method described as efficient and extensible to diverse backbones and tasks.
Significance. If the empirical results are robust and the regularization demonstrably transfers specialization, the work provides a structured way to explicitly leverage representational deviations caused by missing modalities rather than treating them as noise. This could advance incomplete multimodal learning by combining privileged-information training with MoE specialization in a deployment-friendly manner. The extensibility claim, if supported by the experiments, is a practical strength.
major comments (1)
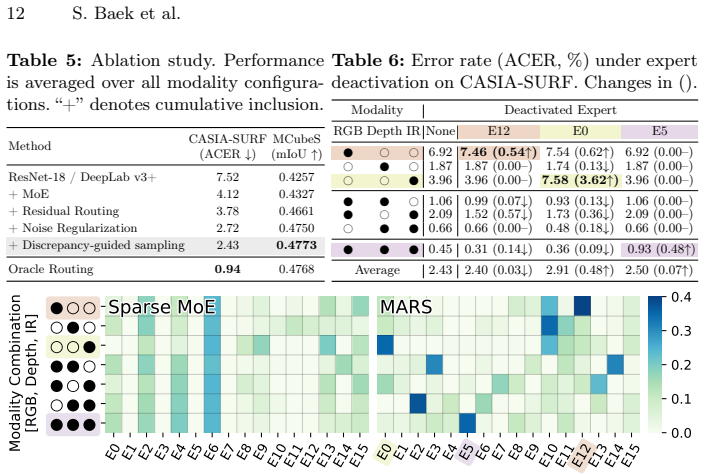
- [Method (discrepancy-aware noise regularization description)] The central claim of consistent outperformance under missing modalities at inference rests on the discrepancy-aware noise regularization sufficiently closing the train-test router gap so that feature-router assignments activate the correctly specialized experts. The manuscript provides no ablations or quantitative analysis (e.g., routing accuracy, expert activation overlap, or distribution matching between perturbed residual-router decisions and actual feature-router deviations) demonstrating that the adaptive perturbations reproduce deployment-time error patterns induced by missingness.
minor comments (1)
- [Abstract] The abstract asserts 'consistent outperformance' and 'surpasses baselines' without any numerical results, effect sizes, or baseline names; including at least one key quantitative comparison would improve the summary.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit validation of the discrepancy-aware noise regularization. We address the comment below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: The central claim of consistent outperformance under missing modalities at inference rests on the discrepancy-aware noise regularization sufficiently closing the train-test router gap so that feature-router assignments activate the correctly specialized experts. The manuscript provides no ablations or quantitative analysis (e.g., routing accuracy, expert activation overlap, or distribution matching between perturbed residual-router decisions and actual feature-router deviations) demonstrating that the adaptive perturbations reproduce deployment-time error patterns induced by missingness.
Authors: We agree that the current version lacks dedicated quantitative analysis of how the discrepancy-aware noise regularization closes the train-test gap. In the revised manuscript we will add a new subsection (or appendix) containing: (i) routing accuracy of the feature router versus the residual router under varying missingness rates, (ii) expert activation overlap (e.g., Jaccard index or cosine similarity of assignment distributions), and (iii) distribution-matching metrics (KL divergence or Wasserstein distance) between the adaptively perturbed residual-router decisions and the actual feature-router outputs. These results will be reported on the same datasets and missing-modality protocols used in the main experiments. revision: yes
Circularity Check
No circularity: standard privileged-information training with empirical validation
full rationale
The derivation chain relies on contrasting complete vs. incomplete representations to obtain a residual signal, training a residual router on it, and training a feature router to imitate under discrepancy-aware regularization. These are architectural choices and training procedures, not reductions where a claimed prediction equals a fitted input by definition. Performance is asserted via experiments on external datasets (CASIA-SURF, CREMA-D, etc.), not by algebraic equivalence to the method's own parameters. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present in the provided text. This is the common case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ISBI
Baek, S., Choi, I., et al.: Learning covariance-based multi-scale representation of neuroimaging measures for alzheimer classification. In: ISBI. pp. 1–5. IEEE (2023)
2023
-
[2]
In: MICCAI
Baek, S., Sim, J., Wu, G., Kim, W.H.: Ocl: Ordinal contrastive learning for impu- tating features with progressive labels. In: MICCAI. pp. 334–344. Springer (2024)
2024
-
[3]
In: ACM SIGKDD
Cai, L., Wang, Z., Gao, H., et al.: Deep adversarial learning for multi-modality missing data completion. In: ACM SIGKDD. pp. 1158–1166 (2018)
2018
-
[4]
IEEE transactions on affective computing5(4), 377–390 (2014)
Cao, H., Cooper, D.G., Keutmann, M.K., et al.: Crema-d: Crowd-sourced emo- tional multimodal actors dataset. IEEE transactions on affective computing5(4), 377–390 (2014)
2014
-
[5]
In: ECCV
Chen, L.C., Zhu, Y., Papandreou, G., et al.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: ECCV. pp. 801–818 (2018)
2018
-
[6]
NeurIPS37, 112050–112103 (2024)
Chen, Z., Li, H., Wang, F., et al.: Rethinking the diffusion models for missing data imputation: A gradient flow perspective. NeurIPS37, 112050–112103 (2024)
2024
-
[7]
In: NAACL
Devlin, J., Chang, M.W., Lee, K., et al.: Bert: Pre-training of deep bidirectional transformers for language understanding. In: NAACL. pp. 4171–4186 (2019)
2019
-
[8]
In: ICCV
Ding, Y., Yu, X., Yang, Y.: Rfnet: Region-aware fusion network for incomplete multi-modal brain tumor segmentation. In: ICCV. pp. 3975–3984 (2021)
2021
-
[9]
In: 2020 35th International conference on image and vision computing New Zealand (IVCNZ)
Gallo, I., Ria, G., Landro, N., La Grassa, R.: Image and text fusion for upmc food-101 using bert and cnns. In: 2020 35th International conference on image and vision computing New Zealand (IVCNZ). pp. 1–6. IEEE (2020)
2020
-
[10]
Proceedings of the IEEE103(9), 1560–1584 (2015)
Gómez-Chova, L., Tuia, D., Moser, G., et al.: Multimodal classification of remote sensing images: A review and future directions. Proceedings of the IEEE103(9), 1560–1584 (2015)
2015
-
[11]
NeurIPS33, 9841–9850 (2020)
Härkönen, E., Hertzmann, A., Lehtinen, J., et al.: Ganspace: Discovering inter- pretable gan controls. NeurIPS33, 9841–9850 (2020)
2020
-
[12]
In: MICCAI
Havaei, M., Guizard, N., Chapados, N., Bengio, Y.: Hemis: Hetero-modal image segmentation. In: MICCAI. pp. 469–477. Springer (2016)
2016
-
[13]
In: CVPR
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR. pp. 770–778 (2016)
2016
-
[14]
In: ICCV (2025)
Li, S., Chen, C., Han, J.: Simmlm: A simple framework for multi-modal learning with missing modality. In: ICCV (2025)
2025
-
[15]
Computers in Biology and Medicine177, 108635 (2024) 26 S
Li, Y., Daho, M.E.H., Conze, P.H., Zeghlache, R., Le Boité, H., Tadayoni, R., Cochener, B., Lamard, M., Quellec, G.: A review of deep learning-based informa- tion fusion techniques for multimodal medical image classification. Computers in Biology and Medicine177, 108635 (2024) 26 S. Baek et al
2024
-
[16]
In: CVPR
Liang, Y., Wakaki, R., Nobuhara, S., et al.: Multimodal material segmentation. In: CVPR. pp. 19800–19808 (2022)
2022
-
[17]
ICLR (2017)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. ICLR (2017)
2017
-
[18]
Ma, M., Ren, J., Zhao, L., et al.: Are multimodal transformers robust to missing modality? In: CVPR. pp. 18177–18186 (2022)
2022
-
[19]
IEEE Transactions on Geoscience and Remote Sensing62, 1–15 (2024)
Ma, X., Zhang, X., Pun, M.O., et al.: A multilevel multimodal fusion transformer for remote sensing semantic segmentation. IEEE Transactions on Geoscience and Remote Sensing62, 1–15 (2024)
2024
-
[20]
Efficient Estimation of Word Representations in Vector Space
Mikolov, T., Chen, K., Corrado, G., et al.: Efficient estimation of word represen- tations in vector space. arXiv preprint arXiv:1301.3781 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[21]
In: CVPR
Peng, X., Wei, Y., Deng, A., et al.: Balanced multimodal learning via on-the-fly gradient modulation. In: CVPR. pp. 8238–8247 (2022)
2022
-
[22]
An overview of gradient descent optimization algorithms
Ruder, S.: An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
In: ICCV
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., et al.: Grad-cam: Visual explanations from deep networks via gradient-based localization. In: ICCV. pp. 618–626 (2017)
2017
-
[24]
In: ICCV
Sharmanska, V., Quadrianto, N., et al.: Learning to rank using privileged informa- tion. In: ICCV. pp. 825–832 (2013)
2013
-
[25]
ICLR (2017)
Shazeer,N.,Mirhoseini,A.,Maziarz,K.,etal.:Outrageouslylargeneuralnetworks: The sparsely-gated mixture-of-experts layer. ICLR (2017)
2017
-
[26]
TPAMI44(4), 2004–2018 (2020)
Shen, Y., Yang, C., Tang, X., et al.: Interfacegan: Interpreting the disentangled face representation learned by gans. TPAMI44(4), 2004–2018 (2020)
2004
-
[27]
ACM Computing Surveys55(7), 1– 31 (2022)
Sleeman IV, W.C., Kapoor, R., Ghosh, P.: Multimodal classification: Current landscape, taxonomy and future directions. ACM Computing Surveys55(7), 1– 31 (2022)
2022
-
[28]
Humanities and Social Sciences Communications11(1), 1–14 (2024)
Sun, Y., Sheng, D., Zhou, Z., et al.: Ai hallucination: towards a comprehensive classification of distorted information in artificial intelligence-generated content. Humanities and Social Sciences Communications11(1), 1–14 (2024)
2024
-
[29]
In: CVPR
Szegedy, C., Vanhoucke, V., Ioffe, S., et al.: Rethinking the inception architecture for computer vision. In: CVPR. pp. 2818–2826 (2016)
2016
-
[30]
In: MICCAI
Tivnan, M., Yoon, S., Chen, Z., et al.: Hallucination index: An image quality metric for generative reconstruction models. In: MICCAI. pp. 449–458. Springer (2024)
2024
-
[31]
JMLR16(1), 2023–2049 (2015)
Vapnik, V., Izmailov, R.: Learning using privileged information: similarity control and knowledge transfer. JMLR16(1), 2023–2049 (2015)
2023
-
[32]
Neural networks22(5-6), 544–557 (2009)
Vapnik, V., Vashist, A.: A new learning paradigm: Learning using privileged infor- mation. Neural networks22(5-6), 544–557 (2009)
2009
-
[33]
In: CVPR
Wang, H., Chen, Y., Ma, C., et al.: Multi-modal learning with missing modality via shared-specific feature modelling. In: CVPR. pp. 15878–15887 (2023)
2023
-
[34]
In: CVPR
Wei, S., Luo, C., Luo, Y.: Mmanet: Margin-aware distillation and modality-aware regularization for incomplete multimodal learning. In: CVPR. pp. 20039–20049 (2023)
2023
-
[35]
In: ECCV
Wei, S., Luo, Y., Wang, Y., et al.: Robust multimodal learning via representation decoupling. In: ECCV. pp. 38–54. Springer (2024)
2024
-
[36]
ACM Computing Surveys (2024)
Wu, R., Wang, H., Chen, H.T., et al.: Deep multimodal learning with missing modality: A survey. ACM Computing Surveys (2024)
2024
-
[37]
In: ACM MM
Xu, W., Jiang, H., Liang, X.: Leveraging knowledge of modality experts for incom- plete multimodal learning. In: ACM MM. pp. 438–446 (2024)
2024
-
[38]
NeurIPS37, 98782–98805 (2024) MARS: Missingness-Aware Residual-guided Specialization 27
Yun, S., Choi, I., Peng, J., et al.: Flex-moe: Modeling arbitrary modality combi- nation via the flexible mixture-of-experts. NeurIPS37, 98782–98805 (2024) MARS: Missingness-Aware Residual-guided Specialization 27
2024
-
[39]
In: CVPR
Zhang, S., Wang, X., Liu, A., et al.: A dataset and benchmark for large-scale multi-modal face anti-spoofing. In: CVPR. pp. 919–928 (2019)
2019
-
[40]
In: MICCAI
Zhang, Y., He, N., Yang, J., et al.: mmformer: Multimodal medical transformer for incomplete multimodal learning of brain tumor segmentation. In: MICCAI. pp. 107–117. Springer (2022)
2022
-
[41]
Image and Vision Computing105, 104042 (2021)
Zhang, Y., Sidibé, D., Morel, O., et al.: Deep multimodal fusion for semantic image segmentation: A survey. Image and Vision Computing105, 104042 (2021)
2021
-
[42]
In: AAAI
Zheng, X., Tang, C., Wan, Z., et al.: Multi-level confidence learning for trustworthy multimodal classification. In: AAAI. vol. 37, pp. 11381–11389 (2023)
2023
-
[43]
In: MICCAI
Zhou, T., Canu, S., Vera, P., et al.: Brain tumor segmentation with missing modal- ities via latent multi-source correlation representation. In: MICCAI. pp. 533–541. Springer (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.