On the Faithfulness of Post-Hoc Concept Bottleneck Models
Pith reviewed 2026-06-30 06:34 UTC · model grok-4.3
The pith
Covariate shifts and label noise make post-hoc concept bottleneck models learn unfaithful projections even at high accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Post-hoc concept projections learned from auxiliary data become unfaithful under covariate shift, with an upper bound given on the resulting error, while surrogate labels from vision-language models introduce systematic unfaithfulness; new metrics that evaluate the projections themselves separate faithfulness from task accuracy.
What carries the argument
Novel metrics that directly quantify faithfulness of the learned concept projection independent of predictive accuracy on the target task.
If this is right
- Accuracy alone is insufficient to certify that a post-hoc CBM has learned semantically meaningful concepts.
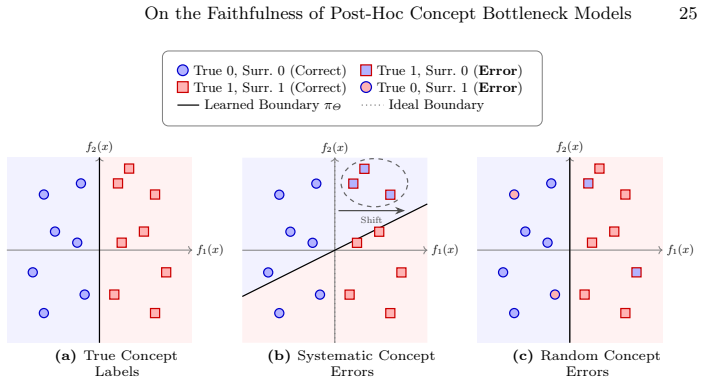
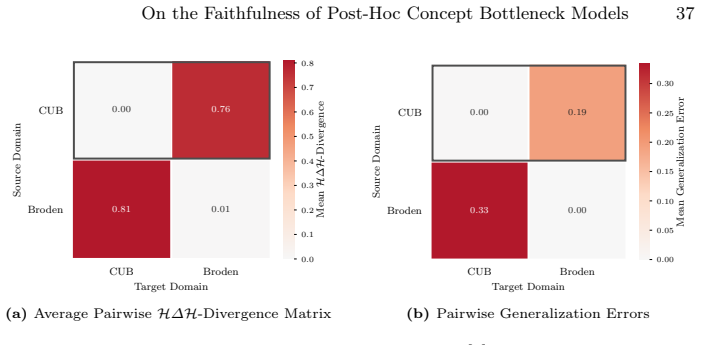
- Covariate shift between auxiliary and target distributions produces a bounded but nonzero error in concept faithfulness.
- Systematic label noise from vision-language models produces unfaithful projections even when target accuracy remains competitive.
- The new metrics detect unfaithful projections on both synthetic and real-world data where accuracy metrics do not.
Where Pith is reading between the lines
- Practitioners may need to collect or simulate target-distribution concept labels rather than relying exclusively on auxiliary sources.
- The error bound could be tightened or extended to other distribution mismatches such as label shift or domain gap.
- If the metrics generalize, they offer a template for auditing other post-hoc interpretability techniques that also rely on auxiliary supervision.
Load-bearing premise
The new metrics measure concept faithfulness without inheriting biases from the auxiliary data or vision-language model labels that create the unfaithfulness they are meant to detect.
What would settle it
A controlled experiment in which a known unfaithful projection (either from a large covariate shift or from noisy VLM labels) receives a high faithfulness score from the new metrics while a faithful projection receives a low score.
Figures

read the original abstract
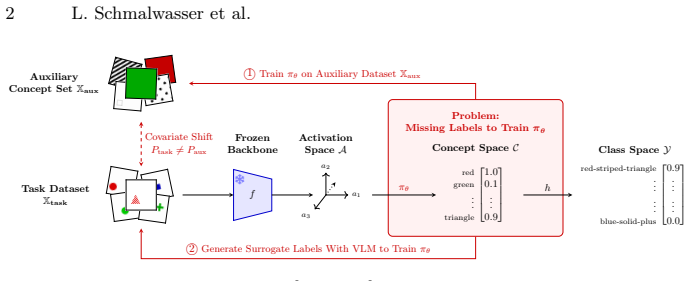
Human decision-making interprets the world through high-level concepts, such as recognizing a bird by its belly color. To bridge the gap between opaque deep learning representations and human understanding, Post-Hoc Concept Bottleneck Models (post-hoc CBMs) project latent features onto interpretable concept spaces using auxiliary datasets or vision-language models. However, relying on target task accuracy as the primary measure of post-hoc CBM success obscures whether the learned concepts are semantically meaningful or merely predictive artifacts. For example, random concept projections can achieve competitive accuracy despite being semantically meaningless. In this work, we analyze the learned projections directly and identify two failure cases: First, for concept projections learned from auxiliary data, covariate shifts can lead to unfaithful concept representations for the target task. In particular, we provide an upper bound on the error introduced by this shift. Second, systematic label noise in surrogate concept labels generated by vision-language models leads to unfaithful projections. After formalizing these failure modes, we introduce novel metrics that decouple concept faithfulness from predictive accuracy. Our empirical results across real-world and synthetic benchmarks confirm that these metrics identify unfaithful behaviors that standard accuracy-based evaluation fails to detect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that post-hoc CBMs can produce unfaithful concept projections due to covariate shifts between auxiliary data and the target task (with an explicit upper bound on the resulting error) and due to systematic label noise in VLM-generated surrogate labels. It formalizes these failure modes, introduces novel metrics intended to measure concept faithfulness independently of predictive accuracy, and reports that experiments on real-world and synthetic benchmarks show these metrics detect unfaithful behavior that accuracy-based evaluation misses.
Significance. If the upper bound is rigorously derived and the new metrics are shown to be independent of the auxiliary data and VLM labels that induce the failures, the work would usefully shift evaluation practice in interpretable ML away from accuracy alone toward direct assessment of semantic faithfulness.
major comments (2)
- [Failure Modes / Upper Bound] The upper bound on covariate-shift error is presented as a central contribution, yet the abstract provides no derivation, assumptions, or proof sketch; if this bound is load-bearing for the first failure mode, the manuscript must include the full derivation (likely in the formalization section) with explicit conditions under which it holds.
- [Novel Metrics] The claim that the novel metrics 'decouple concept faithfulness from predictive accuracy' is central, but the construction must be shown to avoid circular dependence on the same auxiliary datasets and VLM surrogate labels used to induce the documented failure modes; without an explicit independence argument or ablation, the metrics may simply rediscover the shift or noise rather than measure semantic faithfulness.
minor comments (1)
- [Experiments] Empirical results are described as confirming the metrics' utility, but the abstract lacks any mention of error bars, number of runs, or statistical tests; these details should be added to the experimental section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the presentation of the upper bound and the independence of the proposed metrics.
read point-by-point responses
-
Referee: [Failure Modes / Upper Bound] The upper bound on covariate-shift error is presented as a central contribution, yet the abstract provides no derivation, assumptions, or proof sketch; if this bound is load-bearing for the first failure mode, the manuscript must include the full derivation (likely in the formalization section) with explicit conditions under which it holds.
Authors: We agree that the derivation, assumptions, and conditions should be stated explicitly. The bound appears in the formalization section under the assumption of bounded distribution shift and Lipschitz continuity of the projection function, but we will add a complete proof sketch with all conditions to that section and a brief mention of the key assumptions to the abstract in the revision. revision: yes
-
Referee: [Novel Metrics] The claim that the novel metrics 'decouple concept faithfulness from predictive accuracy' is central, but the construction must be shown to avoid circular dependence on the same auxiliary datasets and VLM surrogate labels used to induce the documented failure modes; without an explicit independence argument or ablation, the metrics may simply rediscover the shift or noise rather than measure semantic faithfulness.
Authors: We acknowledge the need for an explicit independence argument. The metrics are defined using only target-task inputs and (where available) ground-truth concept labels, without reference to auxiliary data or VLM outputs at evaluation time. We will add a dedicated paragraph proving this separation and an ablation that recomputes the metrics after removing auxiliary/VLM influence to confirm they do not rediscover the original failure modes. revision: yes
Circularity Check
No circularity: derivation chain self-contained against external benchmarks
full rationale
The abstract formalizes two failure modes (covariate shift with an upper bound on error, and label noise from VLMs) then introduces novel metrics claimed to decouple faithfulness from accuracy. No equations, parameter fits, or self-citations are shown that reduce the bound or metrics to inputs by construction. The provided text contains no self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. Claims rest on analysis of existing post-hoc CBM methods without evident reduction to the authors' own auxiliary data or VLM labels. This is the common honest non-finding for papers whose central contributions are empirical identification of failure modes rather than closed-form derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: The Fourteenth International Conference on Learning Representations (2026) 1
Almudévar, A., Hernández-Lobato, J.M., Ortega, A.: There Was Never a Bottleneck in Concept Bottleneck Models. In: The Fourteenth International Conference on Learning Representations (2026) 1
2026
-
[2]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Alukaev, D., Kiselev, S., Pershin, I., Ibragimov, B., Ivanov, V., Kornaev, A., Titov, I.: Cross-Modal Conceptualization in Bottleneck Models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 5241–5253 (2023) 1
2023
-
[3]
Advances in Neural Information Processing Systems32(2019) 2, 3, 5, 6, 21
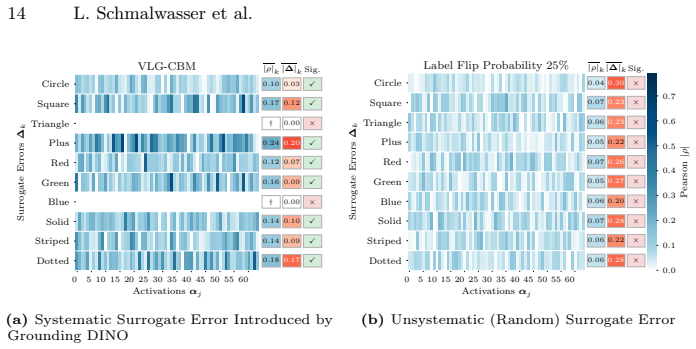
Ansuini, A., Laio, A., Macke, J.H., Zoccolan, D.: Intrinsic dimension of data representations in deep neural networks. Advances in Neural Information Processing Systems32(2019) 2, 3, 5, 6, 21
2019
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Baraniuk, R.G., Wakin, M.B.: Random Projections of Smooth Manifolds. Found. Comput. Math.9(1), 51–77 (2009) 2, 3, 5, 6, 15, 21
2009
-
[6]
Barsalou, L.W.: Perceptual symbol systems. Behav. Brain. Sci.22(4), 577–660 (1999) 1
1999
-
[7]
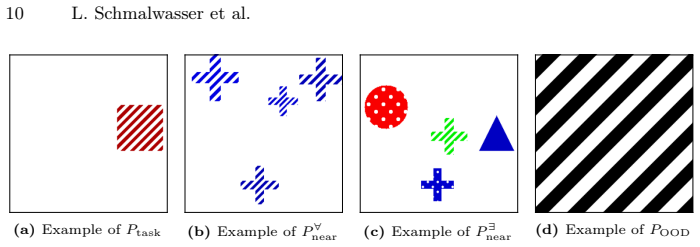
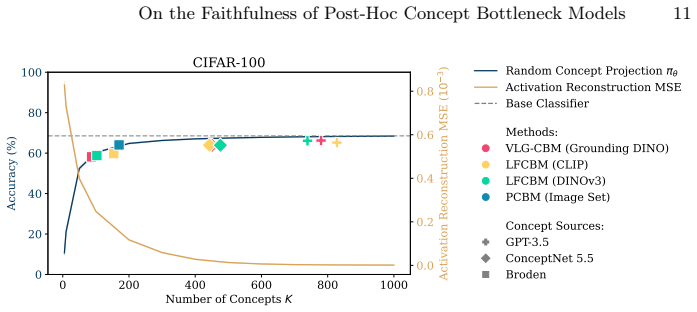
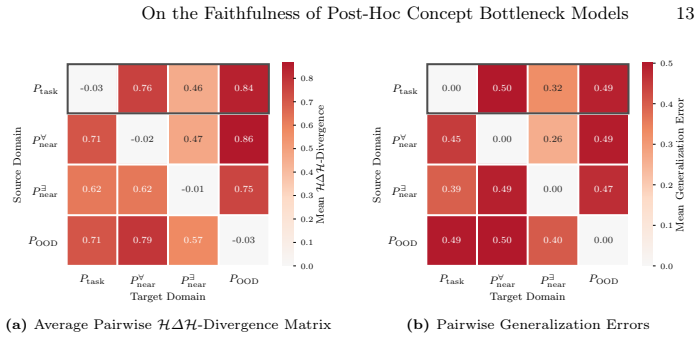
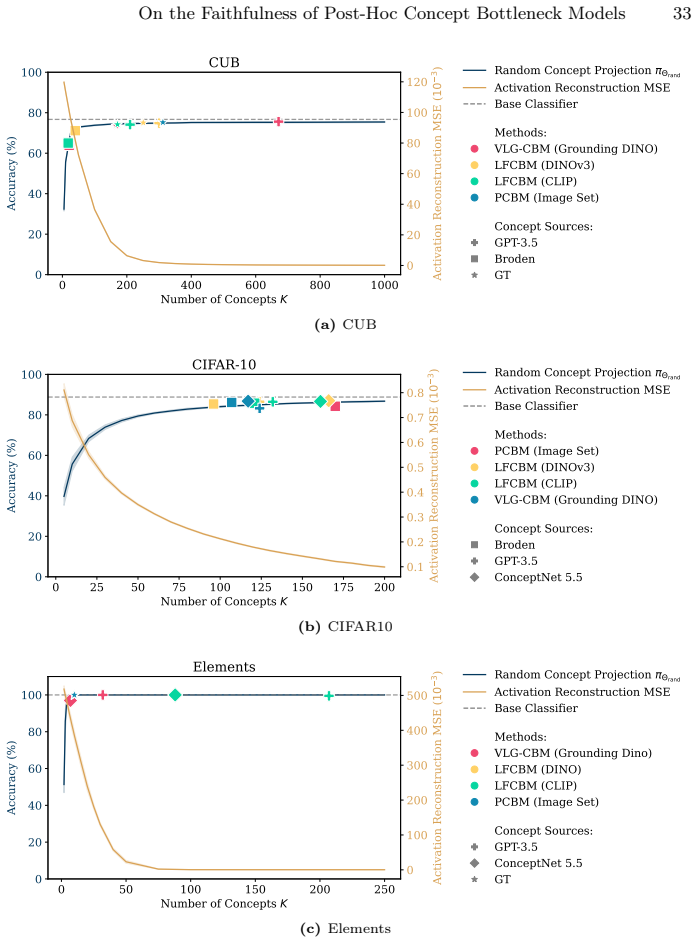
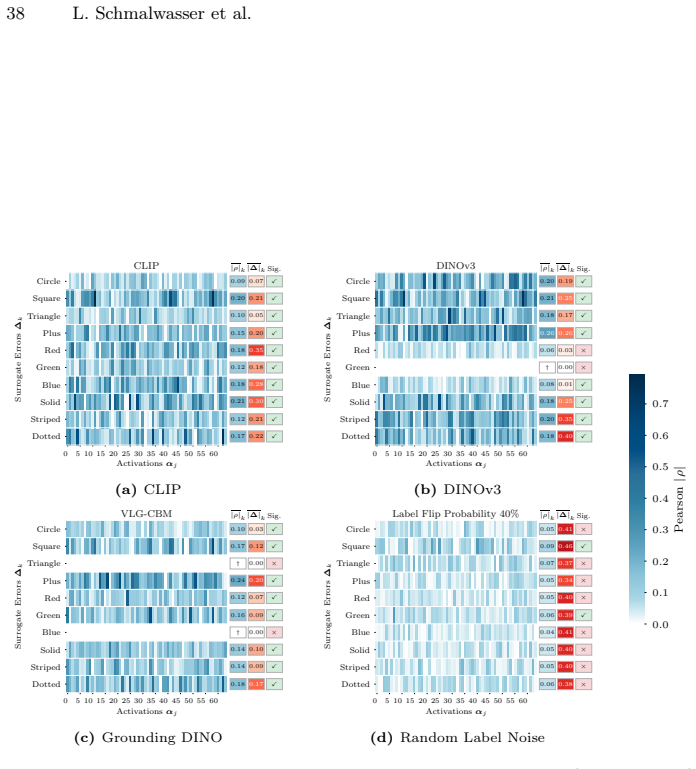
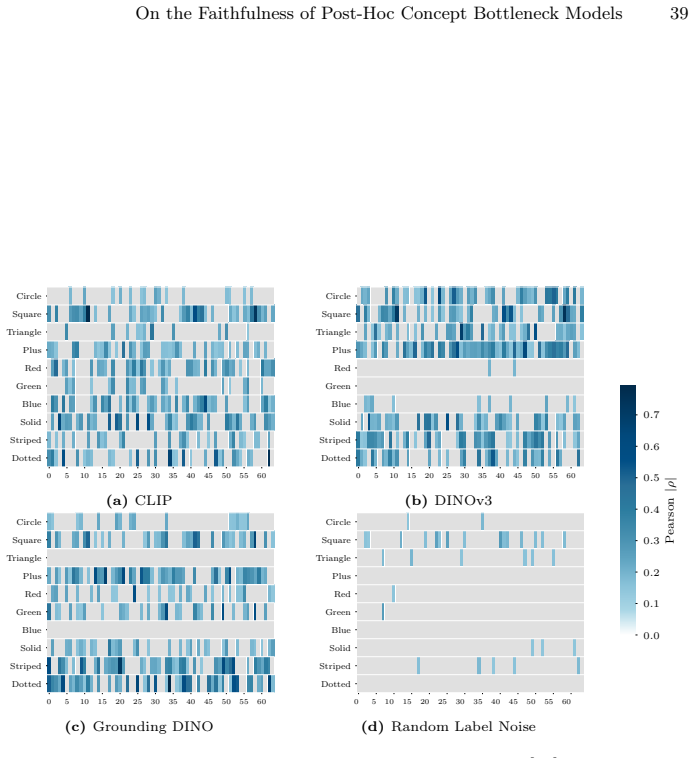
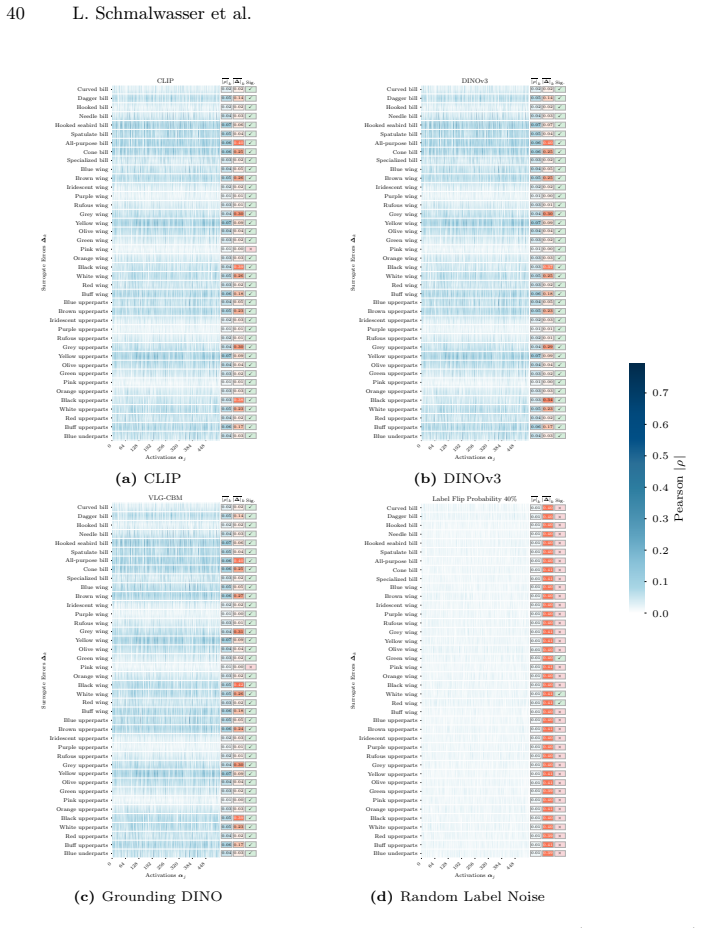
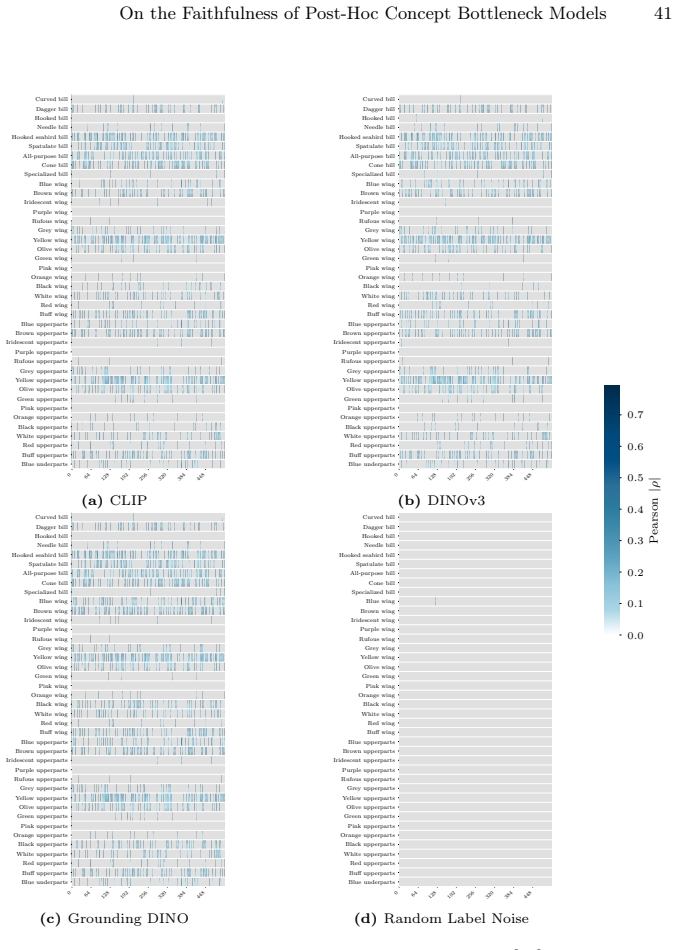
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Bau, D., Zhou, B., Khosla, A., Oliva, A., Torralba, A.: Network Dissection: Quanti- fying Interpretability of Deep Visual Representations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6541–6549 (2017) 1, 2, 3, 7, 10, 11, 32, 36, 37
2017
-
[8]
Ben-David, S., Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., Vaughan, J.W.: A theory of learning from different domains. Mach. Learn.79(1-2), 151–175 (2010) 3, 7, 13, 15, 22, 35, 36, 37
2010
-
[9]
Springer (2006) 6
Bishop, C.M.: Pattern Recognition and Machine Learning. Springer (2006) 6
2006
-
[10]
Advances in Neural Information Processing Systems33, 1877–1901 (2020) 4, 11, 32
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A....
1901
-
[11]
Chauhan, K., Tiwari, R., Freyberg, J., Shenoy, P., Dvijotham, K.: Interactive concept bottleneck models. In: Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence. AAAI’23/IAAI...
2023
-
[12]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. arXiv preprint arXiv:2507.06261 (2025) 24 On the Faithfulness of Post-Hoc Concept Bottlenec...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 248–255 (2009) 10, 31
2009
-
[14]
In: International Conference on Learning Representations (2021) 10
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In: International Conference on Learning Representations (2021) 10
2021
-
[15]
Advances in Neural Infor- mation Processing Systems35, 21400–21413 (2022) 2, 4, 5, 21, 25
Espinosa Zarlenga, M., Barbiero, P., Ciravegna, G., Marra, G., Giannini, F., Dili- genti, M., Shams, Z., Precioso, F., Melacci, S., Weller, A., et al.: Concept Embedding Models: Beyond the Accuracy-Explainability Trade-Off. Advances in Neural Infor- mation Processing Systems35, 21400–21413 (2022) 2, 4, 5, 21, 25
2022
-
[16]
Fahrmeir, L., Lang, S.: Bayesian Inference for Generalized Additive Mixed Models Based on Markov Random Field Priors. J. R. Stat. Soc. Ser. C50(2), 201–220 (2001) 8, 25, 26, 34
2001
-
[17]
In: The Fourteenth International Conference on Learning Representations (2026) 1
Galliamov, K., Kazmi, S.M.A., Khan, A., Rivera, A.R.: Concepts’ Information Bottleneck Models. In: The Fourteenth International Conference on Learning Representations (2026) 1
2026
-
[18]
MIT press (2004) 1
Gardenfors, P.: Conceptual spaces: The geometry of thought. MIT press (2004) 1
2004
-
[19]
MIT Press (2016) 6
Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press (2016) 6
2016
-
[20]
Advances in Neural Information Processing Systems35, 23386–23397 (2022) 3, 5
Havasi, M., Parbhoo, S., Doshi-Velez, F.: Addressing Leakage in Concept Bottleneck Models. Advances in Neural Information Processing Systems35, 23386–23397 (2022) 3, 5
2022
-
[21]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016) 9, 31
He, K., Zhang, X., Ren, S., Sun, J.: Deep Residual Learning for Image Recogni- tion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016) 9, 31
2016
-
[22]
Holm, S.: A Simple Sequentially Rejective Multiple Test Procedure. Scand. J. Stat. 6(2), 65–70 (1979) 15, 39, 41
1979
-
[23]
Neural Netw.2(5), 359–366 (1989) 5, 21
Hornik, K., Stinchcombe, M., White, H.: Multilayer feedforward networks are universal approximators. Neural Netw.2(5), 359–366 (1989) 5, 21
1989
-
[24]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Huang, Q., Song, J., Hu, J., Zhang, H., Wang, Y., Song, M.: On the concept trust- worthiness in concept bottleneck models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 21161–21168 (2024) 4
2024
-
[25]
Jacovi, A., Goldberg, Y.: Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 4198–4205 (2020) 2
2020
-
[26]
Johnson, W.B., Lindenstrauss, J., et al.: Extensions of Lipschitz mappings into a Hilbert space. Contemp. Math.26(189-206), 1 (1984) 2, 3, 5, 21
1984
-
[27]
Jørgensen, B.: Exponential Dispersion Models. J. R. Stat. Soc. Ser. B49(2), 127–162 (1987) 8, 26
1987
-
[28]
Transact
Kazmierczak, R., Berthier, E., Frehse, G., Franchi, G.: CLIP-QDA: An Explainable Concept Bottleneck Model. Transact. Mach. Learn. Res. (2024) 1
2024
-
[29]
In: Pro- ceedings of the Thirtieth International Conference on Very Large Data Bases - Volume 30
Kifer, D., Ben-David, S., Gehrke, J.: Detecting Change in Data Streams. In: Pro- ceedings of the Thirtieth International Conference on Very Large Data Bases - Volume 30. p. 180–191. VLDB ’04, VLDB Endowment (2004) 7, 13
2004
-
[30]
In: Proceedings of the 35th International Conference on Machine Learning
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., Sayres, R.: Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In: Proceedings of the 35th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 80, pp. 2668–2677. PMLR (2018) 7, 31, 32
2018
-
[31]
In: The Third International Conference on Learning Representations (2015) 31 18 L
Kingma, D.P., Ba, J.: Adam: A Method for Stochastic Optimization. In: The Third International Conference on Learning Representations (2015) 31 18 L. Schmalwasser et al
2015
-
[32]
In: Proceedings of the 37th International Conference on Machine Learning
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept Bottleneck Models. In: Proceedings of the 37th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 119, pp. 5338–5348. PMLR (2020) 1, 2, 6, 12
2020
-
[33]
Krizhevsky, A.: Learning Multiple Layers of Features from Tiny Images. Tech. rep. (2009) 3, 10, 11, 31, 32, 33
2009
-
[34]
arXiv preprint arXiv:2504.10833 (2025) 4
Kumar, S., Ahuja, N.: Measuring the (Un) Faithfulness of Concept-Based Explana- tions. arXiv preprint arXiv:2504.10833 (2025) 4
-
[35]
In: The Twelfth International Conference on Learning Representations (2024) 4
Lai, S., Hu, L., Wang, J., Berti-Equille, L., Wang, D.: Faithful Vision-Language Inter- pretation via Concept Bottleneck Models. In: The Twelfth International Conference on Learning Representations (2024) 4
2024
-
[36]
In: Proceedings of the 39th International Conference on Machine Learning
Li, J., Li, D., Xiong, C., Hoi, S.: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. In: Proceedings of the 39th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 162, pp. 12888–12900 (2022) 24
2022
-
[37]
Lipton, Z.C.: The Mythos of Model Interpretability. Commun. ACM61(10), 36–43 (2018) 1
2018
-
[38]
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: LLaVA-NeXT: Improved reasoning, OCR, and world knowledge (2024) 24
2024
-
[39]
In: Computer Vision – ECCV 2024
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., Zhu, J., Zhang, L.: Grounding DINO: Marrying DINO with Grounded Pre-training for Open-Set Object Detection. In: Computer Vision – ECCV 2024. p. 38–55. Lecture Notes in Computer Science (2024) 3, 11, 12, 13, 14, 15, 24, 36, 38, 39
2024
-
[40]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024) 4
Luyten, M.R., van der Schaar, M.: A theoretical design of concept sets: improving the predictability of concept bottleneck models. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024) 4
2024
-
[41]
arXiv preprint arXiv:2106.13314 (2021) 2, 3
Mahinpei, A., Clark, J., Lage, I., Doshi-Velez, F., Pan, W.: Promises and Pitfalls of Black-Box Concept Learning Models. arXiv preprint arXiv:2106.13314 (2021) 2, 3
-
[42]
In: ICLR 2025 Workshop: XAI4Science: From Understanding Model Behavior to Discovering New Scientific Knowledge (2025) 2, 5, 21, 34
Makonnen, M., Vandenhirtz, M., Laguna, S., Vogt, J.E.: Measuring Leakage in Concept-Based Methods: An Information Theoretic Approach. In: ICLR 2025 Workshop: XAI4Science: From Understanding Model Behavior to Discovering New Scientific Knowledge (2025) 2, 5, 21, 34
2025
-
[43]
Margeloiu,A.,Ashman,M.,Bhatt,U.,Chen,Y.,Jamnik,M.,Weller,A.:DoConcept Bottleneck Models Learn as Intended? ICLR 2021 Workshop on Responsible AI (2021) 2, 3, 5
2021
-
[44]
Monographs on statistics and applied probability, 2 edn
McCullagh, P., Nelder, J.A.: Generalized Linear Models. Monographs on statistics and applied probability, 2 edn. (1989) 8, 25, 26, 27, 28, 34
1989
-
[45]
Midavaine, N., Go, G.H.T., Canez, D., Simion, I., Chatterji, S.: [Re] On the Reproducibility of Post-Hoc Concept Bottleneck Models. Trans. Mach. Learn. Res. (2024) 2, 5, 11, 30
2024
-
[46]
In: Proceedings of the 40th International Conference on Machine Learning
Moayeri, M., Rezaei, K., Sanjabi, M., Feizi, S.: Text-To-Concept (and Back) via Cross-Model Alignment. In: Proceedings of the 40th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 202, pp. 25037–25060. PMLR (2023) 1
2023
-
[47]
MIT Press (2002) 1
Murphy, G.: The Big Book of Concepts. MIT Press (2002) 1
2002
-
[48]
Nicolson, A., Schut, L., Noble, A., Gal, Y.: Explaining Explainability: Recommen- dations for Effective Use of Concept Activation Vectors. Trans. Mach. Learn. Res. (2025) 3, 10, 12, 13, 14, 31, 32, 33, 34, 36, 38, 39, 40, 41
2025
-
[49]
Oikarinen, T., Das, S., Nguyen, L.M., Weng, T.W.: Label-free Concept Bottleneck Models (2023) 2, 3, 4, 7, 8, 10, 11, 12, 13, 23, 31, 32, 34 On the Faithfulness of Post-Hoc Concept Bottleneck Models 19
2023
-
[50]
In: The Eleventh International Conference on Learning Representations (2023) 2, 23
Oikarinen, T., Weng, T.W.: Clip-dissect: Automatic description of neuron repre- sentations in deep vision networks. In: The Eleventh International Conference on Learning Representations (2023) 2, 23
2023
-
[51]
Mathematical Contributions to the Theory of Evolution
Pearson, K.: VII. Mathematical Contributions to the Theory of Evolution. III. Regression, Heredity, and Panmixia. Philos. Trans. R. Soc. A. (187), 253–318 (12
-
[52]
9, 14, 36, 38, 39, 40, 41
-
[53]
In: Math
Penrose, R.: On best approximate solutions of linear matrix equations. In: Math. Proc. Camb. Philos. Soc. vol. 52, pp. 17–19. Cambridge University Press (1956) 6, 22
1956
-
[54]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Penzel, N., Denzler, J.: Locally explaining prediction behavior via gradual inter- ventions and measuring property gradients. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 7398– 7408 (March 2026). https://doi.org/10.48550/arXiv.2503.05424 , https: //propgrad.github.io25
-
[55]
In: International Conference on Learning Representations (2021) 2, 3, 5, 6, 21
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., Goldstein, T.: The Intrinsic Dimension of Images and Its Impact on Learning. In: International Conference on Learning Representations (2021) 2, 3, 5, 6, 21
2021
-
[56]
In: Proceedings of the 38th International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning Transferable Visual Models From Natural Language Supervision. In: Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 8748–8763...
2021
-
[57]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ramaswamy, V.V., Kim, S.S., Fong, R., Russakovsky, O.: Overlooked Factors in Concept-based Explanations: Dataset Choice, Concept Learnability, and Human Capability. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10932–10941 (2023) 4, 6
2023
- [58]
-
[59]
In: International Conference on Machine Learning (ICML) (2025),https://fastcav.github.io/ 7
Schmalwasser,L.,Penzel,N.,Denzler,J.,Niebling,J.:Fastcav:Efficientcomputation of concept activation vectors for explaining deep neural networks. In: International Conference on Machine Learning (ICML) (2025),https://fastcav.github.io/ 7
2025
-
[60]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Schoen, R., Abeloos, B., Herbin, S.: Measuring and Addressing Information Leakage in Concept Bottleneck Models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 624–632 (2025) 3, 5, 34
2025
-
[61]
Shimodaira, H.: Improving predictive inference under covariate shift by weighting the log-likelihood function. J. Stat. Plan. Inference90(2), 227–244 (2000) 7, 23
2000
-
[62]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: DINOv3. arXiv preprint a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Speer, R., Chin, J., Havasi, C.: ConceptNet 5.5: an open multilingual graph of generalknowledge.In:ProceedingsoftheThirty-FirstAAAIConferenceonArtificial Intelligence. p. 4444–4451 (2017) 11, 32
2017
-
[64]
Schmalwasser et al
Srivastava, D., Yan, G., Weng, T.W.: VLG-CBM: Training Concept Bottleneck Models with Vision-Language Guidance (2024) 2, 3, 4, 6, 7, 8, 11, 12, 13, 14, 21, 23, 24, 32, 34 20 L. Schmalwasser et al
2024
-
[65]
The MIT Press (2012) 7, 23
Sugiyama, M., Kawanabe, M.: Machine Learning in Non-Stationary Environments: Introduction to Covariate Shift Adaptation. The MIT Press (2012) 7, 23
2012
-
[66]
arXiv preprint arXiv:2402.05945 (2024) 3
Sun, A., Yuan, Y., Ma, P., Wang, S.: Eliminating information leakage in hard concept bottleneck models with supervised, hierarchical concept learning. arXiv preprint arXiv:2402.05945 (2024) 3
-
[67]
https://github.com/osmr/ imgclsmob(2024), GitHub repository, accessed February 2026 9
Sémery, O.: imgclsmob: Deep learning networks. https://github.com/osmr/ imgclsmob(2024), GitHub repository, accessed February 2026 9
2024
-
[68]
In: Computer Vision – ECCV 2024
Tan, A., Zhou, F., Chen, H.: Explain via Any Concept: Concept Bottleneck Model with Open Vocabulary Concepts. In: Computer Vision – ECCV 2024. p. 123–138. Lecture Notes in Computer Science, Springer-Verlag (2024) 1
2024
-
[69]
Vandenhirtz, M., Laguna, S., Marcinkevičs, R., Vogt, J.E.: Stochastic Concept Bottleneck Models (2024) 1
2024
-
[70]
47 (2018) 22
Vershynin, R.: High-Dimensional Probability: An Introduction with Applications in Data Science, vol. 47 (2018) 22
2018
-
[71]
Welinder, P., Branson, S., Mita, T., Wah, C., Schroff, F., Belongie, S., Perona, P.: Caltech-UCSD Birds 200 (2010) 3, 9, 14, 31, 32, 33, 34, 36, 37, 40, 41
2010
-
[72]
In: The Eleventh International Conference on Learning Representations (2023) 2, 3, 4, 6, 7, 10, 11, 12, 14, 21, 25, 30, 31, 32, 34
Yuksekgonul, M., Wang, M., Zou, J.: Post-hoc concept bottleneck models. In: The Eleventh International Conference on Learning Representations (2023) 2, 3, 4, 6, 7, 10, 11, 12, 14, 21, 25, 30, 31, 32, 34
2023
-
[73]
In: Proceedings of the Twenty-First International Conference on Machine Learning
Zhang, T.: Solving large scale linear prediction problems using stochastic gradient descent algorithms. In: Proceedings of the Twenty-First International Conference on Machine Learning. Association for Computing Machinery (2004) 13, 36
2004
-
[74]
Is the concept ’tk’ present in this image? Answer Yes or No
Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B67(2), 301–320 (03 2005) 31 On the Faithfulness of Post-Hoc Concept Bottleneck Models 21 A Additional Theoretical Details A.1 Johnson-Lindenstrauss for Smooth Manifolds While neural activation spaces are high-dimensional (A ⊂R d), valid activations empir...
2005
-
[75]
Distributional Assumption.Because concepts in post-hoc CBMs can be mod- eled in various ways, such as binary indicators (e.g., presence of “wings”) or continuous similarity scores (e.g., similarity with a VLM prompt), we need a gen- eral framework to model the concept distribution. TheMultivariate Exponential Dispersion Family(EDF) [27,44] provides this g...
-
[76]
Structural Assumption.To formally model the concept projection, we follow the standard GLM framework [16,44], which connects the backbone activations to the expected concept valuesµ through a linear predictorζ and an invertible link function ψ. In the context of post-hoc CBMs, the linear predictor corresponds to On the Faithfulness of Post-Hoc Concept Bot...
-
[77]
Gradient of the Log-Likelihood.Our optimization objective is to minimize the Negative Log-Likelihood (NLL) on the training data. For a single observation (f(x), c)∈ A × C, the loss functionLis derived from the EDF density: L(πΘ(f(x)), c) =−logp(c|η, ϕ)(28) =−log exp ⟨c, η⟩ −A(η) s(ϕ) +k(c, ϕ) (29) =− ⟨c, η⟩ −A(η) s(ϕ) +k(c, ϕ) (30) ∝ − 1 s(ϕ) (⟨c, η⟩ −A(η...
-
[78]
Thus, the surrogate objective ˜Jtask(Θ; L)is the expected risk over the task distributionPtask, calculated using these surrogate labels: ˜Jtask(Θ;L) =E x∼Ptask [L(πΘ(f(x)),˜c(x))]
Surrogate Optimality Condition.We assume the projection parametersΘ are learned using a surrogate labeling function˜c: X → C (see Appendix A.4 for examples) rather than the inaccessible ground truth. Thus, the surrogate objective ˜Jtask(Θ; L)is the expected risk over the task distributionPtask, calculated using these surrogate labels: ˜Jtask(Θ;L) =E x∼Pta...
-
[79]
(41) We evaluate the gradient of this objective at the parameters˜Θ learned via the surrogate optimization
Gradient of the True Objective.We define thetrueobjective J ∗ task(Θ; L)as the expected risk with respect to the ground-truth concept functionc∗(x)and the true dispersion parameterϕ∗: J ∗ task(Θ;L) =E x∼Ptask [L(πΘ(f(x)), c ∗(x))]. (41) We evaluate the gradient of this objective at the parameters˜Θ learned via the surrogate optimization. Substituting the ...
-
[80]
with concept projections trained on the CUB [70], CIFAR-10 [33], and Elements [48] datasets and compares them with PCBMs utilizing a semantically meaningless concept projectionπΘrand for the respective dataset (Appendix B.1). For the concept projectionπΘrand, we scale the bottleneck dimensionK of the weight matrixΘrand ∈R K×d to align with the number of c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.