Staged Hybridisation for Visual Quantum Reinforcement Learning via Knowledge Distillation
Pith reviewed 2026-06-30 06:05 UTC · model grok-4.3
The pith
Staged knowledge distillation from a classical teacher lets shallow variational quantum circuit heads learn effective visual-control policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
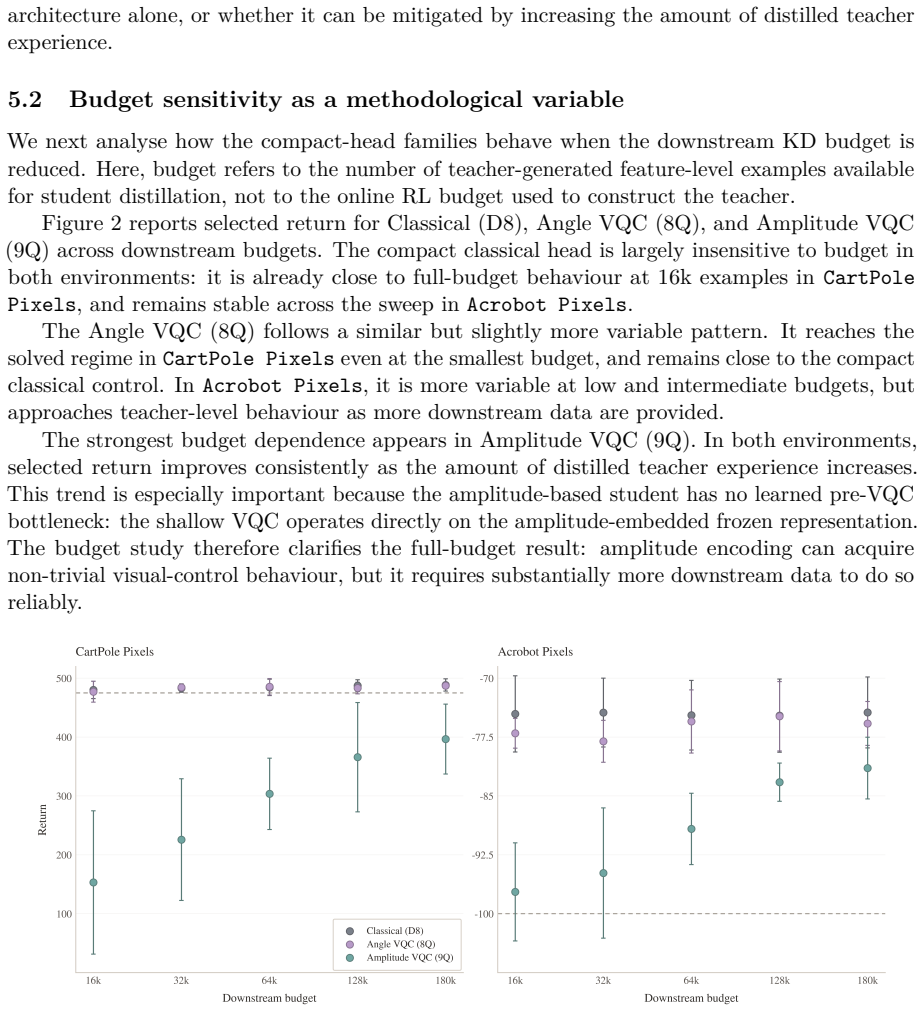
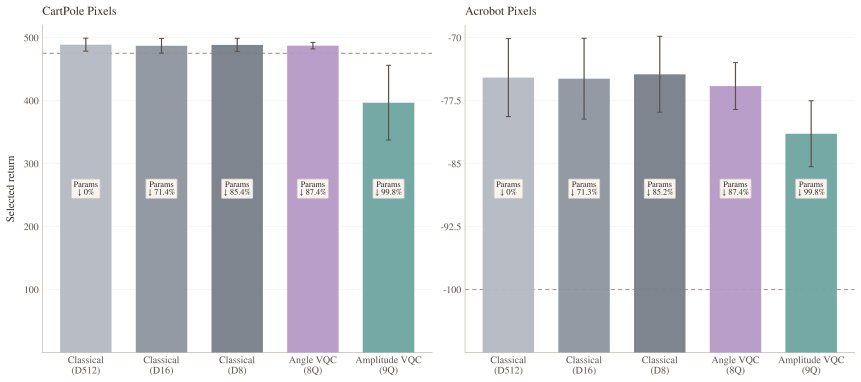
Staged hybridisation via knowledge distillation enables shallow VQC heads to acquire non-trivial visual-control behaviour on CartPole Pixels and Acrobot Pixels in settings where direct pixel-based training would be substantially more difficult. Angle-encoded VQC heads retain near-teacher performance while amplitude-encoded heads achieve greater compactness at the cost of increased fragility and simulation time. The pipeline reframes visual QRL as a compact-head learning problem rather than an end-to-end optimisation task.
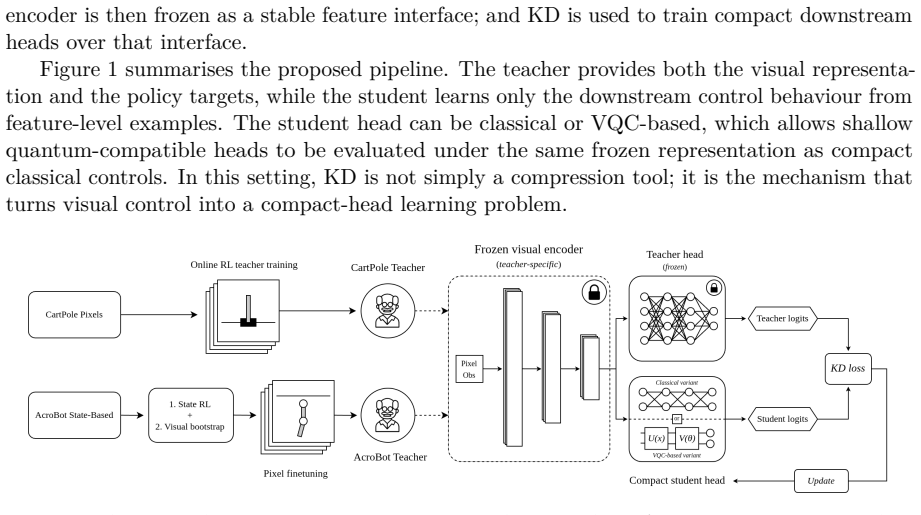
What carries the argument
Frozen classical encoder serving as a fixed feature interface for distilling teacher policy into compact VQC or classical student heads.
If this is right
- Angle-encoded VQC heads can match classical teacher performance under the frozen representation.
- Amplitude-encoded heads reach extreme compactness while still producing usable policies.
- Visual QRL becomes feasible as a compact-head learning problem outside the standard end-to-end RL loop.
- The same frozen encoder supports both classical and quantum student heads for direct comparison.
Where Pith is reading between the lines
- The method could be tested on additional pixel-based control benchmarks to check whether the encoder's features generalise beyond the two evaluated environments.
- If the classical encoder's representation is task-specific, staged distillation might need periodic re-freezing when switching between different visual RL domains.
- Combining the staged approach with other quantum encodings or hybrid architectures could further reduce the simulation budget required for training.
Load-bearing premise
The features extracted by the frozen classical encoder remain sufficient and compatible for small quantum heads to recover effective policies without any joint retraining of the encoder.
What would settle it
Direct end-to-end training of the same shallow VQC architectures from raw pixels achieves performance comparable to or better than the distilled heads on CartPole Pixels and Acrobot Pixels.
Figures
read the original abstract
Visual environments are a demanding setting for quantum reinforcement learning (QRL): high-dimensional observations, unstable RL optimisation, and constrained variational quantum circuits (VQCs) are difficult to train jointly. This paper studies knowledge distillation (KD) as a staged hybridisation strategy for visual QRL. Instead of training a hybrid visual agent end-to-end from pixels, we first train a classical visual teacher, freeze its encoder as a feature interface, and distil the teacher's policy behaviour into compact downstream heads. These heads can be classical or VQC-based, enabling small quantum-compatible students to be evaluated under the same frozen representation as compact classical controls. We evaluate the pipeline on CartPole Pixels and Acrobot Pixels. The results show that staged KD enables shallow VQC heads to acquire non-trivial visual-control behaviour in settings where direct pixel-based training would be substantially more difficult. Angle-encoded VQC heads retain near-teacher performance, while amplitude-encoded heads push compactness to an extreme regime, at the cost of greater fragility, stronger budget sensitivity, and higher simulation time. Overall, staged KD reframes visual QRL as a compact-head learning problem, opening a practical route for training small quantum-compatible policies outside the standard end-to-end RL loop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes staged knowledge distillation (KD) as a hybridisation strategy for visual quantum reinforcement learning (QRL). A classical teacher is trained on pixel observations, its encoder is frozen to provide a feature interface, and the teacher's policy is distilled into compact student heads that may be classical or variational quantum circuit (VQC)-based. Experiments on CartPole Pixels and Acrobot Pixels are reported to show that angle-encoded shallow VQC heads retain near-teacher performance while amplitude-encoded heads achieve extreme compactness at the cost of fragility.
Significance. If the empirical claims hold, the work supplies a practical route for training small quantum-compatible policies on visual tasks by decoupling the high-dimensional encoder from the quantum head, thereby sidestepping joint end-to-end optimisation difficulties that currently limit VQC scalability in visual RL.
major comments (2)
- [Experiments] Experiments section: the central claim that 'staged KD enables shallow VQC heads to acquire non-trivial visual-control behaviour in settings where direct pixel-based training would be substantially more difficult' is load-bearing yet unsupported by any direct comparator. Only results for the staged pipeline (frozen classical encoder + distilled VQC head) are presented; no performance, failure modes, or scaling curves are given for an otherwise identical VQC architecture trained end-to-end from pixels or with joint encoder optimisation. Without this baseline the performance gap attributable to staging versus feature quality cannot be isolated.
- [Method / Experiments] The modelling assumption that the frozen classical encoder produces a feature representation that remains sufficient and compatible for downstream VQC heads is stated but not tested; the paper supplies no ablation that varies encoder quality or joint fine-tuning to quantify when the assumption holds.
minor comments (1)
- [Abstract] Abstract and results paragraphs state empirical outcomes (near-teacher performance, fragility, budget sensitivity) without accompanying numerical values, error bars, or table references, making it impossible to assess effect sizes from the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The points raised identify key areas where additional empirical support would strengthen the manuscript. We respond to each major comment below and commit to revisions that address the concerns without overstating our current results.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that 'staged KD enables shallow VQC heads to acquire non-trivial visual-control behaviour in settings where direct pixel-based training would be substantially more difficult' is load-bearing yet unsupported by any direct comparator. Only results for the staged pipeline (frozen classical encoder + distilled VQC head) are presented; no performance, failure modes, or scaling curves are given for an otherwise identical VQC architecture trained end-to-end from pixels or with joint encoder optimisation. Without this baseline the performance gap attributable to staging versus feature quality cannot be isolated.
Authors: We acknowledge that the absence of a direct end-to-end VQC baseline leaves the specific contribution of staging less isolated than ideal. Our experiments were designed to demonstrate feasibility of the staged pipeline on the chosen environments, and the claim regarding direct training difficulty draws from known VQC optimization challenges with high-dimensional inputs in the broader QRL literature. We will revise the Experiments section to explicitly discuss these challenges, include any available observations from preliminary direct-training attempts, and add a short discussion of failure modes where data exists. Full scaling curves for end-to-end training are not currently available and would require substantial additional computation. revision: partial
-
Referee: [Method / Experiments] The modelling assumption that the frozen classical encoder produces a feature representation that remains sufficient and compatible for downstream VQC heads is stated but not tested; the paper supplies no ablation that varies encoder quality or joint fine-tuning to quantify when the assumption holds.
Authors: We agree that the sufficiency and compatibility of the frozen encoder representation would be better supported by targeted ablations. In the revised manuscript we will add an ablation study that varies the classical encoder architecture and reports performance under the same distillation protocol. We will also include a limited joint fine-tuning experiment to quantify the impact of keeping the encoder frozen versus allowing limited updates. revision: yes
Circularity Check
No circularity; empirical pipeline with no derivation chain
full rationale
The manuscript describes an empirical staged KD pipeline for visual QRL without any mathematical derivations, equations, fitted parameters presented as predictions, or uniqueness theorems. The central claim rests on experimental outcomes under a frozen classical encoder, which is an explicit modeling assumption rather than a result derived from the paper's own inputs or self-citations. No load-bearing steps reduce to self-definition or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Knowledge Distillation in Quantum Neural Network using Approximate Synthesis
Mahabubul Alam, Satwik Kundu, and Swaroop Ghosh. Knowledge Distillation in Quantum Neural Network using Approximate Synthesis. In2023 28th Asia and South Pacific Design Automation Conference (ASP-DAC), pages 639–644, January 2023
2023
-
[2]
Ahmad Alomari and Sathish A. P. Kumar. A Survey of Quantum Reinforcement Learning Approaches: Current Status and Future Research Directions. In2025 IEEE Conference on Artificial Intelligence (CAI), pages 1375–1382, May 2025. doi: 10.1109/CAI64502.2025.00283
-
[3]
Quantum Imitation Learning, April 2023
Zhihao Cheng, Kaining Zhang, Li Shen, and Dacheng Tao. Quantum Imitation Learning, April 2023
2023
-
[4]
Daoyi Dong, Chunlin Chen, Hanxiong Li, and Tzyh-Jong Tarn. Quantum Reinforcement Learning.IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 38 (5):1207–1220, October 2008. ISSN 1941-0492. doi: 10.1109/TSMCB.2008.925743
-
[5]
Simon Eisenmann, Daniel Hein, Steffen Udluft, and Thomas A. Runkler. Model-based Offline Quantum Reinforcement Learning. In2024 IEEE International Conference on Quantum Computing and Engineering (QCE), pages 1490–1496, September 2024. doi: 10.1109/QCE60285.2024.00175
-
[6]
A quantum-classical reinforcement learning model to play Atari games, December 2024
Dominik Freinberger, Julian Lemmel, Radu Grosu, and Sofiene Jerbi. A quantum-classical reinforcement learning model to play Atari games, December 2024
2024
-
[7]
Mohammad Junayed Hasan and M. R. C. Mahdy. Bridging Classical and Quantum Machine Learning: KnowledgeTransferFromClassicaltoQuantumNeuralNetworksUsingKnowledge Distillation, March 2025
2025
-
[8]
Distilling the Knowledge in a Neural Network, March 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the Knowledge in a Neural Network, March 2015
2015
-
[9]
Benchmarking Quantum Reinforcement Learning, February 2025
Georg Kruse, Rodrigo Coelho, Andreas Rosskopf, Robert Wille, and Jeanette-Miriam Lorenz. Benchmarking Quantum Reinforcement Learning, February 2025
2025
-
[10]
Dissecting Quantum Reinforcement Learning: A Systematic Evaluation of Key Components, November 2025
Javier Lazaro, Juan-Ignacio Vazquez, and Pablo Garcia-Bringas. Dissecting Quantum Reinforcement Learning: A Systematic Evaluation of Key Components, November 2025
2025
-
[11]
Playing Atari with Hybrid Quantum-Classical Reinforcement Learning
Owen Lockwood and Mei Si. Playing Atari with Hybrid Quantum-Classical Reinforcement Learning. InNeurIPS 2020 Workshop on Pre-registration in Machine Learning, pages 285–301. PMLR, July 2021
2020
-
[12]
Bromley, Josh Izaac, Maria Schuld, and Nathan Killoran
Andrea Mari, Thomas R. Bromley, Josh Izaac, Maria Schuld, and Nathan Killoran. Transfer learning in hybrid classical-quantum neural networks.Quantum, 4:340, October 2020. doi: 10.22331/q-2020-10-09-340
-
[13]
Scherer, Axel Plinge, and Christopher Mutschler
Nico Meyer, Christian Ufrecht, Maniraman Periyasamy, Daniel D. Scherer, Axel Plinge, and Christopher Mutschler. A Survey on Quantum Reinforcement Learning, March 2024
2024
-
[14]
Nico Meyer, Christian Ufrecht, George Yammine, Georgios Kontes, Christopher Mutschler, and Daniel D. Scherer. Benchmarking Quantum Reinforcement Learning, January 2025
2025
-
[15]
Dániel T. R. Nagy, Csaba Czabán, Bence Bakó, Péter Hága, Zsófia Kallus, and Zoltán Zimborás. Hybrid quantum-classical reinforcement learning in latent observation spaces. Quantum Machine Intelligence, 7(2):88, September 2025. ISSN 2524-4914. doi: 10.1007/ s42484-025-00306-z. 12
2025
-
[16]
Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell
Andrei A. Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy Distillation, January 2016
2016
-
[17]
Distilling the knowledge with quantum neural networks, March 2026
Yuxuan Yan, Sitian Qian, Qi Zhao, and Xingjian Zhang. Distilling the knowledge with quantum neural networks, March 2026. 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.