One-Step Gradient Delay is Not a Barrier for Large-Scale Asynchronous Pipeline Parallel LLM Pretraining
Pith reviewed 2026-06-30 06:39 UTC · model grok-4.3
The pith
One-step gradient delay is not an intrinsic barrier to stable LLM pretraining under asynchronous pipeline parallelism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
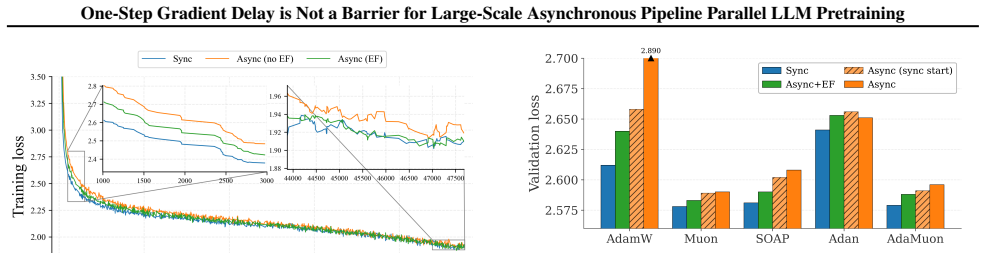
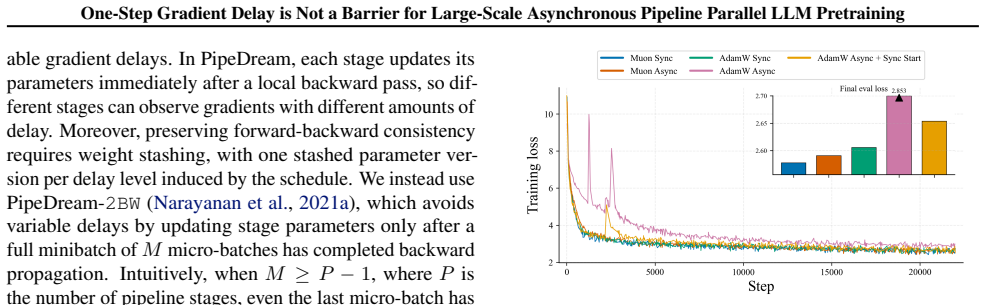
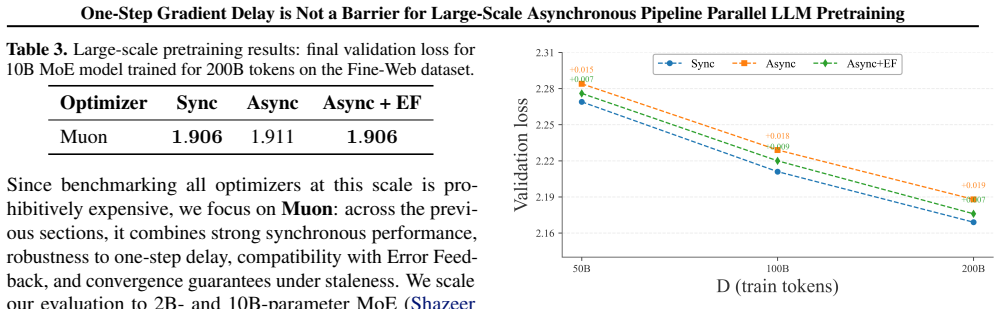
We demonstrate that the performance degradation associated with one-step gradient delay in PipeDream-2BW is not an intrinsic limitation but depends on the choice of optimizer. While AdamW suffers severe degradation, Muon exhibits strong robustness. We introduce an Error Feedback-inspired correction that further mitigates delay effects, provide theoretical convergence analysis for Muon, and show through experiments on models up to 10B parameters that these strategies bridge the performance gap with synchronous training.
What carries the argument
PipeDream-2BW's fixed one-step gradient delay schedule together with optimizer-specific robustness and an Error Feedback correction that compensates staleness without changing the optimizer.
If this is right
- Muon maintains convergence guarantees and practical performance under one-step delay both with and without the correction.
- The Error Feedback correction can be applied across optimizers to reduce staleness impact.
- Asynchronous pipeline schedules become viable for large-scale pretraining while preserving final model quality.
- Throughput gains from eliminating pipeline bubbles can be realized without retraining from scratch or major hyperparameter changes.
- Theoretical analysis extends to Muon under delayed gradients, supporting its use beyond the empirical regimes tested.
Where Pith is reading between the lines
- Other recently proposed optimizers may exhibit similar tolerance to one-step delay and merit targeted testing.
- The correction mechanism could be combined with existing techniques such as gradient accumulation or mixed-precision to amplify throughput benefits.
- If the pattern holds, hardware schedulers for large clusters might default to asynchronous pipelines for most pretraining workloads.
- The same delay-robustness logic may apply to other forms of asynchrony such as data-parallel parameter-server updates.
Load-bearing premise
The empirical robustness observed for Muon on models up to 10B parameters will continue to hold at larger scales and across the full range of training hyperparameters used in production pretraining runs.
What would settle it
A controlled experiment training a model larger than 10B parameters with Muon under one-step delay that produces a persistent loss or perplexity gap relative to its synchronous counterpart of the same size and hyperparameters.
Figures
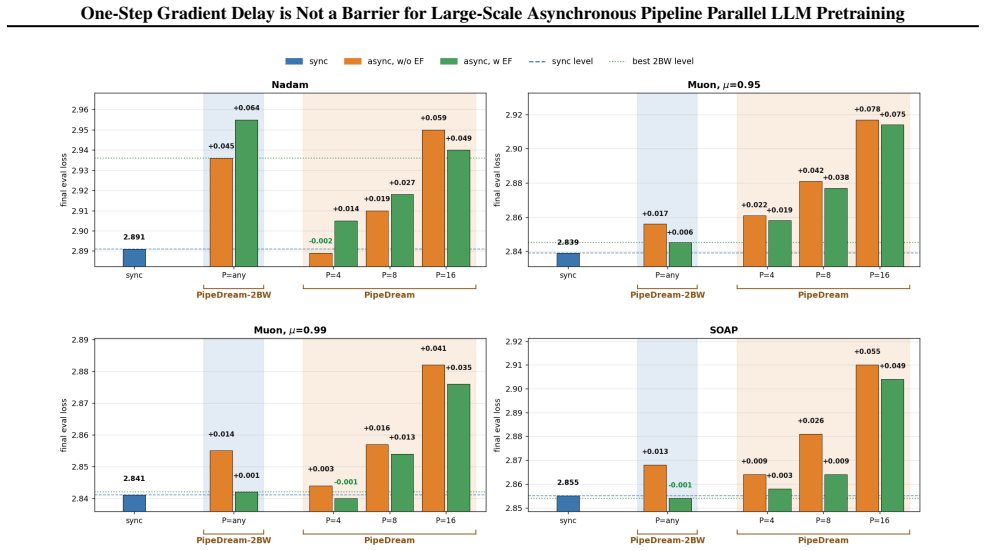
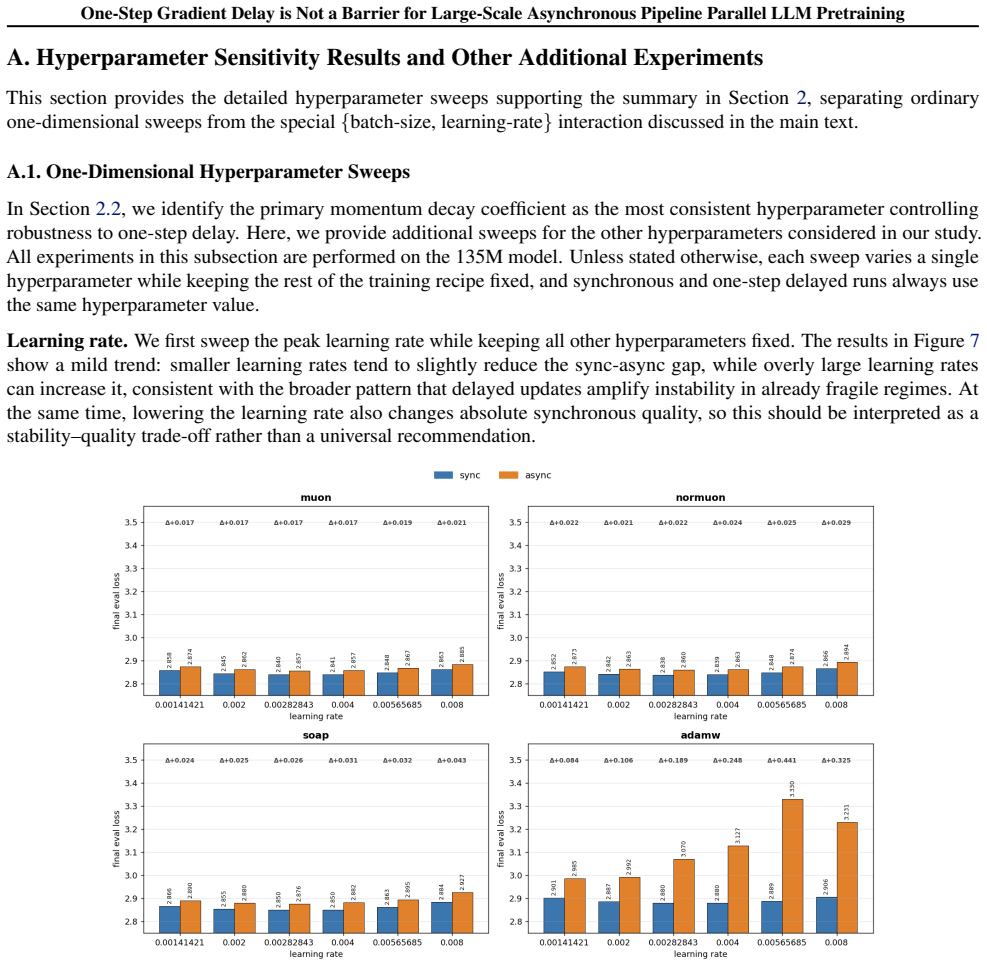
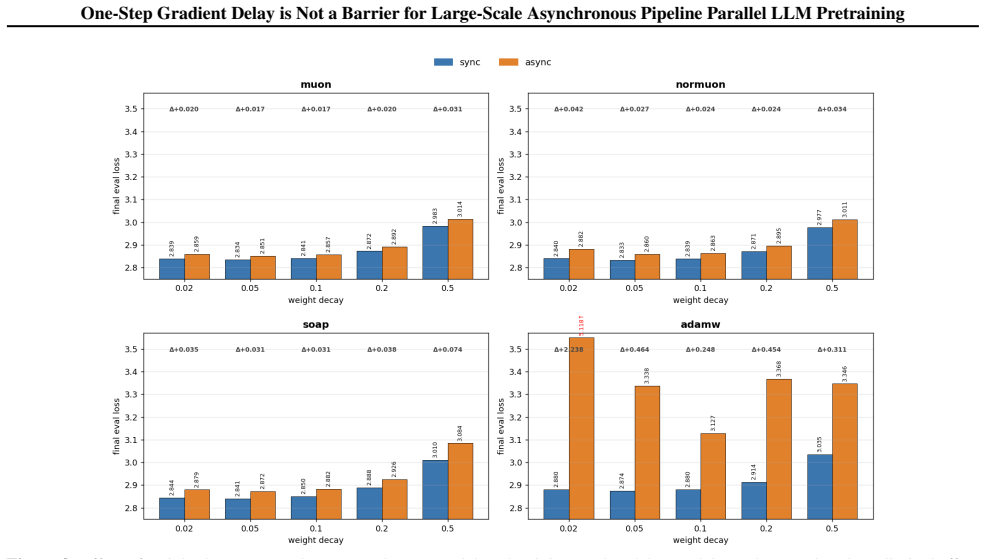
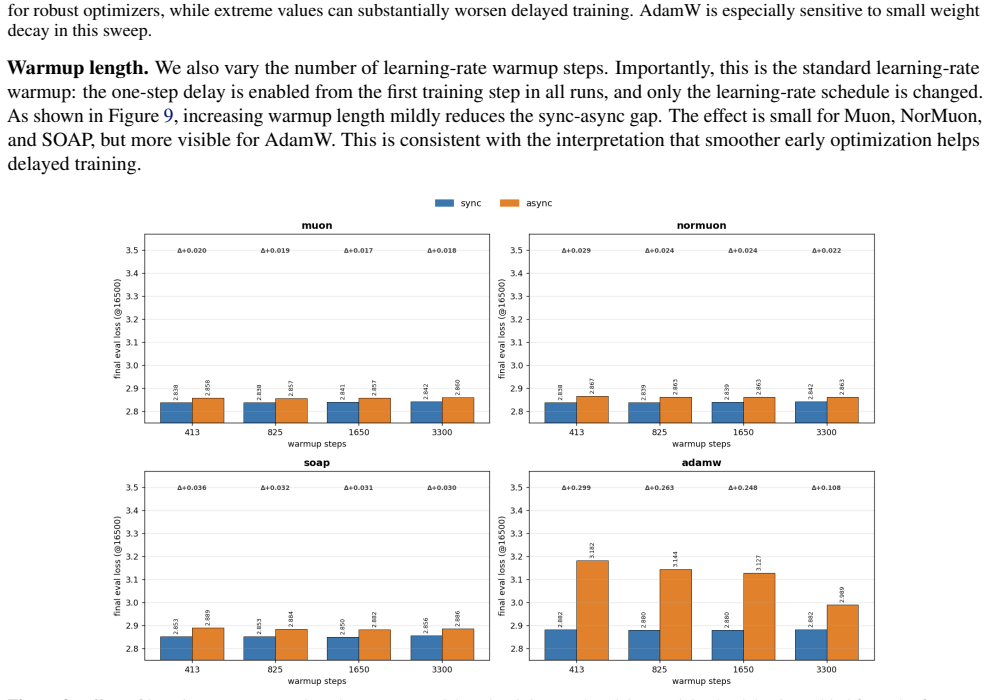
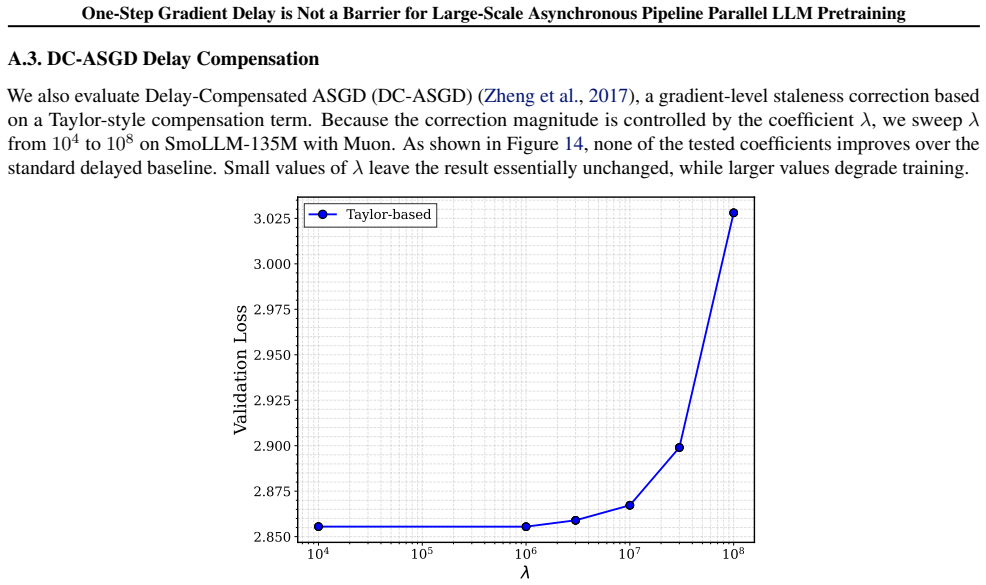
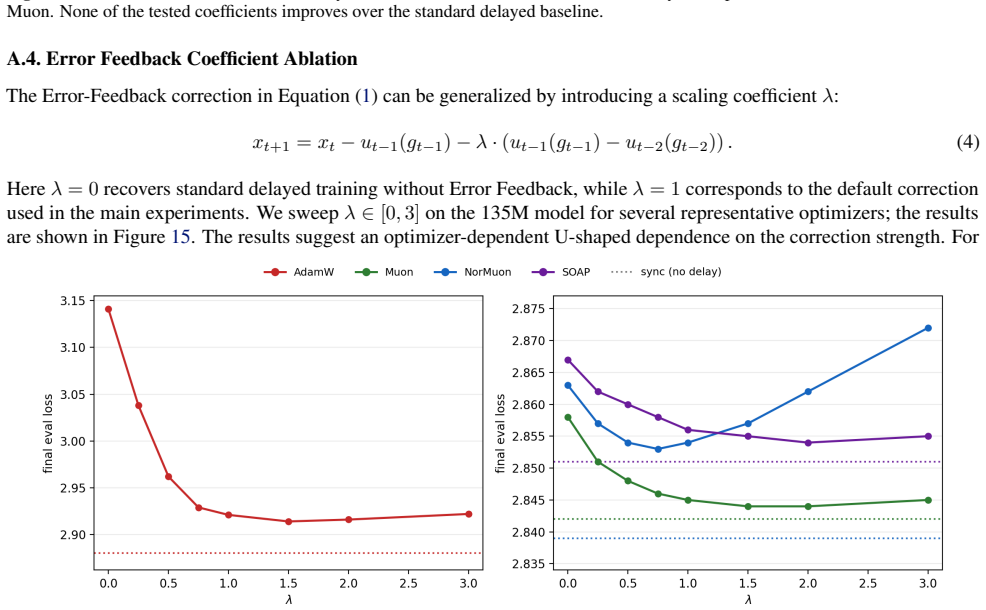
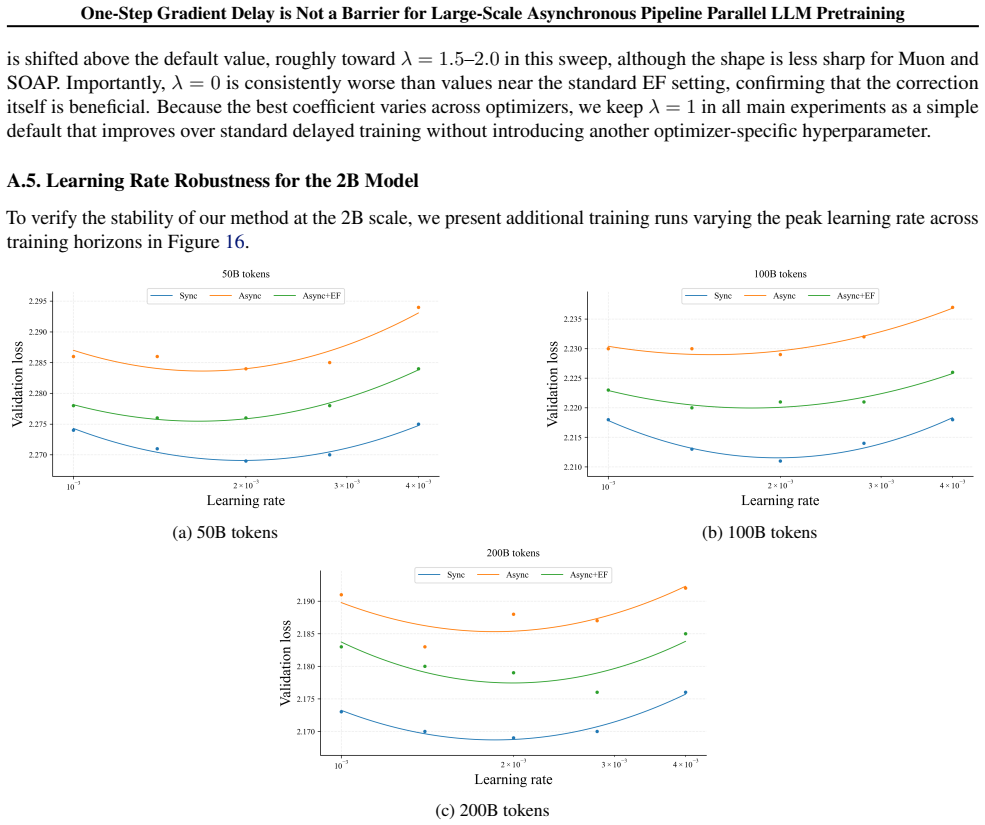
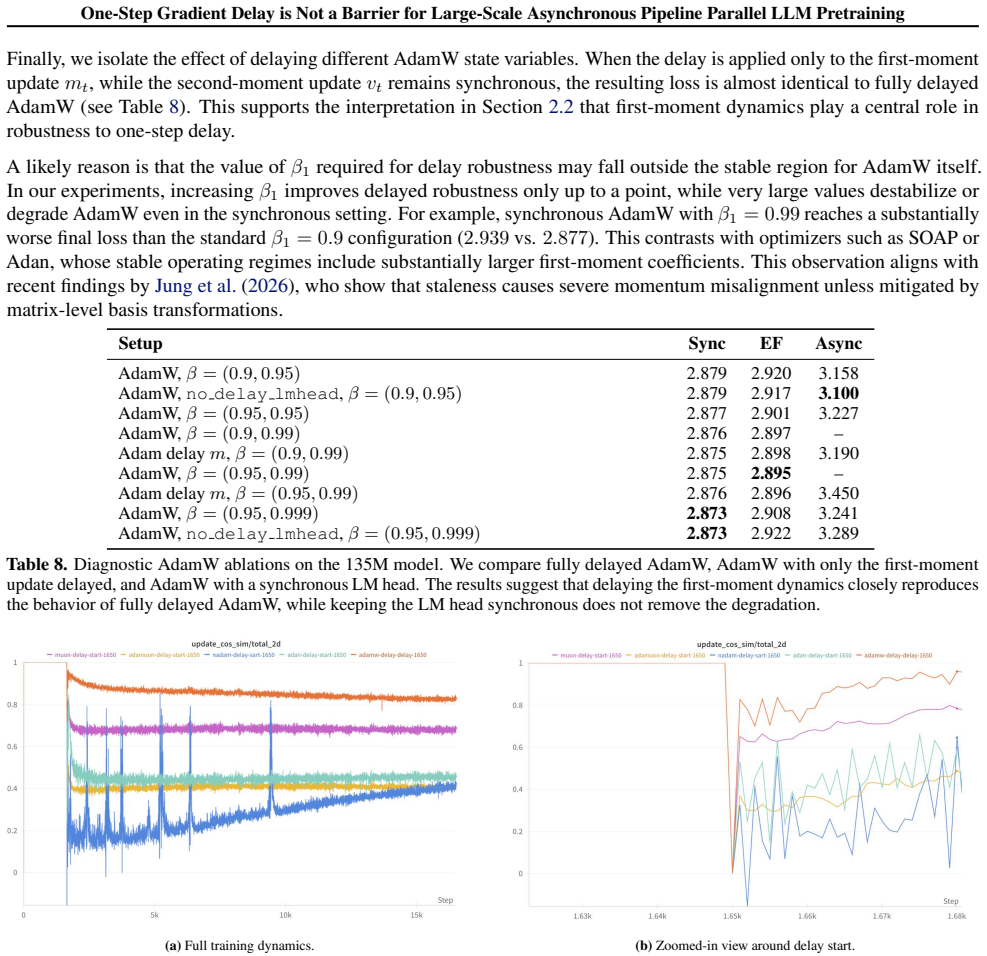
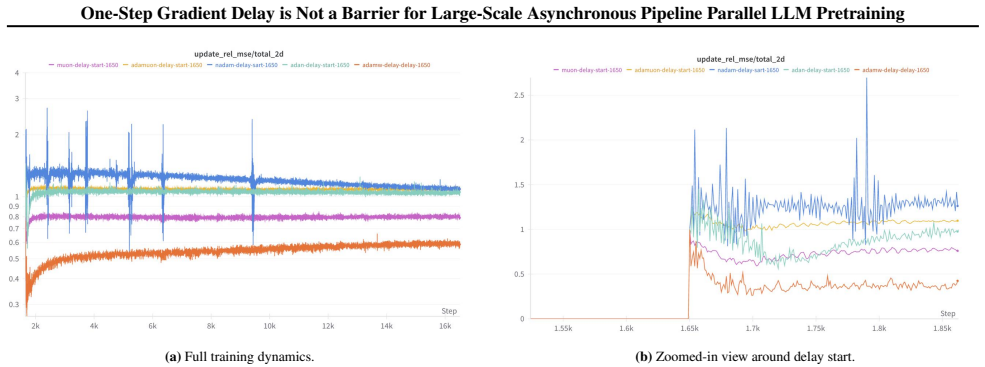
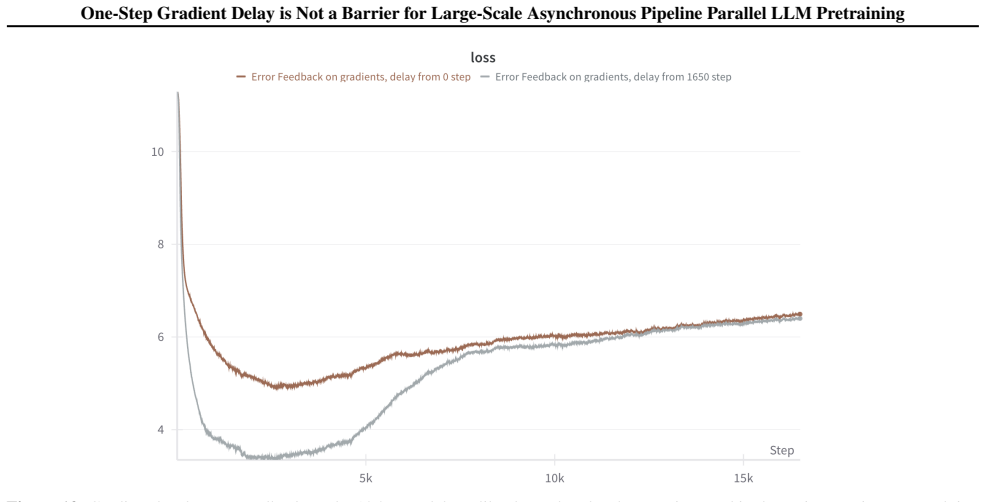
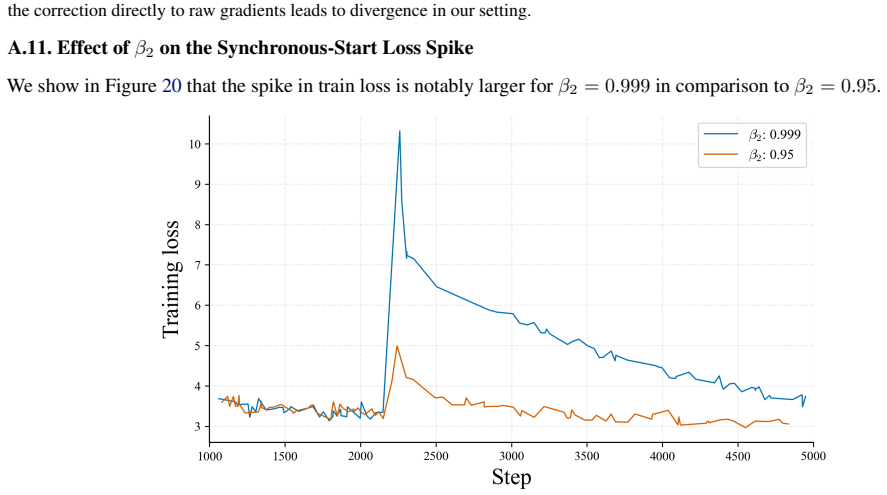
read the original abstract
Modern large-scale LLM pretraining benefits from utilizing Pipeline Parallelism; however, synchronous implementations leave GPUs idle during pipeline bubbles, wasting computational resources. Asynchronous Pipeline Parallelism eliminates these bubbles, maximizing throughput at the cost of gradient staleness. Among asynchronous schedules, PipeDream-2BW is particularly appealing: unlike the original PipeDream schedule, it ensures a constant one-step gradient delay regardless of pipeline depth. However, its adoption remains limited due to the common belief that optimizing under staleness is fundamentally unstable. In this work, we challenge this assumption, demonstrating that degradation under one-step delay depends strongly on optimizer choice rather than being an intrinsic limitation. We provide the first comprehensive empirical analysis showing that while AdamW, the predominant optimizer at the time when PipeDream-2BW was introduced, indeed suffers from severe degradation, recent methods like Muon exhibit strong robustness under a one-step delay. We introduce an optimizer-agnostic Error Feedback-inspired correction to further mitigate delay effects. We provide supporting theoretical analysis demonstrating convergence for Muon with and without this correction. Extensive evaluation on models up to 10B parameters confirms that our strategies bridge the performance gap with synchronous training, highlighting the practical potential of asynchronous pipeline parallelism at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that one-step gradient delay in asynchronous pipeline parallelism (specifically PipeDream-2BW) is not an intrinsic barrier to LLM pretraining performance. It argues that observed degradation depends on optimizer choice: AdamW exhibits severe degradation under delay, while Muon shows strong robustness. The work provides the first comprehensive empirical comparison, introduces an optimizer-agnostic Error Feedback-inspired correction, supplies convergence theory for Muon (with and without correction), and reports that the proposed strategies close the gap to synchronous training on models up to 10B parameters, suggesting practical potential for asynchronous methods at scale.
Significance. If the Muon robustness result generalizes, the work would enable higher GPU utilization in large-scale pretraining by removing pipeline bubbles without accuracy loss, using modern optimizers. The empirical analysis across optimizers and the provision of both theory and an error-feedback fix are clear strengths. The manuscript ships reproducible empirical trends and a stated convergence analysis rather than circular fits.
major comments (1)
- [Abstract and evaluation sections] Abstract and evaluation sections: all reported results use models ≤10B parameters. The central practical claim—that one-step delay 'is not a barrier' and has 'practical potential at scale'—rests on extrapolation from these sizes. The convergence theory does not address scale-dependent phenomena (e.g., changes in gradient variance or curvature at 100B+ scales) that could reintroduce the AdamW-style degradation; this assumption is load-bearing for the title and conclusion.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the important question of scale. We address the concern point-by-point below.
read point-by-point responses
-
Referee: [Abstract and evaluation sections] Abstract and evaluation sections: all reported results use models ≤10B parameters. The central practical claim—that one-step delay 'is not a barrier' and has 'practical potential at scale'—rests on extrapolation from these sizes. The convergence theory does not address scale-dependent phenomena (e.g., changes in gradient variance or curvature at 100B+ scales) that could reintroduce the AdamW-style degradation; this assumption is load-bearing for the title and conclusion.
Authors: We agree that all empirical results are confined to models ≤10B and that the convergence analysis for Muon (with and without error feedback) is derived under standard assumptions on stochastic gradients that do not explicitly model scale-dependent changes in variance or curvature. The manuscript does not claim to have tested 100B+ regimes. However, the core empirical finding—that degradation under one-step delay is optimizer-dependent rather than intrinsic—is demonstrated consistently across model sizes from 125M to 10B, and the Muon analysis relies on properties (e.g., spectral normalization) that are size-agnostic in the proof. We will revise the abstract, title, and conclusion to replace unqualified phrases such as “at scale” and “large-scale” with “up to 10B parameters” and to add an explicit discussion of the extrapolation limit and the assumptions underlying the theory. We cannot run 100B+ experiments with available resources, but the requested revision will ensure the claims accurately reflect the evaluated regime. revision: partial
Circularity Check
No circularity; empirical results and convergence analysis are independent of fitted inputs
full rationale
The paper's central claims rest on new empirical runs (models ≤10B) comparing AdamW vs. Muon under one-step delay, plus a stated convergence analysis for Muon. No derivation reduces by construction to its own fitted parameters, self-citations, or ansatzes. The error-feedback correction is introduced as a new component with supporting theory; scaling caveats are acknowledged as extrapolation limits rather than internal circularity. This matches the default non-circular case.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, J., Lee-Thorp, J., De Jong, M., Zemlyanskiy, Y ., Lebr´on, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head check- points.arXiv preprint arXiv:2305.13245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Nesterov method for asynchronous pipeline parallel optimization.arXiv preprint arXiv:2505.01099,
Ajanthan, T., Ramasinghe, S., Zuo, Y ., Avraham, G., and Long, A. Nesterov method for asynchronous pipeline parallel optimization.arXiv preprint arXiv:2505.01099,
-
[3]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Allal, L. B., Lozhkov, A., Bakouch, E., Bl ´azquez, G. M., Penedo, G., Tunstall, L., Marafioti, A., Kydl ´ıˇcek, H., Lajar´ın, A. P., Srivastav, V ., et al. Smollm2: When smol goes big–data-centric training of a small language model. arXiv preprint arXiv:2502.02737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
PIQA: Reasoning about Physical Commonsense in Natural Language
URL https://arxiv.org/abs/ 1911.11641. Chen, C.-C., Yang, C.-L., and Cheng, H.-Y . Efficient and robust parallel dnn training through model parallelism on multi-gpu platform.arXiv preprint arXiv:1809.02839,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[6]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
URLhttps: //arxiv.org/abs/1905.10044. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
URL https://arxiv.org/abs/ 1803.05457. Dozat, T. Incorporating nesterov momentum into adam
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Error feedback for muon and friends.arXiv preprint arXiv:2510.00643,
Gruntkowska, K., Gaponov, A., Tovmasyan, Z., and Richt´arik, P. Error feedback for muon and friends.arXiv preprint arXiv:2510.00643,
-
[10]
Xpipe: Efficient pipeline model parallelism for multi-gpu dnn training
Guan, L., Yin, W., Li, D., and Lu, X. Xpipe: Efficient pipeline model parallelism for multi-gpu dnn training. arXiv preprint arXiv:1911.04610,
-
[11]
URL https: //arxiv.org/abs/2009.03300. 11 One-Step Gradient Delay is Not a Barrier for Large-Scale Asynchronous Pipeline Parallel LLM Pretraining Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv preprint arX...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[12]
Muon: An opti- mizer for hidden layers in neural networks, 2024.URL https://kellerjordan.github.io/posts/muon, 6,
Jordan, K., Jin, Y ., Boza, V ., Jiacheng, Y ., Cecista, F., Newhouse, L., and Bernstein, J. Muon: An opti- mizer for hidden layers in neural networks, 2024.URL https://kellerjordan.github.io/posts/muon, 6,
2024
-
[13]
Mitigating Staleness in Asynchronous Pipeline Parallelism via Basis Rotation
Jung, H., Shin, S., and Lee, N. Mitigating staleness in asyn- chronous pipeline parallelism via basis rotation.arXiv preprint arXiv:2602.03515,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Kimi K2: Open Agentic Intelligence
KimiTeam. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Kovalev, D. Understanding gradient orthogonalization for deep learning via non-euclidean trust-region optimization. arXiv preprint arXiv:2503.12645,
-
[17]
MiniMax-01: Scaling Foundation Models with Lightning Attention
Li, A., Gong, B., Yang, B., Shan, B., Liu, C., Zhu, C., Zhang, C., Guo, C., Chen, D., Li, D., et al. Minimax-01: Scaling foundation models with lightning attention.arXiv preprint arXiv:2501.08313, 2025a. Li, H., Zheng, W., Wang, Q., Zhang, H., Wang, Z., Xuyang, S., Fan, Y ., Zhou, S., Zhang, X., and Jiang, D. Pre- dictable scale: Part i–optimal hyperparam...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Normuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491, 2025c
Li, Z., Liu, L., Liang, C., Chen, W., and Zhao, T. Normuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491, 2025c. Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.0443...
-
[19]
Maranjyan, A., Tyurin, A., and Richt ´arik, P. Ringmaster asgd: The first asynchronous sgd with optimal time com- plexity.arXiv preprint arXiv:2501.16168,
-
[20]
Merrill, W., Arora, S., Groeneveld, D., and Hajishirzi, H. Critical batch size revisited: A simple empirical approach to large-batch language model training.arXiv preprint arXiv:2505.23971,
-
[21]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
URL https:// arxiv.org/abs/1809.02789. Mishchenko, K., Bach, F., Even, M., and Woodworth, B. E. Asynchronous sgd beats minibatch sgd under arbitrary delays.Advances in Neural Information Processing Sys- tems, 35:420–433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Zero bubble pipeline parallelism.arXiv preprint arXiv:2401.10241,
Qi, P., Wan, X., Huang, G., and Lin, M. Zero bubble pipeline parallelism.arXiv preprint arXiv:2401.10241,
-
[23]
Qwen3-next: Towards ultimate training & inference efficiency, 2025.URL https://qwen.ai/blog?id=qwen3-next,
QwenTeam. Qwen3-next: Towards ultimate training & inference efficiency, 2025.URL https://qwen.ai/blog?id=qwen3-next,
2025
-
[24]
A., and Gordon, A
Roemmele, M., Bejan, C. A., and Gordon, A. S. Choice of plausible alternatives: An evaluation of common- sense causal reasoning. InLogical Formalizations of Commonsense Reasoning, Papers from the 2011 AAAI Spring Symposium, Technical Report SS-11-06, Stan- ford, California, USA, March 21-23,
2011
-
[25]
Ringmaster LMO: Asynchronous Linear Minimization Oracle Momentum Method
URL http://www.aaai.org/ocs/index.php/ SSS/SSS11/paper/view/2418. Sadiev, A., Maranjyan, A., Ilin, I., and Richt´arik, P. Ring- master lmo: Asynchronous linear minimization oracle momentum method.arXiv preprint arXiv:2605.18174,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
URL https://arxiv.org/abs/ 1907.10641. Seide, F., Fu, H., Droppo, J., Li, G., and Yu, D. 1-bit stochastic gradient descent and its application to data- parallel distributed training of speech dnns. pp. 1058– 1062, 09
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[27]
Semenov, A., Pagliardini, M., and Jaggi, M
doi: 10.21437/Interspeech.2014-274. Semenov, A., Pagliardini, M., and Jaggi, M. Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440,
-
[28]
GLU Variants Improve Transformer
Shazeer, N. Glu variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[29]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005,
Si, C., Zhang, D., and Shen, W. Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005,
- [31]
-
[32]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971, 2023a. Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S...
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
SOAP: Improving and Stabilizing Shampoo using Adam
Vyas, N., Morwani, D., Zhao, R., Kwun, M., Shapira, I., Brandfonbrener, D., Janson, L., and Kakade, S. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
URL https://arxiv.org/abs/2406.01574. Wen, K., Hall, D., Ma, T., and Liang, P. Fantastic pretrain- ing optimizers and where to find them.arXiv preprint arXiv:2509.02046,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Gated Delta Networks: Improving Mamba2 with Delta Rule
URL https:// openreview.net/forum?id=cw-EmNq5zfD. Yang, S., Kautz, J., and Hatamizadeh, A. Gated delta net- works: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Yuan, H., Liu, Y ., Wu, S., Zhou, X., and Gu, Q. Mars: Unleashing the power of variance reduction for training large models.arXiv preprint arXiv:2411.10438,
-
[37]
HellaSwag: Can a Machine Really Finish Your Sentence?
URL https://arxiv.org/abs/ 1905.07830. Zeng, A., Lv, X., Zheng, Q., Hou, Z., Chen, B., Xie, C., Wang, C., Yin, D., Zeng, H., Zhang, J., et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[38]
How does critical batch size scale in pre-training?arXiv preprint arXiv:2410.21676,
Zhang, H., Morwani, D., Vyas, N., Wu, J., Zou, D., Ghai, U., Foster, D., and Kakade, S. How does critical batch size scale in pre-training?arXiv preprint arXiv:2410.21676,
-
[39]
Deconstructing what makes a good optimizer for autoregressive language models
Zhao, R., Morwani, D., Brandfonbrener, D., Vyas, N., and Kakade, S. Deconstructing what makes a good optimizer for autoregressive language models. InInternational Conference on Learning Representations, volume 2025, pp. 2830–2850,
2025
-
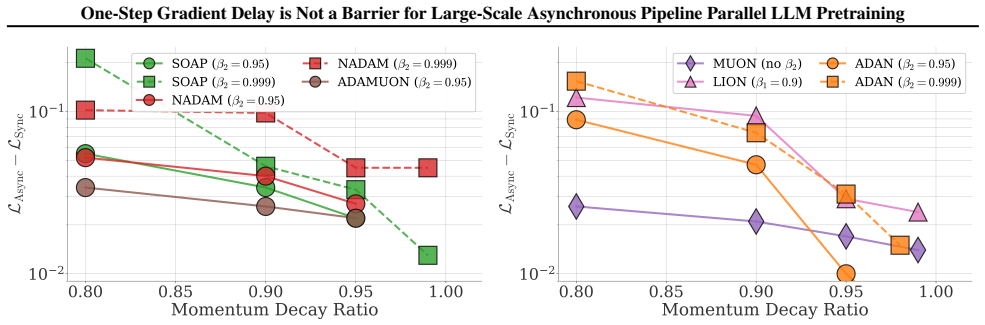
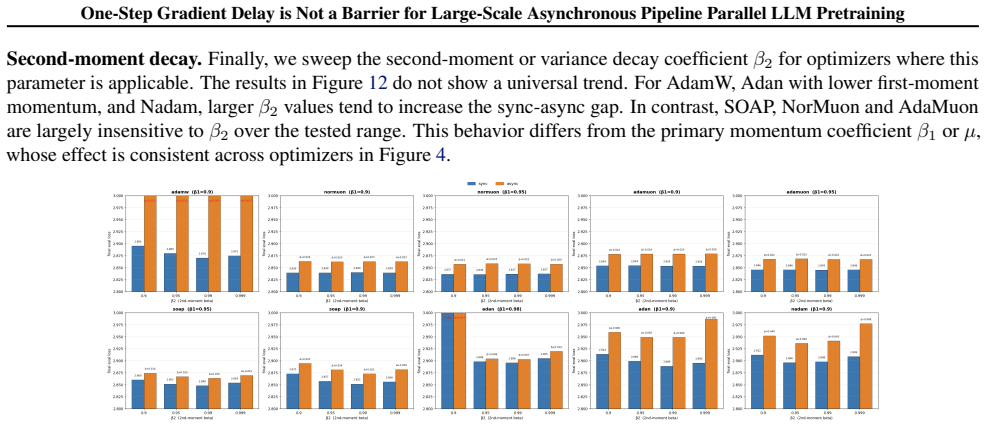
[40]
Unlike the primary momentum coefficient, β2 does not produce a consistent optimizer-independent trend
Figure 12.Effect of the second-moment or variance decay coefficient β2 on synchronous and one-step delayed training on the 135M model. Unlike the primary momentum coefficient, β2 does not produce a consistent optimizer-independent trend. Some bars are clipped for readability; annotations show the corresponding sync-async gap. Optimizer-specific knobs.We a...
2024
-
[41]
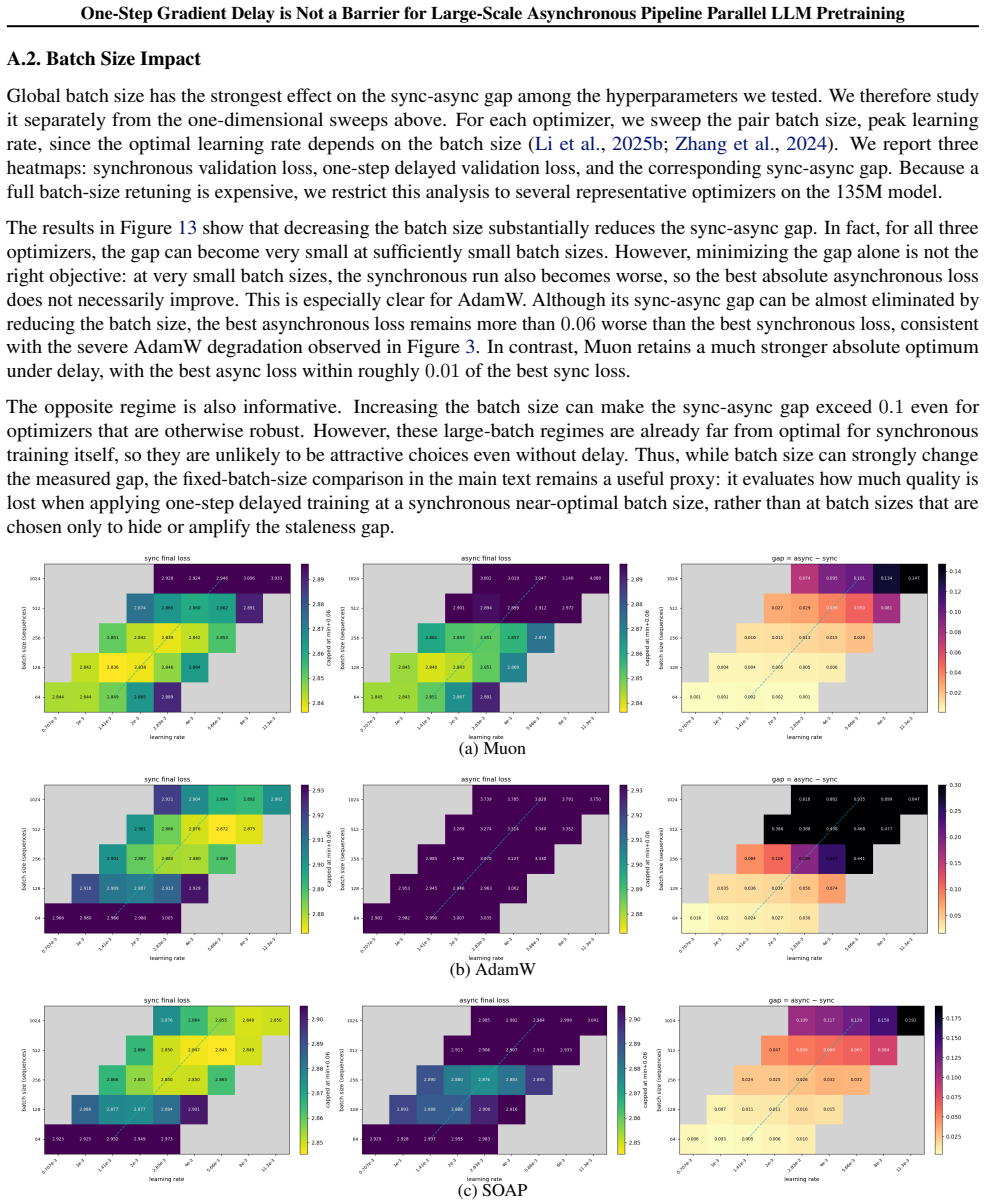
The opposite regime is also informative
In contrast, Muon retains a much stronger absolute optimum under delay, with the best async loss within roughly0.01of the best sync loss. The opposite regime is also informative. Increasing the batch size can make the sync-async gap exceed 0.1 even for optimizers that are otherwise robust. However, these large-batch regimes are already far from optimal fo...
2017
-
[42]
to physical and commonsense reasoning (Bisk et al., 2019; Sakaguchi et al., 2019; Zellers et al., 2019; Roemmele et al., 2011), as well as science question answering (Mihaylov et al., 2018; Clark et al., 2018). As shown in Table 4, the performance of the Async + EF model closely matches the synchronous baseline across these diverse tasks. The benchmarking...
-
[43]
and the WPipe schedule (Yang et al., 2022). B.1. SAPipe Weight Prediction Technique SAPipe (Chen et al.,
2022
-
[44]
provides an alternative way to organize asynchronous pipeline execution. We became aware of this schedule only after the main body of this work had largely been completed, and therefore treat it here as an additional practical consideration rather than as part of the main experimental study. WPipe is applicable in settings where multiple logical pipeline ...
2025
-
[45]
A detailed version can be found in Appendix D.1
to accommodate arbitrary gradient delaysτ≥1 , establishing delay-dependent bounds that explicitly capture how staleness propagates through the momentum accumulation process. A detailed version can be found in Appendix D.1. 28 One-Step Gradient Delay is Not a Barrier for Large-Scale Asynchronous Pipeline Parallel LLM Pretraining Assumption C.5(Star Convexi...
2025
-
[46]
Proof of Theorem C.6 In this proof, we are going to use Lemma D.5 from (Kovalev, 2025)
2Lη2 + (2τ+ 2)η∥∇f(x k+1)−m k+1∥∗ −η∥∇f(x k+1)∥∗ D.4. Proof of Theorem C.6 In this proof, we are going to use Lemma D.5 from (Kovalev, 2025). Lemma D.5.Under the conditions of Equation 6, letx∈ Xbe defined as follows: x=βx ∗ + (1−β)x k.(14) Then, the following inequalities hold: ∥x−(1−β)x k∥ ≤η,∥x−x k∥ ≤2η,∥x−x k+1∥ ≤2η,∥x k+1 −x k∥ ≤2η.(15) Additionally,...
2025
-
[47]
Unless explicitly stated otherwise, all training runs adhere to a Chinchilla compute-optimal token-to-parameter ratio of 20:1 (Hoffmann et al., 2022)
with parameter counts of 135M and 360M using the Fineweb-Edu dataset (Penedo et al., 2024). Unless explicitly stated otherwise, all training runs adhere to a Chinchilla compute-optimal token-to-parameter ratio of 20:1 (Hoffmann et al., 2022). E.1. Hyperparameters and Training Details To ensure a rigorous and fair comparison across different optimization a...
2024
-
[48]
(135M and 360M) using AdamW (Loshchilov & Hutter, 2017). We performed a grid search over learning rates and weight decay values, using a multiplicative step of 2 (uniform grid in log scale) for the learning rate and testing four distinct weight decay values. After verifying that a weight decay of 0.1 consistently yielded optimal results, we fixed this val...
2017
-
[49]
Optimal weight decay for Lion was 0.5 and learning rate was approximately 5e-4, which aligns with results from Wen et al
indicating that optimal hyperparameters for many modern optimizers tend to cluster in similar regions. Optimal weight decay for Lion was 0.5 and learning rate was approximately 5e-4, which aligns with results from Wen et al. (2025). Crucially, we always compared synchronous and asynchronous runs usingidenticalhyperparameter configurations. Batch Size Sele...
2025
-
[50]
Built upon the standard Llama architecture, these models incorporate Grouped Query Attention (Ainslie et al., 2023), RMSNorm (Zhang & Sennrich,
135M and 360M architectures as our dense baselines. Built upon the standard Llama architecture, these models incorporate Grouped Query Attention (Ainslie et al., 2023), RMSNorm (Zhang & Sennrich,
2023
-
[51]
Both models are trained with a context length of 1,024 tokens and a vocabulary size of 49,152
and SwiGLU (Shazeer, 2020). Both models are trained with a context length of 1,024 tokens and a vocabulary size of 49,152. Custom MoE Models.To rigorously validate our hypotheses at scale, we trained two custom MoE models. Both models utilize a tokenizer with a vocabulary size of 128k and support a context length of 8,192 tokens. • 2B MoE (0.5B Active):Th...
2020
-
[52]
The routing mechanism involves 64 experts with top-8 gating
It uses 16 query heads and 4 key-value heads. The routing mechanism involves 64 experts with top-8 gating. Despite the total parameter count of ≈2B, the active parameter count per token is approximately 500M. • 10B MoE (0.65B Active):This model employs a hybrid architecture inspired by QwenTeam (2025), incorporating 34 One-Step Gradient Delay is Not a Bar...
2025
-
[53]
It consists of 24 layers, configured such that every 4th layer uses Full Attention while the remaining layers utilize linear attention
layers. It consists of 24 layers, configured such that every 4th layer uses Full Attention while the remaining layers utilize linear attention. The model scales to 512 experts with top-10 gating and utilizes a Shared Expert and Shared Expert Trainable Weight mechanism. While the total parameter count is ≈10B, the highly sparse architecture maintains an ef...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.