ELEVATE: Designing Human-Centered GenAI Virtual Tutors for Scalable and Inclusive Education
Pith reviewed 2026-07-01 07:43 UTC · model grok-4.3
The pith
ELEVATE framework runs GenAI avatar tutors locally on consumer hardware via a three-stratum design for private scalable education.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
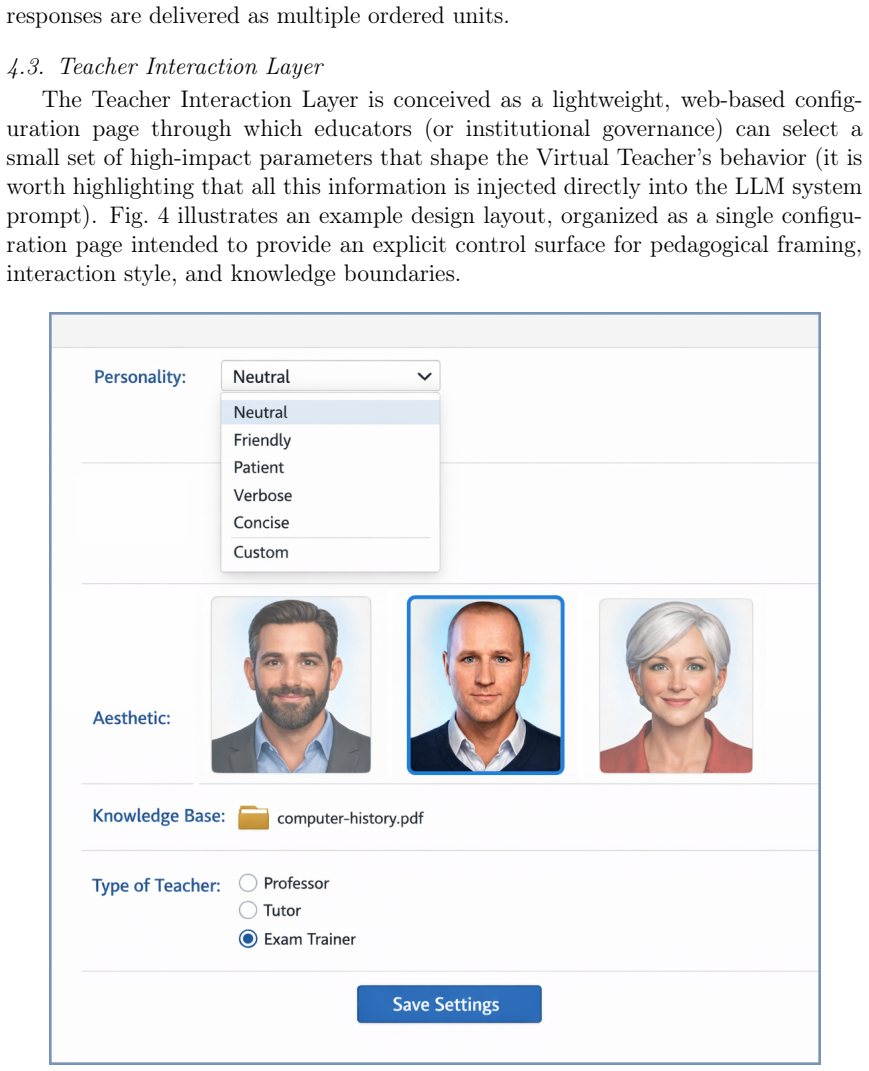
ELEVATE formalizes a three-stratum architecture that separates a student-facing virtual avatar interaction layer, a local GenAI execution and multimodal synthesis core, and a teacher-facing governance layer. The design supports LLM-driven dialogue integrated with embodied 3D avatars while running entirely on consumer-grade hardware, as shown by a deployed prototype in a real-world educational curriculum that maintains responsive interaction under realistic constraints.
What carries the argument
The three-stratum design separating student-facing avatar interaction, local GenAI core for dialogue and synthesis, and teacher governance layer.
If this is right
- Removes the need for continuous internet connectivity and recurring API costs in tutoring systems.
- Keeps student data local to reduce privacy and compliance risks.
- Gives teachers direct governance over the tutoring content and behavior.
- Extends interaction beyond text to include visual and embodied cues from 3D avatars.
- Supports deployment across varied school environments with different hardware levels.
Where Pith is reading between the lines
- Schools with limited budgets could adopt advanced tutoring without vendor contracts or data export.
- The layered separation might allow independent updates to the avatar interface or governance rules without touching the AI core.
- Similar local-first patterns could apply to other domains needing private multimodal AI agents.
- Wider testing across multiple curricula would be needed to confirm consistency of engagement outcomes.
Load-bearing premise
Local execution of GenAI on standard consumer hardware can produce responsive multimodal avatar interactions at classroom scale without cloud fallback or extra tuning.
What would settle it
Measured response times on typical school PCs or smartphones that exceed a few seconds for avatar dialogue turns, or classroom observations showing the system requires cloud support to function.
Figures



read the original abstract
The advent of Generative Artificial Intelligence (GenAI), and in particular Large Language Models (LLMs), is reshaping educational practice, while intensifying ethical debate about its adoption. To date, the dominant paradigm remains cloud-based and text-only chatbot: a centralized service that offers limited pedagogical control, weak transparency over knowledge sources, and non-trivial risks for privacy and regulatory compliance. This model also presumes continuous connectivity and recurring API costs, creating structural barriers for many institutions, reinforcing existing digital divides. At the same time, educational interaction with LLM can benefit from multimodal cues and embodied presence, requiring interfaces that move beyond text-only tutoring. In this work, we propose ELEVATE (Efficient LLM Education with Virtual Avatar Teaching Engine), a framework to develop efficient GenAI-driven avatar tutors governed by epistemic infrastructures. ELEVATE integrates LLM-driven dialogue with embodied 3D avatars for multimodal interaction and adopts a local-first execution model enabling deployment on consumer-grade hardware. The framework formalizes a three-stratum design that separates (i) a student-facing virtual avatar interaction layer, (ii) a local GenAI execution and multimodal synthesis core, and (iii) a teacher-facing governance layer. We implemented and evaluated a working prototype deployed in a real-world educational curriculum. The system runs on standard PCs and smartphones, and we provide system-level performance evidence to show responsive interaction under realistic hardware constraints. Finally, we discuss sociotechnical and pedagogical implications for responsible adoption, positioning ELEVATE as a scalable pathway for privacy-preserving and inclusive GenAI tutoring across heterogeneous school environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ELEVATE framework for GenAI-driven virtual avatar tutors. It proposes a three-stratum architecture separating a student-facing avatar interaction layer, a local GenAI execution and multimodal synthesis core, and a teacher-facing governance layer. The work claims to implement and evaluate a working prototype deployed in a real-world educational curriculum that runs on standard PCs and smartphones, providing system-level performance evidence for responsive multimodal interaction under realistic hardware constraints.
Significance. If the performance claims are substantiated with quantitative data, the framework could offer a meaningful contribution to educational AI by enabling privacy-preserving, low-cost, and scalable GenAI tutoring that reduces dependence on cloud services and mitigates digital divides in heterogeneous school environments.
major comments (1)
- [Abstract] Abstract: The central claim that 'we provide system-level performance evidence to show responsive interaction under realistic hardware constraints' is unsupported by any metrics, latency values, hardware specifications, baselines, or error analysis. This absence directly undermines evaluation of the local-first execution premise required for the stated privacy, cost, and scalability goals.
minor comments (1)
- [Abstract] The abstract is lengthy and could be tightened while preserving the core claims and contributions.
Simulated Author's Rebuttal
We thank the referee for highlighting this important issue with the abstract. We agree that the claim regarding system-level performance evidence requires explicit quantitative support to substantiate the local-first execution premise. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'we provide system-level performance evidence to show responsive interaction under realistic hardware constraints' is unsupported by any metrics, latency values, hardware specifications, baselines, or error analysis. This absence directly undermines evaluation of the local-first execution premise required for the stated privacy, cost, and scalability goals.
Authors: We acknowledge that the abstract asserts the provision of system-level performance evidence without including or referencing specific metrics, latency values, hardware specifications, baselines, or error analysis. The current manuscript text does not contain these quantitative details to support the claim. We will revise the abstract to remove or qualify the unsubstantiated claim (e.g., by stating that a working prototype was implemented and deployed, with performance evaluation to be detailed in a future section or removed if data is absent). If the full evaluation section contains relevant data, we will add explicit references, metrics, and analysis to the abstract and main text. This change directly addresses the concern about evaluating the local-first premise. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript is a systems-design and prototype paper with no equations, fitted parameters, or derivation chain. All load-bearing claims (local-first execution, multimodal avatar interaction, real-curriculum deployment, and consumer-hardware responsiveness) are presented as outcomes of an implemented system rather than quantities derived from prior self-citations or self-definitional constructs. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the supplied text; the architecture is described at the level of standard engineering choices whose validity is asserted by implementation evidence, not by internal reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Consumer-grade hardware can sustain real-time multimodal LLM interaction for tutoring sessions
- ad hoc to paper Separating student avatar, local core, and teacher governance layers produces better privacy and pedagogical control than monolithic cloud chatbots
Reference graph
Works this paper leans on
-
[1]
FirstName Alpher , title =
-
[2]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[3]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[4]
FirstName Alpher and FirstName Gamow , title =
-
[5]
Computer Vision -- ECCV 2022 , year =
2022
-
[6]
Virtual AI Teacher
Design and Development of "Virtual AI Teacher" System Based on NLP , author =. 2023 11th International Conference on Information and Education Technology (ICIET) , pages =. 2023 , organization =
2023
-
[7]
2024 1st International Conference on Trends in Engineering Systems and Technologies (ICTEST) , year =
LLM Based 3D Avatar Assistant , author =. 2024 1st International Conference on Trends in Engineering Systems and Technologies (ICTEST) , year =
2024
-
[8]
Seminars in Orthodontics , volume =
Role of virtual reality (VR), augmented reality (AR) and artificial intelligence (AI) in tertiary education and research of orthodontics: An insight , author =. Seminars in Orthodontics , volume =. 2021 , publisher =
2021
-
[9]
Ecological Informatics , volume =
Application of virtual reality teaching method and artificial intelligence technology in digital media art creation , author =. Ecological Informatics , volume =. 2021 , publisher =
2021
-
[10]
Frontiers in Virtual Reality , volume=
The combination of artificial intelligence and extended reality: A systematic review , author=. Frontiers in Virtual Reality , volume=. 2021 , publisher=
2021
-
[11]
arXiv preprint arXiv:2503.15489 , year=
PersonaAI: Leveraging Retrieval-Augmented Generation and Personalized Context for AI-Driven Digital Avatars , author=. arXiv preprint arXiv:2503.15489 , year=
-
[12]
International Journal of Human--Computer Interaction , pages=
The Effects of LLM-Empowered Chatbots and Avatar Guides on the Engagement, Experience, and Learning in Virtual Museums , author=. International Journal of Human--Computer Interaction , pages=. 2025 , publisher=
2025
-
[13]
Frontiers in Education , volume=
AI-based avatars are changing the way we learn and teach: benefits and challenges , author=. Frontiers in Education , volume=. 2024 , organization=
2024
-
[14]
arXiv preprint arXiv:2411.06490 , year=
Hermes: A Large Language Model Framework on the Journey to Autonomous Networks , author=. arXiv preprint arXiv:2411.06490 , year=
-
[15]
arXiv preprint arXiv:2401.08092 , year=
A survey of resource-efficient llm and multimodal foundation models , author=. arXiv preprint arXiv:2401.08092 , year=
-
[16]
SIGGRAPH Asia 2024 Educator's Forum , pages=
Embodied AI-guided interactive digital teachers for education , author=. SIGGRAPH Asia 2024 Educator's Forum , pages=
2024
-
[17]
2025 IEEE Conference Virtual Reality and 3D User Interfaces (VR) , pages=
Exploring large language model-driven agents for environment-aware spatial interactions and conversations in virtual reality role-play scenarios , author=. 2025 IEEE Conference Virtual Reality and 3D User Interfaces (VR) , pages=. 2025 , organization=
2025
-
[18]
The Journal of Cognitive Systems , volume=
Framework for a foreign language teaching software for children utilizing AR, voicebots and ChatGPT (large language models) , author=. The Journal of Cognitive Systems , volume=. 2022 , publisher=
2022
-
[19]
International conference on immersive learning , pages=
Immersive learning in history education: Exploring the capabilities of virtual avatars and Large Language Models , author=. International conference on immersive learning , pages=. 2024 , organization=
2024
-
[20]
arXiv preprint arXiv:2503.16457 , year=
Integrating Personality into Digital Humans: A Review of LLM-Driven Approaches for Virtual Reality , author=. arXiv preprint arXiv:2503.16457 , year=
-
[21]
Annual Review of Cybertherapy And Telemedicine 2024 , pages=
Virtual Standardized LLM-AI Patients for Clinical Practice , author=. Annual Review of Cybertherapy And Telemedicine 2024 , pages=
2024
-
[22]
2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW) , pages=
RAGatar: Enhancing LLM-driven Avatars with RAG for Knowledge-Adaptive Conversations in Virtual Reality , author=. 2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW) , pages=. 2025 , organization=
2025
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Ai-driven virtual teacher for enhanced educational efficiency: Leveraging large pretrain models for autonomous error analysis and correction , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
IEEE Transactions on Intelligent Vehicles , volume=
Integrating large language models and metaverse in autonomous racing: An education-oriented perspective , author=. IEEE Transactions on Intelligent Vehicles , volume=. 2024 , publisher=
2024
-
[25]
Procedia Computer Science , volume=
A Survey on RAG with LLMs , author=. Procedia Computer Science , volume=. 2024 , publisher=
2024
-
[26]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[27]
Authorea Preprints , year=
A survey on large language models: Applications, challenges, limitations, and practical usage , author=. Authorea Preprints , year=
-
[28]
Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
Building llm-based ai agents in social virtual reality , author=. Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
-
[29]
2022 16th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS) , pages=
MET-iquette: enabling virtual agents to have a social compliant behavior in the Metaverse , author=. 2022 16th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS) , pages=. 2022 , organization=
2022
-
[30]
IEEE Transactions on Visualization and Computer Graphics , year=
Frankenstein's Monster in the Metaverse: User Interaction With Customized Virtual Agents , author=. IEEE Transactions on Visualization and Computer Graphics , year=
-
[31]
arXiv preprint arXiv:2502.13133 , year =
AV-Flow: Transforming Text to Audio-Visual Human-like Interactions , author =. arXiv preprint arXiv:2502.13133 , year =
-
[32]
arXiv preprint arXiv:2506.02847 , year =
CLONE: Customizing LLMs for Efficient Latency-Aware Inference at the Edge , author =. arXiv preprint arXiv:2506.02847 , year =
-
[33]
Journal of Verification, Validation and Uncertainty Quantification , year =
Cascarano, Pasquale and Franchini, Giorgia and Porta, Federica and Sebastiani, Andrea , title =. Journal of Verification, Validation and Uncertainty Quantification , year =
-
[34]
Frontiers in Virtual Reality , volume=
Milo: an LLM-based virtual human open-source platform for extended reality , author=. Frontiers in Virtual Reality , volume=. 2025 , publisher=
2025
-
[35]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Exploring LLM-Powered Role and Action-Switching Pedagogical Agents for History Education in Virtual Reality , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[36]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Exploring the Impact of Avatar Representations in AI Chatbot Tutors on Learning Experiences , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[37]
26th International Symposium on Temporal Representation and Reasoning (TIME 2019) , pages =
Loli Piccolomini, Elena and Gandolfi, Stefano and Poluzzi, Luca and Tavasci, Luca and Cascarano, Pasquale and Pascucci, Andrea , title =. 26th International Symposium on Temporal Representation and Reasoning (TIME 2019) , pages =. 2019 , editor =. doi:10.4230/LIPIcs.TIME.2019.10 , URL =
-
[38]
2023 , institution =
Miao, Fengchun and Holmes, Wayne , title =. 2023 , institution =
2023
-
[39]
2025 , note =
Large Language Model (LLM) Market Size, Forecast & Trends , organization =. 2025 , note =
2025
-
[40]
2024 , note =
Enterprise LLM Market Size & Share Report , organization =. 2024 , note =
2024
-
[41]
2024 , note =
Asia Pacific Enterprise LLM Market Report , organization =. 2024 , note =
2024
-
[42]
Large language models for education: A survey and outlook , author=. arXiv preprint arXiv:2403.18105 , year=
-
[43]
arXiv preprint arXiv:2405.13001 , year=
Large language models for education: A survey , author=. arXiv preprint arXiv:2405.13001 , year=
-
[44]
British Journal of Educational Technology , volume=
Practical and ethical challenges of large language models in education: A systematic scoping review , author=. British Journal of Educational Technology , volume=. 2024 , publisher=
2024
-
[45]
Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 (Artificial Intelligence ...
2024
-
[46]
Proceedings of the 22nd international ACM SIGACCESS conference on computers and accessibility , pages=
Teaching ASL signs using signing avatars and immersive learning in virtual reality , author=. Proceedings of the 22nd international ACM SIGACCESS conference on computers and accessibility , pages=
-
[47]
Bioengineering , volume=
Measuring the Impact of Large Language Models on Academic Success and Quality of Life Among Students with Visual Disability: An Assistive Technology Perspective , author=. Bioengineering , volume=. 2025 , publisher=
2025
-
[48]
Proceedings of the Winter Conference on Applications of Computer Vision , pages=
Multi-Modal Large Language Model driven Augmented Reality Situated Visualization: the Case of Wine Recognition , author=. Proceedings of the Winter Conference on Applications of Computer Vision , pages=
-
[49]
2024 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct) , pages=
XRAI-Ethics: Towards a Robust Ethical Analysis Framework for Extended Artificial Intelligence , author=. 2024 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct) , pages=. 2024 , organization=
2024
-
[50]
Proceedings of the 2024 the 12th International Conference on Information Technology (ICIT) , pages=
Integrating Large Language Models with Digital Avatars: A Case Study of the Educational Domain , author=. Proceedings of the 2024 the 12th International Conference on Information Technology (ICIT) , pages=
2024
-
[51]
A Modular and Efficient Framework for the Development of Large Language Model-Based Virtual Humans: An Educational Scenario
Giordano, Michele and Berardini, Daniele and Frontoni, Emanuele and Zingaretti, Primo and Stacchio, Lorenzo. A Modular and Efficient Framework for the Development of Large Language Model-Based Virtual Humans: An Educational Scenario. Image Analysis and Processing - ICIAP 2025 Workshops. 2026
2025
-
[52]
arXiv preprint arXiv:2411.18708 , year=
Embracing AI in education: Understanding the surge in large language model use by secondary students , author=. arXiv preprint arXiv:2411.18708 , year=
-
[53]
Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue , pages=
An open-domain avatar chatbot by exploiting a large language model , author=. Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue , pages=
-
[54]
arXiv preprint arXiv:2501.00168 , year=
Takeaways from applying llm capabilities to multiple conversational avatars in a vr pilot study , author=. arXiv preprint arXiv:2501.00168 , year=
-
[55]
2024 International Conference on IoT Based Control Networks and Intelligent Systems (ICICNIS) , pages=
Llmedge: A novel framework for localized llm inferencing at resource constrained edge , author=. 2024 International Conference on IoT Based Control Networks and Intelligent Systems (ICICNIS) , pages=. 2024 , organization=
2024
-
[56]
2024 , eprint=
Hermes 3 Technical Report , author=. 2024 , eprint=
2024
-
[57]
International Journal of Human--Computer Interaction , pages=
PerVRML: ChatGPT-Driven Personalized VR Environments for Machine Learning Education , author=. International Journal of Human--Computer Interaction , pages=. 2025 , publisher=
2025
-
[58]
IEEE Transactions on Education , year=
An llm-driven chatbot in higher education for databases and information systems , author=. IEEE Transactions on Education , year=
-
[59]
Information , volume=
An Architecture for Intelligent Tutoring in Virtual Reality: Integrating LLMs and Multimodal Interaction for Immersive Learning , author=. Information , volume=. 2025 , publisher=
2025
-
[60]
2023 , publisher=
Computer: A history of the information machine , author=. 2023 , publisher=
2023
-
[61]
AI & SOCIETY , pages=
Do GenAI avatars open new responsibility gaps? , author=. AI & SOCIETY , pages=. 2025 , publisher=
2025
-
[62]
Advanced Intelligent Systems , volume=
Large language model-based chatbots in higher education , author=. Advanced Intelligent Systems , volume=. 2025 , publisher=
2025
-
[63]
Computers and Education: Artificial Intelligence , volume=
Systematically visualizing ChatGPT used in higher education: Publication trend, disciplinary domains, research themes, adoption and acceptance , author=. Computers and Education: Artificial Intelligence , volume=. 2025 , publisher=
2025
-
[64]
Computers and Education: Artificial Intelligence , volume=
Large language models meet user interfaces: The case of provisioning feedback , author=. Computers and Education: Artificial Intelligence , volume=. 2024 , publisher=
2024
-
[65]
Computers and Education: Artificial Intelligence , pages=
A systematic literature review of generative artificial intelligence (GenAI) literacy in schools , author=. Computers and Education: Artificial Intelligence , pages=. 2025 , publisher=
2025
-
[66]
Computers and Education: Artificial Intelligence , volume=
AI literacy and its implications for prompt engineering strategies , author=. Computers and Education: Artificial Intelligence , volume=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.