A Single Rewrite Suffices: Empirical Lessons from Production Skill Description Optimization
Pith reviewed 2026-07-01 02:28 UTC · model grok-4.3
The pith
A single LLM rewrite using error cases matches manual skill description tuning at 32 times less effort.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
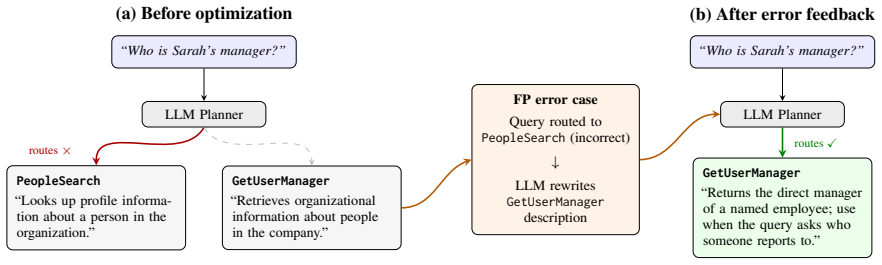
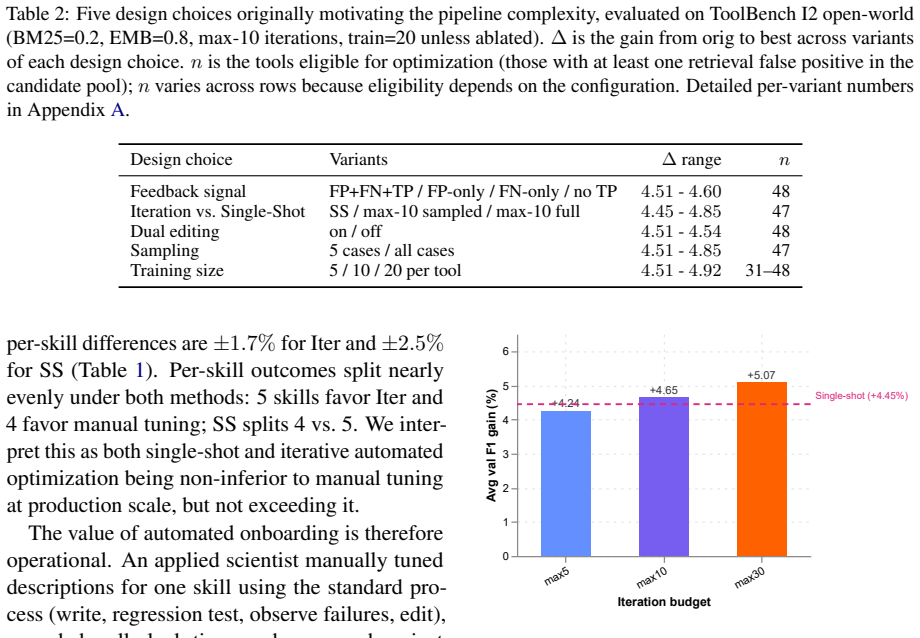
The pipeline produces descriptions averaging 79.2% F1, matching manually tuned descriptions at 79.4% F1 (average per-skill difference -0.20%, within the 0.78% multi-seed noise floor), while reducing per-skill engineering effort from 120 minutes to 3.8 minutes (32 times speedup). Systematic ablation reveals that a single LLM rewrite using any available false-positive and false-negative cases captures most of the available improvement. Other design choices tested (iteration budget, feedback signal composition, dual editing of confused pairs, and training set size) each affect final F1 by less than 0.5%.
What carries the argument
The single LLM rewrite step that edits skill descriptions using false-positive and false-negative cases from regression tests.
If this is right
- A single rewrite using error cases captures most available improvement in description quality.
- Iteration budget, feedback composition, dual editing, and training set size each shift final F1 by less than 0.5 percent.
- Description optimization resolves collisions from overlapping text but cannot fix cases where skill scopes genuinely overlap.
- A large train-validation F1 gap flags genuine scope overlap and calls for architectural rather than text changes.
Where Pith is reading between the lines
- The same single-rewrite pattern may reduce manual work in other LLM routing or tool-selection systems that rely on natural language descriptions.
- Collecting a representative regression set may matter more than building multi-step optimization loops.
- Agents with dozens of skills could maintain routing accuracy without linear growth in tuning labor if the regression set stays current.
Load-bearing premise
The 372 regression cases represent the full query distribution the agent will encounter and the LLM can rewrite descriptions from those errors without creating new routing problems.
What would settle it
Measure F1 on a new query set drawn from production traffic outside the original 372 cases and check whether the automated descriptions stay within 0.78 percent of the manually tuned F1 or drop below it.
Figures
read the original abstract
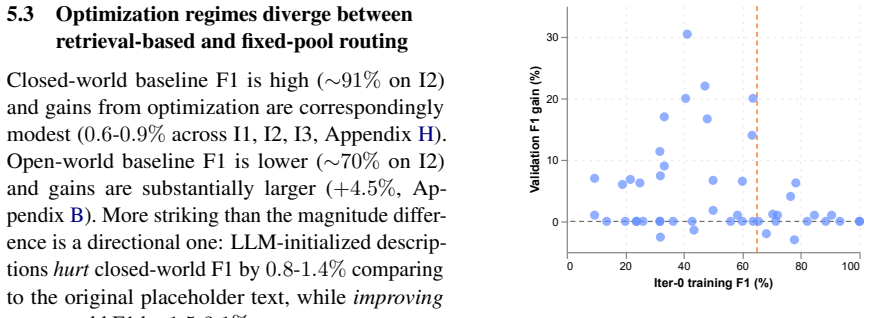
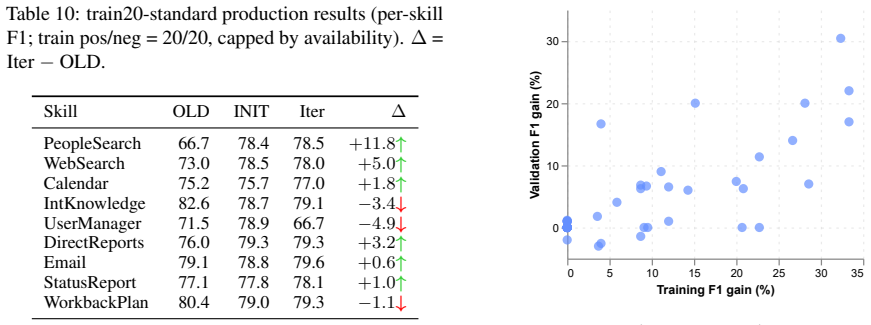
Enterprise AI agents route user queries to specialized skills by matching queries against natural language skill descriptions. When two skills share overlapping descriptions, the routing LLM misroutes queries, a failure we term skill collision. As agents scale to dozens of skills, manually tuning descriptions to maintain routing accuracy becomes a significant engineering bottleneck. We deploy an automated description optimization pipeline on a production enterprise group chat agent (9 skills, 372 regression cases). The pipeline produces descriptions averaging 79.2% F1, matching manually tuned descriptions at 79.4% F1 (average per-skill difference -0.20%, within the 0.78% multi-seed noise floor), while reducing per-skill engineering effort from 120 minutes to 3.8 minutes (32 times speedup). We then examine which pipeline components actually drive this match. Systematic ablation on both the production system and ToolBench (16k tools) reveals that a single LLM rewrite using any available false-positive and false-negative cases captures most of the available improvement. Other design choices we tested (iteration budget, feedback signal composition, dual editing of confused pairs, and training set size) each affect final F1 by less than 0.5%. Description optimization addresses skill collisions caused by overlapping descriptions but cannot resolve cases where two skills intended scopes genuinely overlap. We identify a diagnostic (a large train-validation F1 gap) that flags the latter cases for architectural rather than text-level intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an automated pipeline for optimizing skill descriptions in enterprise AI agents (to reduce routing collisions) achieves F1 scores matching manual tuning (79.2% vs 79.4%) on a production system with 9 skills and 372 regression cases, while cutting per-skill effort from 120 to 3.8 minutes. Ablations on the production data and ToolBench (16k tools) show that a single LLM rewrite using FP/FN cases captures nearly all gains; iteration, feedback composition, dual editing, and training size each affect F1 by <0.5%. A diagnostic (large train-val F1 gap) is proposed to flag cases needing architectural fixes rather than text edits.
Significance. If the equivalence holds out-of-sample, the work provides strong empirical evidence that description optimization is largely solvable with one rewrite step, directly addressing an engineering bottleneck in scaling multi-skill agents. The production deployment plus large-scale ToolBench ablations, combined with the identification of when text-level fixes are insufficient, offer practical, falsifiable lessons for agent routing systems.
major comments (2)
- [Abstract] Abstract and evaluation description: the reported F1 equivalence (79.2% automated vs 79.4% manual) is measured on the same 372 regression cases used to extract the FP/FN cases fed to the LLM rewrite. No held-out query set is described, so the near-zero difference is consistent with in-sample fitting rather than generalization to the production query distribution. This directly undermines the central claim of matching manual performance and the 32x speedup conclusion.
- [Ablations] Ablation section (implied by 'systematic ablation on both the production system and ToolBench'): the claim that 'other design choices each affect final F1 by less than 0.5%' and that 'a single rewrite captures most of the available improvement' cannot be assessed for robustness without confirmation that all ablations use held-out evaluation; if performed in-sample, the small deltas are expected and do not support the 'single rewrite suffices' lesson.
minor comments (2)
- [Abstract] The multi-seed noise floor (0.78%) is cited to contextualize the -0.20% difference, but the paper should explicitly state how many seeds were used and whether the noise floor was computed on the same 372 cases or a separate validation split.
- Clarify the exact definition of 'regression cases' and how FP/FN are extracted (e.g., threshold on routing scores) to allow replication.
Simulated Author's Rebuttal
We thank the referee for the careful review and the focus on evaluation methodology. We address each major comment below, agree that the production evaluation uses the regression cases, and will revise the manuscript to make the evaluation setup and its implications explicit.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the reported F1 equivalence (79.2% automated vs 79.4% manual) is measured on the same 372 regression cases used to extract the FP/FN cases fed to the LLM rewrite. No held-out query set is described, so the near-zero difference is consistent with in-sample fitting rather than generalization to the production query distribution. This directly undermines the central claim of matching manual performance and the 32x speedup conclusion.
Authors: The 372 regression cases are the observed production queries that exhibited skill collisions. Both the automated pipeline and the manual tuning process use these same cases to identify issues and measure improvement, as they represent the critical failures that must be resolved in the deployed system. The reported equivalence therefore shows that the automated method achieves performance comparable to manual optimization on the relevant production cases, while reducing effort from 120 to 3.8 minutes per skill. We do not claim out-of-sample generalization to entirely new query distributions; the engineering value lies in efficiently addressing known collisions. We will revise the abstract and evaluation sections to state explicitly that performance is measured on the regression cases used to derive FP/FN examples and to discuss this as a limitation. revision: yes
-
Referee: [Ablations] Ablation section (implied by 'systematic ablation on both the production system and ToolBench'): the claim that 'other design choices each affect final F1 by less than 0.5%' and that 'a single rewrite captures most of the available improvement' cannot be assessed for robustness without confirmation that all ablations use held-out evaluation; if performed in-sample, the small deltas are expected and do not support the 'single rewrite suffices' lesson.
Authors: Ablations on the production system are performed on the 372 regression cases. Ablations on ToolBench use the benchmark's standard held-out test splits (we will add explicit citations to the splits in the revised text). Even under in-sample evaluation on production data, the observed deltas remain below 0.5% for iteration, feedback composition, dual editing, and training size, indicating that these components add little beyond the single rewrite step. This pattern holds on the held-out ToolBench splits as well. We will revise the ablation section to specify the evaluation data for each experiment and note the in-sample character of the production results. revision: yes
Circularity Check
No significant circularity in empirical ablation results
full rationale
The paper reports direct empirical measurements of an LLM-based rewrite pipeline on 372 production regression cases and separate ToolBench ablations. No derivation chain, equations, fitted parameters renamed as predictions, or self-citations are present in the provided text. Performance equivalence (79.2% vs 79.4% F1) is a measured outcome of applying the pipeline, not a quantity forced to match its inputs by construction. The use of the same cases for error extraction and final F1 reporting is a methodological choice but does not reduce any claimed result to a tautology under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The LLM rewrite using false-positive and false-negative cases can improve descriptions without additional iterations.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Dan Gusfield , title =. 1997
1997
-
[5]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[6]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
-
[7]
Ebersole , journal=
Jorge Nathan Matias and Kevin Munger and Marianne Aubin Le Quere and Charles R. Ebersole , journal=. The Upworthy Research Archive, a time series of 32,487 experiments in. 2021 , volume=
2021
-
[8]
2023 , journal=tacl, url=
Lost in the Middle: How Language Models Use Long Contexts , author=. 2023 , journal=tacl, url=
2023
-
[9]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=icml, year=. Scalable training of
-
[10]
2019 , url=
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , journal=. 2019 , url=
2019
-
[11]
ArXiv , year=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. ArXiv , year=
-
[12]
2023 , eprint=
Towards Reasoning in Large Language Models: A Survey , author=. 2023 , eprint=
2023
-
[13]
2023 , eprint=
Augmented Language Models: a Survey , author=. 2023 , eprint=
2023
-
[14]
Andreas, Jacob and Klein, Dan and Levine, Sergey , year =. Learning with. doi:10.48550/arXiv.1711.00482 , abstract =. arXiv , keywords =:1711.00482 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.00482
-
[15]
Atanasova, Pepa and Simonsen, Jakob Grue and Lioma, Christina and Augenstein, Isabelle , year =. Generating. Proceedings of the 58th. doi:10.18653/v1/2020.acl-main.656 , abstract =
-
[16]
Beltagy, Iz and Cohan, Arman and Logan IV, Robert and Min, Sewon and Singh, Sameer , year =. Zero- and. Proceedings of the 60th. doi:10.18653/v1/2022.acl-tutorials.6 , file =
-
[17]
2021 , journal =
Beyond the. 2021 , journal =
2021
-
[18]
Language Models Are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[19]
PaLM: Scaling Language Modeling with Pathways
Chowdhery, Aakanksha and Narang, Sharan and Devlin, Jacob and Bosma, Maarten and Mishra, Gaurav and Roberts, Adam and Barham, Paul and Chung, Hyung Won and Sutton, Charles and Gehrmann, Sebastian and Schuh, Parker and Shi, Kensen and Tsvyashchenko, Sasha and Maynez, Joshua and Rao, Abhishek and Barnes, Parker and Tay, Yi and Shazeer, Noam and Prabhakaran,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.02311 2022
-
[20]
Semi-Supervised Sequence Modeling with Cross-View Training
Clark, Kevin and Luong, Minh-Thang and Manning, Christopher D. and Le, Quoc V. , year =. Semi-. doi:10.48550/arXiv.1809.08370 , abstract =. arXiv , keywords =:1809.08370 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1809.08370
-
[21]
Gao, Leo , year =. On the. EleutherAI Blog , abstract =
-
[22]
Training Classifiers with Natural Language Explanations
Hancock, Braden and Varma, Paroma and Wang, Stephanie and Bringmann, Martin and Liang, Percy and R. Training. 2018 , month = aug, number =. doi:10.48550/arXiv.1805.03818 , abstract =. arXiv , keywords =:1805.03818 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.03818 2018
-
[23]
Hase, Peter and Zhang, Shiyue and Xie, Harry and Bansal, Mohit , year =. Leakage-. Findings of the. doi:10.18653/v1/2020.findings-emnlp.390 , abstract =
-
[24]
Hendricks, Lisa Anne and Akata, Zeynep and Rohrbach, Marcus and Donahue, Jeff and Schiele, Bernt and Darrell, Trevor , editor =. Generating. Computer. 2016 , series =. doi:10.1007/978-3-319-46493-0_1 , abstract =
-
[25]
Hendricks, Lisa Anne and Hu, Ronghang and Darrell, Trevor and Akata, Zeynep , year =. Grounding. doi:10.48550/arXiv.1807.09685 , abstract =. arXiv , keywords =:1807.09685 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.09685
-
[26]
Hernandez, Evan and Schwettmann, Sarah and Bau, David and Bagashvili, Teona and Torralba, Antonio and Andreas, Jacob , year =. Natural. doi:10.48550/arXiv.2201.11114 , abstract =. arXiv , keywords =:2201.11114 , eprinttype =
-
[27]
and Araki, Jun and Neubig, Graham , year =
Jiang, Zhengbao and Xu, Frank F. and Araki, Jun and Neubig, Graham , year =. How. Transactions of the Association for Computational Linguistics , volume =. doi:10.1162/tacl_a_00324 , abstract =
-
[28]
Can Language Models Learn from Explanations in Context? , author =. 2022 , month = may, number =. arXiv , keywords =:2204.02329 , eprinttype =
-
[29]
Lampinen, Andrew K. and Roy, Nicholas A. and Dasgupta, Ishita and Chan, Stephanie C. Y. and Tam, Allison C. and McClelland, James L. and Yan, Chen and Santoro, Adam and Rabinowitz, Neil C. and Wang, Jane X. and Hill, Felix , year =. Tell Me Why!. doi:10.48550/arXiv.2112.03753 , abstract =. arXiv , keywords =:2112.03753 , eprinttype =
-
[30]
How Many Data Points Is a Prompt Worth? , booktitle =
Le Scao, Teven and Rush, Alexander , year =. How Many Data Points Is a Prompt Worth? , booktitle =. doi:10.18653/v1/2021.naacl-main.208 , abstract =
-
[31]
Lester, Brian and. The. 2021 , month = sep, journal =. arXiv , keywords =:2104.08691 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Ling, Wang and Yogatama, Dani and Dyer, Chris and Blunsom, Phil , year =. Program. Proceedings of the 55th. doi:10.18653/v1/P17-1015 , abstract =
-
[33]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , year =. arXiv , keywords =:1907.11692 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[34]
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus , year =. Fantastically. Proceedings of the 60th. doi:10.18653/v1/2022.acl-long.556 , abstract =
-
[35]
Marasovi. Few-. 2022 , month = apr, number =. doi:10.48550/arXiv.2111.08284 , abstract =. arXiv , keywords =:2111.08284 , eprinttype =
-
[36]
Explanation in Artificial Intelligence:
Miller, Tim , year =. Explanation in Artificial Intelligence:. Artificial Intelligence , volume =. doi:10.1016/j.artint.2018.07.007 , abstract =
-
[37]
Mishra, Swaroop and Khashabi, Daniel and Baral, Chitta and Hajishirzi, Hannaneh , year =. Cross-. doi:10.48550/arXiv.2104.08773 , abstract =. arXiv , keywords =:2104.08773 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.08773
-
[38]
and Goodfellow, Ian J
Miyato, Takeru and Dai, Andrew M. and Goodfellow, Ian J. , year =. Adversarial Training Methods for Semi-Supervised Text Classification , booktitle =
-
[39]
doi:10.48550/arXiv.2004.14546 , abstract =
Narang, Sharan and Raffel, Colin and Lee, Katherine and Roberts, Adam and Fiedel, Noah and Malkan, Karishma , year =. doi:10.48550/arXiv.2004.14546 , abstract =. arXiv , keywords =:2004.14546 , eprinttype =
-
[40]
Training language models to follow instructions with human feedback
Training Language Models to Follow Instructions with Human Feedback , author =. 2022 , month = mar, number =. doi:10.48550/arXiv.2203.02155 , abstract =. arXiv , keywords =:2203.02155 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155 2022
-
[41]
Multimodal Explanations: Justifying Decisions and Pointing to the Evidence
Park, Dong Huk and Hendricks, Lisa Anne and Akata, Zeynep and Rohrbach, Anna and Schiele, Bernt and Darrell, Trevor and Rohrbach, Marcus , year =. Multimodal. doi:10.48550/arXiv.1802.08129 , abstract =. arXiv , keywords =:1802.08129 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.08129
-
[42]
Petroni, Fabio and Rockt. Language. Proceedings of the 2019. 2019 , month = nov, pages =. doi:10.18653/v1/D19-1250 , abstract =
-
[43]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[44]
Rae, Jack W. and Borgeaud, Sebastian and Cai, Trevor and Millican, Katie and Hoffmann, Jordan and Song, Francis and Aslanides, John and Henderson, Sarah and Ring, Roman and Young, Susannah and Rutherford, Eliza and Hennigan, Tom and Menick, Jacob and Cassirer, Albin and Powell, Richard and van den Driessche, George and Hendricks, Lisa Anne and Rauh, Marib...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Rajani, Nazneen Fatema and McCann, Bryan and Xiong, Caiming and Socher, Richard , year =. Explain. doi:10.48550/arXiv.1906.02361 , abstract =. arXiv , keywords =:1906.02361 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.02361 1906
-
[46]
Trinh, Trieu H. and Le, Quoc V. , year =. A. doi:10.48550/arXiv.1806.02847 , abstract =. arXiv , keywords =:1806.02847 , eprinttype =
-
[47]
Wang, Xuezhi and Wei, Jason and Schuurmans, Dale and Le, Quoc and Chi, Ed and Zhou, Denny , year =. Rationale-. doi:10.48550/arXiv.2207.00747 , abstract =. arXiv , keywords =:2207.00747 , eprinttype =
-
[48]
Emergent Abilities of Large Language Models
Wei, Jason and Tay, Yi and Bommasani, Rishi and Raffel, Colin and Zoph, Barret and Borgeaud, Sebastian and Yogatama, Dani and Bosma, Maarten and Zhou, Denny and Metzler, Donald and Chi, Ed H. and Hashimoto, Tatsunori and Vinyals, Oriol and Liang, Percy and Dean, Jeff and Fedus, William , year =. Emergent. doi:10.48550/arXiv.2206.07682 , abstract =. arXiv ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2206.07682
- [49]
- [50]
-
[51]
Xie, Qizhe and Dai, Zihang and Hovy, Eduard and Luong, Minh-Thang and Le, Quoc V. , year =. Unsupervised. doi:10.48550/arXiv.1904.12848 , abstract =. arXiv , keywords =:1904.12848 , eprinttype =
-
[52]
Modeling
Zaidan, Omar and Eisner, Jason , year =. Modeling. Proceedings of the 2008
2008
-
[53]
Zellers, Rowan and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , year =. From. doi:10.48550/arXiv.1811.10830 , abstract =. arXiv , keywords =:1811.10830 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1811.10830
-
[54]
Jiacheng Liu and Alisa Liu and Ximing Lu and Sean Welleck and Peter West and Ronan Le Bras and Yejin Choi and Hannaneh Hajishirzi , title =. CoRR , volume =. 2021 , url =. 2110.08387 , timestamp =
-
[55]
arXiv preprint arXiv:2012.15723 , year=
Making pre-trained language models better few-shot learners , author=. arXiv preprint arXiv:2012.15723 , year=
-
[56]
arXiv preprint arXiv:2001.07676 , year=
Exploiting cloze questions for few shot text classification and natural language inference , author=. arXiv preprint arXiv:2001.07676 , year=
-
[57]
arXiv preprint arXiv:2102.12060 , year=
Teach me to explain: A review of datasets for explainable nlp , author=. arXiv preprint arXiv:2102.12060 , year=
-
[58]
Advances in Neural Information Processing Systems , volume=
e-snli: Natural language inference with natural language explanations , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Zhou, Yangqiaoyu and Tan, Chenhao. Investigating the Effect of Natural Language Explanations on Out-of-Distribution Generalization in Few-shot NLI. Proceedings of the Second Workshop on Insights from Negative Results in NLP. 2021. doi:10.18653/v1/2021.insights-1.17
-
[60]
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference
Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference , author=. arXiv preprint arXiv:1902.01007 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[61]
A Systematic Comparison of Smoothing Techniques for Sentence-Level BLEU
Chen, Boxing and Cherry, Colin. A Systematic Comparison of Smoothing Techniques for Sentence-Level BLEU. Proceedings of the Ninth Workshop on Statistical Machine Translation. 2014. doi:10.3115/v1/W14-3346
-
[62]
arXiv preprint arXiv:2006.06264 , year=
Tangled up in BLEU: Reevaluating the evaluation of automatic machine translation evaluation metrics , author=. arXiv preprint arXiv:2006.06264 , year=
-
[63]
A Structured Review of the Validity of BLEU
Reiter, Ehud. A Structured Review of the Validity of BLEU. Computational Linguistics. 2018. doi:10.1162/coli_a_00322
-
[64]
arXiv preprint arXiv:2010.12762 , year=
Measuring association between labels and free-text rationales , author=. arXiv preprint arXiv:2010.12762 , year=
-
[65]
Hase, Peter and Bansal, Mohit. When Can Models Learn From Explanations? A Formal Framework for Understanding the Roles of Explanation Data. Proceedings of the First Workshop on Learning with Natural Language Supervision. 2022. doi:10.18653/v1/2022.lnls-1.4
-
[66]
Advances in Neural Information Processing Systems , year=
The unreliability of explanations in few-shot prompting for textual reasoning , author=. Advances in Neural Information Processing Systems , year=
-
[67]
2022 , booktitle =
Chenhao Tan , title =. 2022 , booktitle =
2022
-
[68]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Show your work: Scratchpads for intermediate computation with language models , author=. arXiv preprint arXiv:2112.00114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
arXiv preprint arXiv:2209.15189 , year=
Learning by Distilling Context , author=. arXiv preprint arXiv:2209.15189 , year=
-
[70]
arXiv preprint arXiv:2206.11349 , year=
Prompt Injection: Parameterization of Fixed Inputs , author=. arXiv preprint arXiv:2206.11349 , year=
-
[71]
A General Language Assistant as a Laboratory for Alignment
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
2022 , journal=
In-context Learning and Induction Heads , author=. 2022 , journal=
2022
-
[73]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
FitNets: Hints for Thin Deep Nets
Fitnets: Hints for thin deep nets , author=. arXiv preprint arXiv:1412.6550 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Improving multi-task deep neural networks via knowledge distillation for natural language understanding , author=. arXiv preprint arXiv:1904.09482 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[76]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Self-training with noisy student improves imagenet classification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[77]
Chowdhery, Aakanksha and Narang, Sharan and Devlin, Jacob and Bosma, Maarten and Mishra, Gaurav and Roberts, Adam and Barham, Paul and Chung, Hyung Won and Sutton, Charles and Gehrmann, Sebastian and Schuh, Parker and Shi, Kensen and Tsvyashchenko, Sashank and Maynez, Joshua and Rao, Abhishek and Barnes, Parker and Tay, Yi and Shazeer, Noam and Prabhakara...
2024
-
[78]
arXiv preprint arXiv:2202.04538 , year=
Generating training data with language models: Towards zero-shot language understanding , author=. arXiv preprint arXiv:2202.04538 , year=
-
[79]
arXiv preprint arXiv:2203.14465 , year=
Star: Bootstrapping reasoning with reasoning , author=. arXiv preprint arXiv:2203.14465 , year=
-
[80]
arXiv preprint arXiv:2101.06804 , year=
What Makes Good In-Context Examples for GPT- 3 ? , author=. arXiv preprint arXiv:2101.06804 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.