AI-Generated PowerShell Malware: An Experimental Framework and Dataset
Pith reviewed 2026-07-01 01:32 UTC · model grok-4.3
The pith
LLM-generated PowerShell malware triggers the same malicious OS events as real malware in most cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
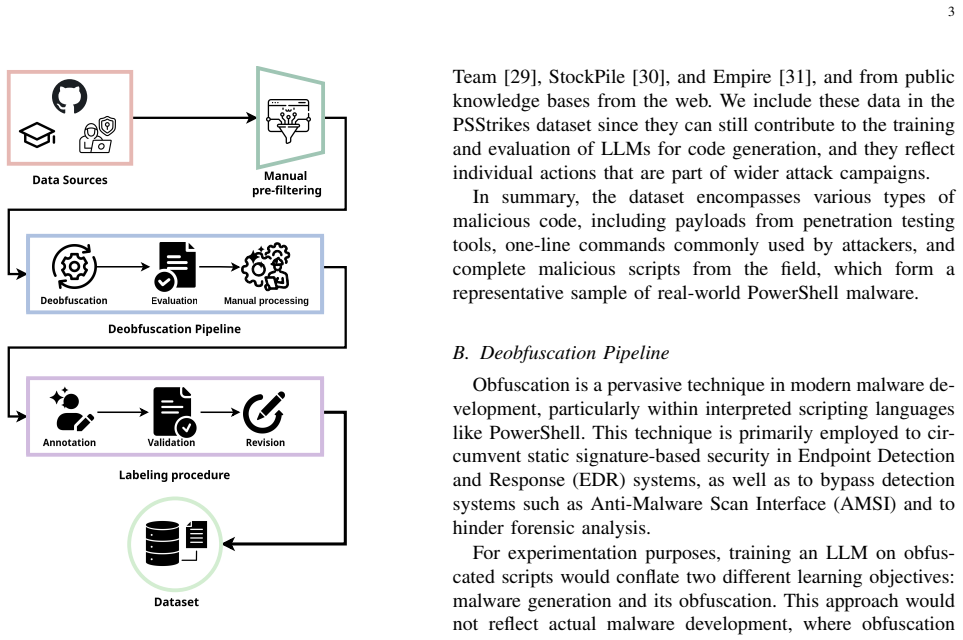
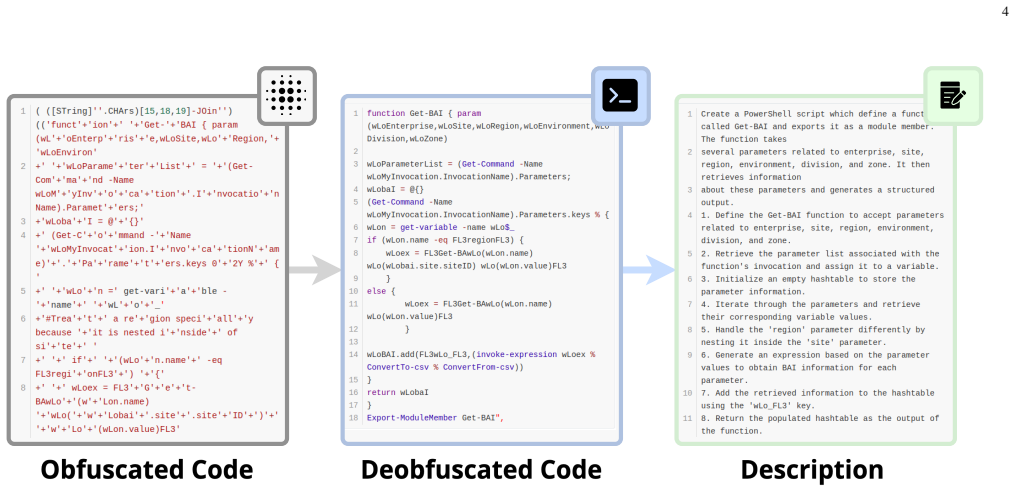
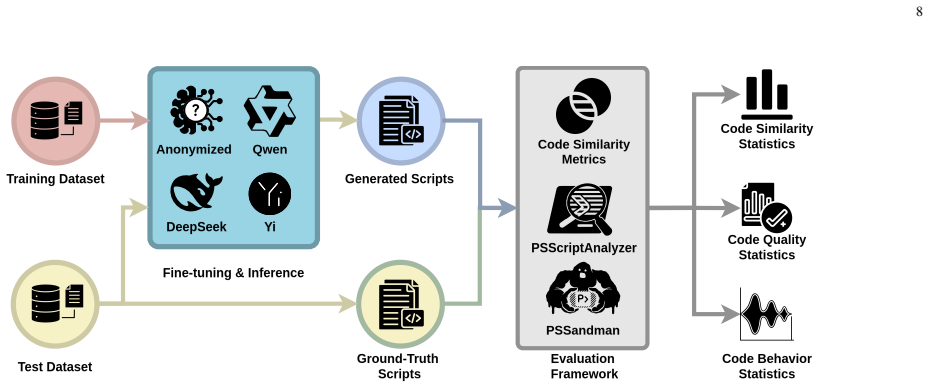
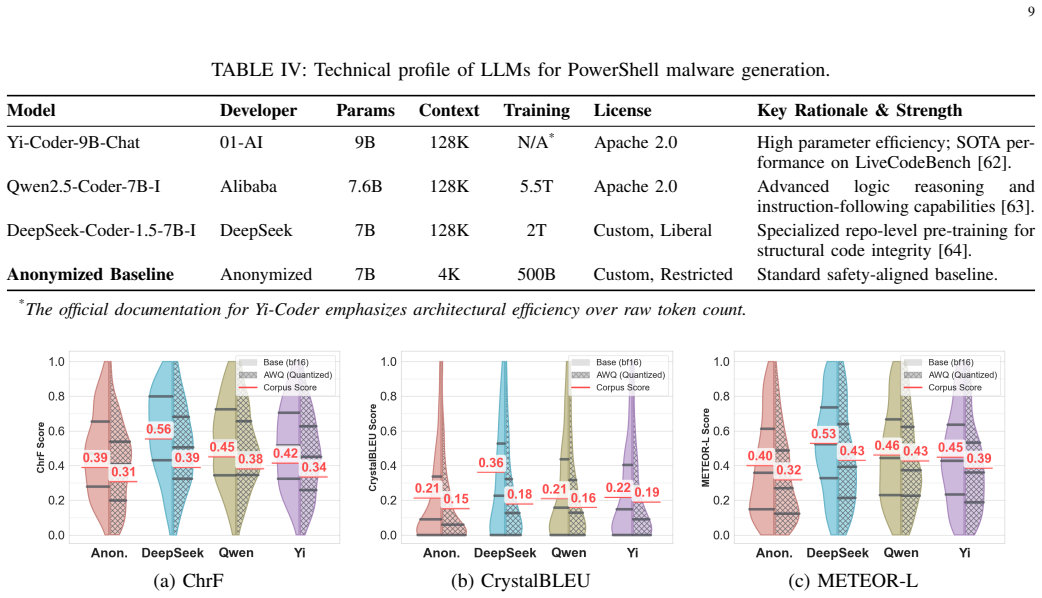
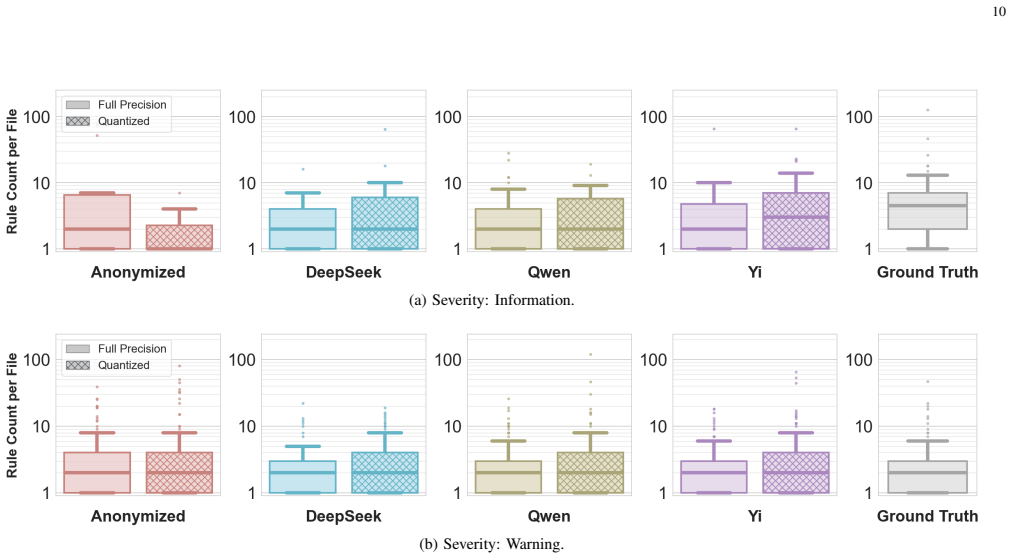
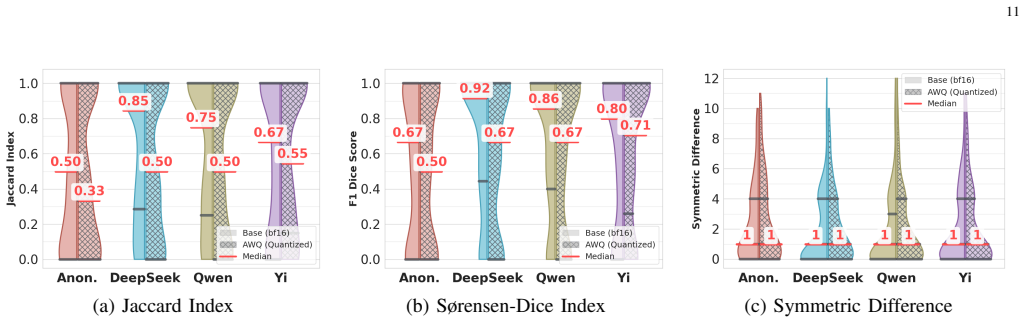
We introduce an experimental framework that includes a novel sandbox for dynamic analysis of AI-generated PowerShell malware together with a manually curated, natural-language-annotated dataset of real-world PowerShell malware. Evaluation of permissive open-weight LLMs adapted for malware generation shows that the synthetic samples trigger malicious operating-system events with a median Jaccard index of 84.5 percent relative to real malware and achieve complete overlap in 48.4 percent of cases.
What carries the argument
The sandbox that executes both real and LLM-generated PowerShell samples while logging the set of triggered malicious OS events, then quantifies similarity via Jaccard index on those event sets.
If this is right
- Detection systems must treat AI-generated scripts as functionally equivalent to human-written malware rather than as a separate class.
- The annotated dataset supplies training material both for improving malware detectors and for aligning LLMs against malicious PowerShell output.
- Dynamic event-set comparison offers a practical way to evaluate future code-generation models without relying on static code signatures.
- Permissive open-weight models already suffice to produce operationally similar malware, lowering the barrier for script-based attacks.
Where Pith is reading between the lines
- The same sandbox framework could be reused to generate large volumes of synthetic malicious samples for training improved behavioral detectors.
- High behavioral overlap implies that purely static or syntactic filters will miss many AI-produced threats even when the generated code looks different from known samples.
- Extending the approach to closed commercial models or to fine-tuned variants would test whether similarity can be driven even higher.
Load-bearing premise
The sandbox and its event logging capture the complete malicious behavior of every sample without systematically missing or inventing events.
What would settle it
Re-running the identical real and generated samples inside an independent sandbox with expanded event logging and obtaining substantially lower Jaccard indices would falsify the reported similarity.
Figures
read the original abstract
Generative AI has emerged as a significant cybersecurity threat, with several recent attack campaigns leveraging LLMs to generate code for malicious purposes via scripting languages such as PowerShell. Consequently, for cybersecurity analysts, it is imperative to investigate the offensive capabilities of AI code generators. In this paper, we propose an experimental framework to assess LLM-generated PowerShell malware, which comprises a novel sandbox approach for dynamic analysis of AI-generated malware. Furthermore, we present a novel, manually curated dataset of real-world PowerShell malware, annotated in natural language to assist the training and evaluation of LLMs. Finally, this study evaluates permissive, open-weight LLMs adapted to PowerShell malware generation. Our results reveal a high degree of similarity between real malware and LLM-generated ones in terms of triggered OS malicious events, with a median Jaccard index of 84.5% and 48.4% of instances achieving complete overlap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an experimental framework to assess the offensive capabilities of LLMs in generating PowerShell malware. It introduces a novel sandbox for dynamic analysis of such malware, presents a manually curated dataset of real-world PowerShell malware with natural language annotations, and evaluates several permissive open-weight LLMs on malware generation. The central empirical claim is that LLM-generated samples exhibit high behavioral similarity to real malware, as measured by triggered OS malicious events, with a median Jaccard index of 84.5% and 48.4% of instances achieving complete overlap.
Significance. If the sandbox-based comparison holds, the work would provide concrete evidence that current LLMs can generate PowerShell malware with functional equivalence to real samples in terms of OS event triggers, underscoring risks for AI-assisted cyber attacks and motivating improved detection methods. The curated dataset and sandbox framework could serve as reusable resources for training and benchmarking malware detectors or LLM safety evaluations.
major comments (2)
- [Sandbox description / Methods] Sandbox and event logging section: The headline similarity result (median Jaccard 84.5%, 48.4% complete overlap) is computed solely on sets of 'OS malicious events' logged inside the authors' custom sandbox. No cross-validation against bare-metal execution, alternative sandboxes, or manual reverse-engineering of a sample subset is described. Without such checks, differential suppression or over-counting of behaviors (e.g., certain cmdlets, network activity, or persistence mechanisms) between real and LLM-generated samples cannot be ruled out, directly undermining the functional-similarity interpretation of the Jaccard metric.
- [Results / Evaluation] Results section on Jaccard calculation: The event taxonomy used to define the sets for the Jaccard index is not shown to have been validated for consistency across the two populations. If the taxonomy was developed or refined after observing the generated samples, or if logging fidelity differs systematically, the reported overlap percentages would not reliably indicate behavioral equivalence.
minor comments (1)
- [Abstract / Evaluation setup] The abstract refers to 'permissive, open-weight LLMs adapted to PowerShell malware generation' but does not list the exact models, fine-tuning details, or prompting strategies in the provided summary; these should be enumerated explicitly in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments highlight important aspects of methodological validation that we address point-by-point below. We propose targeted revisions to strengthen the manuscript while maintaining the integrity of our reported results.
read point-by-point responses
-
Referee: [Sandbox description / Methods] Sandbox and event logging section: The headline similarity result (median Jaccard 84.5%, 48.4% complete overlap) is computed solely on sets of 'OS malicious events' logged inside the authors' custom sandbox. No cross-validation against bare-metal execution, alternative sandboxes, or manual reverse-engineering of a sample subset is described. Without such checks, differential suppression or over-counting of behaviors (e.g., certain cmdlets, network activity, or persistence mechanisms) between real and LLM-generated samples cannot be ruled out, directly undermining the functional-similarity interpretation of the Jaccard metric.
Authors: We agree that explicit cross-validation against bare-metal execution or alternative sandboxes is not described in the current manuscript. Our sandbox was engineered to capture a consistent set of OS-level events (process creation, registry modifications, network connections, and file operations) for both real and generated samples under identical conditions. However, we acknowledge that this leaves open the possibility of differential logging fidelity. In the revised manuscript we will add a new Limitations subsection that explicitly discusses this point, including the design rationale for the sandbox and why we consider the Jaccard metric informative within the controlled environment. We will also note that manual reverse-engineering of a subset was not performed due to the scale of the dataset. revision: yes
-
Referee: [Results / Evaluation] Results section on Jaccard calculation: The event taxonomy used to define the sets for the Jaccard index is not shown to have been validated for consistency across the two populations. If the taxonomy was developed or refined after observing the generated samples, or if logging fidelity differs systematically, the reported overlap percentages would not reliably indicate behavioral equivalence.
Authors: The event taxonomy was constructed prior to any LLM generation experiments, drawing from established categories of malicious PowerShell activity reported in prior cybersecurity literature (e.g., MITRE ATT&CK mappings for scripting languages). It was not refined after observing generated samples. To make this transparent, the revised version will include the complete taxonomy as an appendix together with a description of its development process and the specific OS events mapped to each category. This addition directly addresses the concern about post-hoc refinement and consistency. revision: yes
Circularity Check
No circularity: empirical Jaccard comparison uses external real-malware benchmark
full rationale
The paper's headline result (median Jaccard 84.5 % similarity on OS malicious events) is obtained by running both real and LLM-generated samples inside the same sandbox and directly computing set overlap on the logged events. This is a straightforward empirical measurement against an external reference set (the manually curated real-world PowerShell malware dataset) and does not reduce to any fitted parameter, self-definition, or self-citation chain. No mathematical derivation, ansatz, or uniqueness theorem is invoked; the comparison is data-driven and falsifiable by re-running the samples in a different environment.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Staying ahead of threat actors in the age of AI,
“Staying ahead of threat actors in the age of AI,” 2024. [Online]. Available: https://www.microsoft.com/en-us/security/blog/2024/02/14/ staying-ahead-of-threat-actors-in-the-age-of-ai/
2024
-
[2]
Disrupting malicious uses of AI
OpenAI, “Disrupting malicious uses of AI.” [Online]. Available: https://openai.com/it-IT/global-affairs/ disrupting-malicious-uses-of-ai-october-2025/
2025
-
[3]
Threat Intelligence Report: August 2025,
A. Moix, L. Ken, and Jacob Klein, “Threat Intelligence Report: August 2025,” 2025
2025
-
[4]
ESET Research, “The PromptLock malware,” https://infosec.exchange/ @ESETresearch/115095803130379945
-
[5]
UAC-0001 cyber- attacks on the security and defense sector using LAMEHUG software using LLM,
Computer Emergency Response Team of Ukraine, “UAC-0001 cyber- attacks on the security and defense sector using LAMEHUG software using LLM,” 2025
2025
-
[6]
Available: https://attack.mitre.org/groups/ G0007/
MITRE, “APT28.” [Online]. Available: https://attack.mitre.org/groups/ G0007/
-
[7]
Qwen2.5-Coder Collection Repository
“Qwen2.5-Coder Collection Repository.” [Online]. Available: https: //huggingface.co/collections/Qwen/qwen25-coder
-
[8]
PROMPTFLUX malware,
R. O. Zhen Heng, “PROMPTFLUX malware,” https://promptintel. novahunting.ai/prompt/a816c8b5-5188-4a9c-bd9a-1e6cbcd47686
-
[9]
Talk To Your Malware - Integrating AI Capability in an Open-Source C2 Agent,
GoSecure, “Talk To Your Malware - Integrating AI Capability in an Open-Source C2 Agent,”
-
[10]
Available: https://www.gosecure.ai/blog/ talk-to-your-malware-integrating-ai-capability-in-an-open-source-c2-agent
[Online]. Available: https://www.gosecure.ai/blog/ talk-to-your-malware-integrating-ai-capability-in-an-open-source-c2-agent
-
[11]
2026 Global Threat Report,
CrowdStrike, “2026 Global Threat Report,” CrowdStrike, Tech. Rep., 2026. [Online]. Available: https://www.crowdstrike.com/explore/ 2026-global-threat-report/2026-global-threat-report
2026
-
[12]
Threat Detection Report
red canary, “Threat Detection Report.” [Online]. Available: https: //redcanary.com/threat-detection-report/techniques/powershell/
-
[13]
M-Trends 2025: Special Report,
J. Kutscher, “M-Trends 2025: Special Report,” Google Cloud, Mandiant, Tech. Rep., 2025. [Online]. Available: https://cloud.google.com/blog/ topics/threat-intelligence/m-trends-2025
2025
-
[14]
Understanding the mirai botnet,
M. Antonakakis, T. April, M. . Baileyet al., “Understanding the mirai botnet,” inUSENIX Security Symposium, 2017
2017
-
[15]
Automatic exploit generation,
T. Avgerinos, S. K. Cha, A. Rebert, E. J. Schwartz, M. Woo, and D. Brumley, “Automatic exploit generation,”Commun. ACM, vol. 57, no. 2, 2014
2014
-
[16]
An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection,
S. Yan, S. Wang, Y . Duan, H. Hong, K. Lee, D. Kim, and Y . Hong, “An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection,” inUSENIX Security Symposium, 2024
2024
-
[17]
Casting a SPELL: Sentence Pairing Exploration for LLM Limitation- breaking,
Y . Huang, X. Jia, W. Guo, Y . Sun, Y . Huang, C. Wang, and Y . Liu, “Casting a SPELL: Sentence Pairing Exploration for LLM Limitation- breaking,”arXiv preprint arXiv:2512.21236, 2025
-
[18]
The Power of Words: Generating PowerShell Attacks from Natural Language,
P. Liguori, C. Marescalco, R. Natella, V . Orbinato, and L. Pianese, “The Power of Words: Generating PowerShell Attacks from Natural Language,” inUSENIX WOOT Conf. on Offensive Technologies, 2024
2024
-
[19]
AutoMalDesc: Large-Scale Script Analysis for Cyber Threat Research,
A.-M. Apostu, A. Preda, A. D. Damir, D. Bolocan, R. T. Ionescu, I. Croitoru, and M. Gaman, “AutoMalDesc: Large-Scale Script Analysis for Cyber Threat Research,” inAAAI Conf. on Artificial Intelligence, vol. 40, no. 1, 2026
2026
-
[20]
RedShell: A Generative AI-Based Approach to Ethical Hacking
R. Bessa, R. Claro, J. Trindade, and J. Lourenc ¸o, “RedShell: A Generative AI-Based Approach to Ethical Hacking,”arXiv preprint arXiv:2604.11506, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
PowerShell-for-Hackers
“PowerShell-for-Hackers.” [Online]. Available: https://github.com/ I-Am-Jakoby/PowerShell-for-Hackers
-
[22]
Powershell-Scripts-for-Hackers-and-Pentesters
“Powershell-Scripts-for-Hackers-and-Pentesters.” [On- line]. Available: https://github.com/Whitecat18/ Powershell-Scripts-for-Hackers-and-Pentesters
-
[23]
Malicious-PowerShell-Dataset
“Malicious-PowerShell-Dataset.” [Online]. Available: https://github. com/Fa2y/Malicious-PowerShell-Dataset
-
[24]
MalwareBazaar,
ABUSE.ch, “MalwareBazaar,” https://bazaar.abuse.ch/
-
[25]
HybridAnalysis,
MITRE, “HybridAnalysis,” https://hybrid-analysis.com/
-
[26]
Nishang
“Nishang.” [Online]. Available: https://github.com/samratashok/nishang
-
[27]
PowerSploit
“PowerSploit.” [Online]. Available: https://github.com/PowerShellMafia/ PowerSploit
-
[28]
Invoke-deobfuscation: AST- based and semantics-preserving deobfuscation for PowerShell scripts,
H. Chai, L. Ying, H. Duan, and D. Zha, “Invoke-deobfuscation: AST- based and semantics-preserving deobfuscation for PowerShell scripts,” inIEEE/IFIP Intl. Conf. on Dep. Systems and Networks (DSN), 2022
2022
-
[29]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” Transactions of the Association for Computational Linguistics, vol. 12, 2024
2024
-
[30]
Atomic Red Team,
Red Canary, “Atomic Red Team,” https://atomicredteam.io/
-
[31]
CALDERA plugin: Stockpile,
MITRE, “CALDERA plugin: Stockpile,” https://github.com/mitre/ stockpile
-
[32]
Empire Project, “Empire,” https://github.com/EmpireProject/Empire
-
[33]
Invoke-obfuscation v1.8
“Invoke-obfuscation v1.8.” [Online]. Available: https://github.com/ danielbohannon/Invoke-obfuscation
-
[34]
Selection-inference: Ex- ploiting large language models for interpretable logical reasoning,
A. Creswell, M. Shanahan, and I. Higgins, “Selection-inference: Ex- ploiting large language models for interpretable logical reasoning,”arXiv preprint arXiv:2205.09712, 2022
-
[35]
Revoke-Obfuscation v1.0
“Revoke-Obfuscation v1.0.” [Online]. Available: https://github.com/ danielbohannon/Revoke-Obfuscation
-
[36]
PowerDecode
“PowerDecode.” [Online]. Available: https://github.com/Malandrone/ PowerDecode
-
[37]
Pow- erdecode: a powershell script decoder dedicated to malware analysis,
G. M. Malandrone, G. Virdis, G. Giacinto, D. Maiorcaet al., “Pow- erdecode: a powershell script decoder dedicated to malware analysis,” inItalian Conf. on Cybersecurity, ITASEC, vol. 2940, 2021
2021
-
[38]
Out of the bleu: how should we assess quality of the code generation models?
M. Evtikhiev, E. Bogomolov, Y . Sokolov, and T. Bryksin, “Out of the bleu: how should we assess quality of the code generation models?” Elsevier: Journal of Systems and Software, vol. 203, 2023
2023
-
[39]
chrF: character n-gram F-score for automatic MT evalua- tion,
M. Popovi ´c, “chrF: character n-gram F-score for automatic MT evalua- tion,” inWksp. on Statistical Machine Translation, 2015
2015
-
[40]
Meteor universal: Language specific translation evaluation for any target language,
M. Denkowski and A. Lavie, “Meteor universal: Language specific translation evaluation for any target language,” inWksp. on Statistical Machine Translation, 2014
2014
-
[41]
CrystalBLEU: precisely and efficiently mea- suring the similarity of code,
A. Eghbali and M. Pradel, “CrystalBLEU: precisely and efficiently mea- suring the similarity of code,” inIEEE/ACM Intl. Conf. on Automated Soft. Eng., 2022
2022
-
[42]
Powershell SDK: Parser Class
“Powershell SDK: Parser Class.” [Online]. Avail- able: https://learn.microsoft.com/en-us/dotnet/api/system.management. automation.language.parser?view=powershellsdk-7.4.0
-
[43]
PSScriptAnalyzer
“PSScriptAnalyzer.” [Online]. Available: https://github.com/powershell/ psscriptanalyzer
-
[44]
Payette and S
B. Payette and S. Richard,Windows PowerShell in Action. Manning Publications, 2018
2018
-
[45]
Shepard, C
M. Shepard, C. Venkatesan, S. Talaat, and B. J. Blawat,PowerShell: Automating Administrative Tasks: The art of automating and managing Windows environments. Packt Publications, 2017
2017
-
[46]
Dent,Mastering PowerShell Scripting: Automate repetitive tasks and simplify complex administrative tasks using PowerShell
C. Dent,Mastering PowerShell Scripting: Automate repetitive tasks and simplify complex administrative tasks using PowerShell. Packt Publications, 2024
2024
-
[47]
VirtualBox Technical Documentation
“VirtualBox Technical Documentation.” [Online]. Available: https: //www.virtualbox.org/manual/ch08.html
-
[48]
Benjamin Delpy’s implementation of Mimikatz
“Benjamin Delpy’s implementation of Mimikatz.” [Online]. Available: https://github.com/gentilkiwi/mimikatz
-
[49]
PowerSploit
“PowerSploit.” [Online]. Available: https://attack.mitre.org/software/ S0194/
-
[50]
MITRE ATT&CK Enterprise Techniques
“MITRE ATT&CK Enterprise Techniques.” [Online]. Available: https://attack.mitre.org/versions/v18//techniques/enterprise/ 14
-
[51]
System Monitor (Sysmon)
“System Monitor (Sysmon).” [Online]. Available: https://learn.microsoft. com/en-us/sysinternals/downloads/sysmon
-
[52]
Roddie, J
M. Roddie, J. Deyalsingh, and G. J. Katz,Practical Threat Detection Engineering: A hands-on guide to planning, developing, and validating detection capabilitie. Packt Publications, 2023
2023
-
[53]
Sigma - Generic Signature Format for SIEM Systems
“Sigma - Generic Signature Format for SIEM Systems.” [Online]. Available: https://github.com/sigmahq/sigma
-
[54]
Zircolite
“Zircolite.” [Online]. Available: https://github.com/wagga40/Zircolite
-
[55]
MITRE ATT&CK Matrix for Enterprise, version 18.1
“MITRE ATT&CK Matrix for Enterprise, version 18.1.” [Online]. Available: https://attack.mitre.org/versions/v18/
-
[56]
Impair Defenses: Disable or Modify Tools
“Impair Defenses: Disable or Modify Tools.” [Online]. Available: https://attack.mitre.org/versions/v18/techniques/T1562/001/
-
[57]
On label dependence and loss minimization in multi-label classification,
K. Dembczy ´nski, W. Waegeman, W. Cheng, and E. H ¨ullermeier, “On label dependence and loss minimization in multi-label classification,” Machine Learning, vol. 88, no. 1, 2012
2012
-
[58]
Multi-label classification: An overview,
G. Tsoumakas and I. Katakis, “Multi-label classification: An overview,” Intl. J. of Data Warehousing and Mining (IJDWM), vol. 3, no. 3, 2007
2007
-
[59]
´Etude comparative de la distribution florale dans une portion des Alpes et des Jura,
P. Jaccard, “ ´Etude comparative de la distribution florale dans une portion des Alpes et des Jura,”Bull Soc Vaudoise Sci Nat, 1901
1901
-
[60]
C. D. Manning, P. Raghavan, and H. Sch ¨utze,Introduction to Informa- tion Retrieval. Cambridge University Press, 2008
2008
-
[61]
Measures of the amount of ecologic association between species,
L. R. Dice, “Measures of the amount of ecologic association between species,”JSTOR Ecology, 1945
1945
-
[62]
A method of establishing groups of equal amplitude in plant sociologybased on similarity of species content and its application to analyses of the vegettation on Danish commons,
T. Sφrensen, “A method of establishing groups of equal amplitude in plant sociologybased on similarity of species content and its application to analyses of the vegettation on Danish commons,”Biol. Skr., K. danske Vidensk, vol. 5, 1948
1948
-
[63]
Yi: Open Foundation Models by 01.AI
A. Young, B. Chen, C. Li, C. Huang, G. Zhang, G. Zhang, G. Wang, H. Li, J. Zhu, J. Chenet al., “Yi: Open foundation models by 01. ai,” arXiv preprint arXiv:2403.04652, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Danget al., “Qwen2.5-Coder Technical Report,”arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . Liet al., “DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence,” 2024. [Online]. Available: https://arxiv.org/abs/2401.14196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
A Survey on LLM-based Code Generation for Low-Resource and Domain-Specific Programming Languages,
S. Joel, J. Wu, and F. Fard, “A Survey on LLM-based Code Generation for Low-Resource and Domain-Specific Programming Languages,”ACM Transactions on Software Engineering and Methodology, 2024
2024
-
[67]
The Menlo Report,
M. Bailey, D. A. Dittrich, E. Kenneally, and D. Maughan, “The Menlo Report,”IEEE Security & Privacy, vol. 10, no. 2, 2012
2012
-
[68]
The menlo report: Ethical principles guiding information and communication technology research,
E. Kenneally and D. Dittrich, “The menlo report: Ethical principles guiding information and communication technology research,”Available at SSRN 2445102, 2012
2012
-
[69]
PentestGPT: Evaluating and Har- nessing Large Language Models for Automated Penetration Testing,
G. Deng, Y . Liu, V . Mayoral-Vilches, P. Liu, Y . Li, Y . Xu, T. Zhang, Y . Liu, M. Pinzger, and S. Rass, “PentestGPT: Evaluating and Har- nessing Large Language Models for Automated Penetration Testing,” in USENIX Security Symposium, 2024
2024
-
[70]
Autopentester: An LLM agent-based framework for automated pentesting,
Y . Ginige, A. Niroshan, S. Jain, and S. Seneviratne, “Autopentester: An LLM agent-based framework for automated pentesting,” inIEEE Intl. Conf. on Trust, Security and Privacy in Comp. and Comm. (TrustCom), 2025
2025
-
[71]
Exploring the cybercrime potential of llms: A focus on phishing and malware generation,
O. C ¸ etin, B. Birinci, C ¸ . Uysal, and B. Arief, “Exploring the cybercrime potential of llms: A focus on phishing and malware generation,” in Europ. Interdisciplinary Cybersecurity Conf., 2025
2025
-
[72]
Code as a Weapon: Generating Malware with Large Language Models,
Y .-J. Lin, P.-H. Chou, W.-Y . Shen, Y .-R. Guo, C.-L. Wu, and Y .-T. Huang, “Code as a Weapon: Generating Malware with Large Language Models,” inIEEE Conf. on Dep. and Sec. Comp. (DSC), 2025
2025
-
[73]
Jailbreak-Free LLM-Assisted Malware Generation: An Empirical and Conceptual Analysis,
N. Sugio and H. Ito, “Jailbreak-Free LLM-Assisted Malware Generation: An Empirical and Conceptual Analysis,”IEEE Access, 2026
2026
-
[74]
MalGEN: A Testbed for Modeling and Evaluating Malware Behaviors
B. Saha and S. K. Shukla, “Malgen: A generative agent framework for modeling malicious software in cybersecurity,”arXiv preprint arXiv:2506.07586, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
CyberLLMInstruct: A Pseudo- Malicious Dataset Revealing Safety-Performance Trade-offs in Cyber Security LLM Fine-tuning,
A. ElZemity, B. Arief, and S. Li, “CyberLLMInstruct: A Pseudo- Malicious Dataset Revealing Safety-Performance Trade-offs in Cyber Security LLM Fine-tuning,” inACM Wksp. on Artificial Intelligence and Security, 2025
2025
-
[76]
Z. Xuan, J. Gardiner, and S. Belguith, “The dark deep side of DeepSeek: Fine-tuning attacks against the safety alignment of CoT-enabled models,” arXiv preprint arXiv:2502.01225, 2025
-
[77]
A. Sheshadri, A. Ewart, P. . Guoet al., “Latent adversarial training improves robustness to persistent harmful behaviors in llms,”arXiv preprint arXiv:2407.15549, 2024
-
[78]
Generating Synthetic Malware Samples using Generative AI against Zero-day Attacks,
T. Bao, K. Trousil, Q. D. Tran, F. Di Troia, and Y . Park, “Generating Synthetic Malware Samples using Generative AI against Zero-day Attacks,”IEEE Access, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.