Contrastive Reflection for Iterative Prompt Optimization
Pith reviewed 2026-07-01 01:59 UTC · model grok-4.3
The pith
Contrastive reflection pairs error traces with nearby successes to generate prompt edits that raise held-out HotpotQA exact-match accuracy from 51.4% to 60.4%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
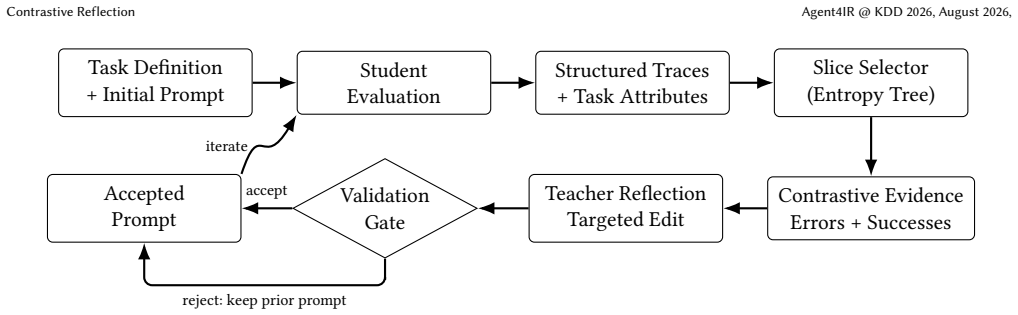
The authors claim that the contrastive reflection loop identifies error-anchored slices from agent traces, adds nearby successful examples from the same region, and solicits targeted prompt edits from a Teacher LLM; when validated, one such edit lifts held-out exact-match accuracy from 51.4% to 60.4% on a public HotpotQA retrieval-augmented QA setup, while failure-only and random variants improve less and break more previously correct cases.
What carries the argument
The contrastive reflection loop, which extracts error-anchored behavioral slices from QA and grading agent traces, augments them with nearby successes, and obtains targeted prompt edits from a Teacher LLM that are accepted only on measured validation gains.
If this is right
- Prompt edits become traceable to specific error-success distinctions rather than opaque search outcomes.
- Validation-driven acceptance limits the number of previously correct examples that become broken.
- The same loop applies to any agent workflow that exposes structured traces and dimension-level grader scores.
- The tree selector is one possible implementation; the contrastive loop itself is presented as the reusable contribution.
Where Pith is reading between the lines
- If the teacher model is weaker or differently aligned than the agent, the quality of proposed edits could degrade on harder tasks not tested here.
- The method could be layered on top of existing automated optimizers by using their candidate prompts as starting points for contrastive reflection.
- Repeated iterations might surface recurring patterns of prompt drift across multiple repair cycles.
Load-bearing premise
A teacher LLM given only contrastive error-success slices will generate prompt edits whose validation gains transfer to held-out data without introducing undetected regressions on other dimensions.
What would settle it
Generate an edit on the reported HotpotQA validation set, then measure whether exact-match accuracy falls below the 51.4% baseline on a held-out test set drawn from a different distribution of multi-hop questions.
Figures
read the original abstract
LLM agents are becoming central to information retrieval: they issue retrieval queries, synthesize answers, and increasingly serve as judges for IR evaluation. Improving the prompts that control these agents is an optimization problem, but in applied IR settings it often looks less like blind search and more like debugging. Engineers need to know which behavior failed, which nearby behavior still worked, what distinguishes the two, and whether a prompt edit improves held-out quality without introducing regressions. We present Contrastive Reflection, an iterative prompt-optimization framework for agentic IR workflows. The framework starts from a task-centric quality definition: QA agents expose retrieval or reasoning traces, and grading agents expose dimension-level scores and rationales. These structured traces are used to identify error-anchored behavioral slices, add nearby successful examples from the same region, and ask a Teacher LLM to propose a targeted prompt edit. Candidate edits are accepted only when validation performance improves, optionally subject to regression checks. We instantiate the framework with a tree-based slice selector, but the contribution is the contrastive reflection loop rather than the tree itself. On a public HotpotQA retrieval-augmented QA setup, one tree-selected contrastive repair improves held-out exact-match accuracy from 51.4% to 60.4%. Failure-only and random-evidence variants improve less and break more previously correct examples. A light instruction-only comparison places the method near modern prompt optimizers: MIPROv2 reaches 59.4% and GEPA 57.0%. The result is an interpretable optimization loop for IR agents, aimed at making prompt repair more inspectable and validation-driven.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Contrastive Reflection, an iterative prompt-optimization framework for LLM agents in information retrieval. It extracts error-anchored behavioral slices from agent traces, contrasts them with nearby successful examples, and uses a Teacher LLM to propose targeted prompt edits that are accepted only if they improve validation performance (optionally with regression checks). On a HotpotQA retrieval-augmented QA task, one tree-selected contrastive repair raises held-out exact-match accuracy from 51.4% to 60.4%, outperforming failure-only and random-evidence baselines while remaining competitive with MIPROv2 (59.4%) and GEPA (57.0%).
Significance. If the central empirical result holds under more rigorous evaluation, the framework supplies a validation-driven, inspectable alternative to black-box prompt search that aligns with engineering practice in agentic IR. Its emphasis on contrastive slices, regression checks, and held-out transfer could improve reliability when debugging retrieval and reasoning agents.
major comments (2)
- [Evaluation on HotpotQA] The central performance claim (held-out EM rising from 51.4% to 60.4%) rests on a single tree-selected contrastive repair. No information is supplied on the number of independent runs, slice-sampling seeds, Teacher-LLM sampling variance, or statistical significance testing, rendering the reliability of validation-to-held-out transfer unverifiable from the reported evidence.
- [Contrastive Reflection framework] The manuscript states that edits are accepted only on validation improvement (optionally with regression checks), yet provides no concrete description of the regression-check implementation, the exact slice-selection algorithm, or how many candidate edits were generated and rejected before the reported repair.
minor comments (1)
- [Evaluation on HotpotQA] The abstract and evaluation paragraph refer to “a light instruction-only comparison” with MIPROv2 and GEPA; the precise experimental protocol (identical task slice, iteration budget, base model) should be stated explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the empirical reliability and methodological transparency of the work.
read point-by-point responses
-
Referee: [Evaluation on HotpotQA] The central performance claim (held-out EM rising from 51.4% to 60.4%) rests on a single tree-selected contrastive repair. No information is supplied on the number of independent runs, slice-sampling seeds, Teacher-LLM sampling variance, or statistical significance testing, rendering the reliability of validation-to-held-out transfer unverifiable from the reported evidence.
Authors: We agree that reporting a single tree-selected repair limits verifiability of the transfer result. In the revised manuscript we will add results from multiple independent runs (different slice-sampling seeds and Teacher-LLM temperatures), report mean and standard deviation on held-out EM, and include paired statistical significance tests between the baseline and repaired prompts. These additions will directly address the concern about reliability. revision: yes
-
Referee: [Contrastive Reflection framework] The manuscript states that edits are accepted only on validation improvement (optionally with regression checks), yet provides no concrete description of the regression-check implementation, the exact slice-selection algorithm, or how many candidate edits were generated and rejected before the reported repair.
Authors: We acknowledge the need for greater concreteness. The current manuscript describes the tree-based selector at a high level in Section 3; we will expand this with (i) explicit pseudocode for slice extraction and contrastive pairing, (ii) the precise regression-check procedure (re-evaluation on a fixed set of previously correct validation examples with a tolerance threshold), and (iii) experimental statistics on the number of candidate edits proposed by the Teacher LLM and the fraction ultimately accepted. These details will be added to the methods and experimental sections. revision: yes
Circularity Check
No circularity: empirical held-out measurement with no self-referential derivation
full rationale
The paper presents a methodological framework (Contrastive Reflection) and reports a direct empirical measurement of held-out exact-match accuracy improvement (51.4% to 60.4%) after applying one tree-selected edit. No equations, fitted parameters, or self-citations are invoked to derive the reported gain; the result is obtained by running the method on validation data and measuring transfer on held-out data. The central claim does not reduce to any input by construction, self-definition, or self-citation chain. This is a standard empirical evaluation with no load-bearing mathematical derivation that could be circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A. Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J. Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. 2025. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning.arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Yeounoh Chung, Tim Kraska, Neoklis Polyzotis, Ki Hyun Tae, and Steven Euijong Whang. 2019. Slice Finder: Automated Data Slicing for Model Validation. InICDE
2019
-
[3]
Sabri Eyuboglu, Maya Varma, Khaled Saab, Jean-Benoit Delbrouck, Christopher Lee-Messer, Jared Dunnmon, James Zou, and Christopher Ré. 2022. Domino: Discovering Systematic Errors with Cross-Modal Embeddings. InICLR
2022
- [4]
-
[5]
Chrisantha Fernando et al . 2023. Promptbreeder: Self-Referential Self- Improvement via Prompt Evolution.arXiv preprint arXiv:2309.16797(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Qingyan Guo et al. 2024. Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers. InICLR
2024
-
[7]
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav San- thanam, Sri Vardhamanan A., Saiful Haq, Ashutosh Sharma, Thomas Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2024. DSPy: Com- piling Declarative Language Model Calls into State-of-the-Art Pipelines. InICLR
2024
-
[8]
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning. InEMNLP
2021
-
[9]
Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab
Krista Opsahl-Ong, Michael J. Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. 2024. Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs.arXiv preprint arXiv:2406.11695(2024). EMNLP 2024
-
[10]
Gradient Descent
Reid Pryzant et al. 2023. Automatic Prompt Optimization with “Gradient Descent” and Beam Search. InEMNLP
2023
-
[11]
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. InACL
2020
-
[12]
Paul Thomas, Seth Spielman, Nick Craswell, and Bhaskar Mitra. 2024. Large Language Models Can Accurately Predict Searcher Preferences.Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval(2024). Earlier version: arXiv:2309.10621
-
[13]
Xinyuan Wang et al. 2024. PromptAgent: Strategic Planning with Language Models Enables Expert-Level Prompt Optimization. InICLR
2024
- [14]
-
[15]
Chengrun Yang et al. 2024. Large Language Models as Optimizers. InICLR
2024
-
[16]
Zhilin Yang, Peng Qi, Saizheng Zhang, et al . 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InEMNLP
2018
-
[17]
Yongchao Zhou et al. 2023. Large Language Models Are Human-Level Prompt Engineers. InICLR
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.