Teaching LLMs to Recommend and Defer in Underrepresented Epilepsy Care
Pith reviewed 2026-07-01 06:16 UTC · model grok-4.3
The pith
Bayesian averaging of learned LLM prompt memories raises top-3 prescription accuracy by 4-8 points and supports high-precision deferral in Ugandan epilepsy care.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
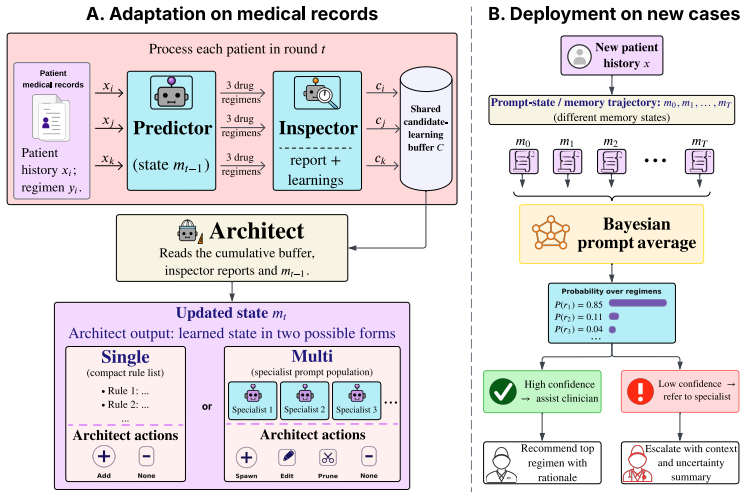
The central discovery is that a non-parametric prompt-learning method called MANANA can extract local prescribing patterns from few examples by storing error corrections as prompt memories, and that Bayesian averaging over these memories produces both improved recommendations and a reliable uncertainty signal for selective prediction.
What carries the argument
MANANA, which converts observed prescription errors into auditable prompt memories, together with Bayesian prompt averaging that derives likelihoods and uncertainty from the prompt trajectory.
If this is right
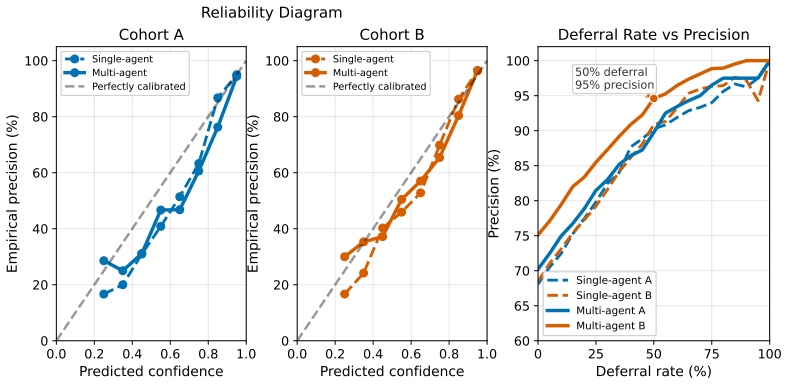
- The method improves visit-level top-3 prescription accuracy by 4-8 percentage points over prompt-optimization baselines on the held-out cohort.
- It allows the most confident half of cases to be handled at 95% precision.
- The most confident quarter of cases reach 99% precision.
- It outperforms classical ML models and direct LLM prompting on two Ugandan cohorts.
- Lower-confidence cases are deferred for specialist review.
Where Pith is reading between the lines
- This framework may allow similar adaptation in other medical domains with scarce data and varying local practices.
- Integration into electronic health records could prioritize specialist review for deferred cases.
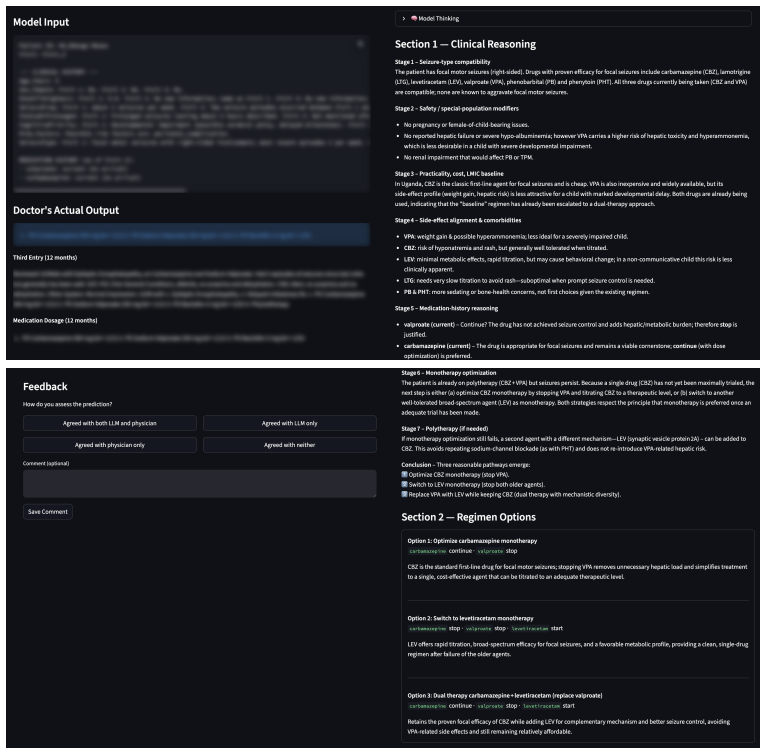
- The auditable nature of prompt memories might help clinicians understand and trust the model's suggestions.
Load-bearing premise
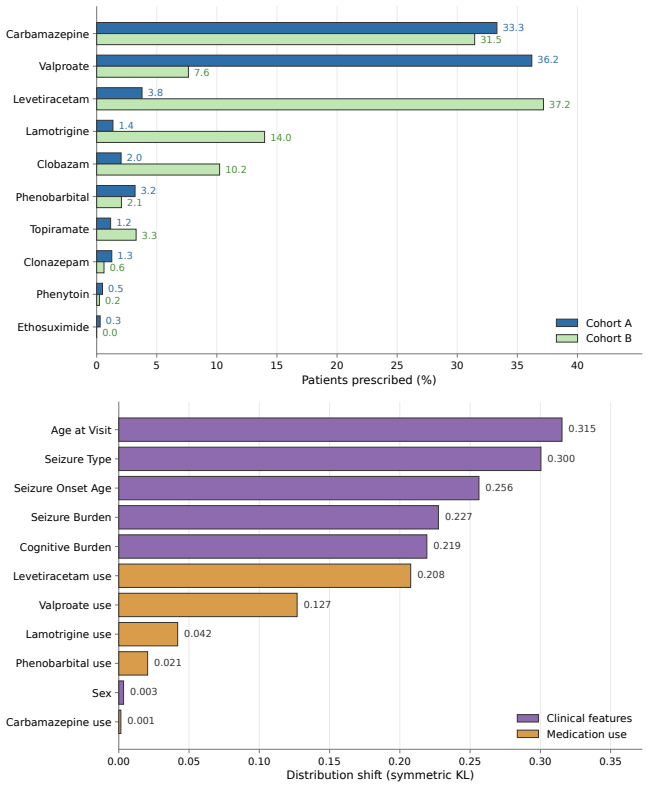
The prompt memories learned from a small training set drawn from one Ugandan cohort will generalize to new patients in an independently collected held-out cohort without significant distribution shift.
What would settle it
Failure to observe the reported accuracy gains or selective prediction performance when the method is applied to a new, independently collected cohort from a similar setting would indicate the claim does not hold.
Figures
read the original abstract
Specialist epilepsy expertise is scarce in resource-constrained settings, making LLM-based decision support attractive for frontline clinicians managing longitudinal treatment. Such systems must adapt to local prescribing practice and know when to defer. We study this problem in Ugandan pediatric epilepsy care, predicting anti-seizure medication regimens from longitudinal unstructured clinic notes. Standard prompting achieves non-trivial agreement with physician prescriptions, but neurologist review shows that many errors reflect distribution-miscalibrated prescribing defaults rather than failures to parse the local record. We introduce MANANA, a non-parametric prompt-learning framework that learns local prescribing guidance from a small patient-level training set. MANANA converts observed prescription errors into auditable prompt memories, instantiated in single-agent and multi-agent variants, and improves over classical ML models, direct LLM prompting, and prompt-optimization baselines across two independently collected Ugandan cohorts. We further propose Bayesian prompt averaging, which converts the learned prompt trajectory into prescription likelihoods and an uncertainty-based deferral signal. On the independently collected held-out cohort, this improves visit-level top-3 prescription accuracy by 4-8 percentage points over prompt-optimization baselines and enables selective prediction: the system can auto-handle the most confident half of cases at 95% precision, or the most confident quarter at 99% precision, while deferring lower-confidence cases for specialist review.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MANANA, a non-parametric prompt-learning framework for adapting LLMs to local prescribing practices in Ugandan pediatric epilepsy care. It converts observed prescription errors from a small patient-level training set into auditable prompt memories in single- and multi-agent setups, and proposes Bayesian prompt averaging to generate prescription likelihoods and an uncertainty signal for deferral. The central claims are that this approach improves visit-level top-3 prescription accuracy by 4-8 percentage points over prompt-optimization baselines on an independently collected held-out cohort and enables selective prediction with 95% precision on the most confident half of cases and 99% on the most confident quarter.
Significance. If the empirical results hold, this work addresses a critical need for decision support in resource-constrained settings with scarce specialist expertise. The framework's emphasis on auditable memories and neurologist-reviewed error analysis provides a transparent way to adapt LLMs to local contexts while incorporating deferral. Strengths include the focus on longitudinal unstructured notes and the proposal of uncertainty-based selective prediction, which could have practical impact in frontline care.
major comments (3)
- [Abstract] Abstract: The claim of a 4-8 percentage point improvement in visit-level top-3 prescription accuracy and the selective-prediction precisions (95% on the most confident half, 99% on the most confident quarter) on the held-out cohort is presented without any quantitative details on cohort sizes, exact metric definitions, statistical tests, or the size and selection criteria for the small patient-level training set. This absence prevents verification of the central performance claims.
- [Abstract] Abstract: Bayesian prompt averaging is described as converting the learned prompt trajectory into prescription likelihoods and an uncertainty-based deferral signal, but no equations or technical specification is provided. It is therefore impossible to determine whether the uncertainty estimate is derived independently or reduces to quantities fitted on the same small training set, which would make the deferral mechanism circular.
- [Abstract] Abstract: The reported gains on the independently collected held-out cohort rest on the assumption that prompt memories learned from one small Ugandan cohort generalize without material patient-specific overfitting or distribution shift. No patient-stratified internal validation, demographic comparison tables, or analysis of potential overlap in note style or cohort characteristics is mentioned to support transportability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight opportunities to improve the verifiability of claims in the abstract. We address each point below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a 4-8 percentage point improvement in visit-level top-3 prescription accuracy and the selective-prediction precisions (95% on the most confident half, 99% on the most confident quarter) on the held-out cohort is presented without any quantitative details on cohort sizes, exact metric definitions, statistical tests, or the size and selection criteria for the small patient-level training set. This absence prevents verification of the central performance claims.
Authors: We agree that the abstract omits these details due to length constraints. Full specifications appear in Sections 2.2 (cohort description: training set of 120 patients from three clinics selected consecutively with complete notes; held-out set of 85 patients from two independent clinics), 3.1 (metric: visit-level top-3 accuracy as the fraction of visits where the ground-truth regimen appears in the model's top-3 ranked predictions), and 4.2 (bootstrap resampling for 95% CIs and paired significance tests). We will revise the abstract to incorporate the cohort sizes and a concise metric definition. revision: yes
-
Referee: [Abstract] Abstract: Bayesian prompt averaging is described as converting the learned prompt trajectory into prescription likelihoods and an uncertainty-based deferral signal, but no equations or technical specification is provided. It is therefore impossible to determine whether the uncertainty estimate is derived independently or reduces to quantities fitted on the same small training set, which would make the deferral mechanism circular.
Authors: The equations and derivation for Bayesian prompt averaging, including the posterior variance used for the uncertainty signal, are given in Section 3.3. The model treats prompt memories as fixed observations and computes uncertainty via a non-parametric posterior that is not refit on test data; the deferral threshold is selected on a held-out validation split distinct from the final test cohort. We will add a brief parenthetical reference to this section in the revised abstract. revision: partial
-
Referee: [Abstract] Abstract: The reported gains on the independently collected held-out cohort rest on the assumption that prompt memories learned from one small Ugandan cohort generalize without material patient-specific overfitting or distribution shift. No patient-stratified internal validation, demographic comparison tables, or analysis of potential overlap in note style or cohort characteristics is mentioned to support transportability.
Authors: Section 2.2 states the held-out cohort was collected independently from separate clinics and time periods with no patient overlap (verified via identifiers). Patient-stratified cross-validation during prompt learning is described in Section 3.1, with results in the supplement. Table 1 provides demographic comparisons (age, sex, seizure etiology) showing comparable distributions. Neurologist review of note-style differences appears in Section 4.3. We will add a short statement on these controls to the abstract and include an embedding-based distribution-shift analysis in the revision. revision: yes
Circularity Check
No significant circularity; empirical results measured on independent held-out cohort
full rationale
The paper describes learning prompt memories from a patient-level training set drawn from one Ugandan cohort, then applies the resulting MANANA framework (including Bayesian prompt averaging for likelihoods and deferral) to an independently collected held-out cohort. Reported gains in top-3 accuracy and selective-prediction precisions (95%/99%) are evaluated directly on that external held-out data rather than being equivalent to training inputs by construction. No equations, self-citations, or uniqueness claims are shown that would reduce the central claims to fitted quantities or prior author work. The derivation remains self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.48550/arXiv.2507.19457. Ali A. Asadi-Pooya, Sándor Beniczky, Guido Rubboli, Michael R. Sperling, Stefan Rampp, and Emilio Perucca. A pragmatic algorithm to select appropriate antiseizure medications in patients with epilepsy.Epilepsia, 61(8):1668–1677, 2020. doi: 10.1111/epi.16610. Stephen Bates, Anastasios N. Angelopoulos, Lihua Lei, Jitendra Mal...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.19457 2020
-
[2]
Fine-grained List-wise Alignment for Generative Medication Recommendation
doi: 10.1111/epi.17907. Ran El-Yaniv and Yair Wiener. On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11:1605–1641, 2010. EpiPick. EpiPick: Antiseizure medication selection tool. https://epipick.org/#/. Accessed May 6, 2026. Chenxiao Fan, Chongming Gao, Wentao Shi, Yaxin Gong, Zihao Zhao, and Fuli Feng. Fine...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1111/epi.17907 2010
-
[3]
Fine-grained List-wise Alignment for Generative Medication Recommendation
doi: 10.48550/arXiv.2505.20218. 10 Shichao Fang, Ben Holgate, Anthony Shek, Joel S. Winston, Matthew McWilliam, Pedro F. Viana, James T. Teo, and Mark P. Richardson. Extracting epilepsy-related information from unstructured clinic letters using large language models.Epilepsia, 66(9):3369–3384, 2025. doi: 10.1111/epi. 18475. GBD 2021 Nervous System Disorde...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.20218 2025
-
[4]
TextGrad: Automatic "Differentiation" via Text
doi: 10.48550/arXiv.2406.07496. Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024. doi: 10.1609/aaai.v38i17.29936. Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Si...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.07496 2024
-
[5]
Appendix A: Extended Related Work
-
[6]
Appendix B: Clinical Cohorts and Distribution Shift
-
[7]
Appendix C: Baseline Definitions
-
[8]
Appendix D: Interpreting the Main-Results Evaluation
-
[9]
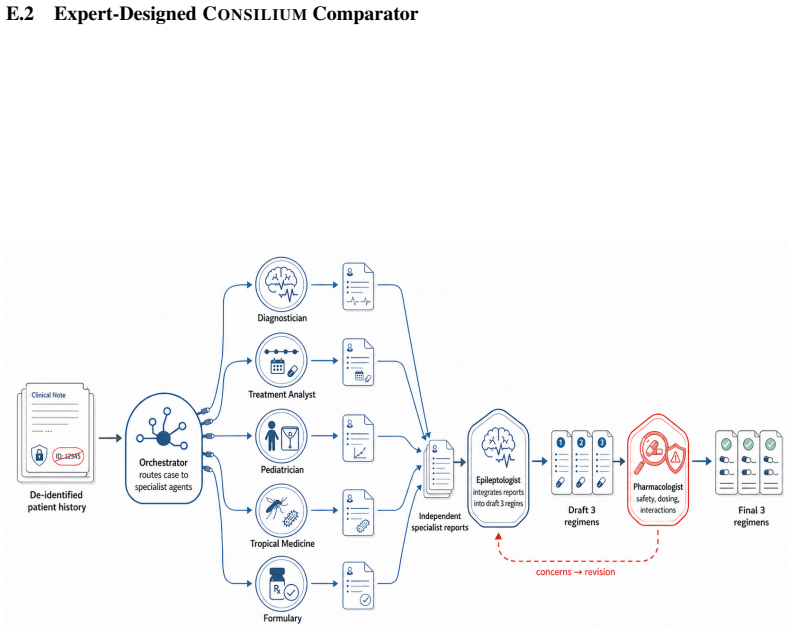
Appendix E: Single-Agent Audit and Expert System CONSILIUM
-
[10]
Appendix F: Cross-Model Transfer Learning
-
[11]
Appendix G: Additional Open Source Model Experiments
-
[12]
Appendix H: MANANAComponent Ablations
-
[13]
Appendix I: Clinician Review of MANANA
-
[14]
Appendix J: MANANABayesian Prompt Averaging Ablations
-
[15]
Appendix K: MIMIC-IV
-
[16]
Appendix L: CONSILIUMCouncil Ablations
-
[17]
Agreed with both LLM and physician,
Appendix M: Learned Artifacts Across Optimization Methods. 15 A Extended Related Work This appendix expands the related-work discussion of Section 5, covering the broader literature in clinical LLM decision support, prompt optimization and self-improving agents, and uncertainty quantification. A.1 Clinical LLM Decision Support Large language models have s...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.