Fleet: Few Shots Lead Effective AI-generated Image Detection
Pith reviewed 2026-07-01 06:30 UTC · model grok-4.3
The pith
Constrained routing correction in decoupled subspaces lets 10-shot adaptation restore AI image detection performance against new generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
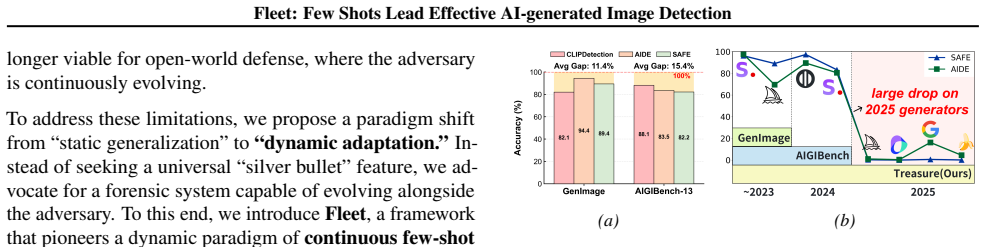
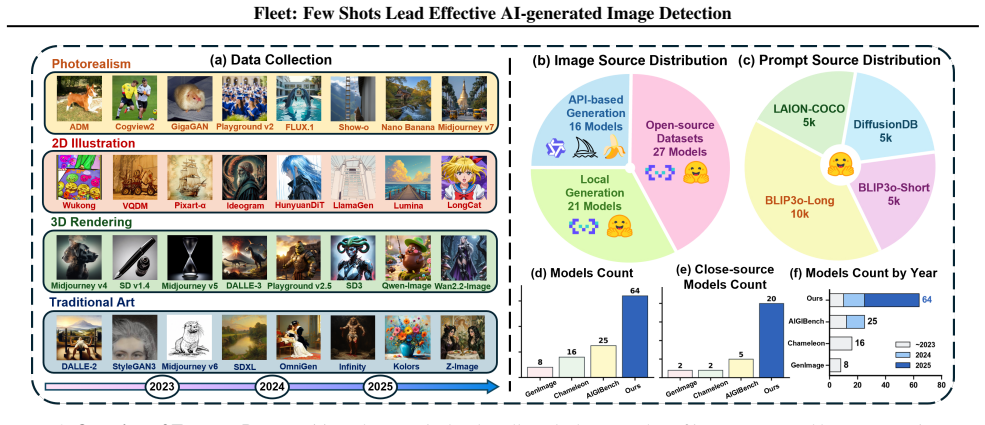
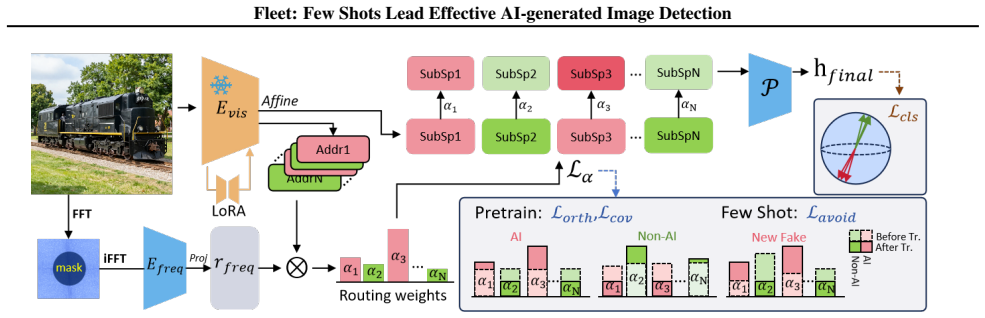
The paper claims that replacing unconstrained feature updates with constrained routing correction enables effective few-shot alignment to new generative threats, where avoidance routing redirects novel AI samples away from Non-AI-dominated routes inside decoupled subspaces, as shown by large gains on the Treasure benchmark spanning 64 models and 360k images.
What carries the argument
Constrained routing correction that redirects novel AI samples away from Non-AI-dominated routes within decoupled subspaces.
If this is right
- Static detection methods that rely on invariant artifacts suffer catastrophic drops against generators released after training data collection.
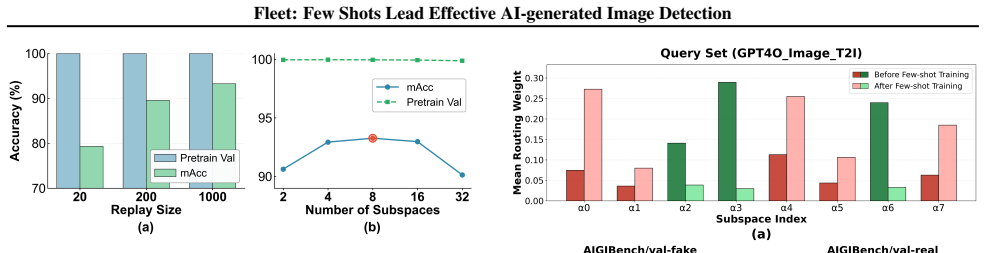
- 10-shot adaptation using routing correction raises accuracy from 20.4 percent to 73.1 percent on Doubao Seedream 4.0.
- The Treasure benchmark of 64 models and 360k images exposes the gap between laboratory saturation and open-world performance.
- Dynamic adaptation supports continuous evolution against commercial closed-source engines without full retraining.
Where Pith is reading between the lines
- Detection pipelines may need built-in mechanisms to discover and stabilize new subspaces on the fly as generators appear.
- The same routing-correction idea could apply to other domains where adversaries evolve faster than labeled data can be collected.
- Long-term monitoring of subspace stability across successive 10-shot updates would test whether the method scales beyond single-adaptation episodes.
Load-bearing premise
That the decoupled subspaces and the avoidance routing mechanism can be identified and stabilized from only 10 new samples without creating failures on the original distribution or on future generators.
What would settle it
Measuring whether accuracy on a new generator outside the 10-shot set falls below 40 percent after adaptation, or whether accuracy on the original held-out test set drops after the routing correction is applied.
Figures

read the original abstract
AI-generated image (AIGI) detection is undergoing a critical transition from laboratory benchmarks to open-world adversarial defense. The prevalent paradigm focuses on finding static feature spaces, assuming that some invariant artifacts learned from historical data can achieve universal zero-shot generalization. While achieving saturation on several AIGI benchmarks, this static hypothesis suffers a severe performance drop against rapidly evolving generators (e.g., SD3, Nano Banana Pro). To address these limitations, we propose that the field should expand beyond "static generalization" to a new paradigm of "dynamic adaptation". We introduce Fleet, a framework that pioneers a dynamic paradigm of continuous few-shot evolution, enabling rapid alignment with emerging generative threats. Fleet improves few-shot adaptation by replacing unconstrained feature updates with constrained routing correction, where avoidance routing redirects novel AI samples away from Non-AI-dominated routes within decoupled subspaces. To validate this, we present Treasure, a benchmark spanning 64 models and 360k images, featuring diverse architectures and 20 closed-source commercial engines. Experiments reveal that while static SOTA methods fail catastrophically on modern generators, Fleet restores performance from 20.4% to 73.1% with only 10-shot adaptation on "Doubao Seedream 4.0". Code and data are available at https://github.com/ICTMCG/Fleet .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Fleet, a framework for dynamic few-shot adaptation in AI-generated image detection. It argues that static feature spaces fail against new generators and introduces constrained routing correction in decoupled subspaces, where avoidance routing redirects novel AI samples away from Non-AI-dominated routes. The central empirical claim is restoration of accuracy from 20.4% to 73.1% with 10-shot adaptation on Doubao Seedream 4.0, validated on the new Treasure benchmark spanning 64 models and 360k images.
Significance. If the result holds, the work would be significant for advocating a shift from static generalization to continuous dynamic adaptation in open-world AIGI detection, a timely concern given evolving generators. The Treasure benchmark, covering diverse architectures and commercial engines, represents a useful community resource. The reported gains highlight the potential of constrained adaptation, though their broader applicability depends on the stability of the proposed mechanism.
major comments (2)
- [Abstract] Abstract: The avoidance routing mechanism within decoupled subspaces is described only at a high level, with no details on how the subspaces are discovered, how Non-AI-dominated routes are identified, or how the routing correction is computed and stabilized from exactly 10 samples. This mechanism is load-bearing for the central claim of the 20.4% to 73.1% performance restoration.
- [Experiments] Experiments: The reported accuracies on Doubao Seedream 4.0 and across the Treasure benchmark are given without error bars, details on 10-shot selection or splits, or ablation studies isolating the effect of the routing correction versus unconstrained updates. This undermines evaluation of the cross-generator claims.
minor comments (1)
- [Abstract] The abstract provides a GitHub link for code and data; ensure the repository includes full experimental protocols, benchmark splits, and implementation of the subspace discovery procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The avoidance routing mechanism within decoupled subspaces is described only at a high level, with no details on how the subspaces are discovered, how Non-AI-dominated routes are identified, or how the routing correction is computed and stabilized from exactly 10 samples. This mechanism is load-bearing for the central claim of the 20.4% to 73.1% performance restoration.
Authors: The abstract is intentionally concise, but Section 3.2 of the manuscript details subspace discovery via principal component analysis on the feature extractor, identification of Non-AI-dominated routes by majority vote on routing statistics from the base training set, and the exact formulation of the constrained routing correction (including the avoidance term and its stabilization via a small regularization coefficient fitted on the 10-shot support set). We will expand the abstract with a one-sentence pointer to these elements for improved readability. revision: partial
-
Referee: [Experiments] Experiments: The reported accuracies on Doubao Seedream 4.0 and across the Treasure benchmark are given without error bars, details on 10-shot selection or splits, or ablation studies isolating the effect of the routing correction versus unconstrained updates. This undermines evaluation of the cross-generator claims.
Authors: We agree that error bars, explicit 10-shot sampling protocol (random stratified selection with fixed seeds), train/validation splits on the support set, and ablations contrasting constrained routing against unconstrained fine-tuning are currently missing. These will be added in the revision, including standard deviations over five independent 10-shot draws and a dedicated ablation table. revision: yes
Circularity Check
No circularity: empirical adaptation method with independent benchmark validation
full rationale
The paper presents Fleet as an empirical framework for few-shot adaptation in AIGI detection, replacing unconstrained updates with constrained routing correction in decoupled subspaces. No equations, fitted parameters, or derivations are described that reduce the reported accuracy gains (e.g., 20.4% to 73.1%) to the same inputs by construction. The Treasure benchmark (64 models, 360k images) and 10-shot results on Doubao Seedream 4.0 are presented as external validation rather than self-referential fits. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The derivation chain is self-contained as a proposed method tested on new data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature space contains identifiable Non-AI-dominated routes that can be redirected via constrained updates
invented entities (1)
-
avoidance routing in decoupled subspaces
no independent evidence
Reference graph
Works this paper leans on
-
[1]
HunyuanImage 3.0 Technical Report
URLhttps://arxiv.org/abs/2509.23951. Chang, H., Zhang, H., Jiang, L., Liu, C., and Freeman, W. T. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11315–11325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Cozzolino, D., Poggi, G., Corvi, R., Nießner, M., and Ver- doliva, L
doi: 10.1109/ CVPR.2018.00916. Cozzolino, D., Poggi, G., Corvi, R., Nießner, M., and Ver- doliva, L. Raising the bar of ai-generated image detection with clip. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 4356–4366,
-
[3]
doi: 10.1109/CVPRW63382.2024. 00439. DeepFloyd. DeepFloyd. https://github.com/dee p-floyd/IF,
-
[4]
URL https://arxiv.org/abs/2504.11346. Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y . Generative adversarial nets. InAdvances in Neural Information Processing Systems, pp. 2672–2680,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
doi: 10.1109/CVPR52688.2022.01043. guangyil. Laion-coco subset with aesthetic and watermark scores. Hugging Face Dataset,
-
[6]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
doi: 10.1109/CVPR52729.2023.00976. Karras, T., Aila, T., Laine, S., and Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. InProceedings of the International Conference on Learning Representations,
-
[7]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Li, D., Kamko, A., Sabet, A., Akhgari, E., Xu, L., and Doshi, S. Playground v2. URL [https://huggingfac e.co/playgroundai/playground-v2-1024p x-aesthetic](https://huggingface.co/p laygroundai/playground-v2-1024px-aes thetic). Li, D., Kamko, A., Akhgari, E., Sabet, A., Xu, L., and Doshi, S. Playground v2.5: Three insights towards enhancing aesthetic qualit...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
doi: 10.1109/CVPR52734.2025.00289. Nichol, A. Q., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., Mcgrew, B., Sutskever, I., and Chen, M. Glide: Towards photorealistic image generation and edit- ing with text-guided diffusion models. InProceedings of the International Conference on Machine Learning, pp. 16784–16804. PMLR,
-
[9]
doi: 10.1109/CVPR52729.2023.02345. OpenAI. Dall-e 3 technical report. https://openai.c om/index/dall-e-3/,
-
[10]
URL https://ar xiv.org/abs/2410.21276. OpenAI. Gpt image 1.5: Openai’s latest image generation model. OpenAI Official Documentation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Hierarchical Text-Conditional Image Generation with CLIP Latents
URL https://arxiv.org/ab s/2204.06125. Rebuffi, S.-A., Kolesnikov, A., Sperl, G., and Lampert, C. H. icarl: Incremental classifier and representation learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2001–2010,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[12]
doi: 10.1109/CVPR52688.2022.01042. Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Den- ton, E., Ghasemipour, S. K. S., Gontijo-Lopes, R., Ayan, B. K., Salimans, T., Ho, J., Fleet, D. J., and Norouzi, M. Photorealistic text-to-image diffusion models with deep language understanding. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.),Advance...
-
[13]
URLhttps://arxiv.org/abs/2508.10104. Stability AI. Stable diffusion v2.1 and dreamstudio updates. https://stability.ai/blog/stablediff usion2-1-release7-dec-2022,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Tan, C., Zhao, Y ., Wei, S., Gu, G., Liu, P., and Wei, Y . Frequency-aware deepfake detection: Improving gener- alizability through frequency space domain learning. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 38, pp. 5052–5060, 2024a. Tan, C., Zhao, Y ., Wei, S., Gu, G., Liu, P., and Wei, Y . Rethinking the up-sampling opera...
-
[15]
doi: 10.1109/CVPR52688.2022.01602. Team Seedream, Chen, Y ., Gao, Y ., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y ., Jian, X., Kuang, H., Lai, Z., Li, F., Li, L., Lian, X., Liao, C., Liu, L., Liu, W., Lu, Y ., Luo, Z., Ou, T., Shi, G., Shi, Y ., Sun, S., Tian, Y ., Tian, Z., Wang, P., Wang, R., Wang, X., Wang, Y ., Wu, G., Wu, J., W...
-
[16]
URL https://arxiv.org/abs/2509.20427. Team Wan, Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T....
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
doi: 10.1109/CVPR42600.2020.008
-
[18]
Wang, Z., Bao, J., Zhou, W., Wang, W., Hu, H., Chen, H., and Li, H. Dire for diffusion-generated image detection. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pp. 22445–22455, 2023a. doi: 10.1109/ICCV51070.2023.02051. Wang, Z. J., Montoya, E., Munechika, D., Yang, H., Hoover, B., and Chau, D. H. Diffusiondb: A large-scale p...
-
[19]
Zhang, H., He, Q., Bi, X., Li, W., Liu, B., and Xiao, B. Towards universal ai-generated image detection by variational information bottleneck network. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 23828–23837, 2025a. doi: 10.1109/CVPR52734.2025.02219. Zhang, Y ., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., ...
-
[20]
However, in the first 5 epochs, we setλcls = 0to prioritize learning the correct routing path. A.1.4. PREPROCESSING& HARDWARE The high-frequency component branch employs random cropping during training and center cropping during testing. All experiments are conducted on 8 NVIDIA GeForce RTX 3090 GPUs. Under this setup, pre-training requires approximately ...
2025
-
[21]
SUPERMERCATI BASKO
Table 6.Exemplar prompts from the four subsets of the Treasure library. Subset Exemplar Prompts Authentic User Input(1)Emma Watson as migrant mother, 1936 photo by Dorothea Lange (2)fantasy character portrait photo. female dwarf. short, broad, extremely muscular, broad face resembles cara delevingne but very squat, elaborately braided orangepink hair. (3)...
1936
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.