AETDICE: Unified Framework and Offline Optimization for Nonlinear Multi-Objective RL
Pith reviewed 2026-07-01 06:44 UTC · model grok-4.3
The pith
The Aggregation-Expectation-Transformation decomposition unifies nonlinear multi-objective reinforcement learning under one framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decomposing scalarization into Aggregation, Expectation, and Transformation components, the AET framework unifies the Scalarized Expected Return and Expected Scalarized Return criteria for nonlinear multi-objective RL. This removes the requirement for global-level optimization or non-Markovian policies. AETDICE then applies DICE-style density-ratio estimation in an augmented state space to enable tractable sample-based optimization of AET objectives from static datasets, capturing trade-offs that prior methods miss.
What carries the argument
The tripartite Aggregation-Expectation-Transformation (AET) decomposition of scalarization, which separates nonlinear preference handling into distinct stages to unify prior SER and ESR approaches.
If this is right
- Nonlinear preferences become optimizable with Markovian policies and without separate global search.
- Offline RL methods using density-ratio estimation apply directly to general AET objectives from static data.
- Methods limited to only SER or only ESR cannot capture the full set of trade-offs permitted by the AET structure.
- Sample-based optimization of nonlinear MORL objectives becomes feasible without online interaction.
Where Pith is reading between the lines
- Designers could create new scalarization functions simply by selecting different operators for the aggregation or transformation stages.
- The augmented-state density-ratio technique may apply to other offline problems whose objectives deviate from standard expected return.
- Empirical tests on risk-sensitive or fairness benchmarks would check whether the claimed unification produces measurable improvements over single-paradigm baselines.
Load-bearing premise
Every relevant nonlinear preference can be expressed exactly by some choice of aggregation, expectation, and transformation functions inside the AET decomposition.
What would settle it
A concrete nonlinear preference function that cannot be written as any composition of aggregation, expectation, and transformation, or an offline dataset on which the AETDICE optimum deviates from the true AET value.
Figures








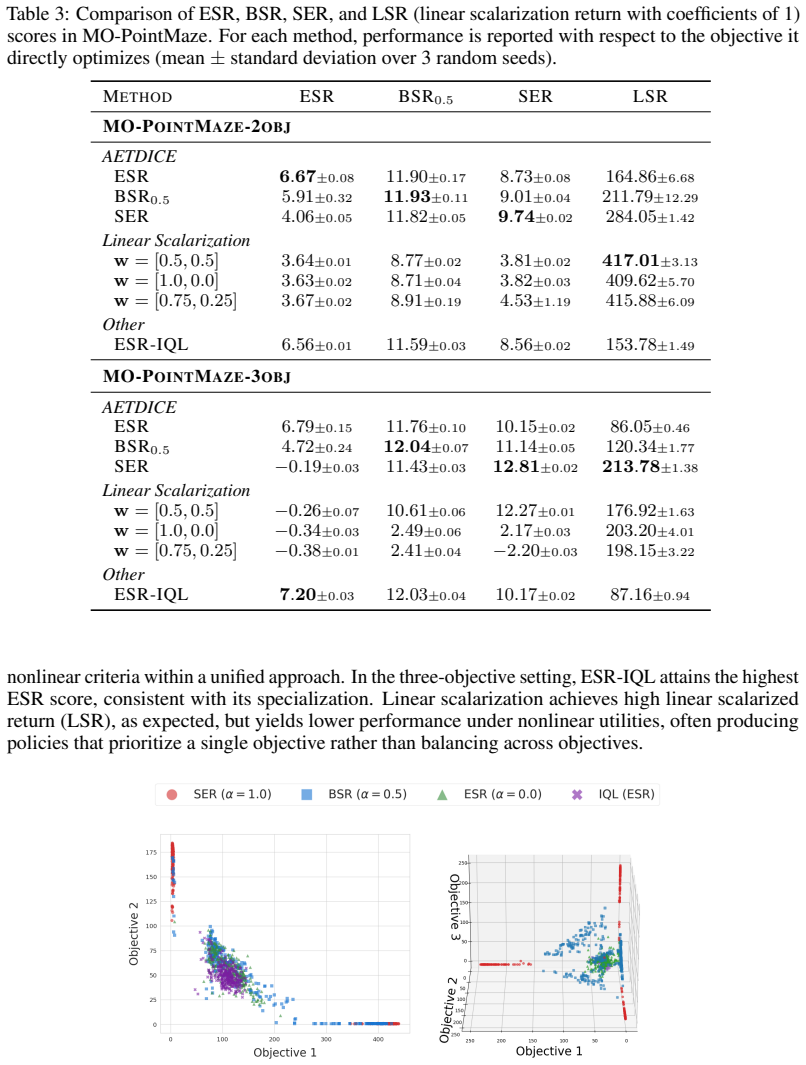
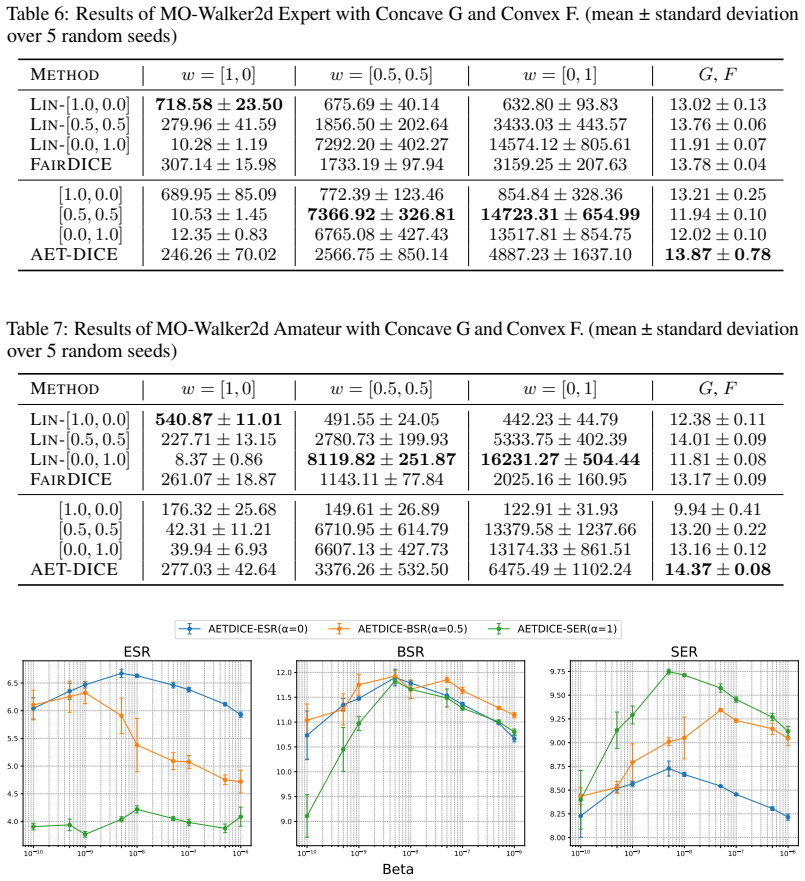
read the original abstract
Optimizing nonlinear preferences in multi-objective reinforcement learning (MORL) is essential for capturing complex trade-offs like risk aversion or fairness. However, such non-linearity has historically bifurcated nonlinear MORL objectives into two distinct paradigms: Scalarized Expected Return (SER) and Expected Scalarized Return (ESR). While SER requires global-level optimization and ESR requires non-Markovian policies, leading to fragmented optimization strategies, we bridge this divide through the Aggregation-Expectation-Transformation (AET) framework. By unifying both criteria through a tripartite decomposition of scalarization, AET provides a principled foundation for general nonlinear MORL. Building on this framework, we propose AETDICE, a tractable offline RL algorithm for AET objectives. By utilizing DICE-style density-ratio estimation in an augmented state space, AETDICE enables sample-based optimization from static datasets. Our framework resolves long-standing barriers and captures respective trade-offs induced by AET framework, which existing methods fail to address.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the Aggregation-Expectation-Transformation (AET) framework that unifies Scalarized Expected Return (SER) and Expected Scalarized Return (ESR) in nonlinear multi-objective RL via a tripartite decomposition of scalarization, thereby providing a principled foundation for general nonlinear preferences. It further proposes AETDICE, an offline algorithm that uses DICE-style density-ratio estimation in an augmented state space to enable sample-based optimization of AET objectives from static datasets.
Significance. If the AET decomposition is valid and the algorithm converges on the claimed objectives, the work would offer a meaningful unification of previously bifurcated approaches in nonlinear MORL, potentially allowing a single framework to handle complex trade-offs such as risk aversion and fairness without separate global or non-Markovian machinery, and extending offline RL techniques to this setting.
major comments (2)
- [Abstract] Abstract, paragraph 3: The claim that the tripartite decomposition unifies SER and ESR such that general nonlinear scalarizations can be optimized via the AET structure alone (without non-Markovian policies or global optimization) is load-bearing for the central unification result, yet no explicit form of the decomposition, derivation, or proof is supplied to show it recovers both criteria or avoids the historical requirements for arbitrary nonlinear utilities.
- [Abstract] Abstract: No indication is given of how the AET framework ensures the decomposition captures all relevant nonlinear preferences (e.g., risk, fairness) while remaining Markovian and amenable to the stated offline procedure; this assumption is required for the assertion that existing methods fail to address the induced trade-offs.
minor comments (1)
- The abstract states that AETDICE 'captures respective trade-offs induced by AET framework' but provides no concrete examples of those trade-offs or baseline comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major comment below, clarifying where the manuscript provides the requested details and indicating revisions to improve the abstract's self-containment.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 3: The claim that the tripartite decomposition unifies SER and ESR such that general nonlinear scalarizations can be optimized via the AET structure alone (without non-Markovian policies or global optimization) is load-bearing for the central unification result, yet no explicit form of the decomposition, derivation, or proof is supplied to show it recovers both criteria or avoids the historical requirements for arbitrary nonlinear utilities.
Authors: The explicit form of the AET decomposition, along with its derivation and proofs, is provided in Section 3 of the manuscript (with full details and recovery of SER/ESR in Appendix B). The tripartite structure (Aggregation-Expectation-Transformation) is shown to recover both criteria while enabling Markovian policies via state augmentation, avoiding the need for global optimization or non-Markovian policies for general nonlinear utilities. We will revise the abstract to include a concise reference to this decomposition and its properties. revision: yes
-
Referee: [Abstract] Abstract: No indication is given of how the AET framework ensures the decomposition captures all relevant nonlinear preferences (e.g., risk, fairness) while remaining Markovian and amenable to the stated offline procedure; this assumption is required for the assertion that existing methods fail to address the induced trade-offs.
Authors: Section 4 provides concrete examples demonstrating how AET captures nonlinear preferences such as risk aversion (via concave transformations) and fairness (via appropriate aggregation), while the augmented state space preserves the Markov property. Section 5 details the AETDICE offline procedure and its applicability. This explains the limitations of prior methods. We will add a brief clarifying phrase to the abstract. revision: partial
Circularity Check
No circularity: AET unification presented as independent framework without reduction to fitted inputs or self-citations
full rationale
The abstract introduces the Aggregation-Expectation-Transformation (AET) tripartite decomposition as a proposed unification of SER and ESR for nonlinear MORL, followed by the AETDICE algorithm using DICE-style estimation. No equations, self-citations, or derivations are shown that would make the claimed unification equivalent to its inputs by construction, a fitted parameter renamed as prediction, or a load-bearing self-citation chain. The central claim remains a distinct modeling proposal without the specific reductions required for circularity flags under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-objective reinforcement learning using sets of pareto dominating policies.The Journal of Machine Learning Research, 15(1):3483–3512, 2014
Kristof Van Moffaert and Ann Nowé. Multi-objective reinforcement learning using sets of pareto dominating policies.The Journal of Machine Learning Research, 15(1):3483–3512, 2014
2014
-
[2]
Regret minimization for reinforcement learning with vectorial feedback and complex objectives.Advances in Neural Information Processing Systems, 32, 2019
Wang Chi Cheung. Regret minimization for reinforcement learning with vectorial feedback and complex objectives.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[3]
A generalized algorithm for multi- objective reinforcement learning and policy adaptation.Advances in neural information pro- cessing systems, 32, 2019
Runzhe Yang, Xingyuan Sun, and Karthik Narasimhan. A generalized algorithm for multi- objective reinforcement learning and policy adaptation.Advances in neural information pro- cessing systems, 32, 2019
2019
-
[4]
A survey of multi- objective sequential decision-making.Journal of Artificial Intelligence Research, 48:67–113, 2013
Diederik M Roijers, Peter Vamplew, Shimon Whiteson, and Richard Dazeley. A survey of multi- objective sequential decision-making.Journal of Artificial Intelligence Research, 48:67–113, 2013
2013
-
[5]
Multi-objective reinforcement learning with non-linear scalarization
Mridul Agarwal, Vaneet Aggarwal, and Tian Lan. Multi-objective reinforcement learning with non-linear scalarization. InProceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, pages 9–17, 2022
2022
-
[6]
Multi-objective reinforcement learning for the expected utility of the return
Diederik Roijers, Denis Steckelmacher, and Ann Nowé. Multi-objective reinforcement learning for the expected utility of the return. InAdaptive Learning Agents Workshop 2018, 2018
2018
-
[7]
Conor F Hayes, Roxana R˘adulescu, Eugenio Bargiacchi, Johan Källström, Matthew Macfarlane, Mathieu Reymond, Timothy Verstraeten, Luisa M Zintgraf, Richard Dazeley, Fredrik Heintz, et al. A practical guide to multi-objective reinforcement learning and planning.arXiv preprint arXiv:2103.09568, 2021
-
[8]
Expected scalarised returns dominance: a new solution concept for multi-objective decision making.Neural Computing and Applications, 37(19):13079–13099, 2025
Conor F Hayes, Timothy Verstraeten, Diederik M Roijers, Enda Howley, and Patrick Mannion. Expected scalarised returns dominance: a new solution concept for multi-objective decision making.Neural Computing and Applications, 37(19):13079–13099, 2025
2025
-
[9]
Baiting Zhu, Meihua Dang, and Aditya Grover. Scaling pareto-efficient decision making via offline multi-objective rl.arXiv preprint arXiv:2305.00567, 2023
-
[10]
Policy-regularized offline multi-objective reinforcement learning
Qian Lin, Chao Yu, Zongkai Liu, and Zifan Wu. Policy-regularized offline multi-objective reinforcement learning. InProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pages 1201–1209, 2024
2024
-
[11]
Woosung Kim, Jinho Lee, Jongmin Lee, and Byung-Jun Lee. Fairdice: Fairness-driven offline multi-objective reinforcement learning.arXiv preprint arXiv:2506.08062, 2025. 10
-
[12]
A utility-based analysis of equilibria in multi-objective normal-form games.The Knowledge Engineering Review, 35:e32, 2020
Roxana R˘adulescu, Patrick Mannion, Yijie Zhang, Diederik M Roijers, and Ann Nowé. A utility-based analysis of equilibria in multi-objective normal-form games.The Knowledge Engineering Review, 35:e32, 2020
2020
-
[13]
Welfare and fairness in multi- objective reinforcement learning
Ziming Fan, Nianli Peng, Muhang Tian, and Brandon Fain. Welfare and fairness in multi- objective reinforcement learning. InProceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, pages 1991–1999, 2023
2023
-
[14]
The nash social welfare function.Econometrica: Journal of the Econometric Society, pages 423–435, 1979
Mamoru Kaneko and Kenjiro Nakamura. The nash social welfare function.Econometrica: Journal of the Econometric Society, pages 423–435, 1979
1979
-
[15]
Fair deep reinforcement learning with preferential treatment
Guanbao Yu, Umer Siddique, and Paul Weng. Fair deep reinforcement learning with preferential treatment. InECAI, pages 2922–2929, 2023
2023
-
[16]
Learning fair pareto-optimal policies in multi- objective reinforcement learning
Umer Siddique, Peilang Li, and Yongcan Cao. Learning fair pareto-optimal policies in multi- objective reinforcement learning. InThe Seventeenth Workshop on Adaptive and Learning Agents
-
[17]
Multi-objective reinforcement learning with nonlinear preferences: Provable approximation for maximizing expected scalarized return
Nianli Peng, Muhang Tian, and Brandon Fain. Multi-objective reinforcement learning with nonlinear preferences: Provable approximation for maximizing expected scalarized return. InProceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, pages 1632–1640, 2025
2025
-
[18]
Nianli Peng and Brandon Fain. Nonlinear multi-objective reinforcement learning with provable guarantees.arXiv preprint arXiv:2311.02544, 2023
-
[19]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning.arXiv preprint arXiv:2110.06169, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Optidice: Offline policy optimization via stationary distribution correction estimation
Jongmin Lee, Wonseok Jeon, Byungjun Lee, Joelle Pineau, and Kee-Eung Kim. Optidice: Offline policy optimization via stationary distribution correction estimation. InInternational Conference on Machine Learning, pages 6120–6130. PMLR, 2021
2021
-
[21]
The max-min formulation of multi-objective reinforcement learning: From theory to a model-free algorithm
Giseung Park, Woohyeon Byeon, Seongmin Kim, Elad Havakuk, Amir Leshem, and Youngchul Sung. The max-min formulation of multi-objective reinforcement learning: From theory to a model-free algorithm. InInternational Conference on Machine Learning, pages 39616–39642. PMLR, 2024
2024
-
[22]
Fair end-to-end window-based congestion control.IEEE/ACM Transactions on networking, 8(5):556–567, 2002
Jeonghoon Mo and Jean Walrand. Fair end-to-end window-based congestion control.IEEE/ACM Transactions on networking, 8(5):556–567, 2002
2002
-
[23]
Scalarized multi-objective rein- forcement learning: Novel design techniques
Kristof Van Moffaert, Madalina M Drugan, and Ann Nowé. Scalarized multi-objective rein- forcement learning: Novel design techniques. In2013 IEEE symposium on adaptive dynamic programming and reinforcement learning (ADPRL), pages 191–199. IEEE, 2013
2013
-
[24]
Efficient reinforcement learning with multiple reward functions for randomized controlled trial analysis
Daniel J Lizotte, Michael H Bowling, and Susan A Murphy. Efficient reinforcement learning with multiple reward functions for randomized controlled trial analysis. InICML, volume 10, pages 695–702, 2010
2010
-
[25]
Hypervolume-based multi-objective reinforcement learning
Kristof Van Moffaert, Madalina M Drugan, and Ann Nowé. Hypervolume-based multi-objective reinforcement learning. InInternational Conference on Evolutionary Multi-Criterion Optimiza- tion, pages 352–366. Springer, 2013
2013
-
[26]
On the limitations of markovian rewards to express multi- objective, risk-sensitive, and modal tasks
Joar Skalse and Alessandro Abate. On the limitations of markovian rewards to express multi- objective, risk-sensitive, and modal tasks. InUncertainty in Artificial Intelligence, pages 1974–1984. PMLR, 2023
1974
-
[27]
Fairness in preference-based reinforcement learning.arXiv preprint arXiv:2306.09995, 2023
Umer Siddique, Abhinav Sinha, and Yongcan Cao. Fairness in preference-based reinforcement learning.arXiv preprint arXiv:2306.09995, 2023
-
[28]
Conservative q-learning for offline reinforcement learning.Advances in neural information processing systems, 33:1179– 1191, 2020
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning.Advances in neural information processing systems, 33:1179– 1191, 2020. 11
2020
-
[29]
Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
2021
-
[30]
Offline constrained multi- objective reinforcement learning via pessimistic dual value iteration.Advances in Neural Information Processing Systems, 34:25439–25451, 2021
Runzhe Wu, Yufeng Zhang, Zhuoran Yang, and Zhaoran Wang. Offline constrained multi- objective reinforcement learning via pessimistic dual value iteration.Advances in Neural Information Processing Systems, 34:25439–25451, 2021
2021
-
[31]
drop-and-die
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning, 2020. 12 A Related Works Multi-Objective Reinforcement LearningMulti-objective reinforcement learning (MORL) stud- ies sequential decision-making problems with vector-valued rewards, where no single policy is universally opti...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.