Delta-JEPA: Learning Action-Sensitive World Models via Latent Difference Decoding
Pith reviewed 2026-07-01 05:45 UTC · model grok-4.3
The pith
Reconstructing actions from latent displacements between observations prevents collapse in action-sensitive world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
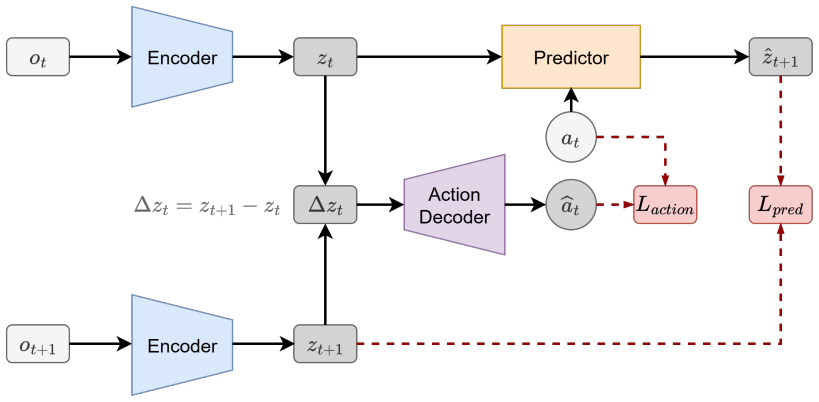
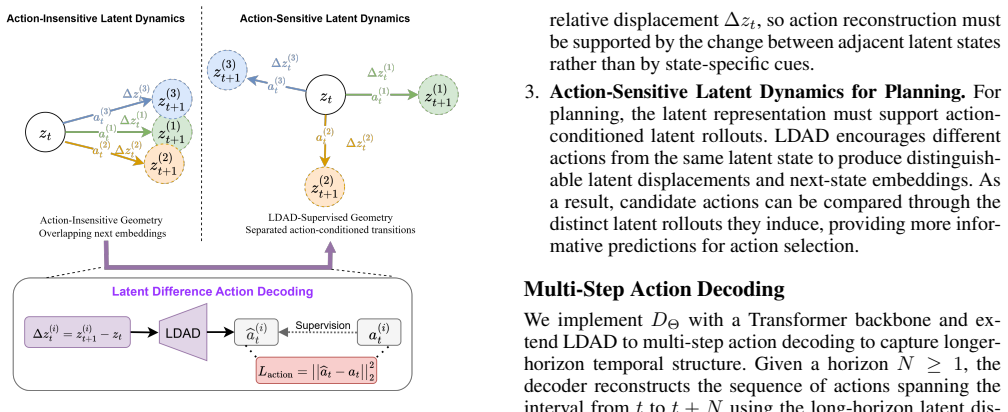
Delta-JEPA augments latent forward prediction with a Latent Difference Action Decoder (LDAD) that reconstructs the executed action from the latent displacement between consecutive observations. This displacement-level supervision directly regularizes transition geometry: adjacent embeddings cannot collapse without losing action information, and different actions are encouraged to induce distinguishable latent changes for rollout-based planning. The method uses only latent prediction and action reconstruction, avoiding pixel reconstruction and distribution-matching regularizers, and improves planning across four visual continuous-control tasks.
What carries the argument
Latent Difference Action Decoder (LDAD), which reconstructs the executed action from the latent displacement between consecutive observations to regularize transition geometry.
If this is right
- Planning performance improves over JEPA-based and representation-learning world model baselines on four visual continuous-control tasks.
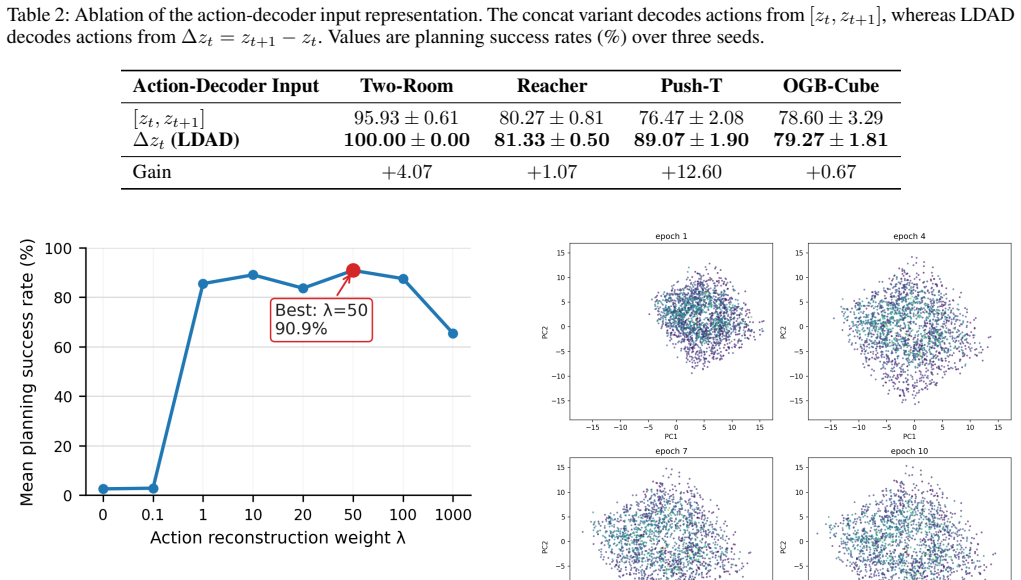
- Displacement-based action decoding is consistently more effective than endpoint concatenation in ablations.
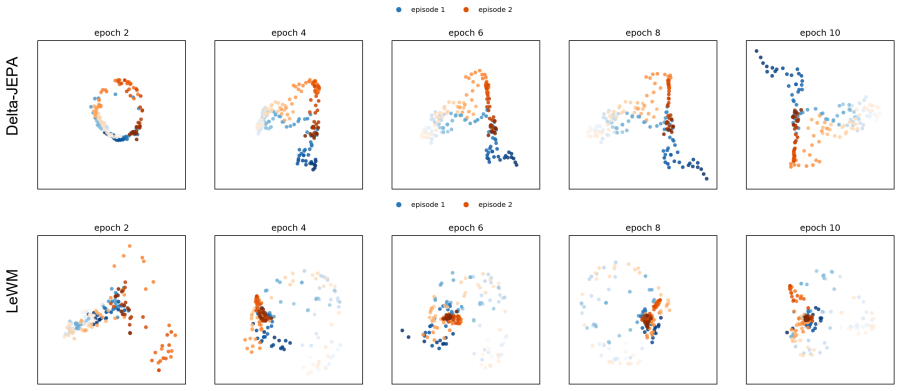
- Action-sensitivity analyses show clearer action-conditioned latent responses.
- Only latent prediction and action reconstruction suffice, without pixel reconstruction or distribution-matching regularizers.
Where Pith is reading between the lines
- The same displacement supervision could be applied to discrete-action environments to test whether collapse resistance generalizes.
- If latent displacements reliably encode action effects, the approach might reduce reliance on auxiliary regularizers in other representation-learning pipelines for control.
- Measuring the correlation between displacement magnitude and action scale in physical simulators would test whether the geometry learned here reflects real dynamics.
Load-bearing premise
Reconstructing the executed action from the latent displacement between consecutive observations will reliably prevent collapse and produce distinguishable latent changes for different actions across the evaluated tasks.
What would settle it
Training the same architecture without the displacement decoder and measuring whether latent states still collapse to action-insensitive representations while planning performance drops on the same four tasks.
Figures
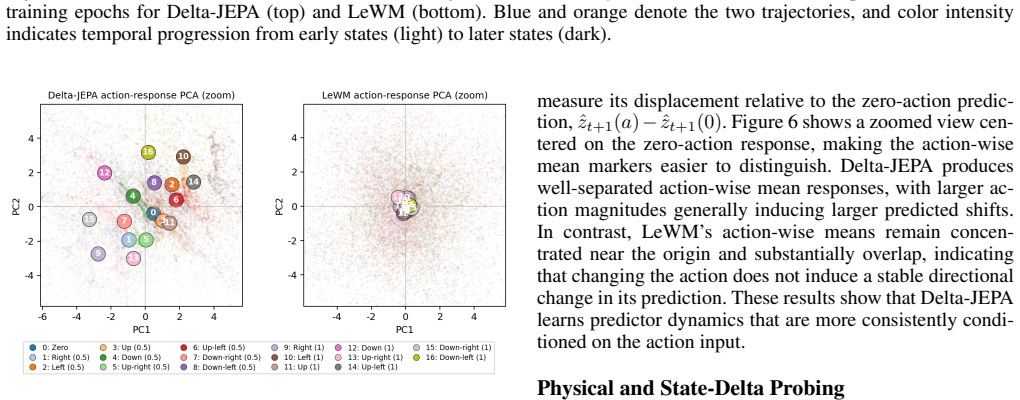
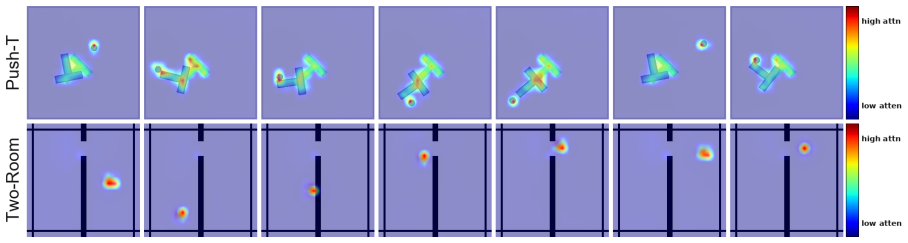
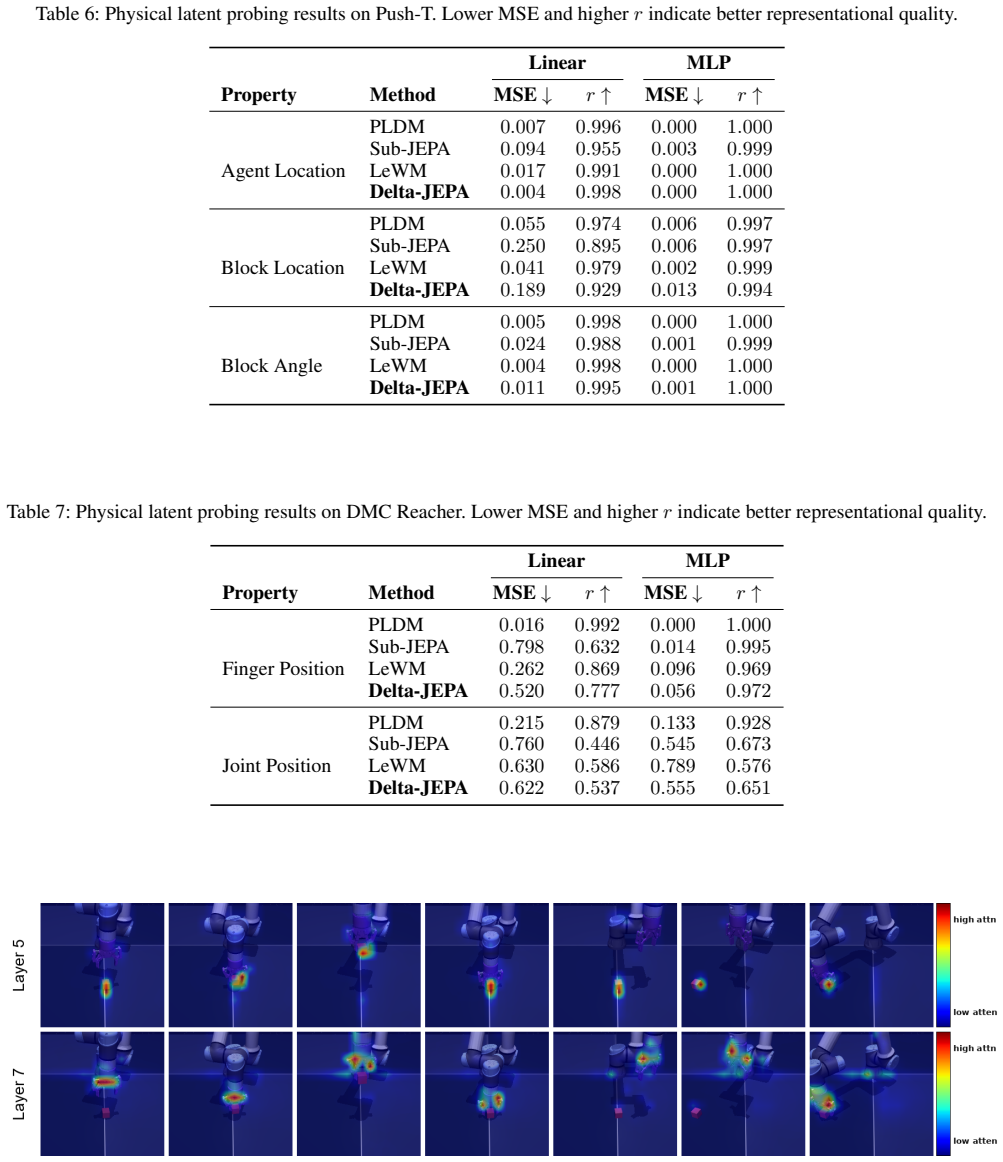
read the original abstract
Learning visual world models for planning requires compact latent dynamics that remain sensitive to actions, yet reconstruction-free joint-embedding objectives can collapse to action-insensitive representations. We propose Delta-JEPA, an end-to-end reconstruction-free world model that augments latent forward prediction with a Latent Difference Action Decoder (LDAD). Unlike inverse decoders that infer actions from concatenated endpoint embeddings, LDAD reconstructs the executed action from the latent displacement between consecutive observations. This displacement-level supervision directly regularizes transition geometry: adjacent embeddings cannot collapse without losing action information, and different actions are encouraged to induce distinguishable latent changes for rollout-based planning. Delta-JEPA uses only latent prediction and action reconstruction, avoiding pixel reconstruction and distribution-matching regularizers. Across four visual continuous-control tasks, Delta-JEPA improves planning over JEPA-based and representation-learning world model baselines. Ablations show that displacement-based action decoding is consistently more effective than endpoint concatenation, and action-sensitivity analyses show clearer action-conditioned latent responses. These results indicate that supervising latent differences is a simple and effective mechanism for collapse-resistant and action-sensitive world model learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Delta-JEPA, an end-to-end reconstruction-free world model that augments latent forward prediction with a Latent Difference Action Decoder (LDAD). LDAD reconstructs the executed action from the latent displacement between consecutive observations rather than from concatenated endpoint embeddings. The approach is claimed to directly regularize transition geometry, preventing collapse to action-insensitive representations while encouraging distinguishable latent changes for different actions. Experiments across four visual continuous-control tasks show improved planning performance over JEPA-based and representation-learning baselines, with ablations indicating that displacement-based decoding outperforms endpoint concatenation and yields clearer action-conditioned latent responses.
Significance. If the results hold, the LDAD mechanism provides a simple, reconstruction-free regularization of latent dynamics that directly ties action reconstruction error to embedding collapse, offering a lightweight alternative to pixel reconstruction or distribution-matching losses in world-model learning for planning. The internal logic is consistent (collapse increases action reconstruction error) and the reported ablations plus action-sensitivity analyses supply concrete support for the central mechanism.
minor comments (3)
- [Abstract] The abstract states improvements on 'four visual continuous-control tasks' without naming them; listing the specific environments (with references to their standard implementations) would aid immediate assessment of scope and reproducibility.
- [§3 or §4] The loss formulation for the LDAD term and its weighting relative to the latent prediction objective are not visible in the provided abstract; including the precise equations (e.g., the action reconstruction loss and any hyperparameters) in §3 or §4 would strengthen reproducibility.
- Action-sensitivity analyses are mentioned but the quantitative metric (e.g., mutual information, classification accuracy, or distance between action-conditioned displacements) is not specified; adding this detail would make the supporting evidence easier to interpret.
Simulated Author's Rebuttal
We thank the referee for the positive summary of Delta-JEPA, the assessment of its significance, and the recommendation for minor revision. The report lists no major comments, so we have no point-by-point responses to provide.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines Delta-JEPA by augmenting latent prediction with an explicit LDAD decoder that reconstructs actions from latent displacements; this is a deliberate architectural choice whose effect on collapse resistance and action sensitivity follows directly from the supervision objective rather than reducing to a fitted input or self-citation by construction. No equations, parameter-fitting procedures, or load-bearing self-citations are described that would equate the claimed improvements to the method's own inputs. The reported ablations and task results constitute independent empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
V-jepa 2: Self-supervised video models en- able understanding, prediction and planning.arXiv preprint arXiv:2506.09985. Assran, M.; Duval, Q.; Misra, I.; Bojanowski, P.; Vincent, P.; Rabbat, M.; LeCun, Y .; and Ballas, N
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
Lejepa: Provable and scalable self-supervised learning without the heuristics. arXiv preprint arXiv:2511.08544. Bardes, A.; Garrido, Q.; Ponce, J.; Chen, X.; Rabbat, M.; LeCun, Y .; Assran, M.; and Ballas, N
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Revisiting Feature Prediction for Learning Visual Representations from Video
Revisiting feature prediction for learning visual representations from video.arXiv preprint arXiv:2404.08471. Bardes, A.; Ponce, J.; and LeCun, Y
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Vi- creg: Variance-invariance-covariance regularization for self- supervised learning.arXiv preprint arXiv:2105.04906. Chi, C.; Xu, Z.; Feng, S.; Cousineau, E.; Du, Y .; Burchfiel, B.; Tedrake, R.; and Song, S
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Ha, D.; and Schmidhuber, J. 2018b. World Models.eprint arXiv: 1803.10122. Hafner, D.; Lillicrap, T.; Ba, J.; and Norouzi, M. 2019a. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603. Hafner, D.; Lillicrap, T.; Fischer, I.; Villegas, R.; Ha, D.; Lee, H.; and Davidson, J. 2019b. Learning latent dynam- ics for planni...
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[6]
Mastering Diverse Domains through World Models
Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104. Hauri, M.; and Zenke, F
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Dreamer-CDP: Im- proving Reconstruction-free World Models Via Continu- ous Deterministic Representation Prediction.arXiv preprint arXiv:2603.07083. LeCun, Y .; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
2, 2022-06-27.Open Review, 62(1): 1–62
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1): 1–62. Maes, L.; Lidec, Q. L.; Scieur, D.; LeCun, Y .; and Balestriero, R
2022
-
[9]
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312. Oquab, M.; Darcet, T.; Moutakanni, T.; V o, H.; Szafraniec, M.; Khalidov, V .; Fernandez, P.; Haziza, D.; Massa, F.; El- Nouby, A.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
DINOv2: Learning Robust Visual Features without Supervision
Dinov2: Learning robust visual fea- tures without supervision.arXiv preprint arXiv:2304.07193. Park, S.; Frans, K.; Eysenbach, B.; and Levine, S
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
InInter- national Conference on Learning Representations, volume 2025, 94937–94982
Og- bench: Benchmarking offline goal-conditioned rl. InInter- national Conference on Learning Representations, volume 2025, 94937–94982. Sobal, U.; Zhang, W.; Cho, K.; Balestriero, R.; Rudner, T. G.; and LeCun, Y
2025
-
[12]
Deepmind control suite.arXiv preprint arXiv:1801.00690. Wu, P.; Escontrela, A.; Hafner, D.; Abbeel, P.; and Gold- berg, K
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Sub-JEPA: Subspace Gaussian Regularization for Stable End-to-End World Models
Sub-JEPA: Subspace Gaussian Regulariza- tion for Stable End-to-End World Models.arXiv preprint arXiv:2605.09241. Zhou, G.; Pan, H.; Lecun, Y .; and Pinto, L
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.