Benchmarking Large Language Models on Floating-Point Error Classification
Pith reviewed 2026-07-01 05:36 UTC · model grok-4.3
The pith
Latest LLMs classify floating-point errors in C code with overall F1 above 0.88 on a new 1130-sample benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
InterFLOPBench treats floating-point error detection as multi-label classification across cancellation, comparison, division by zero, overflow, underflow and NaN; the evaluation shows the strongest models (Qwen 3 32b, Gemini 2.5 Flash, Phi 4 Reasoning, DeepSeek R1T2, gpt-oss 20b and 120b) reach greater than 0.88 overall F1-score, with clear gaps between explicit operations and subtler numerical phenomena.
What carries the argument
InterFLOPBench benchmark of 1130 labeled C samples used as a multi-label classification task measured by F1-score.
If this is right
- Top models can already serve as static checkers for the easier error categories.
- Performance remains limited on cancellation and underflow, so those categories still need human review or complementary tools.
- The benchmark supplies a repeatable way to track future LLM progress on numerical-error detection.
- Explicit operations such as division by zero are classified more reliably than phenomena that require understanding numerical scale.
Where Pith is reading between the lines
- Developers could embed the strongest models inside IDEs to flag potential floating-point issues during editing.
- Training data that emphasizes numerical stability examples might narrow the gap between easy and hard error types.
- The benchmark could be extended with larger or more diverse C codebases to test whether the current scores hold outside the original 90 kernels.
Load-bearing premise
The 1130 samples and their error-category labels accurately represent real floating-point mistakes in C programs and carry no annotation bias.
What would settle it
Running the same 14 models on a fresh collection of real-world C programs whose floating-point errors have been independently verified by dynamic analysis or expert review and finding overall F1 below 0.7.
Figures
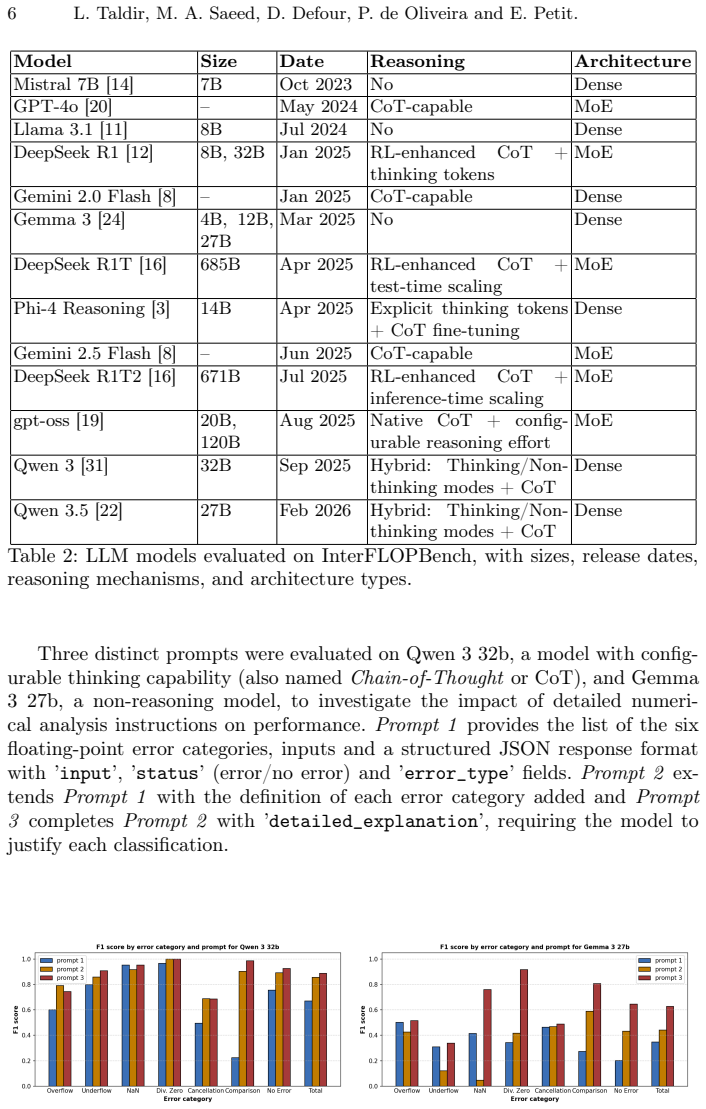
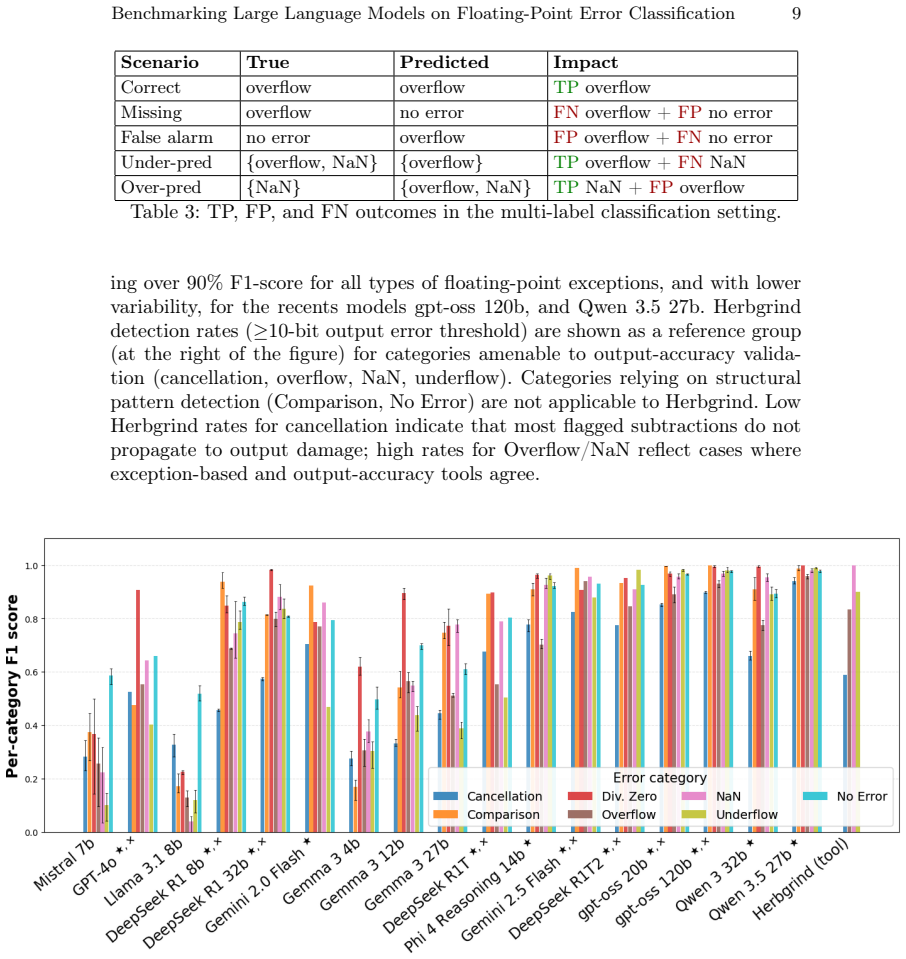
read the original abstract
This paper investigates the capability of Large Language Models (LLMs) to detect and classify floating-point errors statically in software code. We introduce InterFLOPBench, a benchmark of 90 C kernels with 1 130 test samples designed to evaluate LLMs across six categories of floating-point error: cancellation, comparison, division by zero, overflow, underflow and NaN, compared across 14 LLMs. The evaluation framework treats floating-point error detection as a multi-label classification problem and employs the F1-score metric to measure performance. Results demonstrate that latest models (Qwen 3 32b, Gemini 2.5 Flash, Phi 4 Reasoning, DeepSeek R1T2, and gpt-oss 20b and 120b) achieve a performance greater than 0.88 overall F1-score. Performance varies between error categories, between explicit operations such as division by zero (Average F1-score: 0.8479) and more subtle numerical phenomena such as underflow (Average F1-score: 0.6059) and cancellation (Average F1-score: 0.6164).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InterFLOPBench, a benchmark of 90 C kernels producing 1130 multi-label test samples across six floating-point error categories (cancellation, comparison, division by zero, overflow, underflow, NaN). It evaluates 14 LLMs on static detection/classification treated as multi-label classification, reporting F1 scores with top models (Qwen 3 32b, Gemini 2.5 Flash, etc.) exceeding 0.88 overall F1; performance is higher on explicit errors (division by zero: avg. F1 0.8479) than subtle ones (underflow: 0.6059; cancellation: 0.6164).
Significance. If the ground-truth labels prove reliable, the work supplies the first systematic empirical comparison of LLMs on floating-point error classification in C code, quantifying the gap between explicit and subtle numerical issues and thereby providing a concrete baseline for future LLM-assisted static analysis tools.
major comments (2)
- [§3] §3 (Benchmark Construction): The manuscript provides no description of the kernel selection criteria, the procedure used to identify and annotate the 1130 samples for the six categories, or how overlapping labels were resolved in the multi-label setup. Without this, the F1 scores in §5 cannot be interpreted as measurements of model capability rather than artifacts of annotation.
- [§5] §5 (Results): The reported category-wise averages (division by zero 0.8479 vs. underflow 0.6059) rest entirely on the correctness of the 1130 labels; the absence of any inter-annotator agreement, expert review, or external validation means the central claim that models handle explicit errors better than subtle ones is not yet supported by verifiable evidence.
minor comments (2)
- The abstract states 1 130 samples but the text should consistently use either “1130” or “1,130” throughout.
- Table captions in the results section should explicitly state the number of samples per category to allow readers to assess whether low-F1 categories are also low-sample categories.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in benchmark construction and label validation. We agree that these details are necessary for proper interpretation of the results and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The manuscript provides no description of the kernel selection criteria, the procedure used to identify and annotate the 1130 samples for the six categories, or how overlapping labels were resolved in the multi-label setup. Without this, the F1 scores in §5 cannot be interpreted as measurements of model capability rather than artifacts of annotation.
Authors: We agree that the current manuscript lacks a sufficient description of how the benchmark was constructed. In the revised version we will expand §3 with a new subsection that details the kernel selection criteria, the annotation procedure used to produce the 1130 multi-label samples, and the rules applied when a single sample received multiple labels. revision: yes
-
Referee: [§5] §5 (Results): The reported category-wise averages (division by zero 0.8479 vs. underflow 0.6059) rest entirely on the correctness of the 1130 labels; the absence of any inter-annotator agreement, expert review, or external validation means the central claim that models handle explicit errors better than subtle ones is not yet supported by verifiable evidence.
Authors: The referee correctly notes that the category-wise performance differences rest on label quality and that the manuscript currently provides no quantitative validation of those labels. We will revise the paper to describe the annotation process, any internal review steps performed by the authors, and a limitations discussion that acknowledges the absence of formal inter-annotator agreement statistics or external validation. revision: yes
Circularity Check
No circularity: pure empirical benchmarking with no derivations or fitted predictions
full rationale
The paper introduces InterFLOPBench (90 C kernels, 1130 multi-label samples across six FP error categories) and reports direct F1 scores from 14 LLMs on that fixed test set. No equations, first-principles derivations, parameter fitting, or predictions are claimed; performance numbers are measured outputs, not reductions of inputs. No self-citation chains, ansatzes, or uniqueness theorems appear. The central claim (>0.88 F1 for top models) is a straightforward empirical measurement on the authors' own benchmark and does not reduce to any definitional or fitted tautology. This is the normal non-circular outcome for a benchmarking study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Floating-point errors in code can be statically classified into the six distinct categories of cancellation, comparison, division by zero, overflow, underflow and NaN
- standard math F1-score is a suitable metric for evaluating multi-label classification performance on error detection
Reference graph
Works this paper leans on
-
[1]
Polyspace: Static analysis for runtime errors including floating-point anomalies, https://www.mathworks.com/products/polyspace.html
-
[2]
https:// fpbench.org/ (2025), benchmarks, FPCore format, metadata, and standard er- ror measures for floating-point tools
Fpbench: A standard benchmark suite for floating-point accuracy. https:// fpbench.org/ (2025), benchmarks, FPCore format, metadata, and standard er- ror measures for floating-point tools
2025
-
[3]
Abdin, M., Agarwal, S., Awadallah, A., Balachandran, V., Behl, H.: Phi-4- reasoning technical report (2025),https://arxiv.org/abs/2504.21318
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Akshay, M., Noujoud, N., Patrick, D., Deepti, G.: Can llms find bugs in code? an evaluation from beginner errors to security vulnerabilities in python and c++ (2026), https://arxiv.org/abs/2508.16419
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M.I., Bosma, M., Michalewski, H.: Program synthesis with large language models. CoRRabs/2108.07732 (2021), https://arxiv.org/ abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Lecture Notes in Computer Science, Springer (2019)
Chatelain, Y., Petit, E., de Oliveira Castro, P., Lartigue, G., Defour, D.: Automatic explorationofreducedfloating-pointrepresentationsiniterativemethods.In:Euro- Par 2019 Parallel Processing - 25th International Conference. Lecture Notes in Computer Science, Springer (2019)
2019
-
[7]
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H.P.: Evaluating large language models trained on code (2021)
2021
-
[8]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N.: Gemini 2.5:Pushingthefrontierwithadvancedreasoning,multimodality,longcontext,and next generation agentic capabilities (2025),https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Denis, C., de Oliveira Castro, P., Petit, E.: Verificarlo: checking floating point accuracy through monte carlo arithmetic. In: 23rd IEEE Symposium on Com- puter Arithmetic (2015), https://arxiv.org/abs/1509.01347, verificarlo inte- grates Monte Carlo Arithmetic into LLVM to instrument floating point operations post-optimization
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
In: 2019 IEEE/ACM 3rd International Workshop on Software Correctness for HPC Applications (Correctness)
Févotte, F., Lathuili‘ere, B.: Debugging and optimization of hpc programs with the verrou tool. In: 2019 IEEE/ACM 3rd International Workshop on Software Correctness for HPC Applications (Correctness). pp. 1–10. IEEE (2019)
2019
-
[11]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A.: The llama 3 herd of models (2024),https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
doi: 10.1038/s41586-025-09422-z
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P.: Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning. Nature645, 633–638 (2025). https://doi.org/10.1038/s41586-025-09422-z
-
[13]
Jézéquel, F., Chesneaux, J.M.: Cadna: a library for estimating round-off error propagation. Computer Physics Communications178(12), 933–955 (2008).https: //doi.org/10.1016/j.cpc.2008.02.003, cADNA implements discrete stochastic arithmetic (CESTAC) for runtime numerical error estimation
-
[14]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S.: Mistral 7b (2023), https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Jiang, J., Wang, F., Shen, J., Kim, S., Kim, S.: A survey on large language models for code generation. ACM Trans. Softw. Eng. Methodol. (Jul 2025).https://doi. org/10.1145/3747588, https://doi.org/10.1145/3747588, just Accepted
-
[16]
Klagges, H., Dahlke, R., Klemm, F., Merkel, B., Klingmann, D.: Assembly of ex- perts: Linear-time construction of the chimera llm variants with emergent and adaptable behaviors (2025),https://arxiv.org/abs/2506.14794 Benchmarking Large Language Models on Floating-Point Error Classification 15
-
[17]
In: Proceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE)
Laguna, I.: FPChecker: Detecting floating-point exceptions in gpu applications. In: Proceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). pp. 1126–1129. IEEE (2019)
2019
-
[18]
In: 2025 37th International Conference on Microelectronics (ICM)
Mohanty, H., Viswambharan, V.N., Gadde, D.N.: Formal that “floats” high: Formal verification of floating point arithmetic. In: 2025 37th International Conference on Microelectronics (ICM). pp. 1–6. IEEE (2025)
2025
-
[19]
OpenAI, :, Agarwal, S., Ahmad, L., Ai, J.: gpt-oss-120b & gpt-oss-20b model card (2025), https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
OpenAI, :, Hurst, A., Lerer, A., Goucher, A.P.: Gpt-4o system card (2024),https: //arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Pearce, H., Tan, B., Ahmad, B., Karri, R., Dolan-Gavitt, B.: Examining zero-shot vulnerability repair with large language models (2021)
2021
-
[22]
Qwen Team: Qwen3.5-omni technical report (2026).https://doi.org/10.48550/ arXiv.2604.15804
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Sanchez-Stern, A., Panchekha, P., Lerner, S., Tatlock, Z.: Finding root causes of floating point error. pp. 256–269 (06 2018).https://doi.org/10.1145/3192366. 3192411
-
[24]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N.: Gemma 3 technical report (2025), https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Assessing Large Language Models for Stabilizing Numerical Expressions in Scientific Software
Tien, N., Kirshanthan, S., Muhammad Ali, G.: Assessing large language models for stabilizing numerical expressions in scientific software (2026),https://arxiv. org/abs/2604.04854
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
In: Platzer, A., Rozier, K.Y., Pradella, M., Rossi, M
Titolo, L., Moscato, M., Feliu, M.A., Masci, P., Muñoz, C.A.: Rigorous floating- point round-off error analysis in precisa 4.0. In: Platzer, A., Rozier, K.Y., Pradella, M., Rossi, M. (eds.) Formal Methods. pp. 20–38. Springer Nature Switzerland, Cham (2025)
2025
-
[27]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L.: Attention is all you need. CoRR abs/1706.03762 (2017), http://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Vedrine, F.: Fldlib: An instrumentation library based on affine forms for accuracy analysis, https://github.com/fvedrine/fldlib
- [29]
-
[30]
In: Proceedings of the SC’25 Workshops of the International Conference for High Performance Computing, Net- working, Storage and Analysis
Wang, Y., Rubio-González, C.: Llm4fp: Llm-based program generation for trig- gering floating-point inconsistencies across compilers. In: Proceedings of the SC’25 Workshops of the International Conference for High Performance Computing, Net- working, Storage and Analysis. pp. 225–234 (2025)
2025
-
[31]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B.: Qwen3 technical report (2025), https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [32]
- [33]
-
[34]
arXiv preprint arXiv:2405.01466 (2024)
Zhang, Q., Fang, C., Xie, Y., Ma, Y., Sun, W.: A systematic literature re- view on large language models for automated program repair. arXiv preprint arXiv:2405.01466 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.