Look But Don't Touch with Sparse Autoencoders for Unlearning in Diffusion Models
Pith reviewed 2026-07-03 21:54 UTC · model grok-4.3
The pith
Sparse autoencoders detect semantic concepts in diffusion model activations but direct intervention on those features induces out-of-distribution activations and visual artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
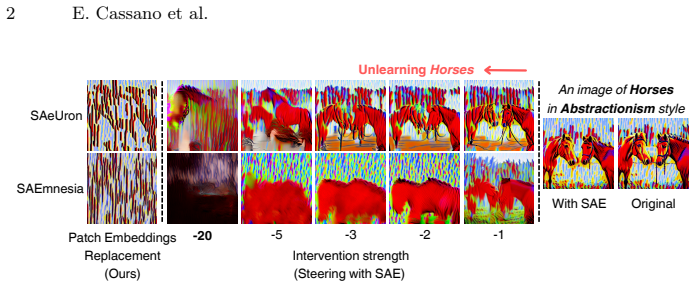
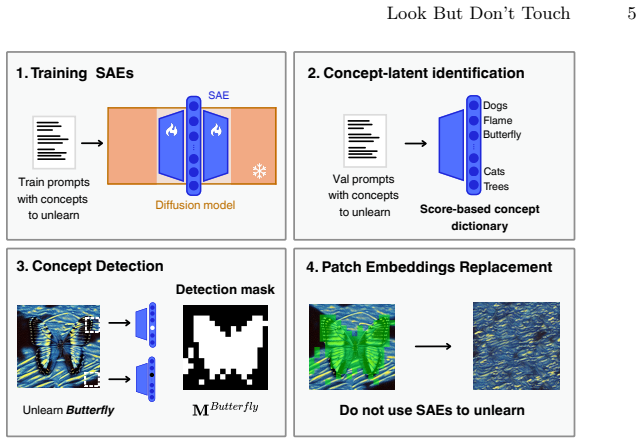
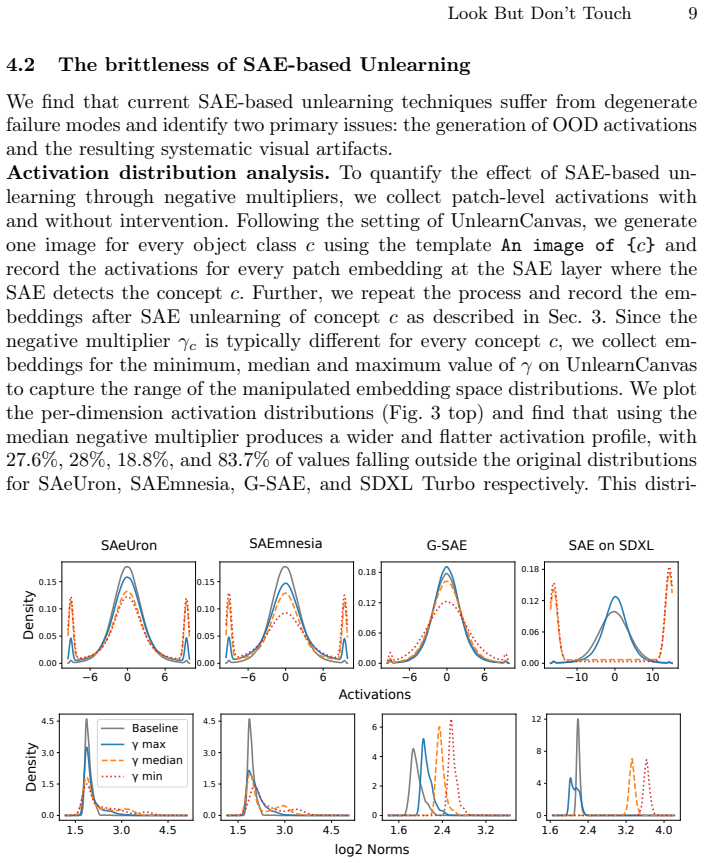
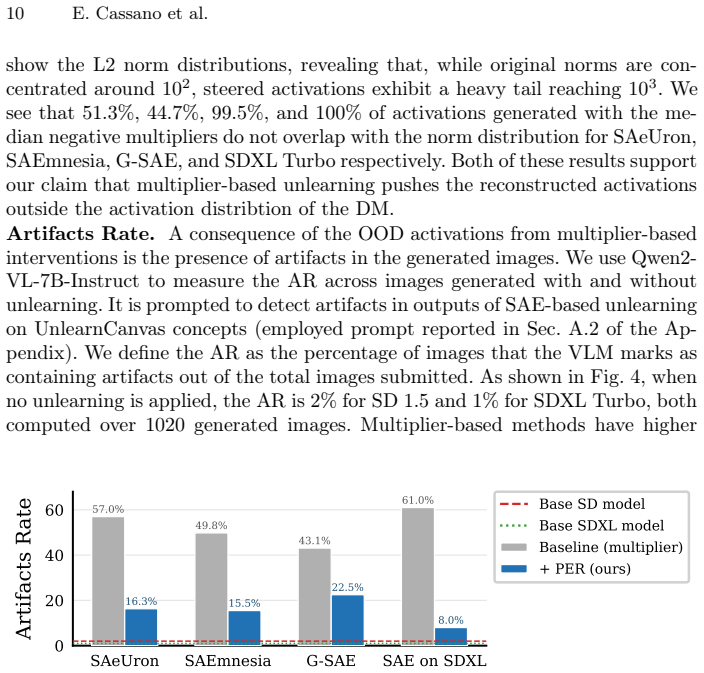
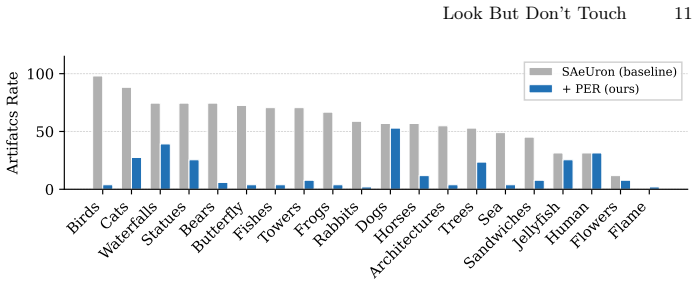
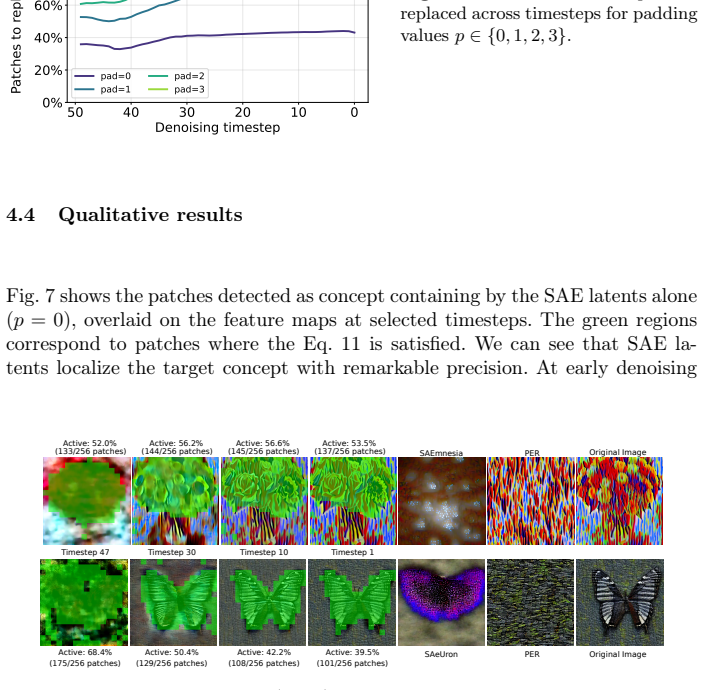
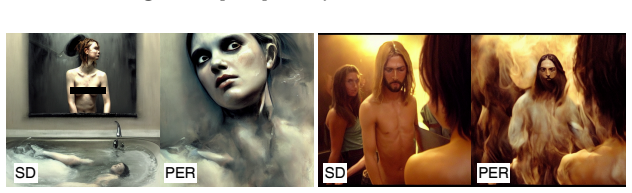
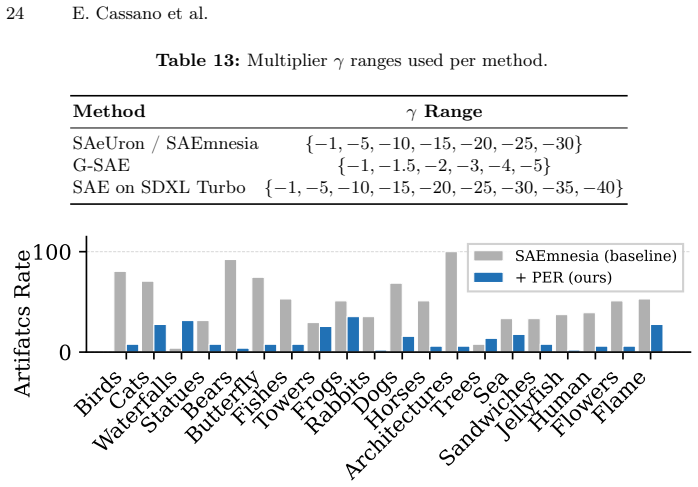
While SAEs reliably detect and localize semantic concepts within diffusion model activations, direct intervention in their latent space frequently induces out-of-distribution activations, resulting in severe visual artifacts. To disentangle detection from intervention, the work uses SAE activations purely as semantic detectors to identify image regions containing the target object, and replaces those patch embeddings with the ones that do not contain it. This detection-based replacement preserves the diffusion model's activation statistics and produces significantly cleaner erasure results than latent steering, revealing that monosemantic or sparse features are not inherently suitable as con
What carries the argument
Sparse autoencoders applied to diffusion model activations, used either for direct latent feature intervention or solely as detectors that trigger patch embedding replacement.
If this is right
- Direct latent intervention on SAE features produces out-of-distribution activations and severe visual artifacts.
- Detection-only replacement that swaps patch embeddings preserves activation statistics and yields cleaner object erasure.
- Monosemantic features located by SAEs are not inherently suitable as control knobs for steering diffusion outputs.
- SAEs function effectively as interpretability tools for analyzing where concepts appear but not as mechanisms for direct manipulation.
Where Pith is reading between the lines
- Unlearning pipelines may need to separate detection from editing and rely on embedding replacement rather than feature editing.
- Similar detection-intervention gaps could appear when SAEs are applied to other generative architectures beyond diffusion models.
- Methods that enforce activation statistics during editing might close the gap between detection and usable control.
- The results suggest testing whether other sparse or interpretable decompositions suffer the same limitation when used for steering.
Load-bearing premise
Isolated features identified by sparse autoencoders can serve as controllable intervention points for object erasure without disrupting the surrounding activation statistics.
What would settle it
An experiment that performs direct ablation or steering on SAE-identified features yet produces no out-of-distribution activations and generates images whose visual quality matches the detection-based replacement method.
Figures




read the original abstract
Sparse autoencoders (SAEs) have recently been proposed as interpretable tools for concept-level manipulation, under the assumption that isolated features can serve as controllable intervention points. In this work, we systematically evaluate this assumption in the context of object erasure and steering in diffusion models. We show that while SAEs reliably detect and localize semantic concepts within diffusion model activations, direct intervention in their latent space frequently induces out-of-distribution activations, resulting in severe visual artifacts. To disentangle detection from intervention, we use SAE activations purely as semantic detectors to identify image regions containing the target object, and replace those patch embeddings with the ones that do not contain it. This detection-based replacement preserves the diffusion model's activation statistics and produces significantly cleaner erasure results than latent steering. Our findings reveal a fundamental gap between concept detection and concept intervention in diffusion models: monosemantic or sparse features are not inherently suitable as control knobs for steering. These results position SAEs as powerful interpretability tools for analyzing generative models, but highlight important limitations when used for direct manipulation, such as unlearning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
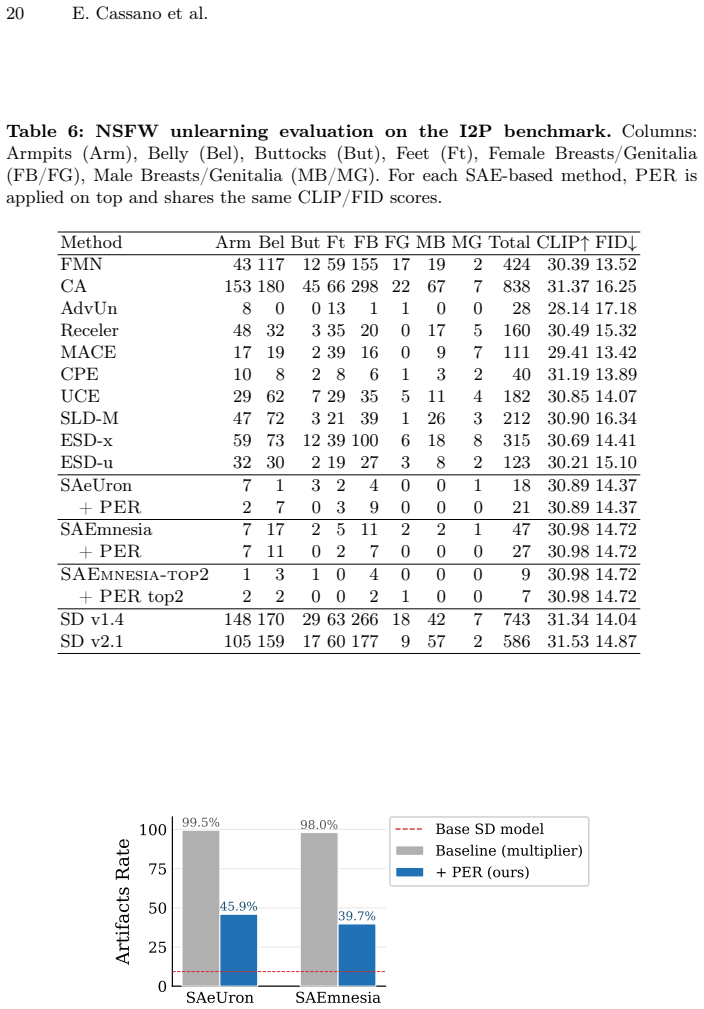
Summary. The manuscript evaluates sparse autoencoders (SAEs) for object erasure and steering in diffusion models. It claims that SAEs reliably detect and localize semantic concepts in activations, but direct latent-space intervention induces out-of-distribution activations and severe visual artifacts. To separate detection from intervention, the authors use SAE activations only as detectors to identify target regions and replace the corresponding patch embeddings with non-target ones; this preserves activation statistics and yields cleaner results than latent steering. The central conclusion is that monosemantic SAE features are not inherently suitable as control knobs for unlearning or steering.
Significance. If the empirical gap holds, the work clarifies the boundary between interpretability and controllability for SAEs in generative models. It supplies concrete evidence that detection success does not imply intervention success, which is directly relevant to ongoing efforts in concept erasure, model unlearning, and activation steering. The detection-plus-replacement protocol is a practical contribution that could be adopted or extended by others working on activation-level interventions.
minor comments (2)
- [§3] §3 (Methods): the description of how SAE activations are thresholded to produce the binary mask for patch replacement should include the exact threshold value or selection criterion used across experiments.
- [Figure 4] Figure 4 and accompanying text: the visual comparison would benefit from reporting the precise fraction of patches replaced and the resulting change in activation norm statistics for both the direct-intervention and detection-replacement conditions.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of our contributions, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
This is an empirical evaluation study that tests the assumption about SAE features as intervention points by directly contrasting two methods (latent steering vs. detection-only replacement) and reporting observed differences in OOD activations, artifacts, and erasure quality. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the derivation chain; the central finding is the empirical gap itself rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trans- actions on Machine Learning Research (2024), survey Certification, Expert Certi- fication
Bereska, L., Gavves, S.: Mechanistic interpretability for AI safety - a review. Trans- actions on Machine Learning Research (2024), survey Certification, Expert Certi- fication
2024
-
[2]
Transformer Circuits Thread (2023), https://transformer-circuits.pub/2023/monosemantic- features/index.html
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., McLean, B., Burke, J.E., Hume, T., Carter, S., Henighan, T., Olah, C.: Towards monose- manticity: Decomposing language ...
2023
-
[3]
In: Forty-third International Conference on Machine Learning (2026)
Cassano, E., Renzulli, R., Nurisso, M., Zaffaroni, M., Perotti, A., Grangetto, M.: SAEmnesia: Erasing concepts in diffusion models with supervised sparse autoen- coders. In: Forty-third International Conference on Machine Learning (2026)
2026
-
[4]
In: Forty-second International Conference on Machine Learning (2025)
Cywiński, B., Deja, K.: SAeUron: Interpretable concept unlearning in diffusion models with sparse autoencoders. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[5]
In: The Twelfth International Conference on Learning Representations (2024)
Fan, C., Liu, J., Zhang, Y., Wong, E., Wei, D., Liu, S.: Salun: Empowering ma- chine unlearning via gradient-based weight saliency in both image classification and generation. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[6]
arXiv preprint arXiv:2507.19894 (2025)
Feng, X., Zhang, J., Yu, F., Wang, C., Zhang, L., Li, K., Li, Y., Chen, C., Yin, J.: A survey on generative model unlearning: Fundamentals, taxonomy, evaluation, and future direction. arXiv preprint arXiv:2507.19894 (2025)
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., Bau, D.: Erasing concepts from diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2426–2436 (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Gandikota, R., Orgad, H., Belinkov, Y., Materzyńska, J., Bau, D.: Unified concept editing in diffusion models. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 5111–5120 (2024)
2024
-
[9]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Härle, R., Friedrich, F., Brack, M., Deiseroth, B., Waeldchen, S., Schramowski, P., Kersting, K.: Measuring and guiding monosemanticity. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[10]
Advances in Neural Information Processing Systems 36, 17170–17194 (2023)
Heng, A., Soh, H.: Selective amnesia: A continual learning approach to forgetting in deep generative models. Advances in Neural Information Processing Systems 36, 17170–17194 (2023)
2023
-
[11]
arXiv preprint arXiv:2501.19066 (2025)
Kim, D., Ghadiyaram, D.: Concept steerers: Leveraging k-sparse autoencoders for controllable generations. arXiv preprint arXiv:2501.19066 (2025)
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kumari, N., Zhang, B., Wang, S.Y., Shechtman, E., Zhang, R., Zhu, J.Y.: Ablat- ing concepts in text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22691–22702 (2023)
2023
-
[13]
In: The Twelfth International Conference on Learning Representations (2023)
Li, S., van de Weijer, J., Khan, F., Hou, Q., Wang, Y., et al.: Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models. In: The Twelfth International Conference on Learning Representations (2023)
2023
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lyu, M., Yang, Y., Hong, H., Chen, H., Jin, X., He, Y., Xue, H., Han, J., Ding, G.: One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7559–7568 (2024)
2024
-
[15]
Makhzani, A., Frey, B.J.: k-sparse autoencoders. CoRRabs/1312.5663(2013) Look But Don’t Touch 17
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[16]
Mayne, H., Yang, Y., Mahdi, A.: Can sparse autoencoders be used to decompose and interpret steering vectors? In: MINT: Foundation Model Interventions (2024)
2024
-
[17]
In: ICML 2025 Workshop on Reliable and Responsible Foundation Models (2025)
O’Brien, K., Majercak, D., Fernandes, X., Edgar, R.G., Bullwinkel, B., Chen, J., Nori, H., Carignan, D., Horvitz, E., Poursabzi-Sangdeh, F.: Steering language model refusal with sparse autoencoders. In: ICML 2025 Workshop on Reliable and Responsible Foundation Models (2025)
2025
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Schramowski, P., Brack, M., Deiseroth, B., Kersting, K.: Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22522– 22531 (2023)
2023
-
[20]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Surkov, V., Wendler, C., Mari, A., Terekhov, M., Deschenaux, J., West, R., Gul- cehre, C., Bau, D.: One-step is enough: Sparse autoencoders for text-to-image diffusion models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[21]
In: Second Workshop on Visual Concepts (2025)
Tinaz, B., Fabian, Z., Soltanolkotabi, M.: Emergence and evolution of interpretable concepts in diffusion models through the lens of sparse autoencoders. In: Second Workshop on Visual Concepts (2025)
2025
-
[22]
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution (2024)
2024
-
[23]
In: European Conference on Computer Vision
Wu, J., Harandi, M.: Scissorhands: Scrub data influence via connection sensitivity in networks. In: European Conference on Computer Vision. pp. 367–384. Springer (2024)
2024
-
[24]
Wu, J., Le, T., Hayat, M., Harandi, M.: Erasediff: Erasing data influence in diffu- sion models (2024)
2024
-
[25]
In: Forty-second International Conference on Machine Learning (2025)
Wu, Z., Arora, A., Geiger, A., Wang, Z., Huang, J., Jurafsky, D., Manning, C.D., Potts, C.: Axbench: Steering LLMs? even simple baselines outperform sparse au- toencoders. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[26]
Xu, H., Zhu, T., Zhang, L., Zhou, W., Yu, P.S.: Machine unlearning: A survey. ACM Comput. Surv.56(1) (Aug 2023).https://doi.org/10.1145/3603620
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, G., Wang, K., Xu, X., Wang, Z., Shi, H.: Forget-me-not: Learning to forget in text-to-image diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1755–1764 (2024)
2024
-
[28]
In: The Thirty-eight Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track (2024)
Zhang, Y., Fan, C., Zhang, Y., Yao, Y., Jia, J., Liu, J., Zhang, G., Liu, G., Kom- pella, R.R., Liu, X., Liu, S.: Unlearncanvas: Stylized image dataset for enhanced machine unlearning evaluation in diffusion models. In: The Thirty-eight Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track (2024)
2024
-
[29]
Zhang, Y., Jia, J., Chen, X., Chen, A., Zhang, Y., Liu, J., Ding, K., Liu, S.: To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images... for now. In: European Conference on Computer Vision. pp. 385–
-
[30]
Cassano et al
Springer (2024) 18 E. Cassano et al. A Appendix A.1 Baselines for UnlearnCanvas. Table 5 reports the performance of the state-of-the-art methods on object con- cept unlearning for the Unlearn Canvas benchmark.PERapplied to theG-SAE pipeline outperforms all the compared methods. Table 5: State-of-the-art methods on object concept unlearning tested on the U...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.