FlexViT: A Flexible FPGA-based Accelerator for Edge Vision Transformers
Pith reviewed 2026-07-01 02:11 UTC · model grok-4.3
The pith
FlexViT maps fully connected and convolutional layers in Vision Transformers to one reconfigurable INT8 GEMM engine on FPGA for edge devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
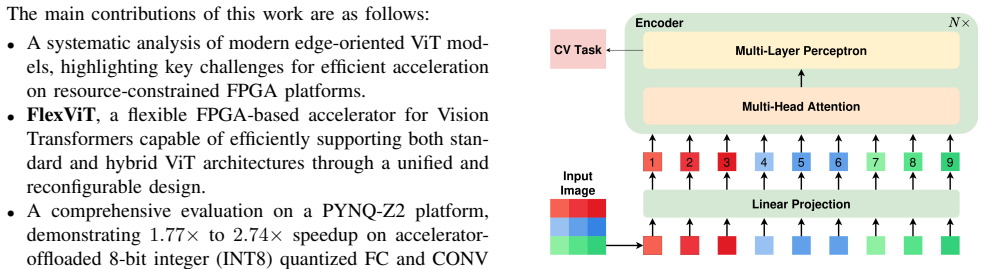
FlexViT is a reconfigurable FPGA accelerator that maps both fully connected and convolutional layers onto a unified high-throughput INT8 GEMM engine using runtime im2col transformation, a dual-mode dataflow that switches between input and weight reuse by reconfiguring the compute array at runtime, and a depth-first tiling strategy that completes accumulation in a single pass to eliminate off-chip partial-sum transfers.
What carries the argument
Dual-mode dataflow that dynamically switches between input and weight reuse by reconfiguring the compute array at runtime, paired with the unified INT8 GEMM engine and depth-first tiling.
If this is right
- Accelerator-executed layers achieve up to 2.74x speedup over CPU execution.
- End-to-end inference achieves up to 1.40x speedup compared to CPU-only execution.
- Memory bandwidth demand drops because accumulation finishes in one pass with no off-chip partial sums.
- Diverse layer shapes are supported through runtime reconfiguration of the same compute array.
Where Pith is reading between the lines
- The single unified engine could reduce the need for separate hardware modules when new ViT variants appear with different layer mixes.
- Depth-first tiling may become more valuable on FPGAs with smaller on-chip buffers than the PYNQ-Z2.
- The approach could be tested on other hybrid networks that combine dense and convolutional stages beyond Vision Transformers.
Load-bearing premise
The runtime im2col transformation and dual-mode reconfiguration incur sufficiently low overhead that the reported speedups remain net positive across the evaluated ViT models on the target PYNQ-Z2 platform.
What would settle it
Measure end-to-end wall-clock time for the same ViT models on the PYNQ-Z2 platform with the accelerator enabled versus disabled; if the accelerator version is not at least 1.4 times faster after including all reconfiguration and im2col costs, the net-benefit claim does not hold.
Figures


read the original abstract
Deploying Vision Transformer (ViT) models on edge platforms remains challenging due to their high computational demands and the architectural heterogeneity of modern hybrid ViT models, which incorporate both fully connected and convolutional layers. This heterogeneity leads to significant variation in tensor shapes, requiring flexible and efficient FPGA-based acceleration. In this paper, we present FlexViT, a reconfigurable FPGA accelerator for efficient ViT inference on resource-constrained edge devices. Built on the SECDA-TFLite framework, FlexViT employs a hardware-software co-design approach that maps both fully connected and convolutional layers onto a unified high-throughput INT8 GEMM engine using a runtime im2col transformation. To efficiently support diverse layer configurations, we propose a dual-mode dataflow that dynamically switches between input and weight reuse by reconfiguring the compute array at runtime. We further introduce a depth-first tiling strategy that completes accumulation in a single pass, eliminating off-chip partial-sum transfers and reducing memory bandwidth requirements. We implement FlexViT on a PYNQ-Z2 FPGA and evaluate it across a representative set of ViT models. FlexViT achieves up to 2.74x speedup on accelerator-executed layers, translating into up to 1.40x end-to-end speedup compared to CPU-only execution. The code is available at: https://github.com/gicLAB/FlexViT
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FlexViT, a reconfigurable FPGA accelerator for Vision Transformer inference on edge devices built on the SECDA-TFLite framework. It maps both fully connected and convolutional layers to a unified high-throughput INT8 GEMM engine via runtime im2col transformation, introduces a dual-mode dataflow that switches between input and weight reuse through runtime reconfiguration of the compute array, and employs depth-first tiling to complete accumulations in a single pass without off-chip partial-sum transfers. The design is implemented on a PYNQ-Z2 platform and evaluated on representative ViT models, claiming up to 2.74× speedup on accelerator-executed layers and up to 1.40× end-to-end speedup versus CPU-only execution, with code released at https://github.com/gicLAB/FlexViT.
Significance. If the measured speedups hold under standard evaluation practices, the work provides a concrete demonstration of hardware-software co-design for handling architectural heterogeneity in hybrid ViT models on resource-constrained FPGAs. The open-source release and use of physical timing measurements on real hardware strengthen reproducibility and allow direct assessment of the unified GEMM plus depth-first tiling approach for edge deployment.
major comments (2)
- [Abstract] Abstract: The central speedup claims (2.74× on accelerator layers, 1.40× end-to-end) are stated without specifying the exact ViT models evaluated, the CPU baseline configuration (processor, compiler flags, or library), the fraction of layers offloaded to the accelerator, or any statistical measures (multiple runs, error bars). These details are load-bearing for assessing whether the reported net speedups are robust and generalizable.
- [Evaluation (inferred from abstract claims)] The manuscript does not appear to include explicit measurements or analysis of the overheads from the runtime im2col transformation and dual-mode reconfiguration; without these, it is difficult to isolate how much of the reported speedup is attributable to the unified GEMM engine versus the overheads being low enough to remain net positive across models.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief table summarizing the key ViT models, their layer counts, and tensor-shape diversity to contextualize the heterogeneity challenge addressed by the dual-mode design.
- [Introduction/Approach] Notation for dataflow modes (input reuse vs. weight reuse) should be defined consistently when first introduced to aid readers unfamiliar with the SECDA-TFLite framework.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive recommendation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central speedup claims (2.74× on accelerator layers, 1.40× end-to-end) are stated without specifying the exact ViT models evaluated, the CPU baseline configuration (processor, compiler flags, or library), the fraction of layers offloaded to the accelerator, or any statistical measures (multiple runs, error bars). These details are load-bearing for assessing whether the reported net speedups are robust and generalizable.
Authors: We agree that the abstract would benefit from greater specificity. In the revision we will explicitly name the evaluated ViT models, state the CPU baseline (PYNQ-Z2 ARM Cortex-A9 with TFLite), note the fraction of layers offloaded, and clarify that reported timings are single-run hardware measurements on the target platform. If space allows we will also add a parenthetical reference to the evaluation section for statistical details. revision: yes
-
Referee: [Evaluation (inferred from abstract claims)] The manuscript does not appear to include explicit measurements or analysis of the overheads from the runtime im2col transformation and dual-mode reconfiguration; without these, it is difficult to isolate how much of the reported speedup is attributable to the unified GEMM engine versus the overheads being low enough to remain net positive across models.
Authors: The end-to-end speedups already incorporate the measured overhead of im2col and reconfiguration because all timings are taken on the complete SECDA-TFLite execution path. Nevertheless, we acknowledge that an explicit breakdown would strengthen the analysis. In the revised manuscript we will add a short table or paragraph in the evaluation section quantifying the reconfiguration and im2col latency relative to GEMM execution time for the evaluated models. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports measured speedups from physical FPGA implementation and timing on PYNQ-Z2 hardware using a unified GEMM engine, runtime im2col, dual-mode reconfiguration, and depth-first tiling. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation of the core performance claims; results are externally falsifiable via the linked code and hardware runs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DLAS: A Conceptual Model for Across-Stack Deep Learning Acceleration,
P. Gibson, J. Cano, E. Crowley, A. Storkey, and M. O’boyle, “DLAS: A Conceptual Model for Across-Stack Deep Learning Acceleration,”ACM Transactions on Architecture and Code Optimization (TACO), 2025
2025
-
[2]
ViTA: A vision transformer inference accelerator for edge applica- tions,
S. Nag, G. Datta, S. Kundu, N. Chandrachoodan, and P. A. Beerel, “ViTA: A vision transformer inference accelerator for edge applica- tions,” in2023 IEEE International Symposium on Circuits and Systems (ISCAS), 2023, pp. 1–5
2023
-
[3]
An fpga-based reconfigurable accelerator for convolution-transformer hybrid efficientvit,
H. Shao, H. Shi, W. Mao, and Z. Wang, “An fpga-based reconfigurable accelerator for convolution-transformer hybrid efficientvit,” in2024 IEEE International Symposium on Circuits and Systems (ISCAS), 2024, pp. 1–5
2024
-
[4]
An energy- efficient fpga-based vision transformer accelerator via software-hardware co-design,
J. Cao, J. Guo, W. Xiong, H. Luo, J. Wang, and J. Lai, “An energy- efficient fpga-based vision transformer accelerator via software-hardware co-design,” in2025 IEEE 33rd Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2025, pp. 272–272
2025
-
[5]
M2-vit: Accelerating hybrid vision transformers with two-level mixed quantization,
Y . Liang, H. Shi, and Z. Wang, “M2-vit: Accelerating hybrid vision transformers with two-level mixed quantization,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 5, pp. 1492– 1496, 2025
2025
-
[6]
SECDA- TFLite: A toolkit for efficient development of FPGA-based DNN accelerators for edge inference,
J. Haris, P. Gibson, J. Cano, N. Bohm Agostini, and D. Kaeli, “SECDA- TFLite: A toolkit for efficient development of FPGA-based DNN accelerators for edge inference,”Journal of Parallel and Distributed Computing, vol. 173, pp. 140–151, 2023
2023
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” Jun. 2021, arXiv:2010.11929 [cs]. [Online]. Available: http://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, ser. NIPS’17. Curran Associates Inc., 2017, p. 6000–6010
2017
-
[9]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jegou, “Training data-efficient image transformers & distillation through attention,” inProceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds., vol. 139. PMLR, 18–24 Jul 2021, pp. 10 347–10 357
2021
-
[10]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 9992–10 002
2021
-
[11]
A Survey on Vision Transformer,
K. Han, Y . Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y . Tang, A. Xiao, C. Xu, Y . Xu, Z. Yang, Y . Zhang, and D. Tao, “A Survey on Vision Transformer,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 87–110, Jan. 2023
2023
-
[12]
CSWin Transformer: A General Vision Transformer Backbone With Cross-Shaped Windows,
X. Dong, J. Bao, D. Chen, W. Zhang, N. Yu, L. Yuan, D. Chen, and B. Guo, “CSWin Transformer: A General Vision Transformer Backbone With Cross-Shaped Windows,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2022, pp. 12 124– 12 134
2022
-
[13]
ViViT: A Video Vision Transformer,
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid, “ViViT: A Video Vision Transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6836–6846
2021
-
[14]
Devit: Decomposing vision transformers for collaborative inference in edge devices,
G. Xu, Z. Hao, Y . Luo, H. Hu, J. An, and S. Mao, “Devit: Decomposing vision transformers for collaborative inference in edge devices,”IEEE Transactions on Mobile Computing, vol. 23, no. 5, p. 5917–5932, May 2024
2024
-
[15]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255
2009
-
[16]
Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer,
S. Mehta and M. Rastegari, “Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer,” inInternational Conference on Learning Representations, 2022
2022
-
[17]
Efficientvit: Memory efficient vision transformer with cascaded group attention,
X. Liu, H. Peng, N. Zheng, Y . Yang, H. Hu, and Y . Yuan, “Efficientvit: Memory efficient vision transformer with cascaded group attention,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 15 094–15 104
2023
-
[18]
Edge computing: Vision and challenges,
W. Shi, J. Cao, Q. Zhang, Y . Li, and L. Xu, “Edge computing: Vision and challenges,”IEEE Internet of Things Journal, vol. 3, no. 5, pp. 637–646, 2016
2016
-
[19]
SECDA: Efficient Hardware/Software Co-Design of FPGA-based DNN Acceler- ators for Edge Inference,
J. Haris, P. Gibson, J. Cano, N. B. Agostini, and D. Kaeli, “SECDA: Efficient Hardware/Software Co-Design of FPGA-based DNN Acceler- ators for Edge Inference,” inSBAC-PAD, 2021, pp. 1–8
2021
-
[20]
TUL Corporation,PYNQ-Z2 User Manual v1.0, TUL Corporation, May 2018
2018
-
[21]
How to train your vit? data, augmentation, and regularization in vision transformers,
A. P. Steiner, A. Kolesnikov, X. Zhai, R. Wightman, J. Uszkoreit, and L. Beyer, “How to train your vit? data, augmentation, and regularization in vision transformers,”Transactions on Machine Learning Research, 2022
2022
-
[22]
Validity of the single processor approach to achieving large scale computing capabilities,
G. M. Amdahl, “Validity of the single processor approach to achieving large scale computing capabilities,” inProceedings of the April 18-20, 1967, spring joint computer conference, 1967, pp. 483–485
1967
-
[23]
(2025) USB Power Meter Digital Display - V oltage Current Amps Capacity Time Temperature Meter
Makerfocus. (2025) USB Power Meter Digital Display - V oltage Current Amps Capacity Time Temperature Meter
2025
-
[24]
ViA: A novel vision-transformer accelerator based on FPGA,
T. Wang, L. Gong, C. Wang, Y . Yang, Y . Gao, X. Zhou, and H. Chen, “ViA: A novel vision-transformer accelerator based on FPGA,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 11, pp. 4088–4099, 2022
2022
-
[25]
Auto-vit-acc: An fpga-aware automatic acceleration framework for vision transformer with mixed- scheme quantization,
Z. Li, M. Sun, A. Lu, H. Ma, G. Yuan, Y . Xie, H. Tang, Y . Li, M. Leeser, Z. Wang, X. Lin, and Z. Fang, “Auto-vit-acc: An fpga-aware automatic acceleration framework for vision transformer with mixed- scheme quantization,” in2022 32nd International Conference on Field- Programmable Logic and Applications (FPL), 2022, pp. 109–116
2022
-
[26]
Vaqf: Fully automatic software-hardware co-design frame- work for low-bit vision transformer,
M. Sun, H. Ma, G. Kang, Y . Jiang, T. Chen, X. Ma, Z. Wang, and Y . Wang, “V AQF: Fully automatic software-hardware co-design framework for low-bit vision transformer,” 2022. [Online]. Available: https://arxiv.org/abs/2201.06618
-
[27]
Heatvit: Hardware-efficient adaptive token pruning for vision transformers,
P. Dong, M. Sun, A. Lu, Y . Xie, K. Liu, Z. Kong, X. Meng, Z. Li, X. Lin, Z. Fang, and Y . Wang, “Heatvit: Hardware-efficient adaptive token pruning for vision transformers,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2023, pp. 442–455
2023
-
[28]
Accelerating vit inference on fpga through static and dynamic prun- ing,
D. Parikh, S. Li, B. Zhang, R. Kannan, C. Busart, and V . Prasanna, “Accelerating vit inference on fpga through static and dynamic prun- ing,” in2024 IEEE 32nd Annual International Symposium on Field- Programmable Custom Computing Machines (FCCM), 2024, pp. 78–89
2024
-
[29]
Vitcod: Vision transformer acceleration via dedicated algorithm and accelerator co-design,
H. You, Z. Sun, H. Shi, Z. Yu, Y . Zhao, Y . Zhang, C. Li, B. Li, and Y . Lin, “Vitcod: Vision transformer acceleration via dedicated algorithm and accelerator co-design,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2023, pp. 273–286
2023
-
[30]
Token merging: Your vit but faster,
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your vit but faster,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[31]
Adaptiv: Sign-similarity based image- adaptive token merging for vision transformer acceleration,
S. Yoo, H. Kim, and J.-Y . Kim, “Adaptiv: Sign-similarity based image- adaptive token merging for vision transformer acceleration,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MI- CRO), 2024, pp. 64–77
2024
-
[32]
DRViT: A dynamic redundancy-aware vision transformer accelerator via algorithm and architecture co-design on FPGA,
X. Sun, Y . Zhang, Q. Wang, X. Zou, Y . Liu, Z. Zeng, and H. Zhuang, “DRViT: A dynamic redundancy-aware vision transformer accelerator via algorithm and architecture co-design on FPGA,”Journal of Parallel and Distributed Computing, vol. 199, p. 105042, 2025
2025
-
[33]
Lightweight vision transformers for low energy edge inference,
S. Nag, L. Liberty, A. Sivakumar, N. J. Yadwadkar, and L. K. John, “Lightweight vision transformers for low energy edge inference,” in Machine Learning for Computer Architecture and Systems 2024, 2024
2024
-
[34]
An FPGA-based transformer accelerator using output block stationary dataflow for object recognition applications,
Z. Zhao, R. Cao, K.-F. Un, W.-H. Yu, P.-I. Mak, and R. P. Martins, “An FPGA-based transformer accelerator using output block stationary dataflow for object recognition applications,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 70, no. 1, pp. 281–285, 2023
2023
-
[35]
A 109-gops/w fpga-based vision transformer accelerator with weight-loop dataflow featuring data reusing and resource saving,
Y . Zhang, L. Feng, H. Shan, and Z. Zhu, “A 109-gops/w fpga-based vision transformer accelerator with weight-loop dataflow featuring data reusing and resource saving,”IEEE Transactions on Circuits and Sys- tems for Video Technology, vol. 34, no. 12, pp. 13 596–13 610, 2024
2024
-
[36]
Me- vit: A single-load memory-efficient fpga accelerator for vision transformers,
K. Marino, P. Zhang, and V . K. Prasanna, “Me- vit: A single-load memory-efficient fpga accelerator for vision transformers,” in2023 IEEE 30th International Conference on High Performance Computing, Data, and Analytics (HiPC), 2023, pp. 213–223
2023
-
[37]
SW AT: An efficient swin transformer accelerator based on FPGA,
Q. Dong, X. Xie, and Z. Wang, “SW AT: An efficient swin transformer accelerator based on FPGA,” inProceedings of the 29th Asia and South Pacific Design Automation Conference (ASPDAC), 2024, pp. 515–520
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.