Prompt Optimization for User Simulation in Conversational Recommender Systems: A Multi-Objective Framework
Pith reviewed 2026-07-02 23:45 UTC · model grok-4.3
The pith
A multi-objective framework automatically optimizes prompts for LLM-based user simulators in conversational recommender systems to reduce bias and improve human alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A multi-objective prompt optimization framework for LLM user simulators in CRSs simultaneously addresses positive bias, data leakage, limited diversity, and manual engineering, resulting in synthetic interactions that align more closely with observed human behavior.
What carries the argument
The multi-objective prompt optimization framework that balances objectives to tune LLM user simulator prompts for greater fidelity.
If this is right
- Synthetic data from the optimized simulators can replace or supplement real user studies for evaluating new CRS algorithms.
- Training data generated this way carries lower risk of leakage and bias, supporting safer model development.
- Prompt engineering for simulators becomes less dependent on scarce domain expertise.
- CRS evaluation cycles shorten because realistic simulations can be produced at scale.
Where Pith is reading between the lines
- The same optimization approach could extend to user simulators in other dialogue domains such as customer support or education.
- Reduced reliance on real interaction logs may ease privacy regulations around recommender system datasets.
- If the multi-objective balance proves stable, it could serve as a template for prompt tuning in other simulation-heavy machine learning tasks.
Load-bearing premise
Automatically optimizing prompts through a multi-objective framework can simultaneously reduce positive bias, data leakage, limited behavioral diversity, and the need for manual prompt engineering in LLM user simulators.
What would settle it
Run a controlled experiment in which independent human raters score the realism and diversity of user interactions produced by the optimized prompts versus standard manual prompts, then measure whether the optimized version shows statistically significant improvement in matching real CRS logs.
Figures
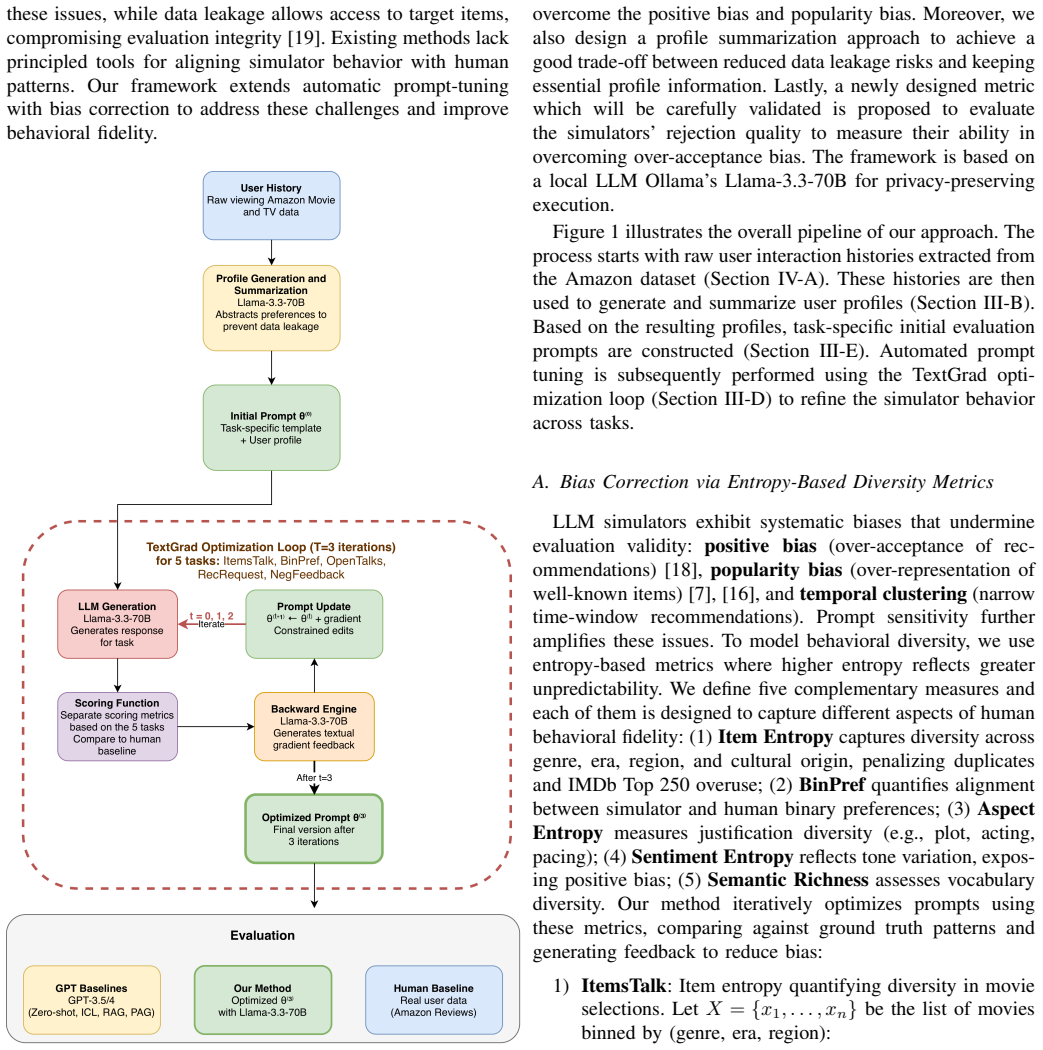
read the original abstract
Conversational recommender systems (CRSs) are a core component of next-generation intelligent recommender systems because they enable users to actively elicit preferences, clarify intentions, and adapt recommendations in real time. However, there are two key obstacles in the CRS domain: evaluation and access to training data. Evaluating CRSs through real human studies is more critical than for traditional recommender systems, yet such studies are both costly and time-consuming. Moreover, CRS interaction data are often difficult to obtain for model training due to privacy concerns. Large language model (LLM)-based user simulators have shown promise in addressing both challenges by generating synthetic user interactions for evaluation and training. However, existing approaches suffer from systematic positive bias, data leakage, and limited behavioral diversity, and they rely on brittle manual prompt engineering that requires extensive domain expertise. In this paper, we propose a framework to automatically optimize prompts for LLM-based user simulators in CRSs, simultaneously mitigating these issues. Experimental results demonstrate that the proposed framework achieves improved behavioral alignment with human interaction patterns compared to baseline methods across diverse prompt settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-objective framework for automatically optimizing prompts in LLM-based user simulators for conversational recommender systems (CRSs). The framework targets simultaneous mitigation of systematic positive bias, data leakage, limited behavioral diversity, and reliance on manual prompt engineering. Experimental results are reported showing improved behavioral alignment with human interaction patterns relative to baseline methods across diverse prompt settings.
Significance. If the reported experimental comparisons hold, the work offers a practical advance for CRS evaluation and training by enabling more reliable synthetic interaction data without extensive human studies or domain-expert prompt tuning. The explicit tying of optimization objectives to bias, leakage, and diversity metrics, along with results across prompt variants, strengthens the contribution over purely heuristic prompt approaches.
minor comments (2)
- The abstract states that the framework 'achieves improved behavioral alignment' but supplies no numerical values, specific metrics, or baseline names; adding one or two key quantitative results (e.g., alignment score deltas) would improve immediate readability without altering the manuscript's scope.
- Section headings and figure captions would benefit from explicit cross-references to the multi-objective formulation (e.g., 'see Eq. (X) for the combined loss') to help readers trace how each objective is operationalized in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation of minor revision. The assessment of the framework's practical value for CRS evaluation and training is appreciated. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The manuscript proposes an empirical multi-objective prompt optimization framework for LLM user simulators and validates behavioral alignment improvements through direct experimental comparisons to baselines across prompt variants. No equations, parameter fittings, derivations, or self-citation chains appear in the load-bearing claims; the abstract and described results treat the framework as a method whose outputs are measured externally rather than defined into existence by the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Recommender systems in the era of large language models (LLMs),
W. Fan, Z. Zhao, J. Li, Y . Liu, X. Mei, Y . Wang, J. Tang, and Q. Li, “Recommender systems in the era of large language models (LLMs),” IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6889–6907, 2024
2024
-
[2]
How can recommender systems benefit from large language models: A survey,
J. Lin, X. Dai, Y . Xi, W. Liu, B. Chen, X. Li, C. Zhu, H. Guo, Y . Yu, R. Tang, and W. Zhang, “How can recommender systems benefit from large language models: A survey,”ACM Transactions on Information Systems, vol. 43, pp. 1–47, 2023
2023
-
[3]
Recommen- dation as instruction following: A large language model empowered recommendation approach,
J. Zhang, R. Xie, Y . Hou, W. Zhao, L. Lin, and J. Wen, “Recommen- dation as instruction following: A large language model empowered recommendation approach,”ACM Transactions on Information Systems, 2023
2023
-
[4]
Optimizing e-commerce recommender systems: A comprehensive review of techniques and future directions,
Z. Wu, “Optimizing e-commerce recommender systems: A comprehensive review of techniques and future directions,” Applied and Computational Engineering, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:274337327
2024
-
[5]
Recdcl: Dual contrastive learning for recommendation,
D. Zhang, Y . Geng, W. Gong, Z. Qi, Z. Chen, X. Tang, Y . Shan, Y . Dong, and J. Tang, “Recdcl: Dual contrastive learning for recommendation,” inProceedings of the ACM Web Conference 2024, ser. WWW ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 3655–3666. [Online]. Available: https://doi.org/10.1145/3589334.3645533
-
[6]
Advances and challenges in conversational recommender systems: A survey,
C. Gao, W. Lei, X. He, M. De Rijke, and T. S. Chua, “Advances and challenges in conversational recommender systems: A survey,”AI Open, vol. 2, pp. 100–126, 2021
2021
-
[7]
Evaluating conversational recommender sys- tems via user simulation,
S. Zhang and K. Balog, “Evaluating conversational recommender sys- tems via user simulation,” inProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020
2020
-
[8]
Towards deep conversational recommendations,
R. Li, S. Ebrahimi Kahou, H. Schulz, V . Michalski, L. Charlin, and C. Pal, “Towards deep conversational recommendations,” inAdvances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[9]
Recmind: Large language model powered agent for recommendation,
Y . Wang, Z. Jiang, Z. Chen, F. Yang, Y . Zhou, E. Cho, X. Fan, Y . Lu, X. Huang, and Y . Yang, “Recmind: Large language model powered agent for recommendation,” inFindings of the Association for Computational Linguistics: NAACL 2024, 2024, pp. 4351–4364. [Online]. Available: https://aclanthology.org/2024.findings-naacl.271/
2024
-
[10]
Theory and toolkits for user simulation in the era of generative AI: user modeling, synthetic data generation, and system evaluation,
K. Balog, N. Bernard, S. Zerhoudi, and C. Zhai, “Theory and toolkits for user simulation in the era of generative AI: user modeling, synthetic data generation, and system evaluation,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18, 2025, 2025
2025
-
[11]
User behavior simulation with large language model-based agents for recommender systems,
L. Wang, J. Zhang, H. Yang, Z. Chen, J. Tang, Z. Zhang, X. Chen, Y . Lin, H. Sun, R. Song, W. Zhao, J. Xu, Z. Dou, J. Wang, and J. Wen, “User behavior simulation with large language model-based agents for recommender systems,”ACM Transactions on Information Systems, 2024
2024
-
[12]
Large language models in power systems: Enhancing control and decision-making,
A. Bernadi ´c, G. Kujund ˇzi´c, and I. Primorac, “Large language models in power systems: Enhancing control and decision-making,”International Journal of Innovative Solutions in Engineering, 2025
2025
-
[13]
The rise of the large language models,
K. Przystalski, J. K. Argasi ´nski, N. Lipp, and D. Pacholczyk, “The rise of the large language models,” inBuilding Personality-Driven Language Models: How Neurotic is ChatGPT. Springer, 2025, pp. 3–9
2025
-
[14]
Simuser: Generating usability feedback by simulating various users interacting with mobile applications,
W. Xiang, H. Zhu, S. Lou, X. Chen, Z. Pan, Y . Jin, S. Chen, and L. Sun, “Simuser: Generating usability feedback by simulating various users interacting with mobile applications,” inProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, 2024, pp. 1–17
2024
-
[15]
Recusersim: A realistic and diverse user simulator for evaluating conversational recommender systems,
L. Chen, Q. Dai, Z. Zhang, X. Feng, M. Zhang, P. Tang, X. Chen, Y . Zhu, and Z. Dong, “Recusersim: A realistic and diverse user simulator for evaluating conversational recommender systems,” inCompanion Proceedings of the ACM on Web Conference 2025, 2025, pp. 133–142
2025
-
[16]
Usersim: User simulation via supervised generative adversarial network,
X. Zhao, L. Xia, L. Zou, H. Liu, D. Yin, and J. Tang, “Usersim: User simulation via supervised generative adversarial network,” in Proceedings of the Web Conference 2021, 2021
2021
-
[17]
Llm-powered user simulator for recommender system,
Z. Zhang, S. Liu, Z. Liu, R. Zhong, Q. Cai, X. Zhao, C. Zhang, Q. Liu, and P. Jiang, “Llm-powered user simulator for recommender system,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, 2025, pp. 13 339–13 347
2025
-
[18]
Evaluating large language models as generative user simulators for conversational recommendation,
S. Yoon, Z. He, J. M. Echterhoff, and J. J. McAuley, “Evaluating large language models as generative user simulators for conversational recommendation,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, J...
2024
-
[19]
How reliable is your simulator? analysis on the limitations of current llm-based user simulators for conversational recommendation,
L. Zhu, X. Huang, and J. Sang, “How reliable is your simulator? analysis on the limitations of current llm-based user simulators for conversational recommendation,” inCompanion Proceedings of the ACM Web Conference 2024, 2024, pp. 1726–1732
2024
-
[20]
A LLM-based controllable, scalable, human-involved user simu- lator framework for conversational recommender systems,
——, “A LLM-based controllable, scalable, human-involved user simu- lator framework for conversational recommender systems,” inProceed- ings of the ACM on Web Conference 2025, 2025, pp. 4653–4661
2025
-
[21]
Duetsim: Building user simulator with dual large language models for task-oriented dialogues,
X. Luo, Z. Tang, J. Wang, and X. Zhang, “Duetsim: Building user simulator with dual large language models for task-oriented dialogues,” Proceedings of LREC-COLING 2024, 2024
2024
-
[22]
Build a good human-free prompt tuning: Jointly pre-trained template and verbalizer for few-shot classification,
M. Chen, H. Fu, C. Liu, X. Wang, Z. Li, and J. Sun, “Build a good human-free prompt tuning: Jointly pre-trained template and verbalizer for few-shot classification,”IEEE Transactions on Knowledge and Data Engineering, vol. 37, pp. 2253–2265, 2025
2025
-
[23]
Q. Wang, J. Wu, Z. Tang, B. Luo, N. Chen, W. Chen, and B. He, “What limits llm-based human simulation: Llms or our design?”CoRR, vol. abs/2501.08579, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2501.08579
-
[24]
User simulator assisted open-ended conversational recommendation system,
Q. Zhan, X. Guo, H. Ji, and L. Wu, “User simulator assisted open-ended conversational recommendation system,” inProceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023), Y .-N. Chen and A. Rastogi, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 89–101. [Online]. Available: https://aclanthology.org/202...
2023
-
[25]
The power of scale for parameter-efficient prompt tuning,
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” inProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, 2021, pp. 3045–3059
2021
-
[26]
Promptmm: Multi- modal knowledge distillation for recommendation with prompt-tuning,
W. Wei, J. Tang, L. Xia, Y . Jiang, and C. Huang, “Promptmm: Multi- modal knowledge distillation for recommendation with prompt-tuning,” inProceedings of the ACM Web Conference 2024, ser. WWW ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 3217–3228. [Online]. Available: https://doi.org/10.1145/3589334. 3645359
-
[27]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023, pp. 1–22
2023
-
[28]
On generative agents in recommendation,
A. Zhang, Y . Chen, L. Sheng, X. Wang, and T. S. Chua, “On generative agents in recommendation,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 1807–1817
2024
-
[29]
A survey on large language models for recommendation,
L. Wu, Z. Zheng, Z. Qiu, H. Wang, H. Gu, T. Shen, C. Qin, C. Zhu, H. Zhu, Q. Liuet al., “A survey on large language models for recommendation,”World Wide Web, vol. 27, no. 5, p. 60, 2024
2024
-
[30]
W. Li, X. Wang, W. Li, and B. Jin, “A survey of automatic prompt engi- neering: An optimization perspective,”arXiv preprint arXiv:2502.11560, 2025
-
[31]
A systematic survey of automatic prompt optimization techniques,
K. Ramnath, K. Zhou, S. Guan, S. S. Mishra, X. Qi, Z. Shen, S. Wang, S. Woo, S. Jeoung, Y . Wanget al., “A systematic survey of automatic prompt optimization techniques,”arXiv preprint arXiv:2502.16923, 2025
-
[32]
Optimizing generative ai by backpropagating language model feedback,
M. Yuksekgonul, F. Bianchi, J. Boen, S. Liu, P. Lu, Z. Huang, C. Guestrin, and J. Zou, “Optimizing generative ai by backpropagating language model feedback,”Nature, vol. 639, no. 8055, pp. 609–616, 2025
2025
-
[33]
Usimagent: Large language models for simulating search users,
E. Zhang, X. Wang, P. Gong, Y . Lin, and J. Mao, “Usimagent: Large language models for simulating search users,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 2687–2692
2024
-
[34]
Analysing utterances in LLM-based user simulation for conversational search,
I. Sekuli ´c, M. Alinannejadi, and F. Crestani, “Analysing utterances in LLM-based user simulation for conversational search,”ACM Transac- tions on Intelligent Systems and Technology, vol. 15, pp. 1–22, 2024
2024
-
[35]
The challenge of using llms to simulate human behavior: A causal inference perspective,
G. Gui and O. Toubia, “The challenge of using llms to simulate human behavior: A causal inference perspective,”Columbia Business School Research Paper, 2023
2023
-
[36]
LLMs and generative agent-based models for complex systems research,
Y . Lu, A. Aleta, C. Du, L. Shi, and Y . Moreno, “LLMs and generative agent-based models for complex systems research,”Physics of Life Reviews, vol. 51, pp. 283–293, 2024
2024
-
[37]
HYDRA: Model factorization framework for black-box LLM personalization,
Y . Zhuang, H. Sun, Y . Yu, R. Qiang, Q. Wang, C. Zhang, and B. Dai, “HYDRA: Model factorization framework for black-box LLM personalization,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=CKgNgKmHYp
2024
-
[38]
Simulating user satisfaction for the evaluation of task-oriented dialogue systems,
W. Sun, S. Zhang, K. Balog, Z. Ren, P. Ren, Z. Chen, and M. De Rijke, “Simulating user satisfaction for the evaluation of task-oriented dialogue systems,” inProceedings of the 44th International ACM SIGIR Confer- ence on Research and Development in Information Retrieval, 2021
2021
-
[39]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Y . Hou, J. Li, Z. He, A. Yan, X. Chen, and J. McAuley, “Bridging language and items for retrieval and recommendation,”arXiv preprint arXiv:2403.03952, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
D2k: Turning historical data into retrievable knowledge for recommender systems,
J. Qin, W. Liu, W. Zhang, and Y . Yu, “D2k: Turning historical data into retrievable knowledge for recommender systems,” inProceedings of the ACM on Web Conference 2025, ser. WWW ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 472–482. [Online]. Available: https://doi.org/10.1145/3696410.3714664
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.