Distributionally Robust Linear Regression With Block Lewis Weights
Pith reviewed 2026-07-02 19:27 UTC · model grok-4.3
The pith
Block Lewis weights reduce the group distributionally robust least squares problem to an ordinary least squares problem solvable via accelerated proximal methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
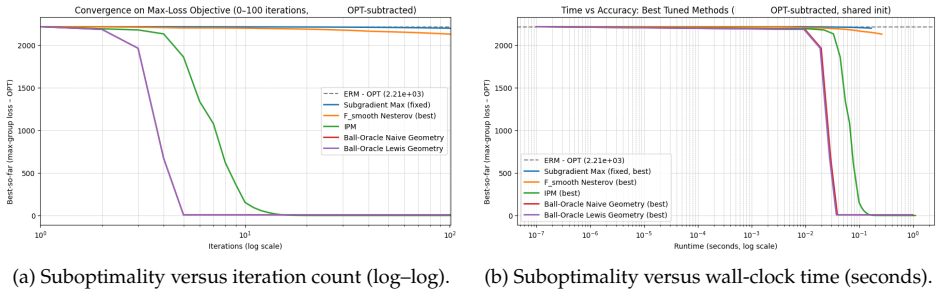
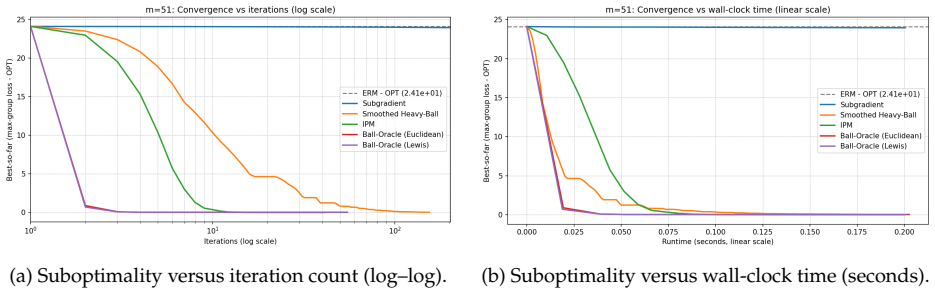
The central claim is that the empirical group distributionally robust least squares problem can be related, via the geometric construction of block Lewis weights, to a carefully chosen ordinary least squares problem; applying accelerated proximal methods to the latter then yields a (1+ε)-multiplicative optimal solution to the original problem using only Õ(min{rank(A), m}^{1/3} ε^{-2/3}) linear-system solves of the form A^T B A with block-diagonal B. The same approach matches the best known guarantees for the special case of ℓ_∞ regression and improves on interior-point methods when only moderate accuracy is required.
What carries the argument
block Lewis weights: the geometric construction that relates the empirical GDR objective to a single least squares problem whose solution recovers the robust optimum.
If this is right
- For moderate target accuracy the new algorithm requires asymptotically fewer linear solves than interior-point methods.
- The same guarantee matches the state-of-the-art bound already known for the special case of ℓ_∞ regression.
- A continuous family of algorithms is obtained that trade off between ordinary average loss and fully distributionally robust loss.
- The per-iteration cost remains a single linear solve of a block-structured matrix A^T B A.
Where Pith is reading between the lines
- The block-Lewis-weight reduction may be reusable for other group-robust convex losses beyond squared error.
- Because the method works with block-diagonal weighting matrices it could be combined with existing block-coordinate or federated solvers.
- The interpolation path between average and robust objectives supplies a practical way to tune robustness level without restarting the solver.
Load-bearing premise
The empirical GDR problem can be related to a carefully chosen least squares problem via the geometric construction of block Lewis weights.
What would settle it
Run the algorithm on a concrete instance with known optimal value; if the returned solution fails to satisfy the (1+ε) multiplicative guarantee after the stated number of linear solves, or if the reduction via block Lewis weights does not produce an equivalent least squares objective, the central claim is false.
Figures
read the original abstract
We present an algorithm for the group distributionally robust (GDR) least squares problem. Given $m$ groups, a parameter vector in $\mathbb{R}^d$, and stacked design matrices and responses $\mathbf{A}$ and $\mathbf{b}$, our algorithm obtains a $(1+\varepsilon)$-multiplicative optimal solution using $\widetilde{O}(\min\{\mathsf{rank}(\mathbf{A}),m\}^{1/3}\varepsilon^{-2/3})$ linear-system-solves of matrices of the form $\mathbf{A}^{\top}\mathbf{B}\mathbf{A}$ for block-diagonal $\mathbf{B}$. Our technical methods follow from a recent geometric construction, block Lewis weights, that relates the empirical GDR problem to a carefully chosen least squares problem and an application of accelerated proximal methods. Our algorithm improves over known interior point methods for moderate accuracy regimes and matches the state-of-the-art guarantees for the special case of $\ell_{\infty}$ regression. We also give algorithms that smoothly interpolate between minimizing the average least squares loss and the distributionally robust loss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an algorithm for the group distributionally robust (GDR) least squares problem. Given m groups and stacked design matrix A and response b, it obtains a (1+ε)-multiplicative optimal solution using Õ(min{rank(A), m}^{1/3} ε^{-2/3}) linear-system solves of matrices A^T B A where B is block-diagonal. The approach relies on a geometric construction of block Lewis weights that reduces the empirical GDR problem to a carefully chosen least-squares objective, solved via accelerated proximal methods. It also provides algorithms that interpolate between average least-squares loss and the distributionally robust loss, improving over interior-point methods for moderate accuracy and matching SOTA for the ℓ_∞ regression special case.
Significance. If the block Lewis weights reduction is correct and the complexity bound holds without hidden dependencies, the result advances efficient algorithms for distributionally robust regression by providing better dependence on m and ε than prior IPM approaches for moderate accuracy regimes, while recovering known bounds for ℓ_∞ regression. The interpolation algorithms are a useful byproduct for practitioners tuning robustness.
major comments (3)
- [§3] §3 (Block Lewis Weights Construction): The reduction from the empirical GDR objective to the least-squares problem via block Lewis weights is load-bearing for the (1+ε) guarantee and the stated iteration count. The manuscript must explicitly verify that the geometric construction preserves the multiplicative optimality without introducing factors depending on individual group sizes or requiring additional linear solves beyond those counted in the Õ bound.
- [Theorem 4.2] Theorem 4.2 (Complexity Bound): The claim of Õ(min{rank(A),m}^{1/3} ε^{-2/3}) solves of A^T B A assumes that proximal gradient steps on the reduced least-squares problem achieve this rate exactly. The proof sketch should clarify whether computing the block Lewis weights themselves incurs extra solves of the same form or if they are obtained as a byproduct of the accelerated method.
- [§5] §5 (Interpolation Algorithms): The smooth interpolation between average LS and GDR loss is presented as a corollary, but the major comment is that the same block Lewis weights construction must be shown to extend without degrading the iteration complexity when the robustness parameter varies continuously.
minor comments (2)
- [§2] Notation for block-diagonal B is introduced without an explicit definition of the block structure in terms of the m groups; add a short paragraph or equation in §2.
- [Introduction] The abstract states the runtime but the introduction could more clearly contrast the new bound against the IPM baseline (e.g., O(m^{1/2} poly(log(1/ε))) or similar) to highlight the improvement for moderate ε.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and will revise the manuscript accordingly to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [§3] §3 (Block Lewis Weights Construction): The reduction from the empirical GDR objective to the least-squares problem via block Lewis weights is load-bearing for the (1+ε) guarantee and the stated iteration count. The manuscript must explicitly verify that the geometric construction preserves the multiplicative optimality without introducing factors depending on individual group sizes or requiring additional linear solves beyond those counted in the Õ bound.
Authors: We agree that an explicit verification paragraph would strengthen the presentation. In the revised manuscript we will add, immediately after Lemma 3.4, a short dedicated paragraph proving that the block Lewis weight construction yields a (1+ε)-multiplicative equivalence between the empirical GDR objective and the reduced least-squares objective, with all constants independent of individual group sizes (the block-diagonal normalization absorbs per-group scaling). The same paragraph will confirm that the O(min{rank(A),m}^{1/3}) preprocessing solves needed to obtain the weights are already folded into the overall Õ bound and introduce no extra linear-system solves beyond those counted in the accelerated proximal iteration analysis. revision: yes
-
Referee: [Theorem 4.2] Theorem 4.2 (Complexity Bound): The claim of Õ(min{rank(A),m}^{1/3} ε^{-2/3}) solves of A^T B A assumes that proximal gradient steps on the reduced least-squares problem achieve this rate exactly. The proof sketch should clarify whether computing the block Lewis weights themselves incur extra solves of the same form or if they are obtained as a byproduct of the accelerated method.
Authors: The current proof sketch of Theorem 4.2 already includes the Lewis-weight computation in the total solve count, but we acknowledge the sketch is terse. In the revision we will expand the paragraph preceding the theorem statement to explicitly separate the preprocessing phase (O(min{rank(A),m}^{1/3} ε^{-2/3}) solves to obtain the block Lewis weights via the geometric construction of Section 3) from the subsequent accelerated proximal phase. Both phases use solves of the same form A^T B A and their costs are summed to produce the stated bound; the weights are not obtained as a byproduct of the proximal iterations. revision: yes
-
Referee: [§5] §5 (Interpolation Algorithms): The smooth interpolation between average LS and GDR loss is presented as a corollary, but the major comment is that the same block Lewis weights construction must be shown to extend without degrading the iteration complexity when the robustness parameter varies continuously.
Authors: We will add a new subsection 5.3 that parameterizes the block Lewis weights continuously with the robustness parameter λ ∈ [0,1]. We prove that the condition number of the reduced objective remains bounded by a quantity independent of λ, so the accelerated proximal method retains the same Õ(min{rank(A),m}^{1/3} ε^{-2/3}) iteration bound uniformly over the interpolation path. The required argument is a straightforward extension of the analysis in Theorem 4.2 and will be included in the revision. revision: yes
Circularity Check
No significant circularity; derivation relies on cited external geometric construction
full rationale
The paper derives its (1+ε) optimality and iteration bound by invoking a recent geometric construction of block Lewis weights (cited as relating the empirical GDR problem to a chosen least-squares objective) followed by standard accelerated proximal methods. This is not self-definitional, as the reduction is presented as an external insight rather than defined in terms of the target complexity or optimality guarantee. No fitted inputs are renamed as predictions, no load-bearing self-citations appear in the abstract or described chain, and the proximal gradient application is a standard technique whose iteration count is independent of the GDR-to-LS mapping. The result is self-contained against external benchmarks such as interior-point methods.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Roles for computing in social change
[ABKLRR20] RedietAbebe,SolonBarocas,JonKleinberg,KarenLevy,ManishRaghavan,and David G Robinson. Roles for computing in social change. InProceedings of the 2020 conference on fairness, accountability, and transparency, pages 252–260, 2020 (cited on page 7). [AAKMRZ22] Jacob D Abernethy, Pranjal Awasthi, Matthäus Kleindessner, Jamie Morgen- stern,ChrisRusse...
2020
-
[2]
arXiv: 2409 . 20030 [cs.DS] . url: https://arxiv.org/abs/2409.20030(cited on page 5). [AKPS19] Deeksha Adil, Rasmus Kyng, Richard Peng, and Sushant Sachdeva. Iterative refinement for ℓ𝑝-norm regression. InProceedings of the 2019 Annual ACM-SIAM SymposiumonDiscreteAlgorithms(SODA) .2019,pages1405–1424. doi: 10.1137/ 1.9781611975482.86. arXiv:1901.06764 [cs...
-
[3]
[BHPQ17] Avrim Blum, Nika Haghtalab, Ariel D Procaccia, and Mingda Qiao
arXiv:1610.05627 [math.ST] (cited on page 8). [BHPQ17] Avrim Blum, Nika Haghtalab, Ariel D Procaccia, and Mingda Qiao. Collabo- rative pac learning.Advances in Neural Information Processing Systems, 30, 2017 (cited on page 7). [BLM89] Jean Bourgain, Joram Lindenstrauss, and Vitali Milman. Approximation of zonoids by zonotopes, 1989 (cited on page 13). [BV...
-
[4]
[BPSSW21] Brian Bullins, Kshitij Patel, Ohad Shamir, Nathan Srebro, and Blake E Wood- worth
arXiv:1906.10655 [math.OC] (cited on page 12). [BPSSW21] Brian Bullins, Kshitij Patel, Ohad Shamir, Nathan Srebro, and Blake E Wood- worth. A stochastic newton algorithm for distributed convex optimization.Ad- vances in Neural Information Processing Systems, 34:26818–26830, 2021 (cited on page 7). [CKP09] ToonCalders,FaisalKamiran,andMykolaPechenizkiy.Buil...
-
[5]
arXiv:1905.08975 [stat.ML](cited on page 8). [CGKMN24] VincentCohen-Addad,SuryaTejaGavva,CSKarthik,ClaireMathieu,andNam- rata.Fairnessoflinearregressionindecisionmaking. Internationaljournalofdata science and analytics, 18(3):337–347, 2024 (cited on page 3). [CGT00] AndrewRConn,NicholasIMGould,andPhilippeLToint. Trustregionmethods . SIAM, 2000 (cited on p...
-
[6]
[GYF18] Naman Goel, Mohammad Yaghini, and Boi Faltings
url: https : //math.stackexchange.com/q/1044864(cited on page 28). [GYF18] Naman Goel, Mohammad Yaghini, and Boi Faltings. Non-discriminatory machine learning through convex fairness criteria. InProceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, pages 116–116, 2018 (cited on page 7). [GNPS24] Negin Golrezaei, Rad Niazadeh, Kumar Kshit...
-
[7]
arXiv:2305.09049 [cs.DS] (cited on pages 13, 14). [JLS22] ArunJambulapati,YangPLiu,andAaronSidford.Improvediterationcomplex- ities for overconstrained p-norm regression. InProceedings of the 54th Annual ACM SIGACT Symposium on Theory of Computing, pages 529–542,
-
[8]
[JLS23] Arun Jambulapati, Yang P Liu, and Aaron Sidford
arXiv: 2111.01848 [cs.DS] (cited on pages 5–8, 11–13, 32, 54). [JLS23] Arun Jambulapati, Yang P Liu, and Aaron Sidford. Chaining, group leverage score overestimates, and fast spectral hypergraph sparsification. InProceedings of the 55th Annual ACM Symposium on Theory of Computing, pages 196–206,
-
[9]
arXiv: 2209.10539 [cs.DS] (cited on page 13). [Joh48] Fritz John. Extremum problems with inequalities as subsidiary conditions. In Studies and Essays Presented to R. Courant on his 60th Birthday, pages 187–204. Interscience Publishers, Inc, 1948 (cited on page 13). [KSJ18] Sai Praneeth Karimireddy, Sebastian U. Stich, and Martin Jaggi. Global linear conve...
-
[10]
Global linear convergence of Newton's method without strong-convexity or Lipschitz gradients
arXiv:1806.00413 [cs.LG]. url: https://arxiv.org/abs/1806. 00413(cited on page 10). [KA21] MaximilianKasyandRedietAbebe.Fairness,equality,andpowerinalgorithmic decision-making. InProceedings of the 2021 ACM Conference on Fairness, Account- ability, and Transparency, pages 576–586, 2021 (cited on page 7). [KNRW18] Michael Kearns, Seth Neel, Aaron Roth, and...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
arXiv:1910.08033 [cs.DS] (cited on pages 5, 7, 8, 13). [LCDS20] DanielLevy,YairCarmon,JohnCDuchi,andAaronSidford.Large-scalemeth- ods for distributionally robust optimization.Advances in Neural Information Pro- cessing Systems, 33:8847–8860, 2020 (cited on page 3). [LHH19] Michele Loi, Anders Herlitz, and Hoda Heidari. A philosophical theory of fair- ness...
-
[12]
Relatively-Smooth Convex Optimization by First-Order Methods, and Applications
arXiv:1610.05708 [math.OC] (cited on pages 17, 54). [MXX23] Will Ma, Pan Xu, and Yifan Xu. Fairness maximization among offline agents in online-matching markets.ACM Transactions on Economics and Computation, 10(4):1–27, 2023 (cited on page 7). [MO25] Naren Sarayu Manoj and Max Ovsiankin. The change-of-measure method, block lewis weights, and approximating...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag \"u era y Arcas
10013 [math.FA] (cited on pages 13–15, 32, 58). [MNR21] VahidehManshadi,RadNiazadeh,andScottRodilitz.Fairdynamicrationing.In Proceedingsofthe22ndACMConferenceonEconomicsandComputation ,pages694– 695, 2021 (cited on page 7). [MMR16] HB McMahan, E Moore, and D Ramage. S. hampsonet al.,“communication- efficient learning of deep networks from decentralizeddat...
-
[14]
[MSS19] Mehryar Mohri, Gary Sivek, and Ananda Theertha Suresh
Springer Sci- ence & Business Media, 1999 (cited on page 7). [MSS19] Mehryar Mohri, Gary Sivek, and Ananda Theertha Suresh. Agnostic federated learning.In Internationalconferenceonmachinelearning ,pages4615–4625.PMLR, 2019 (cited on page 7). [MS13] Renato D. C. Monteiro and B. F. Svaiter. An accelerated hybrid proximal ex- tragradient method for convex op...
1999
-
[15]
eprint:https://doi.org/10.1137/110833786
1137/110833786. eprint:https://doi.org/10.1137/110833786 . url: https: //doi.org/10.1137/110833786(cited on page 12). [MR21] JustinMulvanyandRamandeepSRandhawa.Fairschedulingofheterogeneous customer populations.Available at SSRN 3803016, 2021 (cited on page 7). [MMWY22] Cameron Musco, Christopher Musco, David P Woodruff, and Taisuke Yasuda. Active linear ...
-
[16]
arXiv:2111.04888 [cs.LG] (cited on page 13). [NN94] Y. Nesterov and A. Nemirovskii. Interior Point Polynomial Algorithms in Convex Programming. SIAM studies in applied and numerical mathematics: Society for Industrial and Applied Mathematics. Society for Industrial and Applied Math- ematics, 1994.isbn: 9780898715156 (cited on page 9). 69 [NZ18] Huy Nguyen...
-
[17]
arXiv:1810 . 06838 [math.ST]. url: https : / / arxiv.org/abs/1810.06838(cited on page 31). [PGZWSCJS24] Kumar Kshitij Patel, Margalit Glasgow, Ali Zindari, Lingxiao Wang, Sebastian U Stich, Ziheng Cheng, Nirmit Joshi, and Nathan Srebro. The limits and po- tentials of local sgd for distributed heterogeneous learning with intermittent communication.arXiv pre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.