A Methodology for Investigating AI Patterns Prevalence in Software Repositories
Pith reviewed 2026-07-02 08:55 UTC · model grok-4.3
The pith
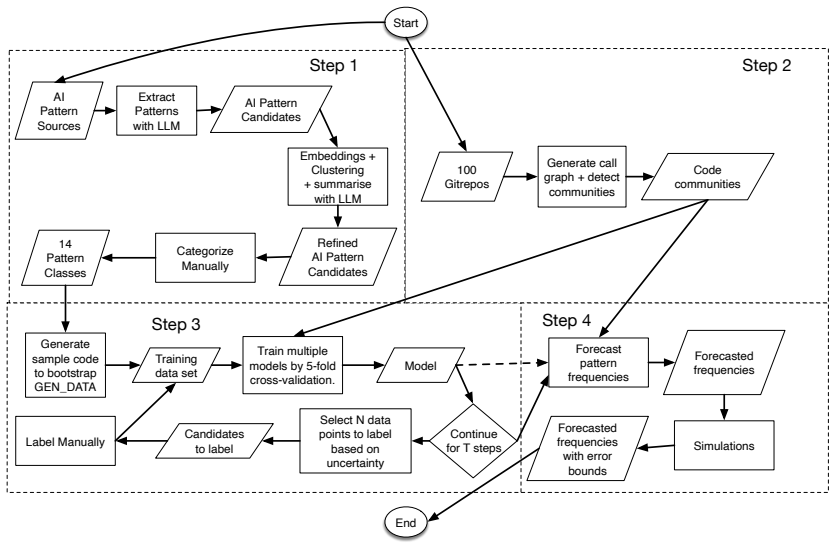
A methodology first extracts 14 AI pattern classes from literature then applies active learning to measure their occurrence in GitHub repositories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
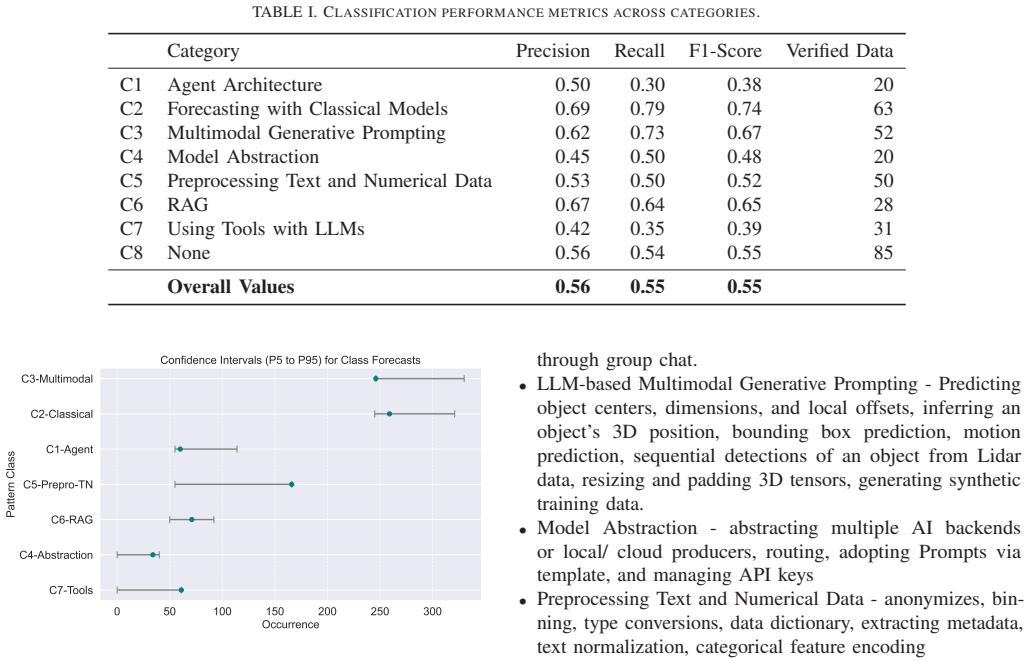
Mining 44 published AI pattern sources yields 14 distinct pattern classes. An active-learning procedure is then used to classify code snippets drawn from 100 GitHub AI repositories for the most common class, producing a classifier with 56 percent accuracy and 55 percent recall that exceeds the 11 percent random baseline; prevalence estimation supplies usable numeric bounds on how frequently the pattern appears.
What carries the argument
Active learning pipeline that trains on literature-derived pattern labels to classify repository code and derive prevalence bounds.
If this is right
- The 14 classes supply a working taxonomy for categorizing AI code practices.
- Prevalence bounds give quantitative guidance on which patterns occur often enough to warrant attention.
- The active-learning workflow can be rerun on new repositories to update the estimates.
- The overall method offers a repeatable template for turning proposed patterns into measured usage data.
Where Pith is reading between the lines
- The same literature-to-repository pipeline could be applied to track whether pattern usage changes when major AI libraries release new versions.
- Prevalence numbers might inform curriculum design so that training materials emphasize patterns that actually dominate production code.
- If the method scales to thousands of repositories it could expose correlations between pattern choice and project outcomes such as maintainability metrics.
Load-bearing premise
The 44 literature sources capture all relevant AI patterns and the labels obtained from the 100 chosen repositories extend to the wider population of AI code.
What would settle it
A manual audit of several hundred additional AI repositories that places the true frequency of the most common pattern class outside the numeric bounds produced by the prevalence estimator.
Figures

read the original abstract
As Artificial Intelligence(AI)-based applications take off, a clear understanding of AI patterns can uplift the quality of AI applications. Many AI patterns have been proposed in the literature; however, their prevalence in real-life code has not yet been validated. Understanding the actual use of those patterns in practice can clarify our understanding both of the significance of these patterns and their utility. In this paper, we present a methodology to a) identify relevant patterns by mining the literature and then to b) validate their presence and prevalence in actual code repositories using active learning. To that end, we identify 14 AI pattern classes by mining 44 published AI pattern-related sources. Then we use an active learning approach to determine the prevalence of the most common pattern class across 100 GitHub open AI repositories. Using prevalence estimation, we propose bounds on the accuracy of the occurrences. The model achieves 56\% accuracy and 55\% recall in an 8-way classification task, significantly outperforming the 11\% random-chance baseline. Furthermore, the prevalence estimation offers usable bounds for analyzing pattern applications. This methodology provides a robust foundation to start understanding how AI patterns are used in practice, a field that currently lacks empirical data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-part methodology: first mining 44 published sources to derive 14 AI pattern classes, then applying active learning to label and estimate the prevalence of the most common class across 100 GitHub AI repositories. It reports an 8-way classifier achieving 56% accuracy and 55% recall (vs. 11% random baseline) and supplies prevalence bounds derived from the labels.
Significance. If the sampling frame and label quality can be shown to support generalization, the work would supply the first quantitative prevalence data on AI patterns in open-source code, filling a documented empirical gap. The combination of literature synthesis with active-learning prevalence estimation is a reasonable starting point, but the modest classifier performance and absent sampling details limit the strength of any prevalence claims.
major comments (2)
- [Abstract] Abstract: the reported 56% accuracy and 55% recall in the 8-way task are only modestly above the 11% baseline; without any description of the class distribution, data splits, or how label noise was propagated into the prevalence bounds, it is impossible to determine whether the classifier supports usable prevalence intervals for the dominant pattern class.
- [Abstract] Abstract: no repository selection protocol (search terms, star/fork thresholds, language filters, or sampling frame) is stated for the 100 GitHub repositories; if the sample is popularity-biased or convenience-selected, the prevalence bounds cannot be claimed to generalize beyond the chosen set.
minor comments (1)
- [Abstract] Abstract: "As Artificial Intelligence(AI)-based" is missing a space after the parenthesis.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight areas where the abstract can be improved to better support the claims. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 56% accuracy and 55% recall in the 8-way task are only modestly above the 11% baseline; without any description of the class distribution, data splits, or how label noise was propagated into the prevalence bounds, it is impossible to determine whether the classifier supports usable prevalence intervals for the dominant pattern class.
Authors: We agree that the abstract should include more information on class distribution, data splits, and label noise propagation to allow assessment of the prevalence intervals. We will revise the abstract to incorporate brief descriptions of these aspects based on the methodology in the full paper. Regarding the performance metrics, we note that for an 8-way classification task the results are substantially better than random and enable the prevalence estimation presented. revision: yes
-
Referee: [Abstract] Abstract: no repository selection protocol (search terms, star/fork thresholds, language filters, or sampling frame) is stated for the 100 GitHub repositories; if the sample is popularity-biased or convenience-selected, the prevalence bounds cannot be claimed to generalize beyond the chosen set.
Authors: We concur that the abstract lacks a description of how the 100 repositories were selected. We will revise the abstract to include the repository selection protocol, specifying the search terms, thresholds, language filters, and sampling frame. We will also clarify the scope of the prevalence bounds to the selected set of repositories. revision: yes
Circularity Check
No significant circularity; empirical methodology is self-contained
full rationale
The paper describes a two-stage empirical process: (1) manual mining of 44 literature sources to enumerate 14 pattern classes, followed by (2) active-learning classification on a sample of 100 GitHub repositories to estimate prevalence of the dominant class. No equations, fitted parameters, or self-citations are present that would reduce the reported 56% accuracy, 55% recall, or prevalence bounds to the input labels or source list by construction. The accuracy figure is explicitly compared to an 11% random baseline, and the methodology is presented as a starting point rather than a closed deductive chain. The representativeness concerns raised in the skeptic note are validity issues, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 44 published sources contain the relevant AI patterns that should be studied.
Reference graph
Works this paper leans on
-
[1]
A survey on evaluation of large language mod- els
Y . Chang et al., “A survey on evaluation of large language mod- els”,ACM Transactions on Intelligent Systems and Technology, vol. 15, no. 3, pp. 1–45, 2024.DOI: 10.1145/3641289
-
[2]
Retrieval-augmented generation for knowledge- intensive NLP tasks
P. Lewis et al., “Retrieval-augmented generation for knowledge- intensive NLP tasks”, inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 9459–9474
2020
-
[3]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao et al., “ReAct: Synergizing reasoning and acting in language models”,arXiv preprint arXiv:2210.03629, 2023. Accessed: Jan. 9, 2026. [Online]. Available: https://arxiv.org/ abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
LLM-based multi-agent systems for software engineering: Literature review, vision, and the road ahead
J. He, C. Treude, and D. Lo, “LLM-based multi-agent systems for software engineering: Literature review, vision, and the road ahead”,ACM Transactions on Software Engineering and Methodology, vol. 34, no. 5, pp. 1–30, 2025.DOI: 10.1145/ 3702989
2025
-
[5]
Gamma, R
E. Gamma, R. Helm, R. Johnson, and J. Vlissides,Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley Professional, 1995
1995
-
[6]
Is that true...? thoughts on the episte- mology of patterns
C. Kohls and S. Panke, “Is that true...? thoughts on the episte- mology of patterns”, inProceedings of the 16th Conference on Pattern Languages of Programs, 2009, pp. 1–14
2009
-
[7]
A survey on active learning: State-of-the-art, practical challenges and research directions
A. Tharwat and W. Schenck, “A survey on active learning: State-of-the-art, practical challenges and research directions”, Mathematics, vol. 11, no. 4, p. 820, 2023
2023
-
[8]
Gen- eralized Louvain method for community detection in large networks
P. De Meo, E. Ferrara, G. Fiumara, and A. Provetti, “Gen- eralized Louvain method for community detection in large networks”, in2011 11th International Conference on Intelli- gent Systems Design and Applications (ISDA), IEEE, 2011, pp. 88–93.DOI: 10.1109/ISDA.2011.6121634
-
[9]
Huang,LLM Design Patterns: A Practical Guide to Building Robust and Efficient AI Systems
K. Huang,LLM Design Patterns: A Practical Guide to Building Robust and Efficient AI Systems. O’Reilly Media, 2025
2025
-
[10]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
A. Singh, A. Ehtesham, S. Kumar, and T. T. Khoei, “Agentic retrieval-augmented generation: A survey on agentic rag”,arXiv preprint arXiv:2501.09136, 2025. [Online]. Available: https: //arxiv.org/abs/2501.09136
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Gullí,Agentic Design Patterns
A. Gullí,Agentic Design Patterns. Packt Publishing, 2024
2024
-
[12]
Emerging patterns in building GenAI products
B. Subramaniam, “Emerging patterns in building GenAI products”, 2024, Accessed: Jan. 22, 2026. [Online]. Available: https://martinfowler.com/articles/gen-ai-patterns/
2024
-
[13]
Agentic AI architectures and design patterns
A. Jain, “Agentic AI architectures and design patterns”, 2024, Accessed: Jan. 22, 2026. [Online]. Available: https://medium. com/@anil.jain.baba/agentic- ai- architectures- and- design- patterns-288ac589179a
2024
-
[14]
AWS prescriptive guidance: Patterns: AI & machine learning
Amazon Web Services, “AWS prescriptive guidance: Patterns: AI & machine learning”, 2026, Accessed: Jan. 22, 2026. [Online]. Available: https://docs.aws.amazon.com/prescriptive- guidance/latest/patterns/machinelearning-pattern-list.html
2026
-
[15]
Agent system design patterns
Databricks, “Agent system design patterns”, 2026, Accessed: Jan. 22, 2026. [Online]. Available: https://docs.databricks.com/ aws/en/generative-ai/guide/agent-system-design-patterns
2026
-
[16]
M. Arslan, H. Ghanem, S. Munawar, and C. Cruz, “A survey on RAG with LLMs”,Procedia Computer Science, vol. 246, pp. 3781–3790, 2024.DOI: 10.1016/j.procs.2024.11.123
-
[17]
Retrieval-augmented generation (RAG) patterns and best practices
J. Alammar, “Retrieval-augmented generation (RAG) patterns and best practices”, InfoQ, 2024, Accessed: Jan. 22, 2026. [Online]. Available: https : / / www. youtube . com / watch ? v = eUY9i1CWmUg
2024
-
[18]
GraphRAG field guide: RAG patterns
Neo4j, “GraphRAG field guide: RAG patterns”, 2026, Accessed: Jan. 22, 2026. [Online]. Available: https://neo4j.com/blog/ developer/graphrag-field-guide-rag-patterns/
2026
-
[19]
Lakshmanan, S
V . Lakshmanan, S. Robinson, and M. Munn,Machine Learning Design Patterns. O’Reilly Media, Inc., 2020. Accessed: Jan. 22, 2026
2020
-
[20]
Solution patterns for machine learning
N. Soroosh et al., “Solution patterns for machine learning”, inInternational Conference on Advanced Information Systems Engineering (CAiSE), Springer, 2019, pp. 43–58
2019
-
[21]
Software-engineering design patterns for machine learning applications
H. Washizaki et al., “Software-engineering design patterns for machine learning applications”,Computer, vol. 55, no. 3, pp. 30–39, 2022.DOI: 10.1109/MC.2021.3139049
-
[22]
A pattern language for machine learning tasks
R. Benjamin et al., “A pattern language for machine learning tasks”,arXiv preprint arXiv:2407.02424v2, 2025. [Online]. Available: https://arxiv.org/abs/2407.02424
-
[23]
Design pattern recognition: A study of large language models
S. K. Pandey et al., “Design pattern recognition: A study of large language models”,Empirical Software Engineering, vol. 30, no. 3, p. 69, 2025
2025
-
[24]
Ai patterns github repository
“Ai patterns github repository”, 2026, Accessed: Jan. 27, 2026. [Online]. Available: https://github.com/wso2- incubator/ai- patterns
2026
-
[25]
Design recovery by automated search for structural design patterns in object-oriented soft- ware
C. Kramer and L. Prechelt, “Design recovery by automated search for structural design patterns in object-oriented soft- ware”, inProceedings of WCRE’96: 3rd Working Conference on Reverse Engineering, IEEE, 1996, pp. 208–215.DOI: 10. 1109/WCRE.1996.558906
-
[26]
Design pattern detection using FINDER
H. Dabain, A. Manzer, and V . Tzerpos, “Design pattern detection using FINDER”, inProceedings of the 30th Annual ACM Symposium on Applied Computing, 2015, pp. 1554–1560. DOI: 10.1145/2695664.2695755
-
[27]
Flexible design pattern detection based on feature types
G. Rasool and P. Mäder, “Flexible design pattern detection based on feature types”,Automated Software Engineering, vol. 18, no. 3-4, pp. 339–365, 2011.DOI: 10.1007/s10515-011- 0084-2
-
[28]
Ensuring and assess- ing architecture conformance to microservice decomposition patterns
U. Zdun, E. Navarro, and F. Leymann, “Ensuring and assess- ing architecture conformance to microservice decomposition patterns”, inInternational Conference on Service-Oriented Computing, Springer, 2017, pp. 411–429
2017
-
[29]
Design pattern detection based on the graph theory
B. B. Mayvan and A. Rasoolzadegan, “Design pattern detection based on the graph theory”,Knowledge-Based Systems, vol. 120, pp. 211–225, 2017
2017
-
[30]
Design pattern detection using similarity scoring
N. Tsantalis, A. Chatzigeorgiou, G. Stephanides, and S. T. Halkidis, “Design pattern detection using similarity scoring”, IEEE Transactions on Software Engineering, vol. 32, no. 11, pp. 896–909, 2006.DOI: 10.1109/TSE.2006.112
-
[31]
Geml: A grammar-based evolutionary machine learning approach for design-pattern detection
R. Barbudo, A. Ramírez, F. Servant, and J. R. Romero, “Geml: A grammar-based evolutionary machine learning approach for design-pattern detection”,Journal of Systems and Software, vol. 175, pp. 110–919, 2021
2021
-
[32]
Design pattern detection using software metrics and machine learning
S. Uchiyama, H. Washizaki, and Y . Fukazawa, “Design pattern detection using software metrics and machine learning”, inFirst International Workshop on Model-Driven Software Migration (MDSM 2011), 2011, pp. 38–42
2011
-
[33]
Software design pattern mining using classification-based techniques
A. K. Dwivedi, A. Tirkey, and S. K. Rath, “Software design pattern mining using classification-based techniques”,Frontiers of Computer Science, vol. 12, no. 5, pp. 908–922, 2018
2018
-
[34]
A. Chihada, V . Arnaoudova, L. M. Eshkevari, G. Antoniol, and Y .-G. Gueheneuc, “Source code and design conformance, design pattern detection from source code by classification approach”,Applied Soft Computing, vol. 26, pp. 357–367, 2015.DOI: 10.1016/j.asoc.2014.09.043
-
[35]
On applying machine learning techniques for design pattern detection
M. Zanoni, F. A. Fontana, and F. Stella, “On applying machine learning techniques for design pattern detection”,Journal of Systems and Software, vol. 103, pp. 102–117, 2015.DOI: 10. 1016/j.jss.2015.01.037
2015
-
[36]
Feature-based software design pattern detection
N. Nazar, A. Aleti, and Y . Zheng, “Feature-based software design pattern detection”,Journal of Systems and Software, vol. 185, pp. 111–179, 2022
2022
-
[37]
P-mart: Pattern-like micro architecture repository
Y .-G. Guéhéneuc, “P-mart: Pattern-like micro architecture repository”,Proceedings of the 1st EuroPLoP Focus Group on pattern repositories, pp. 1–3, 2007
2007
-
[38]
DPB: A bench- mark for design pattern detection tools
F. A. Fontana, A. Caracciolo, and M. Zanoni, “DPB: A bench- mark for design pattern detection tools”, in2012 16th European Conference on Software Maintenance and Reengineering, IEEE, 2012, pp. 235–244.DOI: 10.1109/CSMR.2012.33
-
[39]
Exploring design patterns in quantum software: A case study
M. Fernández-Osuna, M. A. Pérez-Delgado, M. Rojo-Martínez, and M. Piattini, “Exploring design patterns in quantum software: A case study”,Computing, vol. 107, no. 5, pp. 1–31, 2025. DOI: 10.1007/s00607-024-01365-z
-
[40]
Cross-validation is safe to use
R. D. King, O. I. Orhobor, and C. C. Taylor, “Cross-validation is safe to use”,Nature Machine Intelligence, vol. 3, no. 4, pp. 276–276, 2021
2021
-
[41]
Sample size planning for classification models
C. Beleites, U. Neugebauer, T. Bocklitz, C. Krafft, and J. Popp, “Sample size planning for classification models”,Analytica chimica acta, vol. 760, pp. 25–33, 2013
2013
-
[42]
K. Du et al., “Codegrag: Bridging the gap between natural language and programming language via graphical retrieval aug- mented generation”,arXiv preprint arXiv:2405.02355, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.