From Pixels to Temporal Correlations: Learning Informative Representations for Reinforcement Learning Pre-training
Pith reviewed 2026-07-02 15:56 UTC · model grok-4.3
The pith
Modeling multi-scale temporal correlations separately in a dedicated space produces balanced video representations that support better reinforcement learning policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
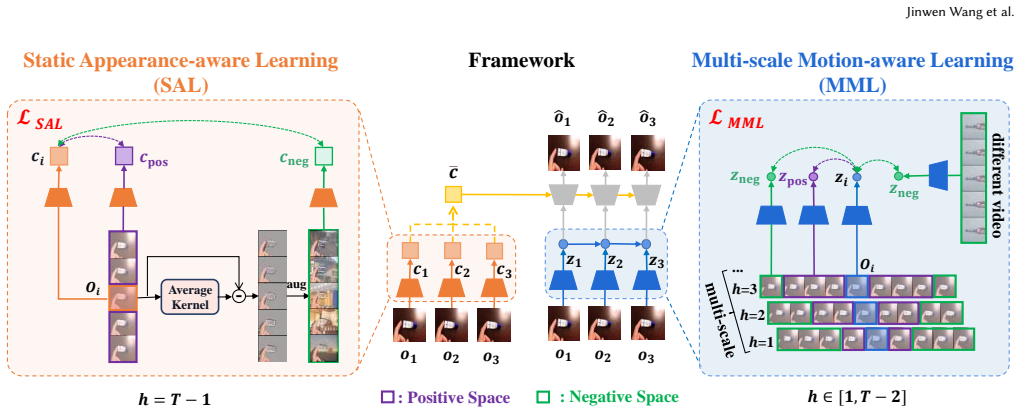
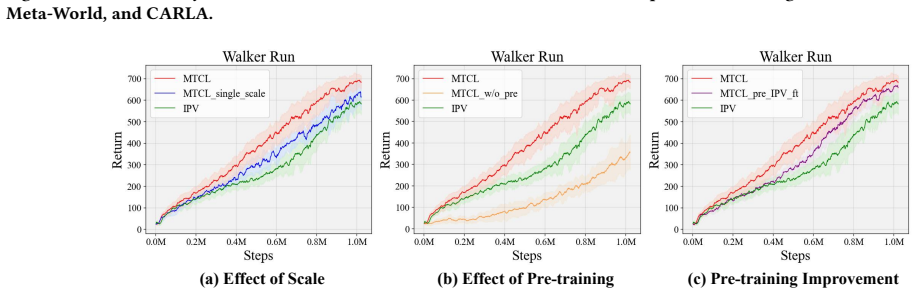
The paper claims that introducing a temporal correlation space to distinguish each element in videos, together with the Multi-scale Temporal Contrastive Learning method that models multi-scale temporal correlations separately, balances attention across elements and preserves small-scale information that single-step or reconstruction methods discard due to stationary bias, thereby producing more informative representations that support policy learning in various downstream tasks.
What carries the argument
The Multi-scale Temporal Contrastive Learning (MTCL) method, which models multi-scale temporal correlations separately inside a temporal correlation space to equalize attention to video elements.
If this is right
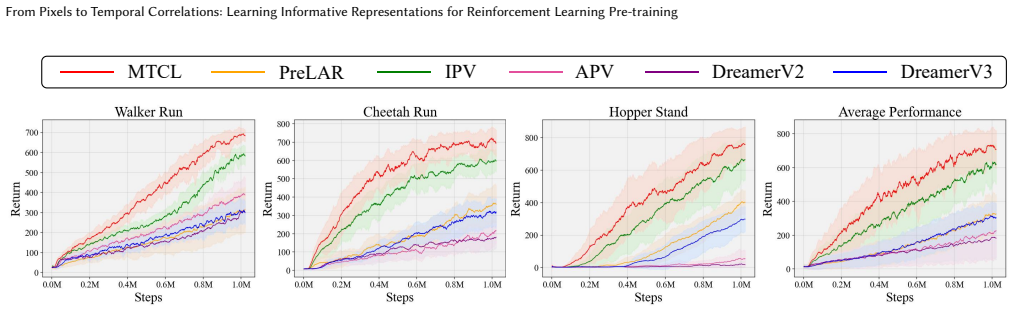
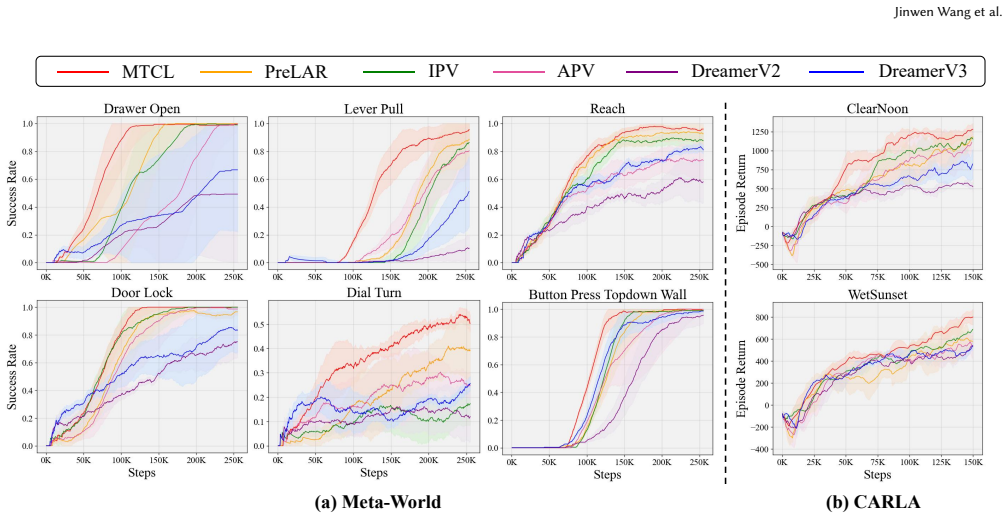
- Representations from MTCL improve sample efficiency across various downstream RL tasks.
- Representations from MTCL improve asymptotic performance across various downstream RL tasks.
- The method supports effective policy learning in multiple different downstream tasks.
- MTCL avoids the preference for large-proportion stationary information that affects single-step and reconstruction pre-training.
Where Pith is reading between the lines
- The same separation of temporal scales could be tested on non-RL video tasks such as action recognition or future-frame prediction to check generality.
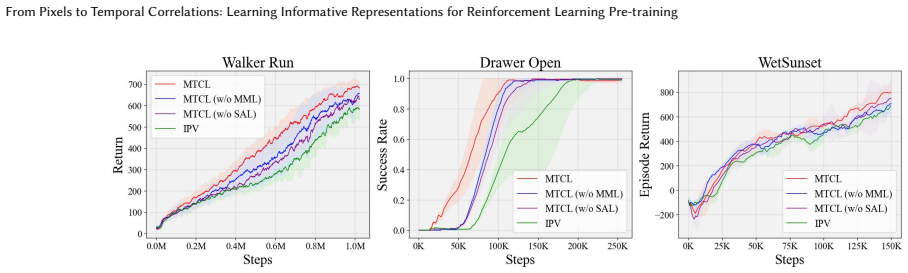
- If the correlation space truly balances elements, ablating individual scales should produce measurable drops in downstream RL metrics that single-scale versions cannot recover.
- The approach implies that contrastive objectives grounded in explicit temporal distinctions may transfer more reliably than reconstruction objectives when video data contains both static backgrounds and sparse motion.
Load-bearing premise
That separating multi-scale temporal correlations in a dedicated space will avoid the stationary bias of prior methods while still preserving all necessary information for downstream policy learning.
What would settle it
Run MTCL pre-training on the same video dataset as a single-step baseline, then fine-tune both on an identical RL task and measure whether MTCL shows no gain or a loss in sample efficiency or final performance.
Figures



read the original abstract
Unsupervised pre-training on large-scale datasets has demonstrated significant potential for improving the sample efficiency and performance of Reinforcement Learning (RL). Given the large-scale action-free internet videos, existing methods utilize single-step transition prediction and image reconstruction to learn representations. However, these methods prefer to preserve large-proportion stationary information in the pixel space, neglecting small but crucial information. To preserve enough information in the representation, it is essential to pay equal attention to each element in videos. Specifically, we propose a temporal correlation space to distinguish each element. For implementation, we introduce the Multi-scale Temporal Contrastive Learning (MTCL) method to model multi-scale temporal correlations separately. This approach can balance the attention of different elements and yield more informative representations, effectively supporting policy learning in various downstream tasks. Experimental results demonstrate that our method improves sample efficiency and asymptotic performance across various downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-scale Temporal Contrastive Learning (MTCL) operating in a temporal correlation space to learn representations from action-free internet videos for RL pre-training. It argues that single-step transition prediction and image reconstruction methods over-emphasize stationary pixel information and neglect small but crucial details; MTCL models multi-scale temporal correlations separately to balance attention across elements and produce more informative representations that improve sample efficiency and asymptotic performance on downstream RL tasks.
Significance. If the empirical claims hold with proper controls, the work would provide a concrete alternative to reconstruction- and single-step-based pre-training for RL by explicitly targeting multi-scale temporal structure, potentially yielding representations that better support policy learning across tasks. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described.
major comments (1)
- [Abstract] Abstract: the central empirical claim (improved sample efficiency and asymptotic performance across downstream tasks) is asserted without any methods details, baselines, error bars, dataset descriptions, or result tables, so the support for the claim cannot be assessed from the provided text.
Simulated Author's Rebuttal
We thank the referee for their feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (improved sample efficiency and asymptotic performance across downstream tasks) is asserted without any methods details, baselines, error bars, dataset descriptions, or result tables, so the support for the claim cannot be assessed from the provided text.
Authors: We agree that the abstract is necessarily concise and therefore omits methodological specifics, baseline names, quantitative results with error bars, and dataset details. The full manuscript supplies these in the Methods (MTCL formulation and multi-scale contrastive objectives) and Experiments sections (baselines, datasets of action-free internet videos, multiple random seeds with error bars, and tables showing gains in sample efficiency and asymptotic performance). We will revise the abstract to incorporate a brief description of the MTCL approach and a high-level summary of the empirical outcomes while remaining within length constraints. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central contribution is an empirical unsupervised pre-training method (MTCL) that constructs a temporal correlation space and models multi-scale correlations to learn representations for RL. No equations, derivations, or first-principles claims are present that reduce any result to a fitted parameter or self-referential definition by construction. The abstract and described approach motivate the method via avoidance of stationary bias but do not invoke self-citations as load-bearing uniqueness theorems, smuggle ansatzes, or rename known results as new derivations. Claims of improved sample efficiency rest on experimental results rather than tautological reductions, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing single-step transition prediction and image reconstruction methods preferentially preserve large-proportion stationary information while neglecting small but crucial information.
- domain assumption Paying equal attention to each element in videos via multi-scale temporal correlations will produce more informative representations for downstream RL.
invented entities (1)
-
Multi-scale Temporal Contrastive Learning (MTCL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Variational Inference: A Review for Statisticians
David M. Blei, Alp Kucukelbir, and Jon D. McAuliffe. 2016. Variational Inference: A Review for Statisticians.CoRRabs/1601.00670 (2016). arXiv:1601.00670 http: //arxiv.org/abs/1601.00670
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
- [3]
-
[4]
Swaroop Guntupalli, Miguel Lázaro-Gredilla, and Kevin Patrick Mur- phy
Antoine Dedieu, Joseph Ortiz, Xinghua Lou, Carter Wendelken, Wolfgang Lehrach, J. Swaroop Guntupalli, Miguel Lázaro-Gredilla, and Kevin Patrick Mur- phy. 2025. Improving Transformer World Models for Data-Efficient RL.CoRR abs/2502.01591 (2025). arXiv:2502.01591 doi:10.48550/ARXIV.2502.01591
-
[5]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InProceedings of the 2019 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, V...
-
[6]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In9th Interna- tional Conference on Learning Representations, IC...
2021
-
[7]
López, and Vladlen Koltun
Alexey Dosovitskiy, Germán Ros, Felipe Codevilla, Antonio M. López, and Vladlen Koltun. 2017. CARLA: An Open Urban Driving Simulator. In1st An- nual Conference on Robot Learning, CoRL 2017, Mountain View, California, USA, November 13-15, 2017, Proceedings (Proceedings of Machine Learning Research, Vol. 78). PMLR, 1–16. http://proceedings.mlr.press/v78/dos...
2017
-
[8]
Dibya Ghosh, Chethan Anand Bhateja, and Sergey Levine. 2023. Reinforcement Learning from Passive Data via Latent Intentions. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceed- ings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabat...
2023
-
[9]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fründ, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. 2017. The "Something Something" Video Database for Learning and Evaluating Visual Common Sense. InIEEE International C...
- [10]
-
[11]
Lillicrap, Jimmy Ba, and Mohammad Norouzi
Danijar Hafner, Timothy P. Lillicrap, Jimmy Ba, and Mohammad Norouzi. 2020. Dream to Control: Learning Behaviors by Latent Imagination. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=S1lOTC4tDS
2020
-
[12]
Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson
Danijar Hafner, Timothy P. Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. 2019. Learning Latent Dynamics for Plan- ning from Pixels. InProceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA (Proceedings of Machine Learning Research, Vol. 97), Kamalika...
2019
-
[13]
Lillicrap, Mohammad Norouzi, and Jimmy Ba
Danijar Hafner, Timothy P. Lillicrap, Mohammad Norouzi, and Jimmy Ba. 2021. Mastering Atari with Discrete World Models. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=0oabwyZbOu
2021
-
[14]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy P. Lillicrap. 2023. Mastering Diverse Domains through World Models.CoRRabs/2301.04104 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Efros, Lerrel Pinto, and Xiaolong Wang
Nicklas Hansen, Rishabh Jangir, Yu Sun, Guillem Alenyà, Pieter Abbeel, Alexei A. Efros, Lerrel Pinto, and Xiaolong Wang. 2021. Self-Supervised Policy Adaptation during Deployment. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https:// openreview.net/forum?id=o_V-MjyyGV_
2021
-
[16]
Nicklas Hansen, Hao Su, and Xiaolong Wang. 2021. Stabilizing Deep Q-Learning with ConvNets and Vision Transformers under Data Augmentation. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural In- formation Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. D...
2021
-
[17]
Nicklas Hansen, Hao Su, and Xiaolong Wang. 2022. Temporal Difference Learning for Model Predictive Control. InInternational Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato (E...
2022
-
[18]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross B. Girshick. 2022. Masked Autoencoders Are Scalable Vision Learners. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 15979–15988. doi:10.1109/CVPR52688.2022.01553
-
[19]
Girshick
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. 2020. Momentum Contrast for Unsupervised Visual Representation Learning. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, W A, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 9726–
2020
-
[20]
doi:10.1109/CVPR42600.2020.00975
-
[21]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. IEEE Computer Society, 770–778. doi:10.1109/CVPR.2016.90
-
[22]
Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei- Fei. 2023. VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models. InConference on Robot Learning, CoRL 2023, 6-9 November 2023, Atlanta, GA, USA (Proceedings of Machine Learning Research, Vol. 229), Jie Tan, Marc Toussaint, and Kourosh Darvish (Eds.). PMLR...
2023
-
[23]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. 2020. RLBench: The Robot Learning Benchmark & Learning Environment.IEEE Ro- botics Autom. Lett.5, 2 (2020), 3019–3026. doi:10.1109/LRA.2020.2974707
-
[24]
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. 2016. End-to-End Training of Deep Visuomotor Policies.J. Mach. Learn. Res.17 (2016), 39:1–39:40. https://jmlr.org/papers/v17/15-522.html
2016
-
[25]
Dipendra Misra, Akanksha Saran, Tengyang Xie, Alex Lamb, and John Langford
-
[26]
arXiv:2403.13765 doi:10.48550/ ARXIV.2403.13765
Towards Principled Representation Learning from Videos for Reinforce- ment Learning.CoRRabs/2403.13765 (2024). arXiv:2403.13765 doi:10.48550/ ARXIV.2403.13765
-
[27]
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. 2022. R3M: A Universal Visual Representation for Robot Manipulation. InConference on Robot Learning, CoRL 2022, 14-18 December 2022, Auckland, New Zealand (Proceedings of Machine Learning Research, Vol. 205), Karen Liu, Dana Kulic, and Jeffrey Ichnowski (Eds.). PMLR, 892–909. h...
2022
-
[28]
Masashi Okada and Tadahiro Taniguchi. 2021. Dreaming: Model-based Rein- forcement Learning by Latent Imagination without Reconstruction. InIEEE International Conference on Robotics and Automation, ICRA 2021, Xi’an, China, May 30 - June 5, 2021. IEEE, 4209–4215. doi:10.1109/ICRA48506.2021.9560734
-
[29]
Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. 2022. Real-World Robot Learning with Masked Visual Pre-training. InConference on Robot Learning, CoRL 2022, 14-18 December 2022, Auckland, New Zealand (Proceedings of Machine Learning Research, Vol. 205), Karen Liu, Dana Kulic, and Jeffrey Ichnowski (Eds.). PML...
2022
-
[30]
James, and Pieter Abbeel
Younggyo Seo, Kimin Lee, Stephen L. James, and Pieter Abbeel. 2022. Rein- forcement Learning with Action-Free Pre-Training from Videos. InInternational Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, G...
2022
-
[31]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, Timothy P. Lillicrap, and Martin A. Riedmiller. 2018. DeepMind Control Suite. CoRRabs/1801.00690 (2018). arXiv:1801.00690 http://arxiv.org/abs/1801.00690
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems 30: An- nual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxbur...
2017
-
[33]
Shuo Wang, Zhihao Wu, Xiaobo Hu, Youfang Lin, and Kai Lv. 2023. Skill-Based Hierarchical Reinforcement Learning for Target Visual Navigation.IEEE Trans. Multim.25 (2023), 8920–8932. doi:10.1109/TMM.2023.3243618 Jinwen Wang et al
-
[34]
Shuo Wang, Zhihao Wu, Xiaobo Hu, Jinwen Wang, Youfang Lin, and Kai Lv
-
[35]
What Effects the Generalization in Visual Reinforcement Learning: Policy Consistency with Truncated Return Prediction. InThirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Appli- cations of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EA...
-
[36]
Jialong Wu, Haoyu Ma, Chaoyi Deng, and Mingsheng Long. 2023. Pre- training Contextualized World Models with In-the-wild Videos for Re- inforcement Learning. InAdvances in Neural Information Processing Sys- tems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan...
2023
-
[37]
Carbonell, Ruslan Salakhutdi- nov, and Quoc V
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdi- nov, and Quoc V. Le. 2019. XLNet: Generalized Autoregressive Pretraining for Language Understanding. InAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, ...
2019
-
[38]
Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel, and Yang Gao. 2021. Mastering Atari Games with Limited Data. InAdvances in Neural Informa- tion Processing Systems 34: Annual Conference on Neural Information Process- ing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, Marc’Aurelio Ran- zato, Alina Beygelzimer, Yann N. Dauphin, Percy Lia...
2021
-
[39]
Weirui Ye, Yunsheng Zhang, Pieter Abbeel, and Yang Gao. 2023. Become a Proficient Player with Limited Data through Watching Pure Videos. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview.net/forum?id=Sy- o2N0hF4f
2023
-
[40]
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. 2019. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning. In3rd Annual Conference on Robot Learning, CoRL 2019, Osaka, Japan, October 30 - November 1, 2019, Proceedings (Proceedings of Machine Learning Research, Vol. 100...
2019
-
[41]
Zhecheng Yuan, Zhengrong Xue, Bo Yuan, Xueqian Wang, Yi Wu, Yang Gao, and Huazhe Xu. 2022. Pre-Trained Image Encoder for Generalizable Visual Reinforcement Learning. InAdvances in Neural Information Process- ing Systems 35: Annual Conference on Neural Information Processing Sys- tems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - Decem- ber 9, 20...
2022
-
[42]
Lixuan Zhang, Meina Kan, Shiguang Shan, and Xilin Chen. 2024. PreLAR: World Model Pre-training with Learnable Action Representation. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXIII (Lecture Notes in Computer Science, Vol. 15081). Springer, 185–201
2024
-
[43]
Bolei Zhou, Àgata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba
-
[44]
Places: A 10 Million Image Database for Scene Recognition.IEEE Trans. Pattern Anal. Mach. Intell.40, 6 (2018), 1452–1464. doi:10.1109/TPAMI.2017. 2723009
-
[45]
Bohan Zhou, Ke Li, Jiechuan Jiang, and Zongqing Lu. 2023. Learning from Visual Observation via Offline Pretrained State-to-Go Transformer. InAdvances in Neu- ral Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Naumann, Amir Glo...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.