SD-RouteFusion: Ego-Trajectory Prediction with SD-Map Route Conditioning
Pith reviewed 2026-07-02 13:34 UTC · model grok-4.3
The pith
SD-map routes reduce ego-trajectory prediction error by 10.5 percent over image-and-kinematics baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
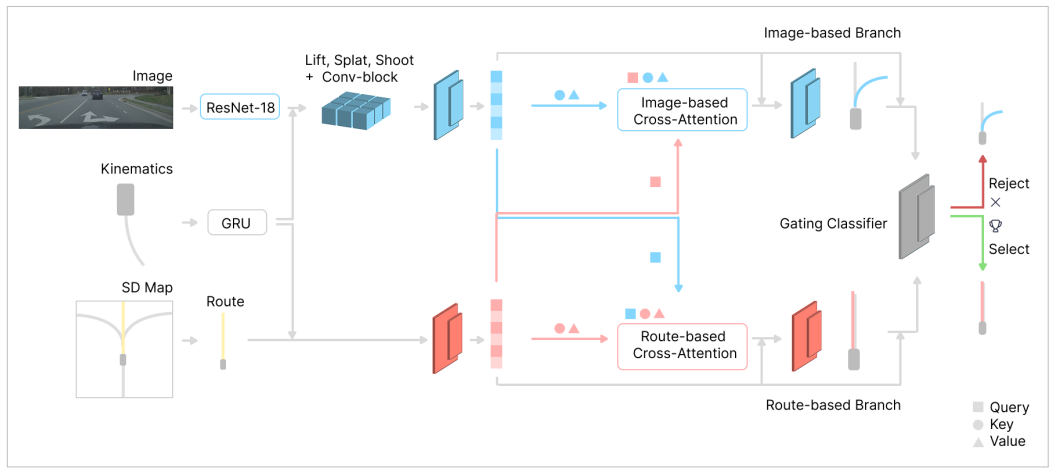
SD-RouteFusion fuses front-facing camera, vehicle kinematics, and an SD-map-derived navigation route via a dual-hypothesis design paired with a gated classifier. On 480k driving scenarios across 10 European countries and the U.S., adding SD-route conditioning yields a 10.5 percent ADE improvement over an image-and-kinematics baseline, and the full fusion strategy achieves a 16.9 percent ADE reduction at an 8-second prediction horizon. The method enables route-aware ego-trajectory prediction without HD-map infrastructure.
What carries the argument
Dual-hypothesis gated classifier that selects between route-conditioned and non-route hypotheses to fuse SD-map route input with camera and kinematics data.
If this is right
- SD-map routes alone deliver a 10.5 percent ADE improvement over the image-and-kinematics baseline.
- The full dual-hypothesis fusion reaches 16.9 percent ADE reduction at 8-second horizons.
- The route prior remains effective across diverse real-world conditions in 10 countries plus the U.S.
- The released SD-route generation toolkit enables the same conditioning on any dataset with ego pose and trajectories.
Where Pith is reading between the lines
- Existing navigation systems could supply the route input, lowering the barrier to route-aware prediction in production vehicles.
- The gated selection mechanism may allow graceful degradation when map data is stale or unavailable.
- The same route prior could be tested on multi-agent trajectory forecasting to improve consistency across nearby vehicles.
Load-bearing premise
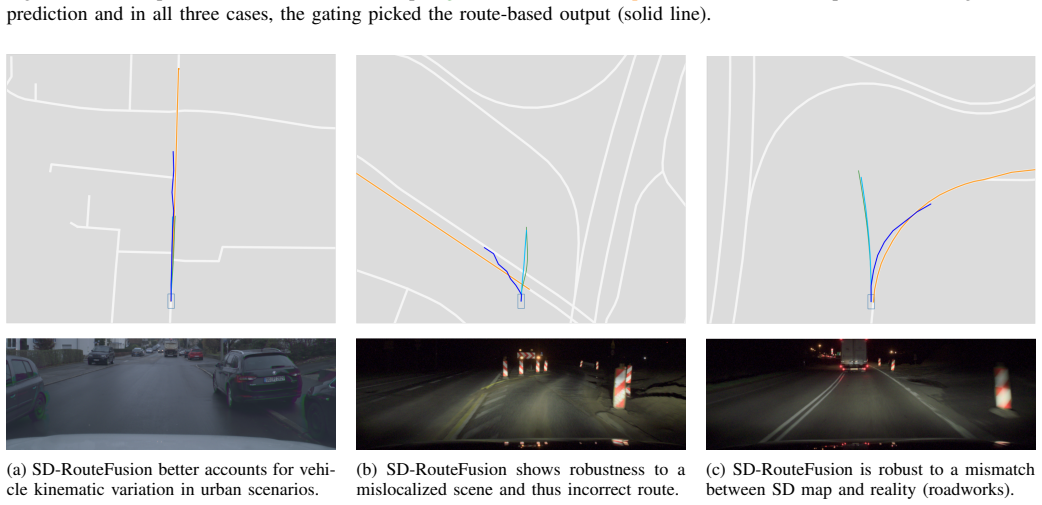
The SD-map route input supplies a reliable long-horizon semantic prior that remains useful even under route corruption or visual uncertainty.
What would settle it
Running the image-and-kinematics baseline with and without SD-route conditioning on the same 480k scenario dataset and observing zero or negative ADE change at the 8-second horizon would falsify the improvement claim.
Figures

read the original abstract
This paper presents SD-RouteFusion, a deployable end-to-end ego-trajectory prediction method that fuses a front-facing camera, vehicle kinematics, and a navigation route derived from a Standard Definition (SD) map. Unlike approaches that rely on High Definition (HD) map geometry, SD-RouteFusion aligns the learning objective with scalable and production-ready SD-map route inputs, enabling route-aware prediction without requiring HD-map infrastructure. First, we demonstrate that SD-map route prior provides a powerful long-horizon semantic prior. Through a comprehensive study on a large-scale real-world dataset comprising 480k driving scenarios across 10 European countries and the U.S., we quantify the value of SD-route conditioning: incorporating SD-map routes yields a 10.5% ADE improvement over an image-and-kinematics baseline, while our full fusion strategy achieves a 16.9% ADE reduction given a prediction horizon of 8 seconds. The fusion strategy consists of a dual-hypothesis design paired with a gated classifier, to ensure robustness under route corruption and visual uncertainty. Finally, to support broader evaluation, we release an SD-route generation toolkit that enables SD-route-conditioned ego-trajectory prediction on all datasets containing ego pose and future trajectories. Together, SD-RouteFusion establishes a practical path toward robust, route-aware ego-trajectory prediction at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SD-RouteFusion, an end-to-end ego-trajectory prediction model that fuses front-facing camera images, vehicle kinematics, and a navigation route extracted from a Standard Definition (SD) map. It claims that SD-map route conditioning supplies a useful long-horizon semantic prior, reporting a 10.5% ADE reduction from adding SD-routes to an image-and-kinematics baseline and a 16.9% ADE reduction with the full dual-hypothesis gated fusion strategy on a 480k-scenario multi-country dataset at an 8-second horizon. The work also releases an SD-route generation toolkit applicable to any dataset containing ego pose and future trajectories.
Significance. If the reported gains are obtained with routes that are strictly available at inference time (i.e., derived only from past pose and map data), the approach would offer a practical, scalable route-aware prediction method that does not require HD-map infrastructure. The dual-hypothesis design with gated classifier is presented as a robustness mechanism. The release of the toolkit could enable broader evaluation, but the numerical claims cannot be assessed without verification that route generation avoids future-trajectory leakage.
major comments (1)
- [Abstract] Abstract (toolkit description): The SD-route generation toolkit is stated to operate on datasets that contain ego pose and future trajectories. No demonstration is provided that the extracted routes are constructed exclusively from information available at t=0 (past pose and SD-map data) rather than being aligned to the ground-truth future path. If route extraction incorporates future information, the 10.5% and 16.9% ADE improvements would reflect an invalid conditioning signal at inference time, directly undermining the central claim that SD-map routes supply an independent long-horizon prior.
minor comments (1)
- The abstract mentions a 'comprehensive study' and 'ablation details' but provides no quantitative breakdown of the dual-hypothesis classifier performance under explicit route corruption or visual uncertainty; these results would strengthen the robustness claim if added.
Simulated Author's Rebuttal
We thank the referee for highlighting the critical need to ensure that SD-route inputs are strictly inference-time compatible. The concern about potential future-trajectory leakage in the toolkit description is well-taken and directly affects the validity of the reported gains. We address the point below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (toolkit description): The SD-route generation toolkit is stated to operate on datasets that contain ego pose and future trajectories. No demonstration is provided that the extracted routes are constructed exclusively from information available at t=0 (past pose and SD-map data) rather than being aligned to the ground-truth future path. If route extraction incorporates future information, the 10.5% and 16.9% ADE improvements would reflect an invalid conditioning signal at inference time, directly undermining the central claim that SD-map routes supply an independent long-horizon prior.
Authors: We agree that the current abstract wording is ambiguous and that the manuscript lacks an explicit demonstration that route extraction uses only t=0 information. The toolkit description mentions datasets containing future trajectories because those trajectories are required for supervised training and evaluation of the prediction model, not because they are inputs to route generation. In practice, routes are obtained by querying the SD map with the ego pose history up to t=0 and a destination derived from the same history (or a user-specified goal); future ground-truth paths are never consulted during route extraction. Nevertheless, because this separation is not shown in the paper, we will revise the abstract to remove any implication of future leakage and add a dedicated subsection (with algorithm pseudocode and a small illustrative example) proving that route generation operates exclusively on past pose and SD-map data. We will also include a short ablation confirming that the reported ADE reductions remain unchanged when routes are regenerated under a strict t=0 constraint. These changes will be reflected in the next revision. revision: yes
Circularity Check
No circularity in derivation chain; claims are empirical measurements on held-out data.
full rationale
The paper presents an empirical architecture for ego-trajectory prediction that fuses camera, kinematics, and SD-map routes, with performance quantified via ADE reductions (10.5% and 16.9%) on a held-out set of 480k real-world scenarios. No equations, fitted parameters, or self-citations are shown that reduce these measured improvements to inputs by construction, nor do any steps match the enumerated circularity patterns such as self-definitional relations or uniqueness theorems imported from prior work. The released toolkit is described as enabling evaluation on datasets with future trajectories but does not alter the self-contained nature of the reported results.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural-network weights
axioms (1)
- domain assumption Deep networks can learn effective multi-modal fusion for trajectory forecasting when given sufficient real-world data.
Reference graph
Works this paper leans on
-
[1]
Trajectory-prediction with vision: A survey,
A. Singh, “Trajectory-prediction with vision: A survey,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3318–3323
2023
-
[2]
Incorporating driving knowledge in deep learning based vehicle trajectory prediction: A survey,
Z. Ding and H. Zhao, “Incorporating driving knowledge in deep learning based vehicle trajectory prediction: A survey,”IEEE Transactions on Intelligent Vehicles, vol. 8, no. 8, pp. 3996–4015, 2023
2023
-
[3]
Large scale interactive motion forecasting for autonomous driving: The Waymo open motion dataset,
S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y . Chai, B. Sapp, C. R. Qi, Y . Zhouet al., “Large scale interactive motion forecasting for autonomous driving: The Waymo open motion dataset,” inProc. of the IEEE/CVF Intl. Conf. on Comp. Vis., 2021, pp. 9710– 9719
2021
-
[4]
nuScenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Kr- ishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuScenes: A multimodal dataset for autonomous driving,” inProc. of the IEEE/CVF Conf. on CVPR, 2020, pp. 11 621–11 631
2020
-
[5]
nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles,
H. Caesar, J. Kabzan, K. Tan, W. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari, “nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles,” 2023
2023
-
[6]
Argoverse 2: Next generation datasets for self-driving perception and forecasting,
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Ponteset al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[7]
One thousand and one hours: Self- driving motion prediction dataset,
J. Houston, G. Zuidhof, L. Bergamini, Y . Ye, L. Chen, A. Jain, S. Omari, V . Iglovikov, and P. Ondruska, “One thousand and one hours: Self- driving motion prediction dataset,” inConf. on Rob. Learning. PMLR, 2021, pp. 409–418
2021
-
[8]
A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook,
M. Liu, E. Yurtsever, J. Fossaert, X. Zhou, W. Zimmer, Y . Cui, B. L. Zagar, and A. C. Knoll, “A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook,”IEEE Transactions on Intelligent Vehicles, 2024
2024
-
[9]
Motion forecasting for autonomous vehicles: A survey,
J. Shi, J. Chen, Y . Wang, L. Sun, C. Liu, W. Xiong, and T. Wo, “Motion forecasting for autonomous vehicles: A survey,”arXiv preprint arXiv:2502.08664, 2025
-
[10]
Multimodal trajectory prediction conditioned on lane-graph traversals,
N. Deo, E. Wolff, and O. Beijbom, “Multimodal trajectory prediction conditioned on lane-graph traversals,” inConf. on Rob. Learning. PMLR, 2022, pp. 203–212
2022
-
[11]
Exploring navigation maps for learning-based motion prediction,
J. Schmidt, J. Jordan, F. Gritschneder, T. Monninger, and K. Dietmayer, “Exploring navigation maps for learning-based motion prediction,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 3539–3545
2023
-
[12]
Hivt: Hierarchical vector transformer for multi-agent motion prediction,
Z. Zhou, L. Ye, J. Wang, K. Wu, and K. Lu, “Hivt: Hierarchical vector transformer for multi-agent motion prediction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8823–8833
2022
-
[13]
Osm vs hd maps: Map representations for trajectory prediction,
J.-Y . Liao, P. Doshi, Z. Zhang, D. Paz, and H. Christensen, “Osm vs hd maps: Map representations for trajectory prediction,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 9990–9996
2024
-
[14]
Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it,
A. Lilja, J. Fu, E. Stenborg, and L. Hammarstrand, “Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 22 150–22 159
2024
-
[15]
Augmenting lane perception and topology understanding with standard definition navigation maps,
K. Z. Luo, X. Weng, Y . Wang, S. Wu, J. Li, K. Q. Weinberger, Y . Wang, and M. Pavone, “Augmenting lane perception and topology understanding with standard definition navigation maps,”arXiv preprint arXiv:2311.04079, 2023
-
[16]
Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving,
M. Alibeigi, W. Ljungbergh, A. Tonderski, G. Hess, A. Lilja, C. Lind- str¨om, D. Motorniuk, J. Fu, J. Widahl, and C. Petersson, “Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 20 178–20 188
2023
-
[17]
Rethinking integration of prediction and planning in deep learning-based automated driving systems: A review,
S. Hagedorn, M. Hallgarten, M. Stoll, and A. Condurache, “Rethinking integration of prediction and planning in deep learning-based automated driving systems: A review,”arXiv e-prints, pp. arXiv–2308, 2023
2023
-
[18]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[19]
Pnpnet: End-to-end perception and prediction with tracking in the loop,
M. Liang, B. Yang, W. Zeng, Y . Chen, R. Hu, S. Casas, and R. Urtasun, “Pnpnet: End-to-end perception and prediction with tracking in the loop,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 553–11 562
2020
-
[20]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022
2022
-
[21]
EMMA: End-to-End Multimodal Model for Autonomous Driving
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sappet al., “Emma: End-to-end multimodal model for autonomous driving,”arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Vip3d: End-to-end visual trajectory prediction via 3d agent queries,
J. Gu, C. Hu, T. Zhang, X. Chen, Y . Wang, Y . Wang, and H. Zhao, “Vip3d: End-to-end visual trajectory prediction via 3d agent queries,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5496–5506
2023
-
[23]
D. Chen and P. Kr ¨ahenb¨uhl, “Learning from all vehicles,” 2022. [Online]. Available: https://arxiv.org/abs/2203.11934
-
[24]
P. Wu, X. Jia, L. Chen, J. Yan, H. Li, and Y . Qiao, “Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline,”arXiv preprint arXiv:2206.08129, 2022, accepted at NeurIPS 2022
-
[25]
Is ego status all you need for open-loop end-to-end autonomous driving?
Y . Liet al., “Is ego status all you need for open-loop end-to-end autonomous driving?”arXiv preprint arXiv:2312.03031, 2023
-
[26]
Leveraging driver field-of-view for multimodal ego-trajectory prediction,
Y . Akbiyiket al., “Leveraging driver field-of-view for multimodal ego-trajectory prediction,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[27]
Densetnt: End-to-end trajectory prediction from dense goal sets,
J. Gu, C. Sun, and H. Zhao, “Densetnt: End-to-end trajectory prediction from dense goal sets,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 303–15 312
2021
-
[28]
TNT: Target-driven trajectory prediction,
H. Zhao, J. Gao, T. Lan, C. Sun, B. Sapp, B. Varadarajan, Y . Shen, Y . Shen, Y . Chai, C. Schmidet al., “TNT: Target-driven trajectory prediction,” inConf. on Rob. Learning. PMLR, 2021, pp. 895–904
2021
-
[29]
GOHOME: Graph-oriented heatmap output for future motion estima- tion,
T. Gilles, S. Sabatini, D. Tsishkou, B. Stanciulescu, and F. Moutarde, “GOHOME: Graph-oriented heatmap output for future motion estima- tion,” in2022 Intl. Conf. on Rob. and Automation (ICRA). IEEE, 2022, pp. 9107–9114
2022
-
[30]
Pbp: Path-based trajectory predic- tion for autonomous driving,
S. Afshar, N. Deo, A. Bhagat, T. Chakraborty, Y . Shao, B. R. Bud- dharaju, A. Deshpande, and H. Cui, “Pbp: Path-based trajectory predic- tion for autonomous driving,” 2024
2024
-
[31]
From prediction to planning with goal conditioned lane graph traversals,
M. Hallgarten, M. Stoll, and A. Zell, “From prediction to planning with goal conditioned lane graph traversals,” in2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2023, pp. 951–958
2023
-
[32]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. Springer, 2020, pp. 194–210
2020
-
[33]
Openstreetmap: Challenges and opportunities in machine learning and remote sensing,
J. E. Vargas-Munoz, S. Srivastava, D. Tuia, and A. X. Falcao, “Openstreetmap: Challenges and opportunities in machine learning and remote sensing,”IEEE Geoscience and Remote Sensing Magazine, vol. 9, no. 1, p. 184–199, Mar. 2021. [Online]. Available: http: //dx.doi.org/10.1109/MGRS.2020.2994107
-
[34]
Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios,
R. Xu, H. Lin, W. Jeon, H. Feng, Y . Zou, L. Sun, J. Gorman, E. Tolstaya, S. Tang, B. White, B. Sapp, M. Tan, J.-J. Hwang, and D. Anguelov, “Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios,”arXiv preprint arXiv:2510.26125, 2025
-
[35]
What the constant velocity model can teach us about pedestrian motion prediction,
C. Sch ¨oller, V . Aravantinos, F. Lay, and A. Knoll, “What the constant velocity model can teach us about pedestrian motion prediction,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1696–1703, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.