Decomposer: Learning to Decompile Symbolic Music to Programs
Pith reviewed 2026-07-03 17:49 UTC · model grok-4.3
The pith
Decomposer recovers executable Strudel programs from MIDI by training on synthetic pairs then refining with reinforcement learning on dual rewards for reconstruction accuracy and code readability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
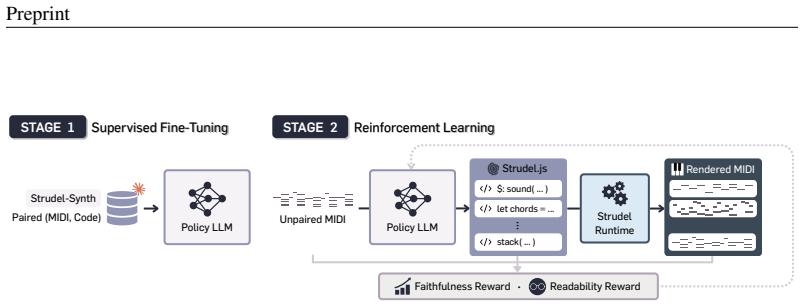
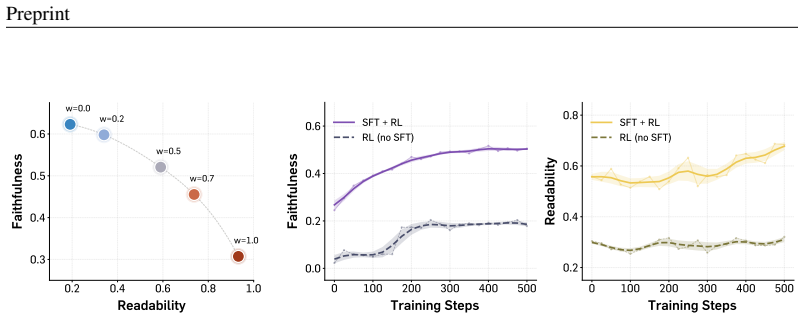
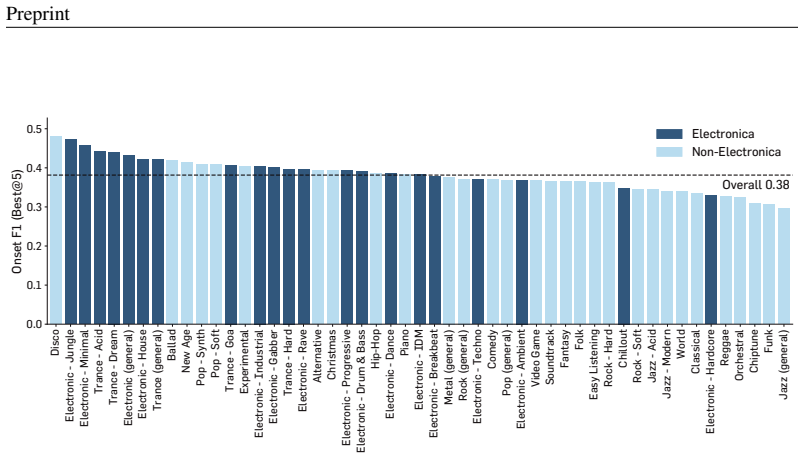
Decomposer is a two-stage post-training method that first performs supervised fine-tuning on the synthetic Strudel-Synth corpus of paired programs and rendered MIDI, then applies reinforcement learning on unpaired MIDI while optimizing a reward that combines MIDI reconstruction faithfulness with code readability; the resulting models produce Strudel programs that reconstruct input MIDI more accurately than closed-source LLMs and yield more readable and diverse code than a heuristic converter across both synthetic and real-world benchmarks.
What carries the argument
The reinforcement learning refinement stage that balances a MIDI reconstruction faithfulness reward against a code readability reward after initial supervised fine-tuning on Strudel-Synth.
If this is right
- Models trained this way reconstruct MIDI more faithfully than closed-source LLMs on both synthetic and real-world benchmarks.
- The generated programs are more readable and diverse than those produced by a heuristic converter.
- The approach works even though Strudel is a low-resource language with little natural paired data.
- Balancing reconstruction and readability prevents collapse to unreadable note-by-note transliterations.
Where Pith is reading between the lines
- The same synthetic-plus-RL recipe could be tried on other low-resource music languages or even non-music domains that need to recover high-level structure from performance data.
- If the readability reward generalizes, the method might reduce the need for large amounts of human-written paired examples in creative program synthesis tasks.
- Musicians could use the output programs as starting points for editing rather than transcribing by hand, but only if the readability gains hold up in actual editing workflows.
Load-bearing premise
That a single combined reward can be optimized to improve both MIDI faithfulness and code readability at the same time without one objective dominating and producing either inaccurate or unreadable programs.
What would settle it
Run the trained Decomposer on a held-out collection of real-world MIDI files, execute the generated Strudel programs, and measure whether the reconstructed MIDI matches the originals more closely than LLM baselines while also scoring higher on automated readability metrics than the heuristic converter.
Figures





read the original abstract
Musical performance involves executing a set of high-level musical instructions, yet recovering those instructions from the performance is a challenging inverse problem. We present Decomposer, a post-training framework for symbolic music decompilation: the task of recovering executable, editable music programs from symbolic music. We instantiate the task as MIDI-to-Strudel decompilation, where the model takes symbolic MIDI as input and produces a program in Strudel, a music programming language, that reconstructs the input when executed. The task poses two challenges: Strudel is a low-resource language with little naturally paired MIDI-code data, and optimizing faithful reconstruction of MIDI alone can collapse to unreadable note-by-note transliteration. We address these challenges in two stages. First, we construct Strudel-Synth, a synthetic corpus of paired Strudel programs and rendered MIDI, and use it for supervised fine-tuning. Second, we refine the model with reinforcement learning on unpaired MIDI, optimizing rewards for both MIDI reconstruction faithfulness and code readability. Our evaluation across synthetic and real-world MIDI benchmarks shows that Decomposer achieves substantially higher MIDI reconstruction faithfulness than closed-source LLMs while producing more readable and diverse code than the heuristic converter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Decomposer, a two-stage post-training framework for symbolic music decompilation: MIDI-to-Strudel program recovery. Stage 1 performs supervised fine-tuning on the synthetic paired corpus Strudel-Synth. Stage 2 applies reinforcement learning on unpaired real MIDI, optimizing a combined reward for MIDI reconstruction faithfulness and code readability. The central claim is that the resulting model yields substantially higher reconstruction faithfulness than closed-source LLMs and more readable/diverse code than a heuristic converter, across both synthetic and real-world MIDI benchmarks.
Significance. If the empirical claims hold after verification of the reward formulation and generalization, the work would provide a concrete advance in low-resource symbolic music inverse problems by demonstrating that synthetic pre-training plus RL can recover editable high-level programs without collapse to note-by-note transliteration. The explicit handling of the readability-faithfulness trade-off via RL is a methodological contribution that could generalize to other program-synthesis-from-performance tasks.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the central claim of 'substantially higher MIDI reconstruction faithfulness' and 'more readable and diverse code' is stated without any reported metrics, data splits, statistical significance tests, or ablation results on the two reward terms. This makes it impossible to verify whether the reported gains are supported or affected by post-hoc choices.
- [§3.2] §3.2 (RL stage): the assumption that the combined reward for faithfulness and readability can be optimized without one objective dominating or producing degenerate note-by-note programs is load-bearing for the two-stage procedure, yet no ablation removing either reward term, no analysis of reward gaming, and no statistics on Strudel-Synth corpus diversity or distribution shift to real MIDI are provided.
- [§4] §4 (Evaluation): the comparison to closed-source LLMs and the heuristic converter lacks details on prompt engineering, decoding parameters, or exact faithfulness metric definitions, undermining the cross-method claim.
minor comments (1)
- [§2] Notation for the Strudel language and MIDI rendering pipeline should be introduced with a small example in §2 to improve readability for readers unfamiliar with the domain.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and verifiability of the results.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the central claim of 'substantially higher MIDI reconstruction faithfulness' and 'more readable and diverse code' is stated without any reported metrics, data splits, statistical significance tests, or ablation results on the two reward terms. This makes it impossible to verify whether the reported gains are supported or affected by post-hoc choices.
Authors: We agree that explicit quantitative support is needed. The revised manuscript will report concrete metrics for reconstruction faithfulness (e.g., note-level and sequence-level similarity scores), readability scores, and diversity measures. We will also specify the data splits, include statistical significance tests, and add ablations isolating each reward term. revision: yes
-
Referee: [§3.2] §3.2 (RL stage): the assumption that the combined reward for faithfulness and readability can be optimized without one objective dominating or producing degenerate note-by-note programs is load-bearing for the two-stage procedure, yet no ablation removing either reward term, no analysis of reward gaming, and no statistics on Strudel-Synth corpus diversity or distribution shift to real MIDI are provided.
Authors: These are valid points. We will add ablations that optimize only faithfulness or only readability, report any observed reward gaming, and include statistics on Strudel-Synth diversity together with an analysis of distribution shift to real MIDI. revision: yes
-
Referee: [§4] §4 (Evaluation): the comparison to closed-source LLMs and the heuristic converter lacks details on prompt engineering, decoding parameters, or exact faithfulness metric definitions, undermining the cross-method claim.
Authors: We agree additional experimental details are required for reproducibility. The revision will specify the prompts and decoding parameters used for the LLMs as well as the exact definitions and computation of the faithfulness metrics. revision: yes
Circularity Check
No circularity detected; empirical pipeline relies on external synthetic data and RL without self-referential reduction
full rationale
The paper describes a two-stage empirical procedure: construct Strudel-Synth for supervised fine-tuning, then apply RL on unpaired MIDI using separate rewards for reconstruction faithfulness and code readability. No equations, derivations, or load-bearing self-citations are present that would make any claimed result equivalent to its inputs by construction. The method is evaluated against external closed-source LLMs and a heuristic converter on both synthetic and real-world benchmarks, rendering the claims falsifiable rather than tautological. This is a standard ML training setup with no patterns matching self-definitional, fitted-input, or uniqueness-imported circularity.
Axiom & Free-Parameter Ledger
axioms (1)
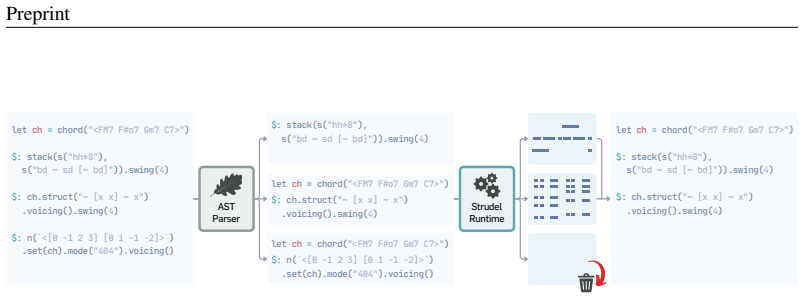
- domain assumption Strudel programs can be deterministically rendered to MIDI
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/1910.08930. Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Hessel, Luke Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, and Prithviraj Ammanabrolu. Personalized soups: Personalized large language model alignment via post-hoc parameter merging.arXiv preprint arXiv:2310.11564, 2023. 13 Preprint Emanuel de Jong. Midi-to-st...
-
[2]
arXiv preprint arXiv:2509.02534 , year=
URLhttps://openreview.net/forum?id=GP5RHZnEsw. Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lan- chantin, and Tianlu Wang. Jointly reinforcing diversity and quality in language model generations. arXiv preprint arXiv:2509.02534, 2025. URLhttps://arxiv.org/abs/2509.02534. Shih-Yang Liu, Xin Dong, Ximing Lu, Shizh...
-
[3]
Association for Computing Machinery. ISBN 9781450367080. doi: 10.1145/3313831. 3376739. URLhttps://doi.org/10.1145/3313831.3376739. Wei-Tsung Lu, Ju-Chiang Wang, and Yun-Ning Hung. Multitrack music transcription with a time- frequency perceiver, 2023. URLhttps://arxiv.org/abs/2306.10785. Ben Maman and Amit H Bermano. Unaligned supervision for automatic mu...
-
[4]
Jan Melechovsky, Abhinaba Roy, and Dorien Herremans
mlsys.org, 2025. Jan Melechovsky, Abhinaba Roy, and Dorien Herremans. Midicaps: A large-scale midi dataset with text captions.arXiv:2406.02255, 2024. Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4.arXiv preprint arXiv:2306.02707, 20...
-
[5]
Proximal Policy Optimization Algorithms
URLhttps://openreview.net/forum?id=nJvgBolRcR. Danila Rukhovich, Elona Dupont, Dimitrios Mallis, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-recode: Reverse engineering cad code from point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9801–9811, 2025. Simone Scalabrino, Mario Linares-Vásquez, Rocco Oliv...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1002/smr.1958 2025
-
[6]
•Identify repeated bars or motifs and express them with concise mini-notation
Structure •Group instruments into separate musical layers, usually insidestack(). •Identify repeated bars or motifs and express them with concise mini-notation. •MIDI note durations are not explicitly encoded; infer reasonable durations from onset gaps and musical context
-
[7]
•Quantize to the smallest common subdivision that preserves the rhythm
Timing •Map cycle onsets directly to rhythmic subdivisions. •Quantize to the smallest common subdivision that preserves the rhythm. •Use~for rests,*Nfor repeated hits,[...]for subdivisions, and<...>for alternation
-
[8]
•For drums, uses()with sound banks
Pitch •For melodic instruments, usenote()with note names orn().scale()when a scale is clear. •For drums, uses()with sound banks. •For same-instrument notes that occur at the same onset, preferchord()withvoicing() when the harmony is recognizable; otherwise use explicit grouped notes. •Do not merge simultaneous notes from different instruments into a singl...
-
[9]
•Usestack()for simultaneous parts andarrange()for section-level organization
Musical structure •Prefer pattern abstraction over event-by-event transliteration. •Usestack()for simultaneous parts andarrange()for section-level organization. •Use<...>for alternating cycles andfast()for intra-cycle density . •Separate bass, chords, melody , and drums when they play distinct musical roles. STYLE GUIDELINES •Ensure readability: voices, s...
-
[10]
Analyze the following MIDI events and write corresponding Strudel code
-
[11]
Can you help me turn this MIDI into Strudel live coding syntax?
-
[12]
Convert the following MIDI events into Strudel code
-
[13]
Encode the following MIDI events into Strudel notation
-
[14]
Express this MIDI sequence as a Strudel program
-
[15]
Generate Strudel code from the MIDI below
-
[16]
Generate the Strudel code that reproduces the following MIDI events
-
[17]
Given the following MIDI events, write the equivalent Strudel pattern
-
[18]
Interpret this MIDI and express it as Strudel live coding syntax
-
[19]
Reproduce the following MIDI pattern in Strudel
-
[20]
Rewrite the following MIDI events using Strudel live coding syntax
-
[21]
Take a look at the MIDI below and write Strudel code that reproduces it
-
[22]
Transform this MIDI representation into Strudel
-
[23]
Translate this MIDI sequence into Strudel code
-
[24]
items":[{
Write Strudel code that is functionally equivalent to the following MIDI. C DESCRIPTIONS FOROPTIMIZATIONMETHODS We provide a description of the two policy-optimization methods referenced in the main paper (Section 2.1). We first explain Group Relative Policy Optimization (GRPO) in Section C.1 and Group reward-Decoupled normalization Policy Optimization (G...
2025
-
[25]
•Plan the main sound layers from the description, such as melody , drums, bass, and pads
Interpret the description •Infer genre conventions: tempo, instruments, rhythmic feel, and harmonic language. •Plan the main sound layers from the description, such as melody , drums, bass, and pads
-
[26]
<Am7 Fmaj7 G C>
Build harmony •Express chord progressions symbolically , e.g.,chord("<Am7 Fmaj7 G C>").voicing(). •Control register with anchor (e.g.,.anchor("c4")) and mode (e.g.,.mode("below"),.mode("duck"), or.mode("above")). •Derive basslines using chord symbols, e.g., chord(chords).rootNotes(2).s("gm_acoustic_bass"). •Use interval stacks such asnote("<[c3,e3,g3] [a2...
-
[27]
bd(3,8)")ors(
Build rhythm and structure •Usestack()or$:for simultaneous parts, andarrange([n, section], ...) for song sections. •Use Euclidean rhythms for organic feels, e.g.,s("bd(3,8)")ors("hh(5,8)"). •Add swing with.swingBy(1/8, 4)or.swing(4). •Add variation with pattern effects, e.g.,.add("<0 1 2 1>"), or.off(1/8, add(7))
-
[28]
bd?","bd | sd
Apply style and effects •Match effects to genre, such as reverb for ambient or jazz, compression for electronic music, and delay for dub. •Keep patterns concise by using mini-notation repetition and<...>alternation instead of spelling out every bar. •Uselayer()orsuperimpose()to add harmonic richness without writing extra voices man- ually . FORBIDDEN CONS...
2013
-
[29]
we adopt an AST-based metric for programming languages. Pure n-gram measures (Papineni et al., 2002) can be dominated by mini-notation pitches and rhythms, which obscures idiom-level diversity, whereas embedding-based code-similarity metrics (Zhou et al., 2023) are trained primarily on high-resource, mainstream languages and are thus less reliable for a l...
2002
-
[30]
Bb3:minor
is a large-scale real-world MIDI corpus of multi-instrument, multi-genre music, including arrangements of modern pop songs and transcriptions of Western classical compositions. For LMD, we sample short fragments shorter than 30 s for evaluation, yielding approximately 9K training segments and 1K test segments. Together, STRUDEL-SYNTHand short LMD fragment...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.