Prompt Coverage Adequacy
Pith reviewed 2026-07-03 08:48 UTC · model grok-4.3
The pith
Prompt Coverage Adequacy uses LLM attention to check test satisfaction of prompts and detects over 30% more faults than code coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prompt Coverage Adequacy serves as an analog to traditional code coverage but operates at the level of prompts. It measures how well a given test suite satisfies the requirements expressed in a prompt by leveraging the attention mechanisms of LLMs. The results demonstrate that Prompt Coverage is associated with fault-detection effectiveness and can uncover over 30+% more faults than traditional code coverage when used to guide test generation.
What carries the argument
Prompt Coverage Adequacy based on attention boosting, which measures test suite satisfaction of prompt requirements using LLM attention mechanisms.
If this is right
- Prompt Coverage is associated with fault-detection effectiveness.
- Prompt Coverage can uncover over 30% more faults than traditional code coverage when used to guide test generation.
- Prompt Coverage Adequacy can serve as a foundation for developing testing metrics better suited to LLM-driven software development.
- Classical coverage criteria have limitations when prompts rather than code are the primary development artifacts.
Where Pith is reading between the lines
- Developers could use prompt coverage to iteratively refine their task descriptions for better testability.
- New tools might emerge that automatically generate tests aimed at maximizing prompt coverage.
- This criterion might help identify when an LLM has misinterpreted a prompt even if the code passes some tests.
- Extensions could apply similar attention-based coverage to other prompt-driven tasks like data generation or analysis.
Load-bearing premise
Attention mechanisms inside LLMs provide a reliable signal for whether a test suite satisfies the requirements expressed in a prompt.
What would settle it
Finding a dataset where test suites with high Prompt Coverage fail to detect faults that suites with low Prompt Coverage detect, or where traditional code coverage performs as well or better in guiding test generation.
Figures

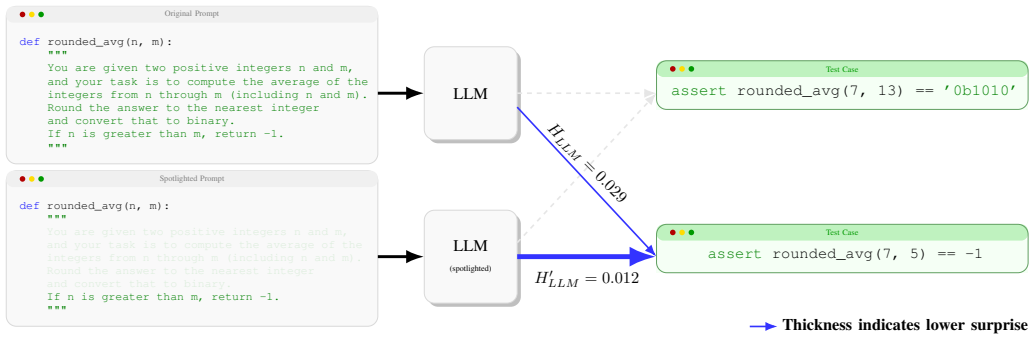
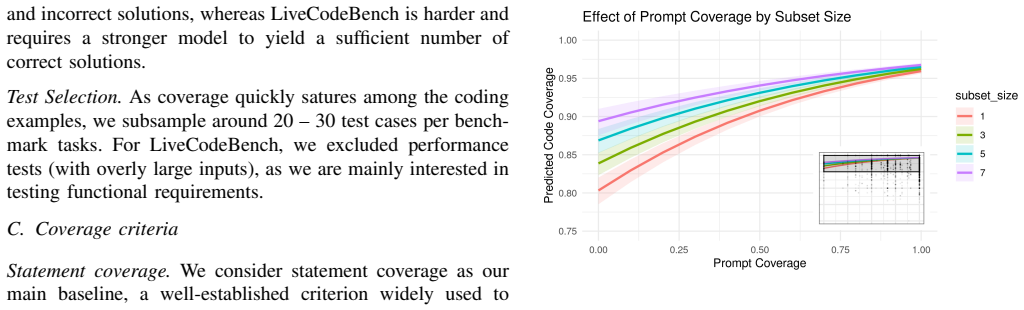
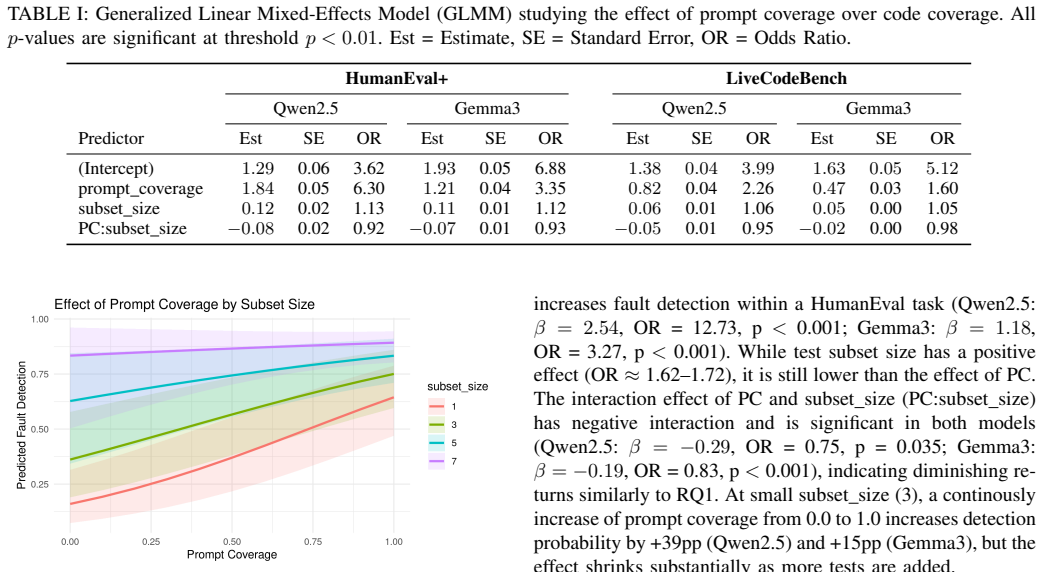
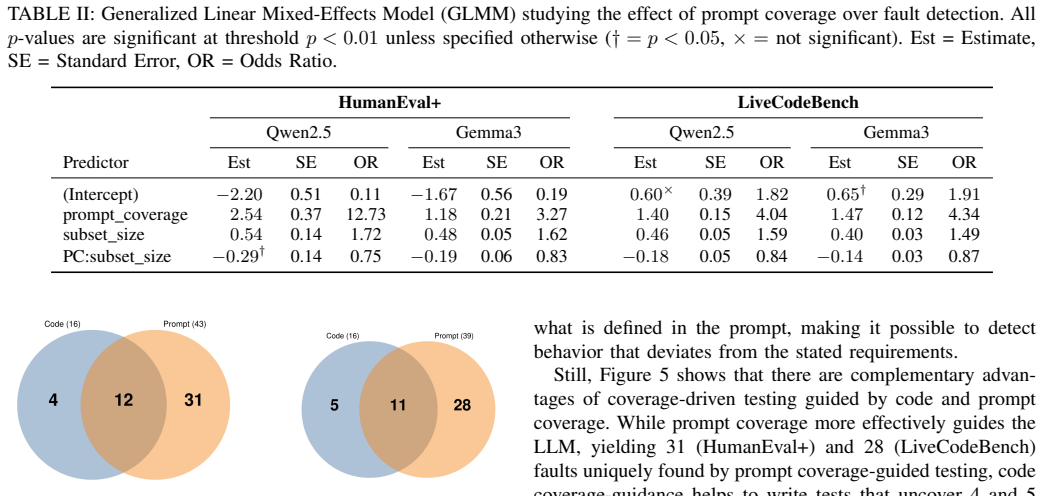
read the original abstract
In recent years, it has become increasingly evident that large language models (LLMs) and autonomous agents raise the level of abstraction in software development by shifting the focus from writing precise procedures to expressing intents and goals. This paradigm shift introduces new challenges, particularly in how testing should be guided when prompts, rather than code, become primary development artifacts. To address this challenge, we propose Prompt Coverage Adequacy, a novel coverage criterion designed to support the testing of code generated from task descriptions. Prompt Coverage Adequacy serves as an analog to traditional code coverage, but operates at the level of prompts used in LLM and agent-based programming. Specifically, it measures how well a given test suite satisfies the requirements expressed in a prompt by leveraging the attention mechanisms of LLMs. We evaluate a simple instantiation of this criterion, based on attention boosting, across two datasets and multiple LLMs. Our results demonstrate that Prompt Coverage is associated with fault-detection effectiveness and can uncover over 30+% more faults than traditional code coverage when used to guide test generation. These findings suggest that Prompt Coverage Adequacy can serve as a foundation for developing testing metrics better suited to the emerging paradigm of LLM-driven software development, addressing the limitations of classical coverage criteria in this new context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Prompt Coverage Adequacy, a novel coverage criterion for testing code generated from prompts in LLM-based development. It measures how well test suites satisfy prompt requirements by leveraging LLM attention mechanisms (via a simple attention-boosting instantiation). Evaluation across two datasets and multiple LLMs is reported to show association with fault-detection effectiveness and over 30% more faults uncovered than traditional code coverage when guiding test generation.
Significance. If the attention-based proxy is validated as measuring semantic requirement satisfaction (rather than model artifacts), the work could provide a useful foundation for testing metrics adapted to prompt-driven software development. The reported empirical association with fault detection and the 30+% gain would then indicate practical utility over classical criteria, but the current lack of grounding or controls for the core mechanism limits its assessed significance.
major comments (2)
- [Abstract] Abstract: The evaluation is described only at high level ('across two datasets and multiple LLMs') with no details supplied on dataset characteristics, the concrete implementation of attention boosting, statistical tests performed, controls, or ablation studies. This absence prevents any assessment of whether the reported association and 30+% gain are attributable to Prompt Coverage Adequacy.
- [Abstract] Abstract: The central claim relies on the assumption that attention mechanisms inside LLMs provide a reliable signal for whether a test suite satisfies the requirements expressed in a prompt. No argument, external validation, or check is given that attention scores track semantic coverage rather than token position, syntactic salience, or other model-specific artifacts; if this proxy is invalid, the fault-detection results cannot be interpreted as support for the new criterion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The evaluation is described only at high level ('across two datasets and multiple LLMs') with no details supplied on dataset characteristics, the concrete implementation of attention boosting, statistical tests performed, controls, or ablation studies. This absence prevents any assessment of whether the reported association and 30+% gain are attributable to Prompt Coverage Adequacy.
Authors: The full manuscript provides these details in the Evaluation section, including dataset descriptions (e.g., prompt counts, domains), the attention boosting formula, statistical methods used (correlation coefficients and p-values), controls (baselines), and ablations. To address the concern for the abstract, we will expand it slightly to include key quantitative details while respecting length constraints. revision: partial
-
Referee: [Abstract] Abstract: The central claim relies on the assumption that attention mechanisms inside LLMs provide a reliable signal for whether a test suite satisfies the requirements expressed in a prompt. No argument, external validation, or check is given that attention scores track semantic coverage rather than token position, syntactic salience, or other model-specific artifacts; if this proxy is invalid, the fault-detection results cannot be interpreted as support for the new criterion.
Authors: We note that the association with fault detection is presented as empirical evidence supporting the utility of the criterion. The paper references literature on attention mechanisms capturing relevant information. However, we agree that a direct validation of the proxy is not included. We will revise the manuscript to include a dedicated limitations subsection discussing this assumption and outlining plans for future validation studies. revision: partial
Circularity Check
No significant circularity; metric defined externally and validated empirically
full rationale
The paper introduces Prompt Coverage Adequacy as a new criterion that measures test-suite satisfaction of prompt requirements by leveraging LLM attention mechanisms, with a simple attention-boosting instantiation evaluated on two external datasets across multiple LLMs. The central empirical claims (association with fault-detection effectiveness and >30% improvement over code coverage) rest on direct experimental comparisons rather than any reduction to fitted parameters, self-citations, or definitional equivalence. No load-bearing step equates the output to its inputs by construction; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention mechanisms of LLMs can be leveraged to measure how well a test suite satisfies requirements expressed in a prompt
invented entities (1)
-
Prompt Coverage Adequacy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
glmmTMB
“glmmTMB.” [Online]. Available: https://www.rdocumentation.org/pac kages/glmmTMB/versions/1.1.13
-
[2]
Replication package,
“Replication package,” UNDER REVIEW
-
[3]
Claude code,
Anthropic, “Claude code,” 2025, accessed: 2025. [Online]. Available: https://www.anthropic.com/claude-code
2025
-
[4]
Recovering traceability links between code and documentation,
G. Antoniol, G. Canfora, G. Casazza, A. D. Lucia, and E. Merlo, “Recovering traceability links between code and documentation,”IEEE Trans. Software Eng., vol. 28, no. 10, pp. 970–983, 2002. [Online]. Available: https://doi.org/10.1109/TSE.2002.1041053
-
[5]
[Online]
Anysphere, “Cursor,” 2024, accessed: 2026. [Online]. Available: https://www.cursor.com
2024
-
[7]
Program Synthesis with Large Language Models
[Online]. Available: https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Evaluation of large language models for assessing code maintainability,
M. Dillmann, J. Siebert, and A. Trendowicz, “Evaluation of large language models for assessing code maintainability,”CoRR, vol. abs/2401.12714, 2024. [Online]. Available: https://doi.org/10.48550/a rXiv.2401.12714
work page doi:10.48550/a 2024
-
[10]
Large language models for software engineering: Survey and open problems,
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, and J. M. Zhang, “Large language models for software engineering: Survey and open problems,” inIEEE/ACM International Conference on Software Engineering: Future of Software Engineering, ICSE-FoSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 2023, pp. 31–53. [Online]. Available: https...
-
[11]
Vibe coding in practice: Motivations, challenges, and a future outlook – a grey literature review,
A. Fawzy, A. Tahir, and K. Blincoe, “Vibe coding in practice: Motivations, challenges, and a future outlook – a grey literature review,” 2025. [Online]. Available: https://arxiv.org/abs/2510.00328
-
[12]
Reachability and propagation for LTL requirements testing,
G. Fraser and P. Ammann, “Reachability and propagation for LTL requirements testing,” inProceedings of the Eighth International Conference on Quality Software, QSIC 2008, 12-13 August 2008, Oxford, UK, H. Zhu, Ed. IEEE Computer Society, 2008, pp. 189–198. [Online]. Available: https://doi.org/10.1109/QSIC.2008.21
-
[13]
Prompt-to-SQL Injections in LLM-Integrated Web Applications: Risks and Defenses ,
D. Fuchß, T. Hey, J. Keim, H. Liu, N. Ewald, T. Thirolf, and A. Koziolek, “Lissa: Toward generic traceability link recovery through retrieval- augmented generation,” in47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 2025, pp. 1396–1408. [Online]. Available: https://doi.org/10.110...
-
[14]
Github copilot,
GitHub, “Github copilot,” 2021, accessed: 2026. [Online]. Available: https://github.com/features/copilot
2021
-
[15]
Semantically enhanced software traceability using deep learning techniques,
J. Guo, J. Cheng, and J. Cleland-Huang, “Semantically enhanced software traceability using deep learning techniques,” inProceedings of the 39th International Conference on Software Engineering, ICSE 2017, Buenos Aires, Argentina, May 20-28, 2017, S. Uchitel, A. Orso, and M. P. Robillard, Eds. IEEE / ACM, 2017, pp. 3–14. [Online]. Available: https://doi.or...
-
[16]
Livecodebench: Holistic and contamination free evaluation of large language models for code,
N. Jain, K. Han, A. Gu, W. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,” in The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://...
2025
-
[17]
S. Jain and B. C. Wallace, “Attention is not explanation,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds. Association for Com...
-
[18]
There’s a new kind of coding I call “vibe cod- ing
A. Karpathy, “There’s a new kind of coding I call “vibe cod- ing”,” https://x.com/karpathy/status/1886192184808149383, Feb. 2025, accessed: 2025-02-03
-
[19]
Likelihood-based inference for generalized linear mixed models: Inference with the r package glmm,
C. Knudson, S. Benson, C. Geyer, and G. Jones, “Likelihood-based inference for generalized linear mixed models: Inference with the r package glmm,”Stat, vol. 10, no. 1, p. e339, 2021, e339 sta4.339. [Online]. Available: https://onlinelibrary.wiley.com/doi/abs/10.1002/sta4 .339
-
[20]
How well llm-based test generation techniques perform with newer LLM versions?
M. Konstantinou, R. Degiovanni, and M. Papadakis, “How well llm-based test generation techniques perform with newer LLM versions?”CoRR, vol. abs/2601.09695, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.09695
-
[21]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,
J. Liu, C. S. Xia, Y . Wang, and L. Zhang, “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Nauma...
2023
-
[22]
T. Merten, D. Kr ¨amer, B. Mager, P. Schell, S. B ¨ursner, and B. Paech, “Do information retrieval algorithms for automated traceability perform effectively on issue tracking system data?” inRequirements Engineering: Foundation for Software Quality - 22nd International Working Conference, REFSQ 2016, Gothenburg, Sweden, March 14-17, 2016, Proceedings, ser...
-
[23]
G. J. Myers, T. Badgett, T. M. Thomas, and C. Sandler,The art of software testing. Wiley Online Library, 2004, vol. 2
2004
-
[24]
Chapter six - mutation testing advances: An analysis and survey,
M. Papadakis, M. Kintis, J. Zhang, Y . Jia, Y . L. Traon, and M. Harman, “Chapter six - mutation testing advances: An analysis and survey,” Adv. Comput., vol. 112, pp. 275–378, 2019. [Online]. Available: https://doi.org/10.1016/bs.adcom.2018.03.015
-
[25]
Coverup: Effective high coverage test generation for python,
J. A. Pizzorno and E. D. Berger, “Coverup: Effective high coverage test generation for python,”Proc. ACM Softw. Eng., vol. 2, no. FSE, pp. 2897–2919, 2025. [Online]. Available: https://doi.org/10.1145/3729398
-
[26]
Model-based testing in practice,
A. Pretschner, “Model-based testing in practice,” inFM 2005: Formal Methods, International Symposium of Formal Methods Europe, Newcastle, UK, July 18-22, 2005, Proceedings, ser. Lecture Notes in Computer Science, J. S. Fitzgerald, I. J. Hayes, and A. Tarlecki, Eds., vol. 3582. Springer, 2005, pp. 537–541. [Online]. Available: https://doi.org/10.1007/11526841 37
-
[27]
B. Ray, V . J. Hellendoorn, S. Godhane, Z. Tu, A. Bacchelli, and P. T. Devanbu, “On the ”naturalness” of buggy code,” inProceedings of the 38th International Conference on Software Engineering, ICSE 2016, Austin, TX, USA, May 14-22, 2016, L. K. Dillon, W. Visser, and L. A. Williams, Eds. ACM, 2016, pp. 428–439. [Online]. Available: https://doi.org/10.1145...
-
[28]
Neural language models for code quality identification,
S. Sengamedu and H. Zhao, “Neural language models for code quality identification,” inProceedings of the 6th International Workshop on Machine Learning Techniques for Software Quality Evaluation, MaLTeSQuE 2022, Singapore, Singapore, 18 November 2022, M. Cordy, X. Xie, B. Xu, and S. Bibi, Eds. ACM, 2022, pp. 5–10. [Online]. Available: https://doi.org/10.1...
-
[29]
Sommerville,Software engineering, 9/E
I. Sommerville,Software engineering, 9/E. Pearson Education India, 2011
2011
-
[30]
Toward automated validation of language model synthesized test cases using semantic entropy,
H. Taherkhani, J. Shin, M. A. Tahir, M. R. H. Misu, V . S. Gattani, and H. Hemmati, “Toward automated validation of language model synthesized test cases using semantic entropy,”IEEE Trans. Software Eng., vol. 52, no. 4, pp. 1426–1445, 2026. [Online]. Available: https://doi.org/10.1109/TSE.2026.3664287
-
[31]
Bugs in large language models generated code: an empirical study,
F. Tambon, A. M. Dakhel, A. Nikanjam, F. Khomh, M. C. Desmarais, and G. Antoniol, “Bugs in large language models generated code: an empirical study,”Empir. Softw. Eng., vol. 30, no. 3, p. 65, 2025. [Online]. Available: https://doi.org/10.1007/s10664-025-10614-4
-
[32]
A taxonomy of model-based testing approaches,
M. Utting, A. Pretschner, and B. Legeard, “A taxonomy of model-based testing approaches,”Softw. Test. Verification Reliab., vol. 22, no. 5, pp. 297–312, 2012. [Online]. Available: https://doi.org/10.1002/stvr.456
-
[33]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S...
2017
-
[34]
Spotlight your instructions: Instruction-following with dynamic attention steering,
P. Venkateswaran and D. Contractor, “Spotlight your instructions: Instruction-following with dynamic attention steering,” inProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2026 - Volume 1: Long Papers, Rabat, Morocco, March 24-29, 2026, V . Demberg, K. Inui, and L. Marquez, Eds. Association...
-
[35]
Counterfactual explanations and algorithmic recourses for machine learning: A review,
S. Verma, V . Boonsanong, M. Hoang, K. Hines, J. Dickerson, and C. Shah, “Counterfactual explanations and algorithmic recourses for machine learning: A review,”ACM Comput. Surv., vol. 56, no. 12, pp. 312:1–312:42, 2024. [Online]. Available: https://doi.org/10.1145/3677 119
-
[36]
Software testing with large language models: Survey, landscape, and vision,
J. Wang, Y . Huang, C. Chen, Z. Liu, S. Wang, and Q. Wang, “Software testing with large language models: Survey, landscape, and vision,” IEEE Trans. Software Eng., vol. 50, no. 4, pp. 911–936, 2024. [Online]. Available: https://doi.org/10.1109/TSE.2024.3368208
-
[37]
C. S. Xia, Y . Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” in45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 2023, pp. 1482–1494. [Online]. Available: https://doi.org/10.1109/ICSE48619.2023.00129
-
[38]
Swe-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, A. Globersons,...
2024
-
[39]
Autocoderover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “Autocoderover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024, M. Christakis and M. Pradel, Eds. ACM, 2024, pp. 1592–1604. [Online]. Available: https://doi.org/10.1145/365021...
-
[40]
Software unit test coverage and adequacy,
H. Zhu, P. A. V . Hall, and J. H. R. May, “Software unit test coverage and adequacy,”ACM Comput. Surv., vol. 29, no. 4, pp. 366–427, 1997. [Online]. Available: https://doi.org/10.1145/267580.267590
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.